
基于Transformer的新闻情感分析算法
2021-10-18 08:13王天宇张丽珩臧天昊文一涵
现代计算机 2021年24期
王天宇,张丽珩,臧天昊,文一涵
(1.北京工业大学计算机学院,北京100124;2.北京工业大学软件学院,北京100124)
0 引言
文本情感分析是自然语言处理的一个重要的研究方向,由于一词多义、情感转折、反语等现象的存在,导致情感分析较为困难,模型分类效果不理想。而新闻作为一种记录与传播信息的文体,不但篇幅较长,情感的表达也较为分散。文本中既有客观的事实报道,也有主观的情感表达,一个主观句中也可能含有多种情感,这使得新闻文本情感分析成为更具挑战性的任务。由于新闻文本较长,大多需要对其内容进行精简,以便进一步分析。目前的工作的降维方法对于标题和正文各有侧重,但大多没有综合二者考量。此外,融合知识图谱的方法在短文本的情感分析中已经证明其有效性,但是目前有关新闻情感分析的工作大多忽略了外部知识的辅助作用。
针对目前工作存在的不足,本文以网络新闻为研究对象,创新性地提出了基于情感重点句融合知识图谱的Transformer模型分类方法。该方法借助Trans⁃former的Seq2Seq结构,从根本上将新闻分为标题和正文两个独立的部分考虑,既突出了新闻标题的特殊地位,又可以较为全面地把握正文信息。同时,通过知识图谱引入的外部信息,改善了文本信息缺失和二义性等问题。结果表明,该模型可以有效提升情感分析的正确性,且知识图谱是提升新闻文本情感分析模型性能的有效手段。
1 相关研究
文本的情感分析技术有基于情感词典的方法、基于机器学习的方法和基于深度学习的方法三大类。
情感词典是一种判断情感倾向性的传统方法,其依赖于人工总结的情感用词,通过文本用词与情感词典的比对来总体把握文本的情感倾向。显而易见的是,词典中有限列举的情感用词,既不能全面地表征情感用词在不同语境下的语义差别,也无法应对随着时代发展而快速演变的用词习惯。尽管学者们以情感词典为基础,尝试了结合搜索引擎拓展词典,针对语义层次设定不同判断标准,在情感词典中加入表情符号等多种手段[1-2],但文本情感分析效果并不理想。
机器学习方法在分类任务中已有广泛的应用,并同样适用于情感的分类任务。特征工程是分类任务的关键,目前常用的分类特征有:情感词、词性、句法结构、否定表达模板、连接、语义话题等[3],采用文本频率、CHI统计量、互信息、信息增益等方法进行特征选择[4],并使用朴素贝叶斯、支持向量机、神经网络等作为分类器。基于机器学习的方法,相较基于情感词典的方法具有更强的泛化能力,但其分类效果受特征工程的构建影响较大,构建的特征无法表示复杂语义,且需要人工进行数据标注,工作量较大。
深度学习方法与以上两类方法相比,具有明显的优势。这种方法可以自动完成文本特征的抽取和学习,所学习到的特征也更加复杂,可以提高文本分类的正确性。Xu等[5]对LSTM模型进行改进,提出了CLSTM模型,对Context-Level词向量序列进行情感预测,进一步提升了情感极性判断的正确性。梁斌等[6]提出了基于词向量注意力机制,词性注意力机制和位置注意力机制的多注意卷积模型,改善了模型应对情感反转的能力。
新闻文本情感分析不同于一般性文本,由于其篇幅较长而存在大量无情感流露的中立表达,因此,在进行情感分析前大多需要对文本内容进行精简。目前主要有提取文本子集和标题情感分析两种思路:冯亮祖[7]构建了情感关键句抽取算法,在得到的关键句集合的基础上使用CHI统计法构建特征向量,并进一步训练了神经网络和支持向量机作为分类器。李天赐等[8]将新闻标题作为全文的代表,并将标题分为两个半句,构建了前半句、后半句和全标题三输入通道卷积神经网络。以上两种方法各有侧重,但均没有将标题与正文综合考量。
综上所述,结合注意力机制的深度学习模型是解决长文本情感分类的较为有效的处理手段。目前,有关新闻文本情感分析的工作大多缺乏对新闻结构的考量,也没有借助外部知识辅助情感分析。本文针对以上问题提出基于情感重点句融合知识图谱的Transformer模型,改善了情感分析模型性能。
2 基于情感重点句融合知识图谱的新闻文本情感分析算法


