
基于CenterNet 的实时行人检测模型
2021-10-15 10:08:44姜建勇龙慧云黄自萌
计算机工程 2021年10期
姜建勇,吴 云,龙慧云,黄自萌,蓝 林
(贵州大学 计算机科学与技术学院,贵阳 550025)
0 概述
行人检测作为计算机视觉领域的研究热点[1],在车辆高级驾驶辅助系统、视频监控、安全检查以及反恐防暴等方面有着重要应用。在过去的几十年中,研究人员针对行人检测问题做了大量研究并取得一系列成果。行人检测方法主要分为基于人工设计特征和基于神经网络特征的2 种检测方法。
传统的检测器多数使用HOG 方法进行检测,如文献[2]通过改进HOG 并且联合使用SVM 进行行人检测。在传统的检测方法中,需要人工手动去提取图像特征,使得检测模型存在可扩展性、泛化能力差以及计算速度慢等问题。
随着在机器视觉中使用深度学习,研究人员开始寻找深度学习方案来解决目标检测问题。R-CNN[3]提出结合深度学习的方法解决对象检测的问题,后续很多两阶段的方法都是基于R-CNN[3]去构建的,如Fast-RCNN[4]、Faster-RCNN[5]等。在行人检测上,如文献[6]使用更为快速的Faster-RCNN[5]进行行人检测,在Caltech 数据集上比其他传统方法更为准确和快速,文献[7]使用单阶段式网络YOLO[8-10]进行行人检测,在INRIA 数据集上取得比传统方法更好的准确度。虽然Faster-RCNN 在RCNN 的基础上改进了很多组件,使得在准确度和速度上有了很大的提升,速度能够达到20 frame/s,但运用在实时检测中效果还不是很理想。而单阶段网络YOLO[8-10]在速度上很快,但是准确度距离Faster-RCNN 相差较大。
CenterNet[11]与R-CNN[3]相比,不需要区域建议网络以及ROI 等重要组件,而与YOLO[8]和SSD[12]相比,则无需预先去设定Anchor 的大小,并且CenterNet 在推理阶段不需要NMS(Non-Maximum Suppression)[13],因此在速度上有很大的提升。为了能够平衡检测的速度和准确度,本文基于CenterNet,提出PD-CenterNet 改进模型对行人进行检测。该模型通过融合低级语义信息来减少细节性信息在下采样过程中丢失的问题,并设计一个新的损失函数来解决正负样本不平衡的问题。
1 PD-CenterNet 模型设计
目标检测往往在图像上将目标以轴对称的框形式框出,成功的目标检测器都是先穷举出潜在目标位置,然后对该位置进行分类,但这种做法浪费时间、低效、需要额外的后处理。PD-CenterNet 在构建模型时将目标作为一个点,即目标BBox(Bounding Box)的中心点,检测器能够通过特征图的相对位置来估计出BBox 的中心点和尺寸。本文设计的PDCenterNet 主要由网络结构、Anchor 和损失函数3 个部分构成,下文将围绕这3 个方面进行介绍。
1.1 网络结构设计
