
基于深度融合残差网络的驾驶员眼睛状态检测
2021-10-19 02:55:50王国栋王增才范佳城
机械设计与制造工程 2021年9期
王国栋,王增才,范佳城
(1.山东大学机械工程学院,山东 济南 250061) (2.山东大学高效洁净机械制造实验室教育部重点实验室,山东 济南 250061) (3.山东大学机械基础实验教学中心国家级实验教学示范中心,山东 济南 250061)
驾驶员眼睛状态检测是驾驶员疲劳检测的重要组成部分,有效的眼睛状态检测算法为驾驶员眨眼频率及闭眼时间等与疲劳相关的眼部参数的计算提供了基础。目前用于眼睛状态检测的方法包括4种:基于运动的眼睛状态检测[1]、基于特征的眼睛状态检测[2-3]、基于外观的眼睛状态检测[4-5]和基于深度学习的眼睛状态检测[6-7]。基于运动的眼睛状态检测方法通过检测眼睛视频中眼睑运动的时空特征对眼睛状态进行检测。基于特征的眼睛状态检测方法通过模板匹配和眼部特征实现对眼睛状态的检测。 这两种方法在实际运用中鲁棒性较差,眼部图像质量的好坏会严重影响检测准确率。基于外观的眼睛状态检测方法通过提取眼部信息对眼睛状态进行检测。文献[4]提出了多尺度直方图(MultiHPOG)以用于检测眼睛状态,该方法需要手动提取眼睛特征,此过程会消耗实验人员大量时间。随着深度学习的迅速发展[8-9],一些基于深度学习的方法相继被提出,其通过深度卷积神经网络对眼睛图像进行信息分析,最终通过分类器对眼睛状态进行判别。文献[6]建立了深度集成神经网络(DINN)用于检测眼睛状态。文献[7]提出了多尺度汇集卷积神经网络(MSP-Net)用于检测眼睛状态。然而基于深度学习的方法由于其计算量较大、参数量较多,降低了检测速度,因此限制了其在实际环境中的应用。为此,本文提出了深度融合残差网络(deep fusion residual network,DF-ResNet),用于在实际驾驶环境中快速、准确地检测驾驶员的眼睛状态。
1 深度融合残差网络框架
本文提出的整体网络架构如图1所示。首先对驾驶员面部图像进行人脸对齐,然后提取眼睛特征点坐标值并裁剪出眼睛区域图像,最后将经过数据预处理后的特征与图像输入到预先训练好的DF-ResNet网络进行眼睛状态检测。
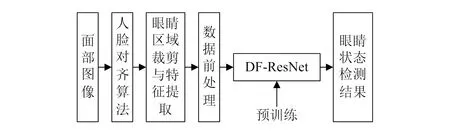
图1 整体网络架构图
1.1 眼睛区域裁剪与特征提取
在进行驾驶员眼睛状态识别时,神经网络的输入只需要驾驶员眼睛区域图像及特征即可,因此需要从驾驶员的面部视频图像中裁剪出眼睛区域并提取特征。在进行图像裁剪及特征提取之前,需要采用人脸对齐算法对驾驶员的眼睛区域进行定位,本文采用了基于回归树集合[10]的方法,该方法在执行人脸对齐时速度快、稳定性好,并解决了以往人脸对齐检测器参数相对难以调整的问题,同时当检测器的训练集中某些关键点校准不足时,该检测器仍然表现良好。部分人脸对齐后图像如图2所示。在完成人脸对齐后,需要根据标记出的人脸关键点对输入图像进行眼睛区域裁剪,并提取眼部特征,本文使用的眼睛特征为驾驶员眼睛的6个关键特征点的坐标值。最终裁剪出的眼睛图像的像素尺寸为24×24。

