
嵌入式处理器P2020机器码程序到C语言源程序的溯源方法
2021-10-20 03:06:14谢文光李琪马春燕汪克念尹伟张涛
航空学报 2021年9期
谢文光,李琪,马春燕,*,汪克念,尹伟,张涛
1. 中国民航大学 适航学院 民航航空器适航审定技术重点实验室, 天津 300300
2. 航空工业无线电电子研究所, 上海 200241
3. 西北工业大学 软件学院, 西安 710072
目前,电信、军事以及工业嵌入式应用领域均要求确保机器码程序和C源程序的功能一致性,以防止编译过程中插入非C源程序中要求的例外功能,影响嵌入式系统可靠性和安全性[1]。例如民用飞机机载软件通常采用RTCA/DO-178C作为适航符合性方法。对于A级软件(即安全水平最高的研制保证等级软件)[2],RTCA/DO-178C要求实现机器码程序到源程序的追溯性。
PowerPC P2020[3]处理器在航空嵌入式软件系统和其他嵌入式领域中被广泛应用。C语言应用程序需要在PC平台X86处理器上通过C语言编译器进行编译[4],生成可以在PowerPC P2020处理器上执行的机器码程序。本文以RTCA/DO-178C中的适航要求[5]作为研究的出发点,以PowerPC P2020处理器的机器码程序作为溯源的需求,假设编译器在编译过程中可能会插入例外代码,通过追溯机器码程序和C源程序的溯源关系,降低安全关键软件存在的风险和不稳定因素。
目前溯源方法需要程序员人工分析并建立映射关系,分析难度高、效率低。提升机器码程序和C源程序溯源关系的自动化程度是目前研究的热点之一。Brauer等[6]通过判断机器码和源代码的控制流图是否同构,提出了一种使用抽象解释验证部分机器码和源代码可追溯性分析的技术。Boccardo等[7]利用调用图的大小、函数数量、控制流图的顶点和边的数量4个特性,提出了一种使用人工神经网络来关联源代码和机器码的方法,但是,该方法实现的机器码的溯源关系精确性有待提高。文献[8]采用程序分析技术建立知识库,并对源代码进行分析,以揭示所使用的变量、算术操作、逻辑操作、关系操作和控制结构等参数。Rapita 公司和GmbH 公司[9-10]分别研制了源码到机器码追溯的可视化工具,静态分析C代码和汇编代码程序,从分支、函数、内存分配等角度,验证源代码到机器码的追溯关系。文献[11]讨论了从源代码到机器码追溯涉及的相关技术,但未给出具体追溯方法。文献[12]根据源代码的典型语法结构及代码子集,生成源码、汇编代码交叉对照列表,但未给出函数体中机器码和源代码的代码行追溯方法。文献[13]对恶意代码可执行文件进行反汇编及分词,利用Word2Vec对反汇编后的十六进制码进行矢量化,搭建TextCNN深度学习模型进行家族谱判定,但该方法仅根据已有的样本来识别变体,可能导致溯源工作低效甚至无效。文献[14]研究目前提出的恶意代码的溯源技术,指出具有更高级威胁的恶意代码检测存在缺陷。文献[15]将源代码与机器码的每一个语句映射到向量,利用神经网络体系结构,逐句分析源代码及机器码之间的关系。文献[16-17]介绍了一种验证MC68020机器码正确性的形式化方法,但是该研究并未涉及浮点型程序的验证。文献[18]将GCC编译器源代码中的函数分为会修改输入数据的函数和不会修改输入数据的函数,人工对比输入输出数据检测是否被插入恶意代码,但效率较低。
基于以上研究背景,本文提出从文件、函数名、函数体代码行3层次实现PowerPC P2020处理器机器码程序与C源程序之间的溯源方法,与现有工作相比,具有以下优点:
1) 方法更具有通用性,适用于不同语言、不同处理器型号之间溯源关系的研究,只需将 2.4.1 节中语言语法结构到汇编语言指令序列映射规则的定义修改为相关语言及处理器汇编语言指令序列映射规则的定义即可。
2) 方法分析机器码代码行和源码的溯源关系时,不局限于机器码子集、关键语法特征、分支或函数等。