PD-CenterNet 由主干网络、上采路径和网络顶端2 个卷积组成,如图1(b)所示。由于在目标检测中,感受野的大小在很大程度上直接影响检测的效果,因此本文通过主干网络来获取一个1/32 的特征图,编码高层的语义信息。其中向下箭头表示下采样过程,向上箭头表示上采样过程。
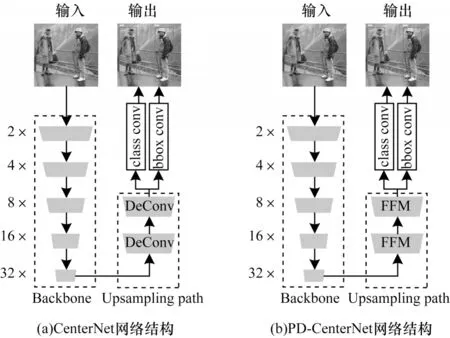
图1 CenterNet 和PD-CenterNet 网络结构Fig.1 Network structure of CenterNet and PD-CenterNet
在网络结构上,使用主干网络和上采路径的设计方式能够为整个模型带来很好的可扩展性,通过主干网络可切换为MobileNet[14]、ResNet18[15]、Xception[16]、ShuffleNet[17]等轻量级网络即可获得更快的速度,也可切换至ResNet101[15]、GoogLeNet[18]、DenseNet[19]等较大的网络来获取更高的准确度。
在上采路径上,BiSeNet[20]指出在特 征表示的层面上,低层和高层的特征表示不同,仅以通道来连接低层和高层特征,则就会带来很多噪音,所以本文设计了一个特征融合模块(FFM)来融合低层丰富的空间信息和高层的语义信息,如图2 所示。在特征融合模块中,首先将高层特征进行上采至低层特征图一致的大小,然后按通道进行连接,后面紧接一个深度可分离卷积来学习通道上每一层的表示,最后使用类似于SENet[21]的通道特征注意力机制,把相连接的特征使用全局平均池化为一个特征向量,并学习出一个权重向量,然后对先前的特征进行加权,增强了低层和高层特征融合之后的表示能力,同时也减少了特征融合之后带来的噪音。

图2 特征融合模块Fig.2 Feature fusion module
在网络顶端分别使用2 个卷积用来预测类别置信度、BBox 的位置和尺寸信息。
通过对网络结构的改进,使得模型的网络参数和计算量大幅减少。尤其将MobileNet[14]作为主干网络时使得模型的参数减少了50%,降低了计算量,在以ResNet[15]作为主干网络时参数量和计算量也得到了很大的降低,具体的信息如表1 所示。
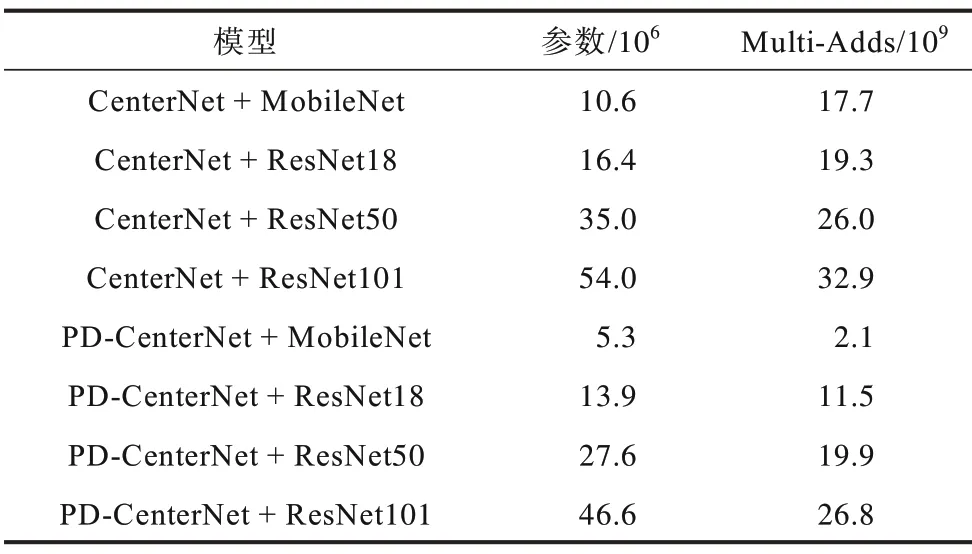
表1 模型参数及数量Table 1 Model parameters and quantity
1.2 Anchor 设计
在训练时获得网络输出的类别置信度和BBox后,需要用BBox 去匹配GT BBox,在这个过程中,BBox 即为Anchor BBox。标准的Anchor 设计了在低分辨率特征图中一系列固定的BBox,通过计算交并比(IoU)来判断是否为正样本,若交并比大于0.7 则标记为正样本,若小于0.3 则标记为负样本。而本文则将对象的中心点在低分辨率上所对应BBox 作为正样本,其他没有包含对象中心点的标记为负样本,并且一个中心点仅检测一个对象,如图3所示。
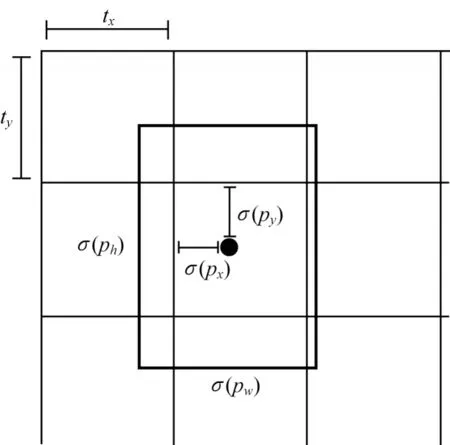
