
基于注意力机制的车辆目标检测算法研究
2021-10-19 13:28罗建晨杨蕾
现代信息科技 2021年6期
关键词:注意力机制
罗建晨 杨蕾

摘 要:在智能交通系统中,车辆目标检测有广泛应用。为了提高车辆目标检测性能,采用基于FPN的YOLOv3算法进行车辆多目标检测,并且通过添加注意力机制模块进行网络优化,提出了一种基于空间注意力机制SAM的YOLOv3车辆多目标检测优化算法,并在所构造的车辆多目标数据集上对提出的算法进行了验证,证明其对车辆多目标检测的优势。实验表明,优化后的检测算法相比原检测算法模型参数量降低了55.36%,mAP值提升了1.15%,优于原检测算法。
关键词:车辆目标检测;注意力机制;YOLOv3;SAM
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2021)06-0103-04
Research on Vehicle Target Detection Algorithm Based on Attention Mechanism
LUO Jianchen,YANG Lei
(School of Electronic and Information,Zhongyuan University of Technology,Zhengzhou 450007,China)
Abstract:Vehicle target detection is widely used in intelligent transportation system. In order to improve vehicle target detection performance,the FPN-based YOLOv3 algorithm is used for vehicle multi-target detection,and the attention mechanism module is added to optimize the network. An optimized YOLOv3 vehicle multi-target detection algorithm based on spatial attention mechanism(SAM)is proposed. The proposed algorithm is verified on the constructed vehicle multi-target dataset,which proves its advantage in multi-target vehicle detection. The experimental results show that compared with the original detection algorithm,the model parameters of the optimized detection algorithm are reduced by 55.36%,and the mAP value is increased by 1.15%,which is better than the original detection algorithm.
Keywords:vehicle target detection;attention mechanism;YOLOv3;SAM
0 引 言
目標检测是计算机视觉的一个重要研究方向,是一种基于目标特征的图像分类和识别方法。在对交通目标进行动态检测和跟踪的智能化交通系统中具有广泛的应用价值,如车速智能监控与测量、自动驾驶行为识别等[1]。由于目标检测算法对不同目标的适应性不同,故需要选择适于交通目标检测的检测算法,并对其进行优化研究。
现代目标检测算法是基于卷积神经网络(Convolutional Neural Network,CNN)的,旨在通过自动学习图像高层特征,从图像中检测出感兴趣的目标,准确判断出每个目标的类别,并用检测框标记出每个目标所在的位置[2]。
特征提取主干网络是目标检测网络的基础,其作用是生成反映不同层次图片信息的、具有不同尺度的特征图,其中,低层特征图分辨率高,位置信息准确,可以较好地关注小目标的特征,但是包含的语义信息不丰富;高层特征图分辨率低,包含的语义信息丰富,可以充分地提取大目标的特征,但是位置信息粗糙、容易忽略小目标。在交通目标检测的应用场景中,由于车速较快,车辆及车辆上的检测目标在视频图像中的大小会迅速变化,这构成一个多尺度变化的目标检测问题,因此需要选取恰当的特征层利用方式。