图2 部分人脸对齐后图像
1.2 卷积神经网络
卷积神经网络是一种主要用于处理阵列数据的人工神经网络,其结构主要包含输入层、卷积层、池化层、全连接层(或全局平均池化层)以及输出层。卷积层是特征提取层,用于提取和计算输入的数据并映射到下一层。池化层的目的是对数据进行降维。全连接层将从前一层学习到的特征图映射到样本标记空间。全局平均池化层起到的的作用与全连接层相似,但是其大大降低了模型的计算量和参数量。
1.3 深度模型压缩策略
深度神经网络由于存在参数量及计算量大、模型复杂等缺点,使得深度模型运算开销较大。深度压缩模型具有较少的参数和计算量,在向客户端导出新模型时的开销更小,并且使得模型嵌入式部署的可行性提高。而深度模型压缩策略可以在不显著影响模型性能的基础上,大大降低模型复杂度。因此深度模型压缩策略显得尤为重要。在本文中,使用以下4种压缩策略:
1)卷积核优化。对深度卷积神经网络中卷积核的大小进行调整,同时采用卷积核分解策略。
2)对卷积层通道数进行压缩。在相似检测结果的前提下,尽量降低卷积核的通道数,从而降低模型的参数量。
3)使用全局平均池化层替代全连接层。全连接层的参数量在深度模型中所占的比例很大,而全局平均池化层在达到全连接层相同效果的情况下可以极大减少参数量。
4)降采样层后移。降采样层尽量后移可以生成更大的特征图,从而得到更大的模型容量。
1.4 残差网络
在深度学习领域,模型容量随深度的增加也在增加。但当模型的深度过大时,模型会出现退化现象,此时训练过程中的误差会越来越大。残差网络通过Short-cut连接解决了模型退化的问题,同时减少了深度模型训练的时间,增加了模型的可训练性[11]。Short-cut连接是在标准前馈卷积神经网络的基础上加入一个跳跃连接,从而直接跳过某些卷积层。前馈神经网络和残差网络的对比图如图3所示。
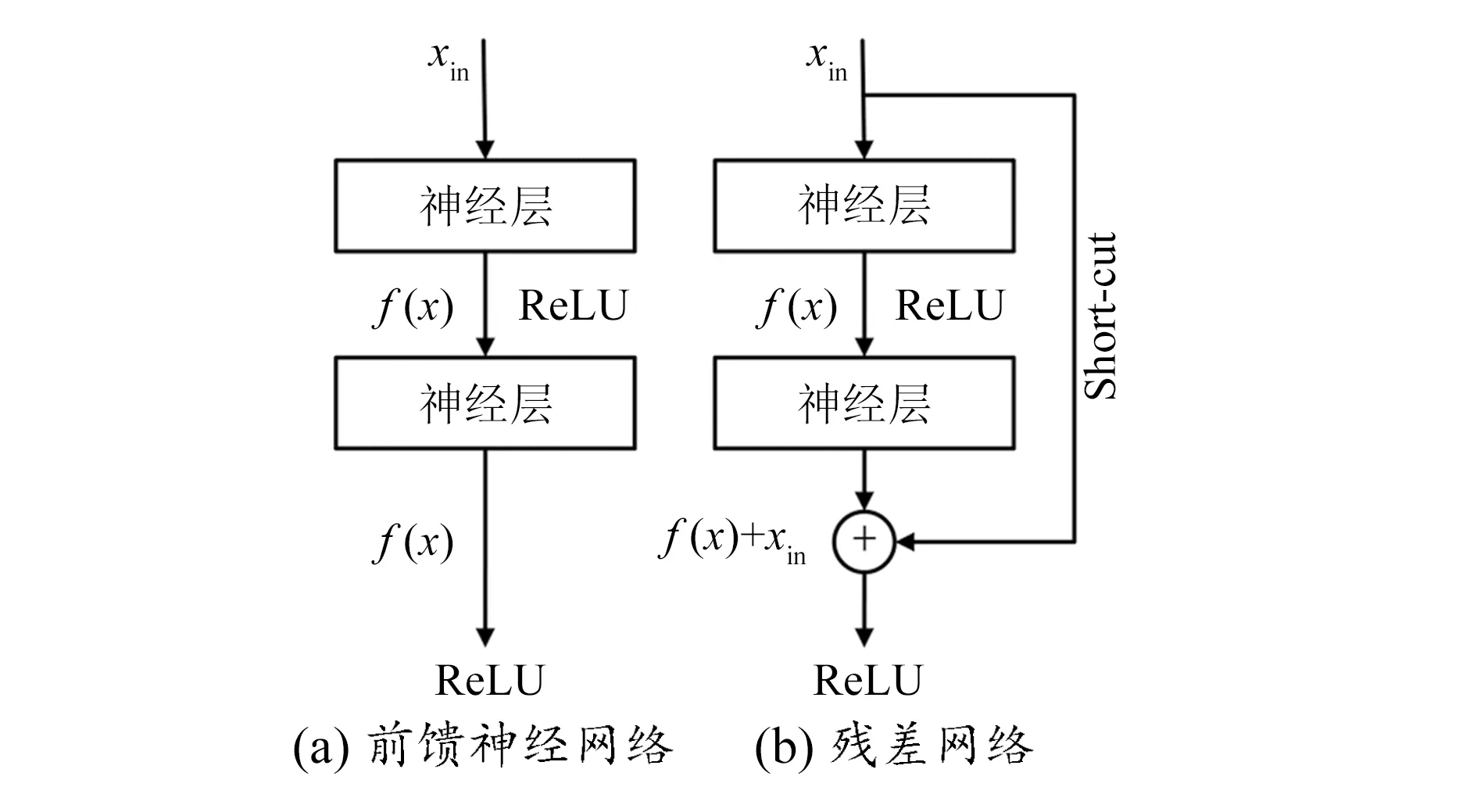
图3 前馈神经网络和残差网络对比图
经过两层前馈神经网络的预测值H(x)计算过程如下:
f(x)=ReLU(b1+xin·w1)
(1)
H(x)=ReLU(b2+f(x)·w2)
(2)
式中:xin为输入特征;w1,w2分别为第一、二神经层的权重;b1,b2分别是第一、二神经层的偏置;ReLU为激活函数。
残差网络中预测值H(x)与x之间存在函数关系,假设两者之间的函数关系满足H(x)=2x,则
H(x)=ReLU(b2+f(x)·w2)+xin
(3)
深度神经网络退化的主要原因是梯度爆炸和梯度消失,而残差网络的出现解决了这一问题。在残差网络中输入与输出存在两个不同的连接关系,一个是输入数据经过多个神经层之后输出,另一个是输入数据直接连接到输出。在进行反向传播时,最终得到的梯度为误差经过两个不同的连接反向传播后得到的和,因此当网络较深时,即使经过若干层神经层反向传播之后得到的梯度很小,但是输出通过Short-cut连接反向传播到输入的梯度值却保持在适当的范围内,从而使梯度爆炸及梯度消失的问题得到有效地解决。同时,残差网络在前向传播时将网络的深层结构变成了并行结构,使得深度神经网络模型容量变大的同时又具有可训练性。
1.5 DF-ResNet网络结构
在眼睛图像处理部分,本文基于多通道卷积、残差网络和深度模型压缩策略,建立起深度卷积神经网络中的细胞单元,如图4所示,细胞单元是深度卷积网络的基本组成单元。其中,最大池化部分采用3×3的最大池化,步数为1。卷积层1代表具有1×1卷积核的卷积层,通道数为72,卷积步数为1;卷积层2代表具有1×3卷积核的卷积层,通道数为72,卷积步数为1;卷积层3代表具有3×1卷积核的卷积层,通道数为72,卷积步数为1。