3) 方法可以提升溯源的自动化程度,并研制落地的实验环境实现溯源对比的目标,节省人工劳动。
4) 方法利用源代码和机器码之间语法和语义的等价性原理进行溯源,更为精确可靠。
1 PowerPC P2020机器码程序到C语言源程序的溯源需求
自顶向下分解C语言源码和PowerPC P2020机器码之间的溯源关系,可将C语言源码和PowerPC P2020机器码之间的映射需求分为3部分:
1) PowerPC P2020机器码文件主名应与C语言源码文件主名溯源。
在编译过程[19]中,编译器会根据C源程序文件主名生成相同主名的PowerPC P2020机器码文件。在映射函数及函数体前,需要先对生成的机器码文件(.o文件)进行检查,建立文件之间的映射关系,以防在链接时引入未知的文件模块。
2) PowerPC P2020机器码文件中函数名应与C语言源码文件中的函数名溯源。
在文件主名一一映射的前提下,需要先对生成的机器码文件中所有的函数名进行检查,建立函数名之间的映射关系,以防在链接时引入未知的函数模块。
3) PowerPC P2020机器码文件中的函数体代码应和C语言源码文件中的函数体代码溯源。
在文件主名与函数名一一映射的前提下,对生成的机器码中所有的函数体进行检查,防止在编译时引入未知的代码行。
2 PowerPC P2020机器码程序到C语言源程序的溯源
2.1 算法概览
论文提出的溯源算法 CodeTraceBack的伪代码如算法1。根据第1节的3层次映射需求,溯源算法CodeTraceBack包括3个子算法,即文件的溯源子算法、函数声明的溯源子算法和函数体的溯源子算法。

算法1 溯源算法CodeTraceBack伪代码

1) 文件溯源(伪代码1~25行):C源程序与PowerPC P2020机器码程序经预处理模块处理后,获取C源程序文件主名列表与PowerPC P2020机器码程序文件主名列表,对比得出C源程序与PowerPC P2020机器码程序文件主名的溯源关系,详见2.2节。
2) 函数声明溯源(伪代码26~62行):通过遍历C源程序抽象语法树[20]获取函数名列表;通过遍历PowerPC P2020机器码程序汇编码获取函数名列表。对比两项函数列表分析得出C源程序与PowerPC P2020机器码程序函数名的溯源关系,详见2.3节。对于函数可变参数的情况或其他错误情况,如果导致函数声明中形式参数和形式参数个数出现溯源问题,由于形式参数会在函数体中的代码行中使用,函数体溯源时会发现与机器码汇编指令集无法匹配的问题。
3) 函数体溯源(伪代码63~103行):根据C源程序生成的抽象语法树,结合论文定义的抽象语法树节点与汇编指令集的映射规则,生成以函数为单位的期望汇编指令序列。同时,以函数为单位获取机器码程序对应的实际汇编代码序列。对比期望的汇编指令序列和编译器生成的汇编代码序列,即可得出C源程序与机器码程序函数体的溯源关系,详见2.4节。
2.2 PowerPC P2020机器码程序文件主名与源文件文件主名溯源
C源程序与PowerPC P2020机器码程序文件主名之间的溯源包括经预处理获取PowerPC P2020机器码程序文件主名名称、C源程序文件主名名称、建立追溯关系3个步骤。
1) 针对PowerPC P2020机器码程序,预处理模块解析其文件主名,去除文件名后缀,生成机器码主名列表,标记为targetFileNameSet,对应伪代码中第3行。
2) 针对C源程序,预处理模块解析其文件主名,去除文件名后缀,生成源文件主名列表,标记为sourceFileNameSet,对应伪代码中第2行。