根据特征图的利用方式不同,目标检测网络分为三类:基于单层特征图、基于金字塔型特征层级、基于特征金字塔网络(Feature Pyramid Network,FPN)[3]。基于单层特征图的目标检测网络仅使用单个最高层特征图进行预测,检测速度快,但是仅利用最后一层高层特征,分辨率低,不利于小目标检测。基于金字塔型特征层级的目标检测网络利用多个不同层次、不同尺度的特征图进行预测,检测速度快,但是没有使用已经计算出的低层高分辨率特征图,也不利于小目标检测。基于FPN的目标检测算法利用多个不同层次、不同尺度的特征图,对每一层的特征图分别自上而下进行特征融合,使新的特征图包含高层特征图的信息,充分补充低层的语义信息,获得高分辨率、语义信息丰富的特征,能出色完成小目标检测的任务,更适于完成交通目标检测的任务。
注意力机制符合人脑和人眼的感知机制,本质是更加关注感兴趣的信息,抑制无用信息。注意力模块分为空间注意力模块、通道注意力模块、混合注意力模块三类,其中,空间注意力模块的任务是寻找单层特征中包含有效信息的2D空间位置,通道注意力模块的任务是寻找不同特征通道中包含有效信息的通道位置,混合注意力模块的任务是同时寻找不同特征通道中包含有效信息的通道位置以及每个通道中包含有效信息的2D空间位置[4,5]。在目标检测网络中,可以使用注意力模块对网络结构进行优化,将更多的权重分配给包含有效信息的区域,同时减小包含干扰信息区域的权重,从而进一步提高交通目标检测的精度。
本文面向交通目标检测的应用场景,优选了一种基于FPN的YOLOv3车辆多目标检测算法,然后又提出了一种基于空间注意力机制(Spatial Attention Mechanism,SAM)的YOLOv3车辆多目标检测优化算法,并在所构造的车辆多目标数据集上对提出的算法进行了验证,证明其对车辆多目标的检测性能优于现有算法。
1 车辆多目标数据集构造
本文训练使用的数据集是车辆多特性数据集,数据集由四部分构成,分别是OpenITS数据集、BIT Vehicle数据集、CCPD数据集和本实验室自主采集的数据集。从Open ITS数据集[6]中随机选择了6 103张分辨率为1 600×1 200的车辆图片、从BIT Vehicle数据集[7]中随机选择了1 921张分辨率为1 920×1 080的车辆图片、从CCPD[8]数据集中随机选择了280张分辨率为720×1 160的车辆图片,用尼康相机d3200 SLR采集了3 351张分辨率为6 000×4 000的车辆图片,并且用海康威视摄像头MV-CA050-11UC采集了480张分辨率为2 448×2 048的车辆图片,共12 135张车辆图片。
2 基于注意力机制的YOLOv3车辆多目标检测算法
基于FPN的目标检测算法适合解决交通目标检测应用场景中多尺度变化的目标检测问题。因此,选择基于FPN的目标检测算法对车辆及其上的多个目标进行检测,其中,YOLOv3以更高的检测速度和精度,成为优先选择的网络,图1是基于YOLOv3的车辆多目标检测算法原理框图。
输入的车辆场景图片经过特征提取主干网络Darknet53提取特征,提取的特征经过FPN结构完成不同尺度特征图的融合,最终利用13×13,26×26,52×52三个不同尺度的特征图进行预测,获得车辆多特性的检测框、类别和置信度。
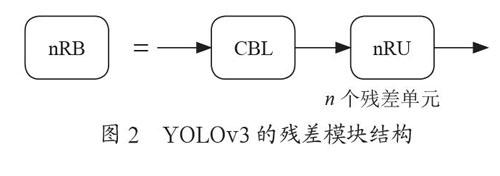
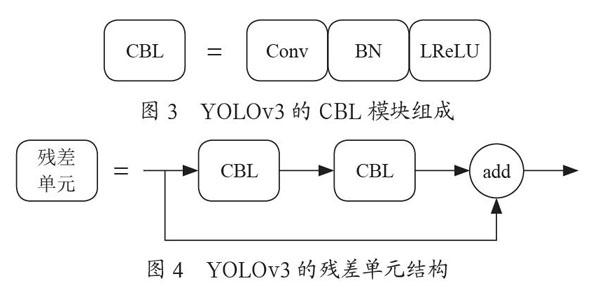
Darknet53一共有23个残差模块,残差模块如图2所示,残差单元能有效解决网络层数增多时出现的梯度消失和过拟合现象。CBL模块由Conv函數、标准化(Batch Norma-lization)和LReLU(Leaky-ReLU)激活函数构成,如图3所示。残差单元的结构如图4所示,输入的特征图经过两次卷积操作之后与原特征图相加。
在图3中的CBL模块中,卷积核的尺寸为3×3和1×1,假设卷积核对应的输入维度为Cin,输出维度为Cout,需要的总参数量为Cin×Cout×3×3+Cin×Cout×1×1。为了减少参数量,本文分别采用空间注意力模块SAM、通道注意力模块SE、混合注意力模块CBAM代替常规的卷积模块,对YOLOv3车辆多目标检测算法的网络结构进行了改进,如图5所示。
3 实验与结果分析
在训练模型的时候,为了控制变量对比模型的性能,将每次模型训练的epoch设置为相同,并且使用相同的数据集。模型训练参数如表1所示。本文进行训练时所使用的GPU是技嘉GeForce GTX 2080Ti,显存为11 GB,CPU是Intel E5 2678 V3。
从表2可以看出,在模型尺寸都为416×416的情况下,YOLOv3的模型参数量为236.32 MB;SAM-YOLOv3的模型参数量为105.50 MB,模型压缩了55.36%;SE-YOLOv3的模型参数量为108.80 MB,模型压缩了53.96%;CBAM-YOLOv3的模型参数量为112.12 MB,模型压缩了52.56%,由以上数据可知SAM-YOLOv3的模型参数量最小。
在实验过程中,选择相同的模型训练参数,用于衡量检测准确性的指标包括:Precision、Recall、AP(Average Precision)。其中,Precision是精确率,表示模型检测结果中正确的目标样本所占的比率;Recall表示召回率,表示目标正样本被正确检测的占总体样本的比率,如式(1)和(2)所示:
(1)
(2)
AP综合考虑了Precision和Recall的变化,等于Precision- Recall曲线所包围的面积,如式(3)所示:
(3)
mAP等于所有物体的类的AP之和与所有物体类别的总和的比值,如式(4)所示:
(4)
用于衡量检测效率的指标是FPS,即模型每秒钟可以处理的图片数量。
实验结果如表3所示。可以看出,从对整车、车牌、车灯、车镜的检测AP分析,SAM-YOLOv3的检测性能明显优于YOLOv3;从对车标的检测AP分析,SAM-YOLOv3的检测性能略低于YOLOv3;但从mAP分析,SAM-YOLOv3的平均检测性能明显优于YOLOv3,也明显优于作为对比的SE-YOLOv3和CBAM-YOLOv3;从FPS分析,SAM-YOLOv3的检测速度明显优于YOLOv3,也明显优于作为对比的SE-YOLOv3和CBAM-YOLOv3。
综上所述,SAM-YOLOv3检测算法性能和检测速度均优于YOLOv3,也均优于对比算法SE-YOLOv3和CBAM-YOLOv3。因此,通过实验验证确定并提出了该基于SAM的YOLOv3车辆多目标检测优化算法。
4 结 论
车辆目标的正确检测对智能交通监控系统有重大意义。在行驶过程中不同距离处的车辆目标存在多尺度问题,给准确检测带来了巨大挑战。本文针对此问题选择了基于FPN型的YOLOv3作为车辆目标的目标检测算法;然后在所选的YOLOv3车辆目标检测算法的基础上,融合了SAM进行优化,提出了一种基于SAM的YOLOv3车辆目标检测算法,并通过实验结果验证了所提出的算法在模型参数量缩减、模型检测精度改善、模型检测效率提高方面所表现出的优势。
参考文献
[1] 肖雨晴,杨慧敏.目标检测算法在交通场景中应用综述 [J].计算机工程与应用,2021,57(6):30-41.
[2] JIAO L C,ZHANG F,LIU F,et al. A Survey of Deep Learning-based Object Detection [J].IEEE Access,2019,7:128837-128868.
[3] LIN T Y,DOLLAR P,GIRSHICK R,et al. Feature Pyramid Networks for Object Detection [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:936-994.
[4] HU J,SHEN L,SAMUEL A,et al. Squeeze-and-Excitation Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,42(8):2011-2023.
[5] WOO S,PARK J,LEE J Y,et al. CBAM:Convolutional Block Attention Module [C]//ECCV:European Conference on Computer Vision.Munich:Springer,2018:3-19.
[6] OpenITS. OpenData V11.0-車辆重识别数据集 VRID [EB/OL].[2021-02-11].https://www.openits.cn/openData4/ 748.jhtml.
[7] DONG Z,WU Y W,PEI M T,et al. Vehicle Type Classification Using a Semisupervised Convolutional Neural Network [J].IEEE Transactions on Intelligent Transportation Systems,2015,16(4):2247-2256.
[8] XU Z B,YANG W,MENG A J,et al. Towards End-to-End License Plate Detection and Recognition:A Large Dataset and Baseline [C]//ECCV:European Conference on Computer Vision.Munich:Springer,2018:261-277.
作者简介:罗建晨(1993—),男,汉族,河南信阳人,硕士研究生在读,主要研究方向:计算机视觉,深度学习;杨蕾(1979 —),女,回族,河南洛阳人,教授,博士,主要研究方向:图像处理,计算机视觉。
猜你喜欢
计算机应用(2019年3期)2019-07-31
无线互联科技(2019年9期)2019-07-29
无线互联科技(2019年9期)2019-07-29
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