图3 PD-CenterNet Anchor 的设计Fig.3 Design of PD-CenterNet Anchor
基于图3 所示的设计,网络只需要预测在某一个单元格内的偏移即可。对于网络输出的每一个BBox 为(px,py,pw,ph),其中:(px,py)为BBox 的中心点位置;(pw,ph)为BBox 的宽和高。如果该单元格对应于图像单元格左上角的坐标为(tx,ty),则最后预测的BBox 为(bx,by,bw,bh),计算公式如下:

1.3 损失函数设计
PD-CenterNet 由BBox 的中心点、BBox 尺寸和BBox 类别置信度3 个部分损失构成,计算公式如下:
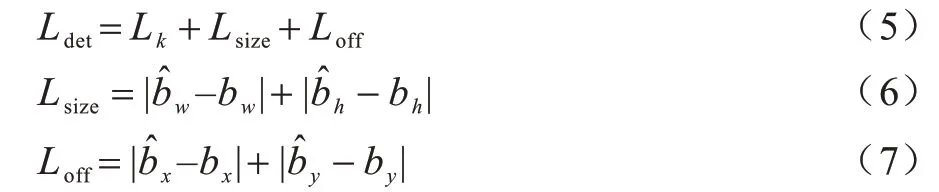
其中:Ldet为总损失;Lk为BBox 类别置信度损失;Lsize为BBox 尺寸损失;Lk为置信度损失;Loff为中心点损失。由于模型的输入是300×300,因此最终得到一个75×75 的一个特征图,并且模型一个特征点仅预测一个对象,极端情况下会出现1∶5 625 的正负样本极度不平衡,所以,本文设计一个损失函数来解决这个问题。
在类别置信度损失中,本文设计α、γ、δ3 个影响因子提高正样本的损失和减小负样本的损失以解决正负样本不平衡的问题,定义如式(8)~式(10)所示:

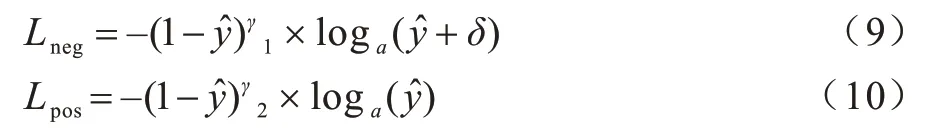
在负样本损失中通过设置δ和γ12 个因子来减小负样本的损失,定义见式(9),在正样本损失中通过γ2进行调节,定义见式(10),最后通过α因子来控制正样本和负样本损失所占的比例。通过对损失函数中的α1、α2、γ1、γ2、δ使用网格搜索得到最佳的一组参数,如表2 所示。

表2 损失函数参数值Table 2 Loss function parameter value
2 模型实现
2.1 网络结构
本文对残差网络(ResNet[15])进行修改以适应PD-CenterNet。选取 ResNet[15]网络中“layer2”“layer3”和“layer4”的输出分别作为“8×”“16×”和“32×”的特征图,然后通过特征融合模块来对这3 个特征图进行融合,接着在融合后“8×”倍的特征图上通过反卷积上采到“4×”,最后通过网络顶端的2 个卷积来进行类别置信度和BBox 预测。
MobileNet 专注于移动端或者嵌入式设备中的轻量级CNN 网络,它使得推理速度能够得到极大的提高。因此,修改MobileNet[12]作为本文模型的主干网 络,选 取MobileNet[12]中 第7 层、第14 层和最后 一个卷积层的输出分别作为“8×”“16×”和“32×”的特征图,然后通过上采路径和2 个卷积来进行类别置信度和BBox 预测。
2.2 Anchor 选择