3) 建立targetFileNameSet中文件主名到sourceFileNameSet中文件主名的追溯关系,标记为ResultOfFileName。分析机器码文件主名列表targetFileNameSet和源文件列表sourceFileNameSet中的文件主名是否相等。若匹配成功,将该文件主名对应的文件目录和文件主名存储在ResultOfFileName中;若匹配失败,则添加该文件主名至ResultOfFileName中,并标注其未能追溯的结果,对应伪代码中4~23行。ResultOfFileName表格包含3列,即PowerPC P2020机器码程序文件主名所在的目录、C源程序文件主名所在的目录、文件主名和结果标注。
2.3 PowerPC P2020机器码程序函数声明与源文件函数声明的溯源
C源程序与PowerPC P2020机器码程序函数名之间的溯源分为3个步骤,包括反汇编机器码程序获取机器码函数名列表、通过语法分析获取C源程序函数名列表,以及对比获取机器码函数名列表和C源程序函数名列表的溯源关系。
1) 针对PowerPC P2020机器码程序,生成其所有函数名列表(伪代码49~61行)。
伪代码第50行通过编译器套件中提供的“powerpc-linux-gnu-objdump-t”命令对PowerPC P2020机器码程序进行反汇编操作。PowerPC P2020机器码程序文件遵循ELF格式,伪代码51~59行解析PowerPC P2020机器码程序ELF格式中的符号表段(.symtab段),识别函数名、函数名所在的行号以及该函数名所在的机器码文件主名,构造PowerPC P2020机器码程序所有函数声明的列表targetFuncNameSet(伪代码第60行)。列表中的每个元素包括3个属性信息:函数名、行号、机器码文件主名。其中,机器码文件主名是2.2节中机器码程序成功映射的文件主名。
2) 针对C源程序,基于抽象语法树生成其所有函数名列表(伪代码31~48行)。
语法分析模块可以利用开源工具Pycparser或其他自主研制的类似工具,生成C源程序文件的抽象语法树(伪代码第44行)。每个抽象语法树的节点包含了语法结构的名称、子节点信息及其在C源程序中的行号信息。伪代码第46行调用的getSourceFunc函数(伪代码31~42行)遍历抽象语法树,搜索抽象语法树中所有FuncDef节点(函数声明节点),根据节点的属性信息,构造C源程序所有函数声明的列表sourceFuncNameSet(伪代码第47行)。列表中的每个元素包括3个属性信息:函数名、行号、源文件主名。其中,源文件主名是2.2节中机器码程序成功映射的文件主名。
3) 建立PowerPC P2020机器码程序函数名和C源程序函数名之间的追溯关系(伪代码第62行)。
针对targetFuncNameSet和sourceFuncNameSet中机器码文件主名和源文件主名一致的2个元素,利用伪代码中的compareSets函数计算这2个元素的函数名是否相等。建立PowerPC P2020机器码程序函数名和C源程序函数名之间的追溯关系列表,标记为ResultOfFuncName,将匹配成功的函数名信息存入该表格中,表格包含6列,即targetFuncNameSet列表中的每个元素和sourceFuncNameSet列表中的每个元素,同时将未匹配成功的进行标注。
2.4 PowerPC P2020机器码函数体代码与源文件函数体代码的溯源
C源程序与PowerPC P2020机器码程序的函数体之间的溯源分为3个步骤,包括结合C源程序对应的抽象语法树与映射规则生成期望汇编指令序列、反汇编机器码程序获取实际的汇编代码序列,以及获取汇编代码序列和期望汇编指令序列的溯源关系。其中,确定C源程序抽象语法树节点生成期望汇编语言指令序列的规则是本文的核心关键技术。
本文建立了抽象语法树节点映射到P2020期望汇编语言指令序列的规则库,伪代码第70行即当遍历到抽象语法树节点时则调用该规则库,利用规则库中抽象语法树节点与期望汇编指令序列之间关系的规则定义,生成源程序的期望汇编指令序列。2.4.1节将详细阐述该抽象语法树节点映射到PowerPC P2020汇编语言指令序列的规则库定义。