图4 细胞单元图
基于细胞单元建立深度卷积神经网络,如图5所示。在深度卷积神经网络中,输入层为眼睛图像,第一层为常规卷积层,卷积核大小为3×3,通道数为128;第二到第四层为3个细胞单元,每个单元的输出值经过ReLU函数激活后输入下一层;降采样层为第二层到第四层,充分保证了特征图中信息的多样性。在第四层之后卷积结果与全局平均池化层连接,将学习到的信息映射到样本标记空间,最后通过归一化指数函数(Softmax函数)进行二分类输出。Softmax函数将指数变换后的模型输出值进行归一化,从而转化成(0,1)之间的数,且所有值之和为1,即可以理解为Softmax函数将模型输出值转化为分类概率。最终分类决策时,选取概率值最大的结果作为最终结果。

图5 深度卷积神经网络
对于眼睛特征部分,本文采用深度神经网络,如图6所示。输入层为6个眼睛特征点的横纵坐标值平铺之后的特征向量,即输入层有12个节点,3个隐藏层神经元数量相同,为128个,最后通过Softmax函数进行分类输出,最终输出分为两类:眼睛张开或闭合。神经层激活函数为双曲正切函数。

图6 深度神经网络
在建立完成深度神经网络与深度卷积神经网络之后,建立深度融合残差网络,如图7所示。将眼睛特征点与眼睛图像分别输入到深度神经网络及深度卷积神经网络中进行分析计算,并将两个神经网络的输出结果输入一个神经元进行加权平均,最终输出眼睛状态的检测结果。