根据Anchor 的设计,使得一个特征点仅能预测一个对象,如果一张图像中有超过一个对象的中心点重叠,则导致模型存在漏检。而由于在行人检测中存在很多对象会存在中心点一致的问题,因此在Anchor 选择时,如果BBox 被占用,则选择离中心点最近的BBox 来预测对象,这样就避免了中心点重复的问题,算法过程如下:
通过网络的输出得出B(W×H,4),其中B的宽和高在本文中为(75,75),第三维分别为BBox 的中心点位置(x,y)和大小(w,h)。对于GT(Ground Truth)中的每一个Gi,计算其在特征图大小为(W,H)的中心点位置(x,y),然后计算出(x,y)在B上的索引c(见算法1第5 行)。如果c不在正样本集合A中,则将c添加到集合A中,否则计算出离c最近的一个点并添加到集合A中。最后通过构建一个D集合,其中D的区间为[0,W×H],此时正样本Anchor为B[A],负样本Anchor为B[DA]。Anchor 选择算法如算法1 所示。

2.3 模型训练
训练使用分辨率为300 像素×300 像素的图像作为输入,对于输入的图像使用随机翻转、随机缩放(0.5~1.5 的比例)、随机裁剪和色彩抖动做数据增强,使用学习率为1e−4 的Adam[22]作为优化器,使用批大小为4 训练80 轮,其中前5 轮使用线性学习率进行预热,后75 轮使用余弦退火算法来对学习率进行衰减,如图4 所示。
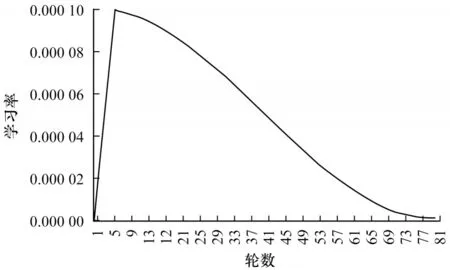
图4 学习率衰减Fig.4 Decline of learning rate
2.4 推理阶段
在推理阶段不使用数据增强,将输入的图片进行等比例的缩放,其余的地方用0 进行填充至300 像素×300 像素的输入。目前大多数的目标检测模型都依赖于NMS[13]对模型最后输入的BBox进行筛选,由于NMS的时间复杂度为O(n2),因此使得在后处理阶段变得更加耗时。结合本文模型的设计,本文设计一种时间复杂度为O(n)的后处理算法,算法过程如下:
在模型的推理和模型的训练中规定类别置信度第一个位置的值为背景的置信度,在推理时设置一个置信度阈值d用来过滤置信度低的BBox。当获得网络输出的预测框B和类别置信度C时,则需要遍历每一个Bi所对应的类别置信度Ci,如果Ci的最大值位置为0 或者对象的置信度低于设置好的置信度阈值,那么就忽略该预测框,否则保存Bi和Ci作为最好的输出,最后将面积特别小的预测框移除,以及将预测框超出图像范围的区域裁剪掉,最终的输出即为对行人的检测以及置信度,具体的实现如算法2 所示。

3 实验
3.1 数据集和环境
实验使用INRIA 行人数据集,它是当前使用较为广泛的静态行人检测数据集[23],具有拍摄条件多样化、背景复杂、存在人体遮挡以及光线强度变化大等情况。
实验使用的深度学习框架为PyTorch,模型中的主干网络ResNet 和MobileNet 均来自于torchvision 的实现,实验使用的GPU 为Tesla P100 16G 型号。
3.2 实验过程