2.4.1 C程序语法结构到PowerPC P2020汇编
语言指令序列映射规则的定义
抽象语法树节点包含23类,由于论文篇幅所限,本文仅列出函数类、流程控制类、跳转类、运算类等较为常用的抽象语法树节点,详细阐述它们到PowerPC P2020汇编语言指令序列映射规则的定义。完整的语法结构、语义及对应的P2020汇编代码序列的映射规则上传https:∥gitee.com/angelavor/cto,便于读者查看。
1) 函数类
① 函数调用节点funcCall
对于C源程序的抽象语法树的函数调用节点funcCall,生成的汇编语言指令的规则为
(1)若调用语句中不存在实参:
生成一条条件跳转指令:bl。
(2)若调用语句中存在实参:
(a)识别C语言函数调用语句中的实参对应的抽象语法树,遍历该抽象语法树的各个节点类型,生成相应的汇编语言指令序列:若参数类型为整型或者长整型:lwz;若参数类型为字符型:lbz、clrlwi、mr;若参数类型为短整型:lhz、extsh、mr;若参数类型为浮点型:lwz、efdcfs、evmergehi、mr;若参数类型为双精度浮点型:lwz、lwz、mr、mr;若参数类型为数组型:addi、mr。
(b)生成一条函数调用指令:crclr addres。
(c)一条条件跳转指令:bl。
② 函数声明节点funcDecl
对于C源程序的抽象语法树的函数声明节点funcDecl,生成的汇编语言指令序列规则为
(1)函数体入口指令序列:stwu、stw、mr。
(2)识别C语言函数体中语句序列对应的抽象语法树,遍历该抽象语法树的各个节点类型,生成相应的汇编语言指令序列。
(3)函数体出口指令序列:lwz、mr、blr。
2) 控制语句相关节点
① if控制节点
对于C源程序的抽象语法树的if节点,生成的汇编语言指令序列规则为
(1)根据if语句的判断条件语句函数块信息生成对应的汇编指令序列:
(a)如果第1个子树是constant或者id节点:不添加汇编指令。
(b)如果第1个子树是binaryOp,且binaryOp的两个子树均为constant节点:不添加汇编指令。
(c)其他情况:遍历该抽象语法树,根据各个节点类型,生成相应的汇编语言指令序列。
(2)生成1条比较指令:
(a)如果第1个子树是constant或者id节点:不添加汇编指令。
(b)如果第1个子树是binaryOp且binaryOp的两个子树均为constant节点:不添加汇编指令。
(c)如果第1个子树是binaryOp,且binaryOp的判断条件是“||”,binaryOp的两个子树存在一个constant节点:不添加汇编指令。
(d)如果第1个子树binaryOp的两个子树节点均为id:cmpw。
(e)如果第1个子树binaryOp的两个子树有且只有一个constant节点:cmpwi。
(3)生成1条条件跳转指令:
(a)若第1个子树是id:beq。
(b)若第1个子树binaryOp的比较符号为“==”:若变量为浮点型:ble;其他情况:bne。
(c)若第1个子树binaryOp的比较符号为“!=”:若变量为浮点型:bgt;其他情况:beq。
(d)若第1个子树binaryOp的比较符号为“>=”:若均为变量且变量均为浮点型:ble;若均为变量:blt;若存在一个常量(即其他情况):ble。
(e)若第1个子树binaryOp的比较符号为“>”:ble。
(f)若第1个子树binaryOp的比较符号为“<=”:若变量为浮点型:ble;其他情况:bgt。
(g)若第1个子树binaryOp的比较符号为“<”:若均为变量且变量均为浮点型:ble;若均为变量:bge;若存在一个常量(即其他情况):bgt。