图7 DF-ResNet
2 实验结果及分析
2.1 实验环境
本文实验使用的硬件平台为Intel Core i3-3220,主频为3.30 GHz,显卡为GTX1060。软件环境为Spider + TensorFlow 4.5.11。
2.2 数据集和数据前处理
实验中使用两个公共数据集——CEW数据集[4]和ZJU数据集[4],以及一个实际驾驶环境下建立的数据集(DES)。实际驾驶环境中驾驶员眼睛状态数据集建立过程如下:在封闭安全的道路上,对驾驶员和副驾驶员的安全提供有效保证,并收集来自20名实验者的疲劳驾驶图像。所有实验者中,男性驾驶员数量为12名,女性驾驶员数量为8名,驾驶员年龄分布为18~50岁。最终,经过筛选后获得睁眼图像数量为5 450张,闭眼图像数量为4 550张,保存相应图像的特征点坐标值。DES数据集中部分图像如图8所示。

图8 DES数据集中部分图像
由于ZJU与CEW数据集只有图像而没有眼部特征点,因此实验人员对数据集中图像进行手动标定。ZJU数据集预先划分了训练集及测试集,CEW和DES数据集均采用十折交叉验证法对模型进行评估实验。对所有的图像进行最大最小值归一化,消除图像自身差异性。相关公式如下:
(4)
式中:xnorm为归一化后的值;xvalue为图像某一点的像素值;xmin、xmax为图像像素最小、最大值。
2.3 实验结果及分析
为了评估本文所提的网络模型的性能,在3个数据集上,分别与表现最好的MultiHPOG+LTP+Gabor+SVM[4]、DINN[6]和MSP-Net[7]3种方法进行了3组对比实验,对比4种方法在不同数据集上的测试准确率、模型运算速度两项指标。测试准确率是经模型处理后正确分类的眼睛图像数占总图像数的百分比,模型运算速度是基于当前实验平台检测ZJU数据集中一张眼部图像所需时间。
基于ZJU数据集、CEW数据集和DES数据集,对比了本文所提出方法和其他方法的实验效果,实验结果分别见表1、表2、表3。由表可知,基于深度学习的方法相比于基于外观的方法检测效果更好,DINN模型的检测准确率明显优于其他方法,但是相比于本文提出的DF-ResNet网络,仍然有所逊色。DF-ResNet网络在ZJU数据集上的测试准确率达到了98.12%,在CEW数据集上更是达到了98.55%。在DES数据集下,由于光照等外界因素变化复杂,各种方法的检测精度均有所下降。相比之下,本文提出的DF-ResNet网络表现更加稳定,检测精度相对更高,测试准确率达到了96.91%。

表1 基于ZJU数据集的模型评估实验结果

表2 基于CEW数据集的模型评估实验结果

表3 基于DES数据集的模型评估实验结果
基于ZJU数据集,评估了不同方法的时间消耗情况,实验结果见表4。由实验结果可知,本文所提模型不仅测试准确率更高、鲁棒性更好,模型运算速度也明显快于现有的基于深度学习方法,检测单张图像的眼睛状态只需0.68 ms。

表4 时间消耗实验结果
由于深度学习的目标是通过数据学习得到一个最佳的函数近似,因此无论在训练过程中还是在测试过程中均不可能达到100%的检测精度。除此之外,外界环境变化及个人差异性等原因也是造成测试集误检的原因之一,部分误检如图9所示。因此下一步的工作需要在保证模型运算速度的前提下提升鲁棒性。

图9 部分误检图像
3 结束语
本文针对现有用于检测眼睛状态的算法存在鲁棒性差、人力成本高和检测效率低等问题,提出了一个深度融合残差网络,将深度神经网络与深度卷积神经网络进行了融合用以检测实际环境下驾驶员眼睛状态。合理设计的网络结构提升了检测精度,通过优化卷积核、压缩卷积通道、全局平均池化层代替全连接层和降采样层后移等深度模型压缩策略显著提升了模型的检测速度。为了评估所提出的网络模型,本文建立了实际环境下的驾驶员眼睛状态数据集。相关实验结果显示,在ZJU数据集和CEW数据集上该模型的检测精度分别达到了98.12%和98.55%,在DES数据集上的检测精度达到了96.91%。在ZJU数据集上每张图像的检测时间仅为0.68 ms,相比于其他方法提升了眼睛状态检测的精度、鲁棒性和检测速度。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
幼儿教育·父母孩子版(2016年5期)2016-10-08 16:30:28
学苑创造·A版(2016年5期)2016-06-21 01:58:27
儿童故事画报·智力大王(2015年12期)2016-01-23 01:18:11
爆笑show(2015年5期)2015-07-09 19:27:38