其中n为全部重点句包含的词语数。


其中W3∈Rd×q,b3∈Rq,q为情感倾向性类别数。
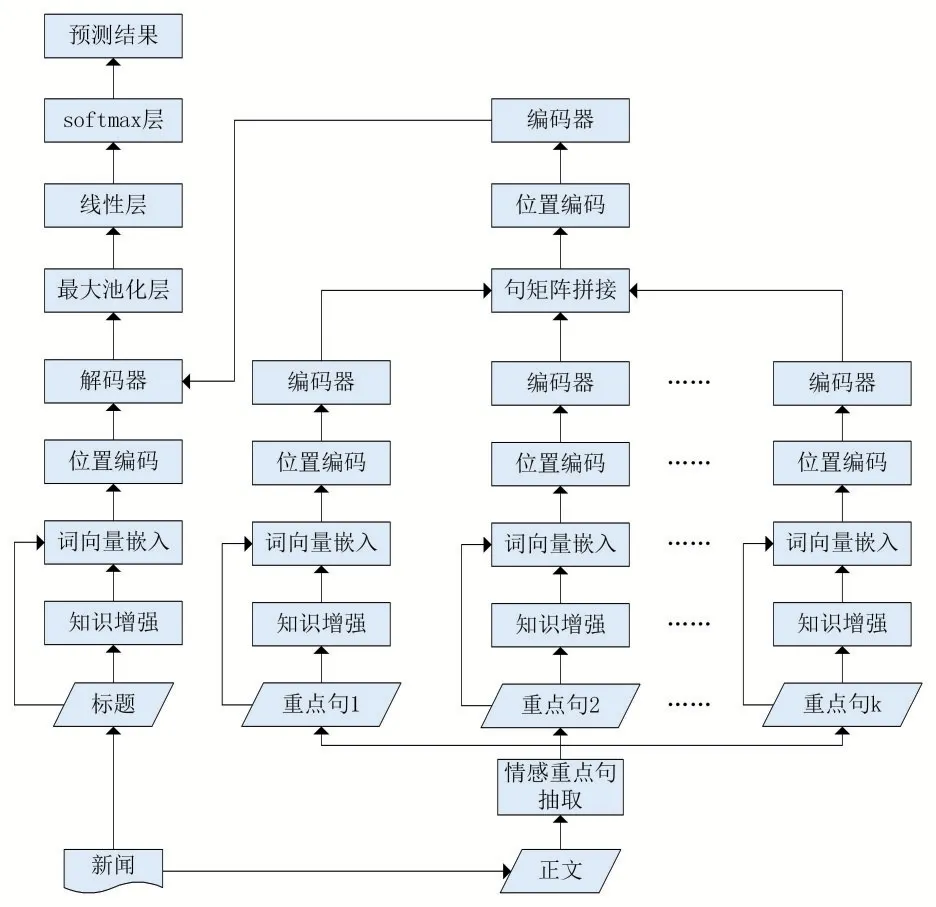
图1基于Transformer的情感分析模型结构
3 多特征情感重点句抽取算法
在前人工作的基础上,本文构建了融合关键词特征、句子位置特征、线索词特征、情感词特征和新闻标题相关性特征的情感重点句抽取算法。通过对上述特征评价指标加权求和,得到综合评价分数,由此衡量各句的重要程度,以便提取重点句,从而降低文本纬度、减少噪音。
3.1 文本预处理
首先,对语料进行了分句、分词和词性筛选处理,删除了连词、拟声词、介词、代词、数词、助词等对文本情感分析无意义的词汇。其中分句的依据为中文常用标点符号,分词与词性筛选使用了Python语言编写的jieba分词工具。
3.2 关键词特征
本文使用了前人提出的关键词特征计算方法[11],由于新闻用词丰富,可能出现一些分词词典以外的词语,为避免遗漏首先使用TF-IDF算法得到新闻的关键词,记为ipw1,词频记为tf1,其对应的集合记为关键词表IP W1,而后使用N-Gram新词发现算法,发现的新关键词记为ipw2,词频记为tf2,其对应的集合记为关键词表IPW2。用于关键词ipw2可能包含ipw1,因此,还需根据IPW2对IPW1进行更新,再将两个关键词表融合得到最终的关键词表IPWfinal,具体生成算法如下所示。

在得到新闻文本的关键词表IPWfinal后,对其赋权以体现重要性的不同。首尾句子数φ确定方法为:φ=0.04m+2。其中m为文章中句子总数。各关键词的权重设置如关键词权重表(表1)所示。若同一个关键词在文章中不同位置出现,则取其权重最高值。最后,得出文章中各句关键词特征值:


表1不同位置关键词权重
3.3 句子位置特征
按文本位置来说,新闻的开头导语与结尾总结部分往往包含与主题相关的重点信息、作者观点以及情感倾向。即在文章开篇提出包含重要信息的提要,中部陈述新闻事实,在文章结尾集中发表观点与态度[12]。因此,文章开头与结尾的句子在情感分析中往往更为重要,由此不同位置的句子需要计算其重要性,即:

其中si表示新闻文本的第i句句子,m为该文本的句子总数。
3.4 线索词特征
作者在表达情感时可能出现:“因此”、“可以预见”、“不难看出”等流露倾向性的线索词,参照以往工作提出的线索词表可以构造各句倾向性表述程度计算公式[11],如下式所示。

3.5 情感词特征
一般来说,句子中包含的情感词越多,其表达的情感倾向越强烈。本研究使用中国知网HowNet与清华大学李军的中文褒贬义词典作为汉语情感词典,根据句子所包含的情感词来衡量句子情感的表达程度,其衡量指标为fewf(si),即:

3.6 标题相关性特征


其中 |h|为标题所含词语数,|si|为第i句所含词语数。
最后,在以上计算的基础上通过计算二者的余弦相似度ftf(si),即:
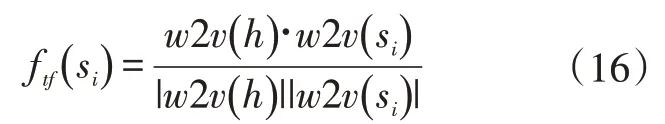
得到标题相关性特征,其中w2v(h)为标题的向量表示,w2v(si)为句子的向量表示。
3.7 特征融合
在上文中,分别考量了关键词特征、句子位置特征、线索词特征、情感词特征以及标题相关性特征,现在,以加权求和的方式对这些特征进行融合,获得文章中句子si最终重要性评分fweight,即:

其中λ代表各特征权重,其总和为1。
上述5个特征权重的取值,如特征权重表(表2)所示。通过对各句重要程度的量化计算,可以按fweight值从高到低选取适当数量的句子,来作为一篇新闻的情感重点句集,以实现文本的降维。

表2本文五个特征值的权重
4 使用知识图谱技术对关键句进行特征加强
在文本信息中引入知识图谱可以增加外部知识,丰富情感重点句的文本特征,在一定程度上可以提高情感分析的效果。因此,本文使用ConceptNet 5的中文部分作为知识图谱。ConceptNet是常识知识库,由RDF三元组形式的关系型知识构成,节点与节点间的关系由关系类型和关系权重来标识。

5 实验结果
5.1 实验数据
本文新闻数据集来源于网络,共计2283篇新闻资讯,将其情感倾向性标注为正面、中立和负面3类,数据集较为平衡。数据集中的新闻按7:3划分为训练集和测试集,采用F1-score作为评价指标。
5.2 实验结果与分析
为验证模型结构的有效性,本文由于算力有限本文使用Albert-tiny预训练语言模型和TextRCNN作为基线模型,并进行了消融实验,以验证知识图谱的有效性,实验结果见模型性能对比表(表3)。由该表可见,相较于基线模型,本文的模型有较为明显的性能提升,相较于去除知识图谱的模型也有一定的提升,这表明本文提出的算法具有一定的实用性和有效性。

表3 模型性能对比
6 结语
本文基于情感重点句对新闻情感展开研究,通过Transformer模型的注意力机制有效地捕捉了长文本的情感信息,并结合其Seq2Seq的模型结构在突出了标题的重要性的同时兼顾了正文,使得文本信息的把握更加全面合理。通过引入ConceptNet知识图谱,增加了上下文的常识信息,丰富了文本的维度。
本文的模型算法在与基线模型的对比中具有一定的优越性,但同时也存在一些不足:本文使用的情感重点句抽取算法较为依赖统计自然语言处理方法,缺乏对于上下文语境的考量,在后续的工作中可以考虑使用预训练语言模型,结合深度学习网络结构的方法完成重点句的自动抽取。
最后,本文使用的知识图谱嵌入方法虽然简洁有效,但是部分知识图谱内容陈旧,在一定程度可能引入噪音,需要构建更加贴合现代常识认知的知识图谱。且该方法也忽略了同一词语在不同知识关系中的语义差别,在后续的工作中将使用TransE、TransR等知识图谱嵌入模型表征这些语义差别,进一步提升模型性能。
猜你喜欢
军事文摘(2022年16期)2022-08-24
舰船科学技术(2022年11期)2022-07-15
学苑创造·A版(2020年10期)2020-11-06
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
新城乡(2018年6期)2018-07-09
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
西南学林(2014年0期)2014-11-12
中关村(2014年5期)2014-05-15
小学生作文辅导·看图读写(2009年5期)2009-06-11