(4)根据if语句条件为true情况下函数块信息生成对应的汇编指令序列:遍历该抽象语法树,根据各个节点类型,生成相应的汇编语言指令序列。
(5)若存在第3个子树else函块,则生成1条无条件跳转指令:b。
(6)根据if语句条件为false情况下函数块信息生成对应的汇编指令:遍历该抽象语法树,根据各个节点类型,生成相应的汇编语言指令序列。
图1给出了if节点翻译为汇编指令序列排列的逻辑原理。
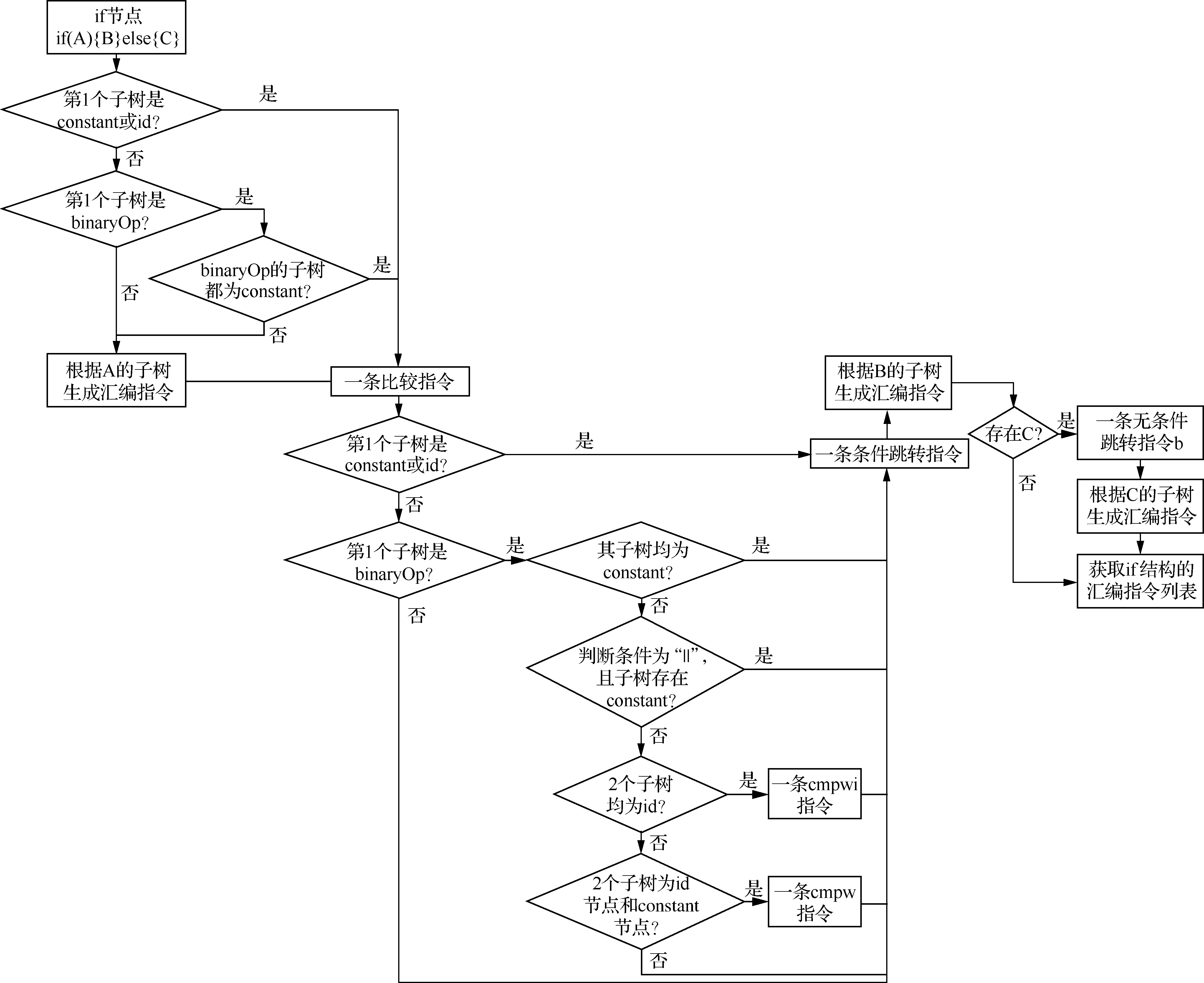
图1 if节点映射规则图Fig.1 Diagram of correspondece of if node to rule
② for循环节点
对于C源程序的抽象语法树的for节点,简式标记为“for(A;B;C){D}”,生成的汇编语言指令序列规则为
(1)根据代码块A信息生成对应的汇编指令序列:
(a)A为变量:lwz。
(b)A为其他数据类型:根据A节点类型对应的规则生成程序块A对应的汇编指令序列。
(2)一条跳转指令:b。
(3)若存在代码块D:根据D节点类型对应的规则生成程序块D对应的汇编指令序列;否则不产生汇编指令。
(4)若存在代码块C:根据C节点类型对应的规则生成代码块C对应的汇编指令序列。
(5)若存在代码块B:根据B节点类型对应的规则生成代码块B对应的汇编指令序列。
3) 跳转类节点
① 返回节点return
对于C源程序的抽象语法树的return节点,生成的汇编语言指令序列规则为
根据函数体返回类型信息生成对应的汇编语言指令序列:
(1)若函数体返回类型为void:
(a)若返回值为空:li、stw。
(b)若返回值不为空:不添加汇编指令。
(2)若函数体返回类型为整型:
(a)若返回值为常量:li。
(b)返回值为变量:lwz。
(3)若函数体返回类型为字符型:lbz,clrlwi。
(4)若函数体返回类型为浮点型:lwz,mtctr。
② 循环终止节点break
对于C源程序的抽象语法树的break节点,规则为生成一条b指令,表示无条件跳转。
4) 运算类节点
① 二元运算符binaryOp
对于C源程序的抽象语法树的binaryOp节点,简式为:“A?B”。其中“?”代表“>”“ < ”“ ==”“!=”“ +”“ -”“ *”“/”等运算符号。生成的汇编语言指令序列步骤为:
步骤1识别binaryOp节点中存储的运算符,如果是“>”“ <”“ ==”“ !=”则跳转至步骤2,执行步骤2~步骤4;如果为“+”“ -”“ *”“/”则跳转至步骤5~步骤7。
步骤2识别程序中B对应的抽象语法树,遍历该抽象语法树的各个节点类型,生成相应的汇编语言指令序列。
步骤3识别程序中A对应的抽象语法树,遍历该抽象语法树的各个节点类型,生成相应的汇编语言指令序列。
步骤4一条比较指令cmpw。
步骤5识别程序中A对应的抽象语法树,遍历该抽象语法树的各个节点类型,生成相应的汇编语言指令序列。
步骤6识别程序中B对应的抽象语法树,遍历该抽象语法树的各个节点类型,生成相应的汇编语言指令序列。
步骤7识别binaryOp节点中存储的运算符,如果是“+”则添加一条add指令;如果是“-”则添加一条subf指令;如果是“*”则添加一条mullw指令;如果是“/”则添加一条divw指令。
② 单目运算节点unaryOp
C源程序中单目运算符生成汇编语言指令集合的规则。对于C源程序的抽象语法树的unaryOp节点,简式为:“a++”“ --a”“ &a”“ -a”“ !a”“ ~a”“ *a”,生成的汇编语言指令序列应为:
步骤1识别unaryOp节点中存储的运算符,若为“*”或“&”,直接跳转至步骤4。
步骤2一条lwz指令,用于将a加载进寄存器。