本文通过比较改进后的主干网络和损失函数进行实验。实验采用不同的IoU 阈值计算平均精度(AP)去评价预测的结果,IoU 阈值的选取分别为0.50~0.95(AP)、0.5(AP50)和0.75(AP75)。
实验将原有的CenterNet、改进后的PD-CenterNet和损失函数进行对比,在实验中使用轻量级主干网络MobileNet 和较大的ResNet 作为主干网络进行不同的实验。
第1 组实验使用原有的CenterNet 和Focal Loss 损失函数,并在MobileNet 和ResNet 上进行实验,如表3所示。
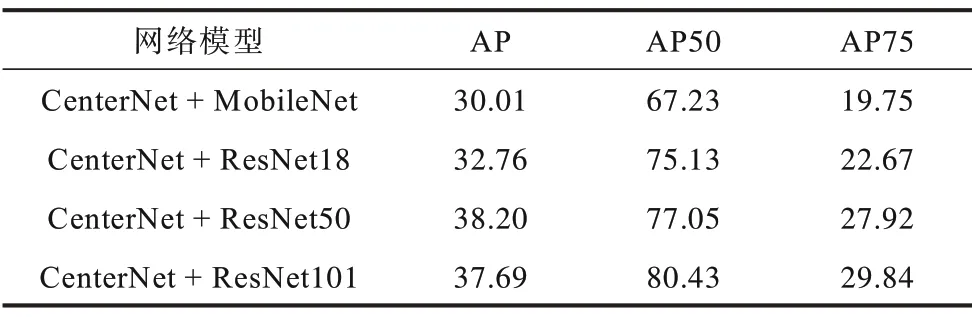
表3 CenterNet 网络和Focal loss 函数Table 3 CenterNet network and Focal Loss function %
第2组实验使用CenterNet来预测BBox和置信度,在训练时使用改进后的损失函数来计算损失,如表4所示。

表4 CenterNet 网络和改进的损失函数Table 4 CenterNet network and improved loss function %
第3 组实验使用改进后的预测网络PD-CenterNet来预测BBox 和置信度,在训练时使用Focal Loss 来计算损失,如表5 所示。

表5 PD-CenterNet 网络和Focal loss 函数Table 5 PD-CenterNet letwork and Focal Loss function %
第4 组实验使用改进后的预测网络PD-CenterNet来预测BBox 和置信度,在训练时使用改进后的损失函数来计算损失,如表6 所示。
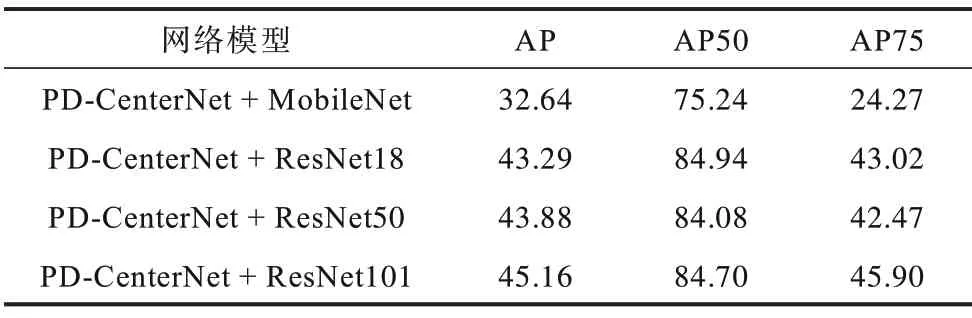
表6 PD-CenterNet 网络和改进后的损失函数Table 6 PD-CenterNet network and improved loss function %
3.3 结果分析
本文改进的PD-CenterNet 相对于CenterNet 在准确度上有了明显的提升,最高提升了9.81%,如图5 所示。改进后的网络结构由于使用了特征融合模块,所以在AP50 准确度上提高了5.1%(见表3、表5),在AP准确度上提高了1.23%,在AP75 准确度提高了0.39%;改进后的损失函数也相对于Focal Loss 函数[24]在使用ResNet18作为主干网络时,AP50准确度也提高了5.16%(见表3、表4),同时在AP 和AP75 准确度上也都有着明显的提升。最终改进网络结构和损失函数在使用ResNet18 作为主干网络时提升最大,在AP50 准确度提升了9.81%(见表3、表6),在AP准确度上提高了8.09%,在AP75 准确度上提高了20.35%。
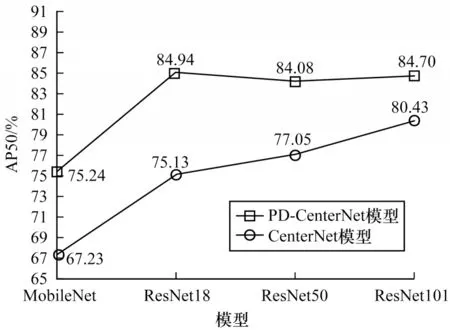
图5 模型准确度比较Fig.5 Comparison of model accuracy