步骤3识别unaryOp节点中存储的运算符,如果为“++”“--”则添加一条add指令,它是“addi”和“add”的统一表示,用于进行自增自减运算;如果为“-”,增添一条neg指令;若为“~”,增添一条not指令;若为“!”,不处理。
步骤4一条st指令,用于将寄存器中的结果加载到栈中。
2.4.2 建立PowerPC P2020机器码程序函数体语句序列与C源程序函数体语句之间的追溯关系
基于2.4.1节中 C程序语法结构到PowerPC P2020汇编语言指令序列映射规则的定义,建立函数体之间的追溯关系分以下3个步骤。
1) 针对于C源程序,利用pycpaser开源库生成其抽象语法树ast(伪代码第50行)。伪代码95~102行通过遍历ast的抽象语法树节点,并结合2.4.1节中构建的规则库生成期望汇编指令序列,并以函数体为单位将生成的期望指令序列存储在sourceFuncAssemSet数组中。期望汇编指令序列中子项的节点格式为[cmd, coord],其中cmd存储期望汇编语言指令序列助记符,coord中存储对应C源程序中的代码行号信息。
2) 针对PowerPC P2020机器码程序,伪代码第50行利用“powerpc-linux-gnu-objdump-d-lfilename”命令解析机器码程序文件,提取出函数名、汇编语言指令序列以及对应C源程序中的代码行号信息。伪代码第70~94行以函数体为单位,将编译器生成的相应函数的汇编语言指令序列存储在targetFuncAssemSet数组中。
3)建立PowerPC P2020机器码程序函数体语句序列与C源程序函数体语句之间的追溯关系:
① 为方便计算其匹配率,算法将每一个汇编指令用唯一的ASCII码值替换,并保存汇编指令与ASCII码转换的映射字符表(伪代码第103行)。
② 对比实际汇编指令序列以及期望汇编指令序列对应的字符串,若完全匹配,则匹配率为100%;若存在不匹配的字符,则匹配率为匹配的字符个数/字符总个数。
③ 根据映射字符表,回溯对应的汇编指令。字符串中互相匹配的字符即为实际汇编指令序列与期望的汇编指令序列中互相匹配的汇编指令。
2.5 库函数的溯源
1) 动态链接库函数的溯源。对于动态链接的库函数,首先需要存放常用动态链接库的源码,当ELF文件头中表明所依赖动态链接库时,需要根据对应动态链接库的源码,按照2.4节机器码文件函数体代码与源文件函数体代码的映射方法进行匹配即可,以验证该动态链接库是否存在问题。
2) 静态链接库函数的溯源。当机器码文件函数体内部存在连续的汇编代码行不能与期望汇编指令序列匹配时,需要验证该段代码是否为直接展开的库函数。对于直接展开的库函数,需要预先加载当前C源程序引用的函数库。匹配方法与2.4节函数体匹配相似,但不需要建立C程序语法结构到PowerPC P2020汇编语言指令序列映射规则,只需要对展开前函数库的二进制代码进行反汇编作为期望汇编指令序列,然后与机器码文件中未能匹配的连续汇编代码行(即内嵌的库函数)进行匹配即可,以验证编译器是否在静态链接时对汇编指令进行修改。
3 实验验证
3.1 实验环境搭建
本文采用ubuntu20.04和python3.8,根据图2的实验流程,编程实现用于实验验证的实验环境(命名为:NwpuSrcTrace)。NwpuSrcTrace以C源程序文件和PowerPC P2020机器码文件作为输入,通过可视化界面输出机器码和C源程序在文件、函数声明和函数体代码的追溯结果。
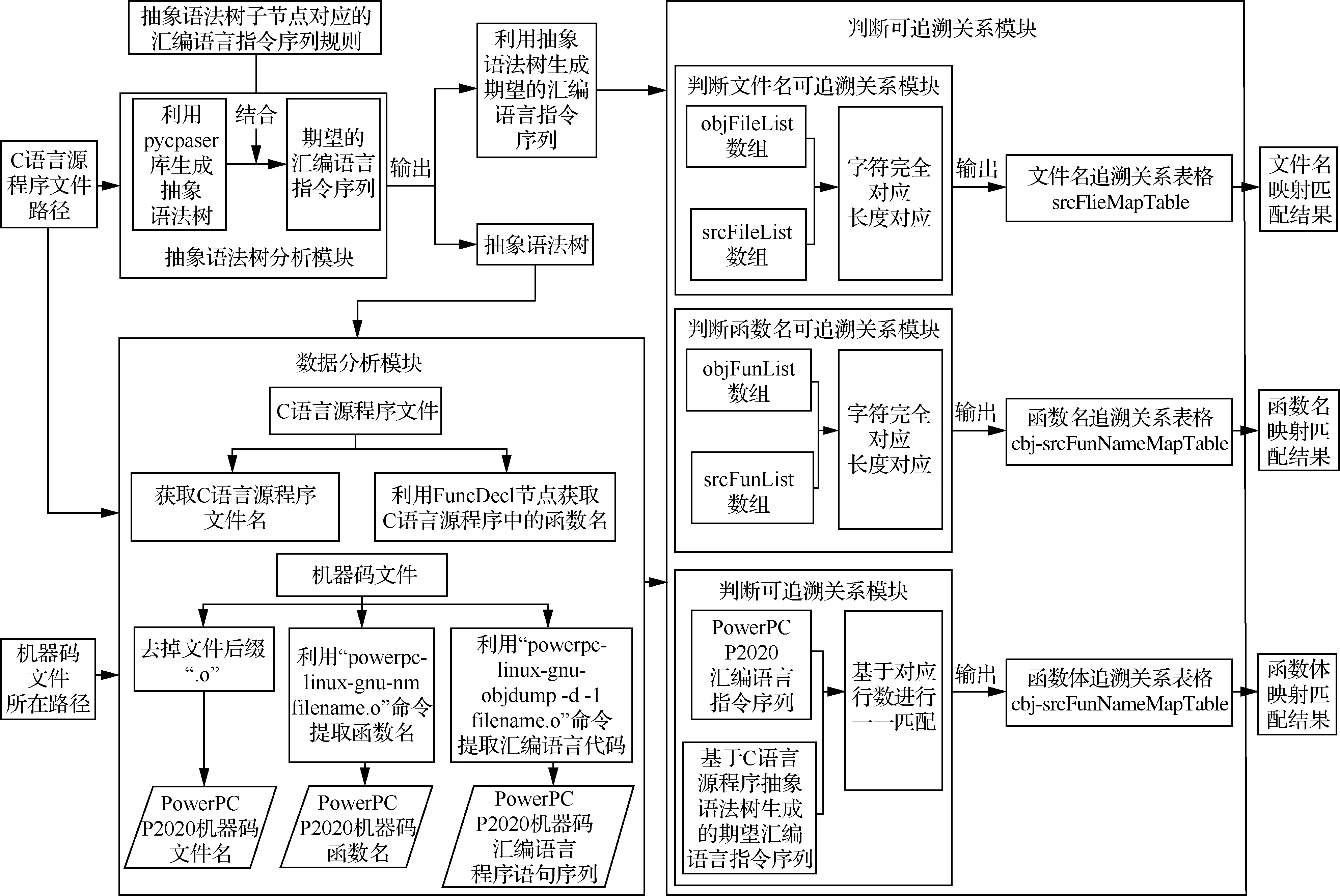
图2 实验验证流程Fig.2 Experimental verification process
3.2 测试用例
1) 文件主名溯源测试用例
为验证文件溯源方法的有效性,论文设计了245个C源程序文件和与345个PowerPC P2020机器码文件,其中100个机器码文件设计为无法匹配到C语言源文件。
2) 函数名溯源测试用例
为验证函数声明溯源方法的有效性,论文设计了1 111个C语言函数声明与1 273个PowerPC P2020机器码函数声明,其中162个机器码函数声明无法找到对应的C语言源文件中的函数声明。
3) 函数体溯源测试用例
为验证函数体代码溯源的有效性,论文覆盖C语言程序的23类抽象语法树节点,分别设计了20个C源程序文件和相应的20个PowerPC P2020机器码程序文件,共计460个测试用例进行函数体代码溯源实验。表1列举了函数声明decl、if、for和while等部分抽象语法树节点对应的C源程序测试用例。为便于读者查看完整的测试用例,详见https:∥gitee.com/angelavor/cto。

表1 部分节点C源程序实验对象
3.3 实验步骤
1) 导入源文件和机器码文件
将C源程序文件存储在指定文件夹中,利用风河Workbench嵌入式开发平台GCC编译器(航空领域应用常用编译器)对C源程序文件进行编译,得到对应的PowerPC P2020机器码程序文件,并存储在相应工程文件夹中。运行实验环境NwpuSrcTrace中的home.py程序,启动可视化界面,导入C源程序文件与PowerPC P2020机器码程序文件。
2) 机器码文件溯源
点击溯源菜单, “文件主名溯源”“函数名溯源”和“函数体溯源”功能可以分别输出文件名(如图3所示)、函数名(如图4所示)和函数体代码(如图5所示)的追溯清单。
文件主名溯源界面(图3)中,上方为源文件列表与机器码文件列表。下方的文件主名溯源结果显示匹配信息与文件主名。
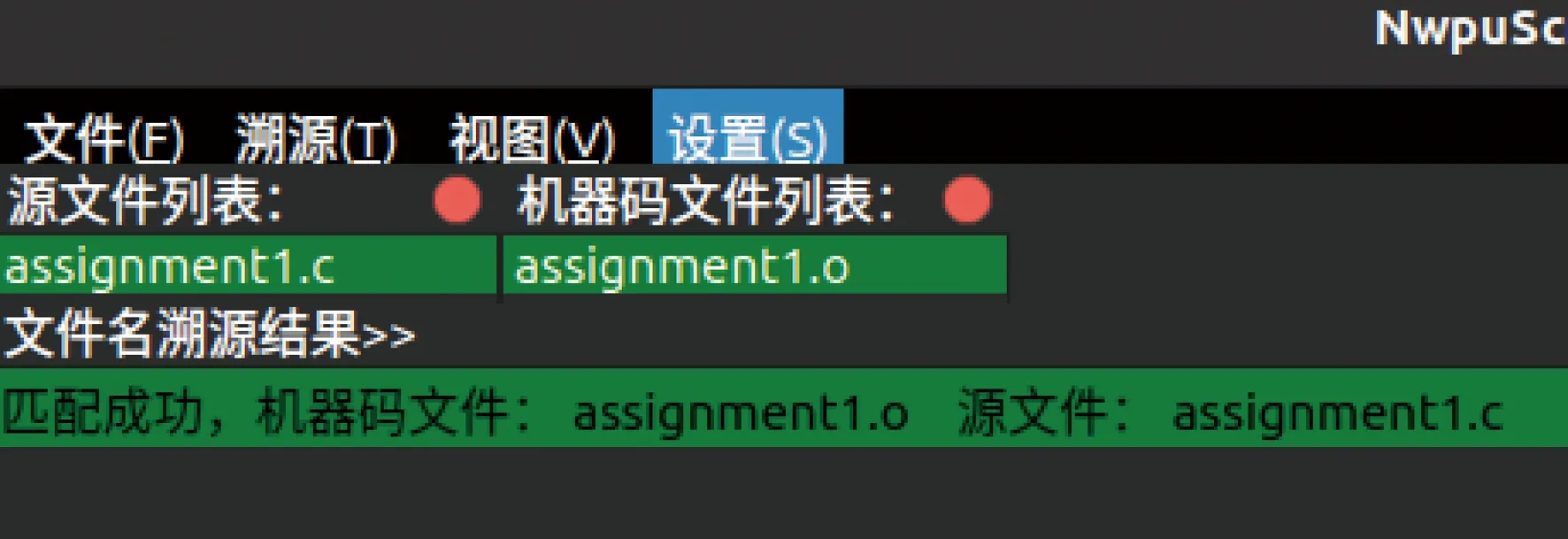
图3 文件溯源结果输出界面Fig.3 File traceability output interface
函数名溯源界面(图4)中,右侧上方显示为机器码函数的汇编指令列表。下方的函数名溯源结果显示匹配信息、函数名以及函数所在文件主名。

图4 函数声明溯源结果输出界面Fig.4 Output interface of function definition tracing results
函数体溯源界面(图5)中,右侧上方为机器码函数对应的汇编指令列表。界面下方的函数体溯源结果显示以函数体为单位的匹配率。

图5 函数体溯源结果输出界面Fig.5 Output interface of function body tracing results
3.4 实验结果分析
1) 文件溯源结果
图6为系统导出的共590个文件溯源结果的部分截图,其中包括匹配成功/失败信息、C源程序文件主名信息和PowerPC P2020程序文件主名信息。目前文件主名溯源方法已达到100%准确率。

图6 文件溯源测试结果展示Fig.6 Display of file traceability test results
2) 函数声明溯源结果
图7为系统导出的共2 384个函数名溯源方法的部分测试结果,其中包括匹配成功/失败信息、该函数名所在C源程序文件主名或该函数名所在PowerPC P2020程序文件主名信息。目前函数声明溯源已达到100%的准确率。

图7 函数名溯源测试结果展示Fig.7 Display of function name traceability test results
3) 函数体代码行溯源结果
表2给出了覆盖23类抽象语法树节点的C程序溯源测试结果:第1列为抽象语法树节点,第2列为节点含义的描述,第3列为测试用例介绍,第4列为C语言函数体与机器码函数体部分代码示例,第5列为函数体代码溯源的匹配率。实验结果表明,除少数节点类型匹配率较低外,其余节点的匹配率较高,函数体代码的平均成功匹配率为97.22%。匹配率低的节点涉及到复杂数据类型,如长整型long、浮点型float和双精度浮点型double。编译器对浮点和双精度数据类型的处理是动态的并依赖于计算机的硬件环境,同时编译器会对部分运算进行合并优化操作。例如:针对“b=a*2”语句,根据抽象语法树节点对应规则,BinaryOp节点的运算符号为“*”,对应的汇编语言指令为“mullw”,但是在实际编译过程中,编译器会将其编译为加法运算,即“+”对应的“addi”指令。这些情况会导致匹配度无法到达预期的情况,仍需要人工对溯源结果进行审核。