ResNet 在所有主干网络中平均精度最高,但相对于MobileNet 作为主干网络在速度上相对较慢。ResNet18速度在ResNet系统中最快,达到136 frame/s(图6),在AP50 准确度上与ResNet50 和ResNet101持 平,但PD-CenterNet 在使用ResNet101 时AP 和AP75 最高。实验结果表明,主干网络越大,则AP 和AP75 就越好,因此在对行人进行检测时也就更为准确。
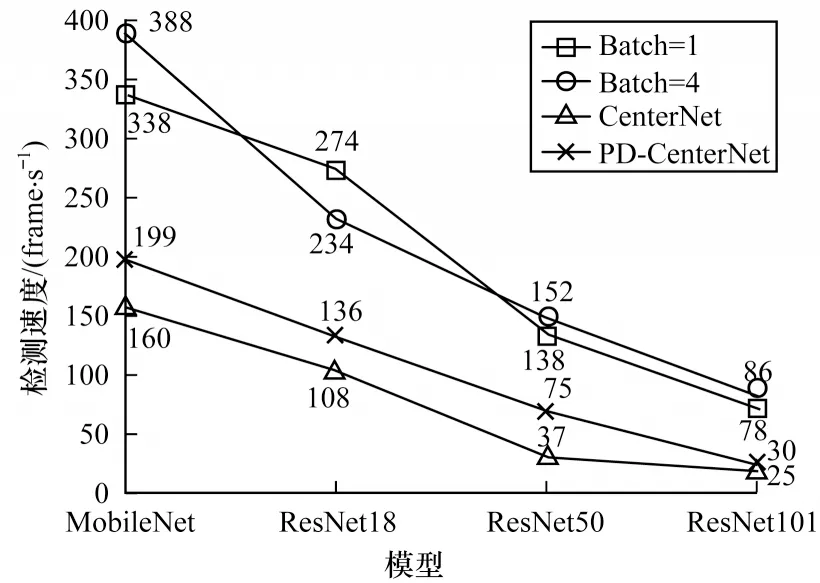
图6 模型检测速度比较Fig.6 Comparison of mode detectl speeds
MobileNet 相对于ResNet 在速度上优势更为明显,能够达到199 frame/s(图6),但是在准确度上低于ResNet,而改进后的模型准确度相比ResNet 提高了8.01%。
从上述实验结果可以看出,在网络结构中使用特征融合改进后的PD-CenterNet,AP、AP50 以 及AP75 都具有较好的表现;改进后的损失函数也表现出了良好的结果。最终的检测结果如图7 所示,其中,第1 行为GT(Ground Truth),第2 行为模型预测的结果,在检测结果中设置的置信度阈值为0.5。从图7 可以看出,本文模型在大对象、小对象、对象重叠、密集对象等场景下仍然能获得较好的结果。

图7 行人检测结果Fig.7 Pedestrian detection results
4 结束语
为平衡行人检测速度和准确度的问题,本文提出一种基于CenterNet的行人检测模型PD-CenterNet。在速度上设计一个轻量级特征融合模块来减小网络结构中上采路径的计算量,并在推理时降低后处理程序的时间复杂度。在准确度上设计特征融合模块对低层和高层特征进行融合,并在损失函数中设计α、γ、δ3 个因子来改善正负样本不平衡的问题。实验结果表明,该模型对行人检测的AP50 准确度为84.94%,检测速度达到136 frame/s。本文在网络设计时仅使用了2 个特征融合模块,在小对象上的IoU 不是最优,因此提高小对象的IoU 将是下一步的主要工作。
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
电脑报(2020年12期)2020-06-30 19:56:42
电脑报(2019年4期)2019-09-10 07:22:44
建筑科技(2018年6期)2018-08-30 03:40:54
计算机应用(2018年5期)2018-07-25 07:41:26
中国交通信息化(2016年5期)2016-06-06 03:51:43
少儿美术·书法版(2016年1期)2016-02-06 00:59:39
大众摄影(2015年9期)2015-09-06 17:05:41
轴承(2015年2期)2015-07-25 03:51:04
天津冶金(2014年4期)2014-02-28 16:52:58