表2 函数体代码行的溯源测试结果Table 2 Traceability test results for function body code
实验环境NwpuSrcTrace可以实现自动化溯源文件、函数声明和函数体代码,能较好地实现C源码和编译后PowerPC P2020机器码的可追溯性,详细展示机器码和源码的匹配情况,缩减人工追溯C源码和编译后的PowerPC P2020机器码关系的时间与经济成本。
4 结论和展望
本文提出了一种由PowerPC P2020处理器平台的机器码工程文件到C语言源代码工程文件的追溯性分析方法,用户可以从文件映射、函数声明映射、函数体模块映射3个方面获取PowerPC P2020机器码工程文件到C源代码工程文件的追溯关系,函数体代码的平均追溯匹配率达97.22%,文件和函数声明溯源的追溯匹配率达100%。

续表7

续表7
本文研究目标是验证编译器在编译过程中是否插入异常代码,在工程实践过程中,可以将得到机器码程序的过程分为编译过程、验证过程、裁剪过程等3个过程。在编译过程中,通过参数控制编译器生成带符号表的ELF文件,即本文中的.o文件。在验证过程中,使用本文所述方法验证生成程序的正确性。在裁剪过程中,使用裁剪工具对验证后的程序进行裁剪。因为裁剪过程是在追溯机器码程序的正确性后再进行,因此在资源受限的嵌入式领域,生成的二进制文件即使经过裁剪,以及溯源所用的符号表可能会被删除,也不会影响到本文的验证方法。所以本文方法在实践中是可行的。
在现有成果的基础上,未来可以从以下4个方面继续进行深入研究:
1) 针对浮点数和双精度带来的部分节点匹配率低问题,未来将通过分析源码、存储符号及类型的办法解决。
2) 目前实验结果是覆盖23类抽象语法树节点的C程序单元测试的溯源,未来工作采用嵌入式航空领域包含C语言复杂嵌套数据结构的常用函数库和相关开源软件作为集成测试集,对提出的方法进行集成测试,进一步验证方法的有效性。
3) 在C程序语义分析的基础上进一步探索不同编译优化选项影响下的代码溯源问题。目前编译器的优化选项有O0、O1、O2、O3、Os 这5种,编译器默认使用的是O2优化选项,本文的实验结论也是基于O2优化选项。如果修改优化选项,会对论文目前的实验结果产生一定的影响,对于修改优化选项后未能溯源的代码,需要通过人工方式进行溯源分析。本文方法仍能辅助人工完成大部分机器码溯源任务,降低全部机器码溯源所花费的时间,满足机载软件适航要求。
4) C/C++是目前机载软件开发的主要语言选择项,后续将针对C/C++中更复杂的嵌套数据结构和函数,开展进一步研究,并根据实验环境已留出的选择不同处理器及编程语言的开放接口,使提出的溯源方法推广适配到其他平台处理器以及C++编程语言。
猜你喜欢
科普童话·神秘大侦探(2023年1期)2023-05-30 12:48:10
时代英语·高一(2019年1期)2019-03-13 10:29:48
时代英语·高三(2019年1期)2019-03-13 10:29:26
测控技术(2018年5期)2018-12-09 09:04:26
电子测试(2018年18期)2018-11-14 02:30:34
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
时代英语·高三(2018年1期)2018-02-23 19:33:53
