
基于MobileNet⁃SSD 的安全帽佩戴检测算法
2021-10-15 10:08:48徐先峰赵万福邹浩泉潘卓毅
计算机工程 2021年10期
徐先峰,赵万福,邹浩泉,张 丽,潘卓毅
(长安大学电子与控制工程学院,西安 710064)
0 概述
安全帽作为一种安全防护工具,对工人的人身安全具有重要保障作用。目前对于工人安全帽的佩戴检测主要依靠人工监视,这种检查方式不仅耗费人力资源,而且容易受工作人员的主观影响。基于视频监控的智能安全帽佩戴检测,在能够降低施工现场人力资源成本的同时,也能防范安全事故的发生。
人员之间的部分遮挡、摄像头的拍摄像素、摄像头距目标距离的远近程度等因素造成安全帽的佩戴检测具有一定的难度。为实现安全帽佩戴自动检测,研究人员进行了大量研究。LI 等[1]运用帧间差分方法分割视频画面的动态目标后,利用图像的方向梯度直方图(Histogram of Oriented Gradient,HOG)特征训练支持向量机(Support Vector Machines,SVM)分类器,并使用该分类器判断动态目标是否为行人。若是行人,则使用Haar-like 进行特征提取并输送到Adaboost 分类器以判断画面中的行人是否佩戴安全帽。LIU 等[2]使用尺度滤波算法从视频图像中提取前景,对运动目标进行分割、跟踪和标记,通过检测运动目标的上部1/3 部分中的像素点及色度值的分布情况判断检测目标安全帽的佩戴情况。FENG 等[3]使用混合高斯模型进行前景检测,通过图像处理方法对连通域进行处理并判断其是否属于人体,定位到的人体头部区域可实现安全帽的自动识别。DU 等[4]利用viBe 算法提取前景目标,通过前景目标对安全帽的佩戴区域进行初步定位,并使用DPM 算法对安全帽佩戴情况进行检测。此类方法受视角影响较大,当出现被检测人员非站立、被遮挡、静止不动等复杂情况时,此类方法呈现一定局限性,其检测精度还有待提高。总体来说,以上基于传统方法的安全帽佩戴检测算法存在手工设计特征困难、泛化能力差等问题,难以应用到实际工程实践中。
目前,基于深度学习的方法是目标检测的主流方法[5-6],单发多盒探测器(Single Shot MultiBox Detector,SSD)[7]作为经典的基于深度学习的目标检测算法之一,具有检测速度快、检测精度高、对小目标和多目标检测效果好的优点,在行人检测[8]、遥感目标检测[9]、绝缘子检测[10]等目标检测领域应用广泛。但目前为止尚未发现有文献将SSD 算法应用于安全帽佩戴检测中。在通常情况下,视频监控设备运行在CPU 平台下,而SSD 在GPU 平台下的检测速度快但在CPU 平台下无法达到实时的目标检测。由于SSD 为卷积神经网络,需要大量数据集,而目前可用的安全帽公开数据集少且规模较小,数据集收集困难。有研究人员发现,迁移学习(Transfer Learning)[11]通过从已学习的相关任务中转移知识以改进学习的新任务,可有效解决SSD 模型训练困难的问题。
针对安全帽佩戴检测多为小目标和多目标的现实问题,本文基于深度学习的基础理论知识,对SSD 检测算法中暴露出的问题进行优化改进。引入轻量型网络加快检测速度实现实时的目标检测,采用迁移学习策略训练SSD,通过依托互联网平台大量采集安全帽图像,并从施工相关视频中获取真实环境下的安全帽样本构建样本集。
1 安全帽佩戴检测算法
SSD[12]是经典的目标检测算法,其在6 层卷积层输出的特征图上进行多尺度特征提取,这些特征图又被称为预测层,每层分别对多尺度分支的回归网络(Loc_Layers)和多尺度分支的分类网络(Conf_Layers)进行卷积,得到待检测目标的位置和种类。
靠近输入的特征图尺寸较大而感受野较小,特征包含的位置信息丰富,因此适合检测小安全帽目标;靠近输出的特征图尺寸较小而感受野较大,包含全局信息,因此适合检测大安全帽目标。SSD 检测算法在大特征图和小特征图上均可进行位置回归,因此可同时兼顾大小安全帽目标的检测,较仅在最后一层特征图上进行位置回归的算法检测性能优异。在实际应用场景中,由于监控摄像头与距检测目标具有一定的距离,因此会出现较多的小安全帽目标,而SSD 检测算法在小目标检测上表现出较好的检测性能,非常适用于安全帽的佩戴检测场景[13-14]。
SSD 检测算法虽然在检测精度和检测速度上均优于传统检测算法,但仍然无法达到实时的目标检测,对于安全帽的佩戴检测速度还无法达到实际的应用要求。针对此问题,本文引入轻量型网络对SSD 模型进行压缩以加快安全帽的检测速度。同时,针对SSD 训练困难这一问题,使用迁移学习训练策略对轻量型SSD 网络进行训练,以快速训练网络并得到较好的训练结果。
1.1 轻量型安全帽检测模型
实际应用中的视频监控设备多使用CPU 平台,不具备GPU的并行加速计算能力。而在CPU平台下,SSD算法的检测速度非常缓慢,难以满足安全帽佩戴检测的速度要求。针对此问题,在SSD 的研究基础上,提出使用MobileNet[15]代替SSD 中的基础网络VGG[16]进行安全帽佩戴检测以加快模型的检测速度。
MobileNet 是一种兼备检测精度和检测速度的轻量型神经网络,其通过构建深度可分离卷积(Depthwise Separable Convolution)以改变网络的计算方式从而降低网络参数量,在降低模型复杂度的同时提高模型的检测速度。其中,深度可分离卷积分为单深度卷积(Depthwise)和单点卷积(Pointwise)2 个操作,如图1所示。
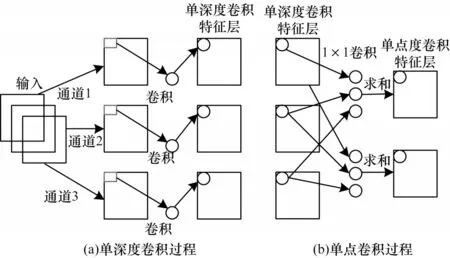
图1 深度可分离卷积过程Fig.1 Deep separable convolution process
深度可分离卷积能够减少模型的参数量,表1 为MobileNet 网络参数量和VGG 网络参数量的统计结果[17]。

表1 VGG 和MobileNet 网络参数量对比Table 1 Comparison of parameters of VGG and MobileNet
在表1 中:访存量是参数量所占内存与输出特征图参数量所占内存之和;计算量(Floating Point 0perations,FLOPs)指浮点运算数,用来衡量算法或模型的复杂度,1GFLOPs=109FLOPs;VGG 网络的GFLOPs 为14.20,表示模型前向传播一次需要进行142 亿次浮点运算;MobileNet 的GFLOPs 为0.53,表示模型向前传播一次需要进行5.3 亿次浮点运算。MobileNet 的运算量远少于VGG 的运算量。此外,VGG 的参数量是MobileNet 的30 倍左右,表明MobileNet 占用的内存空间更少。
综上所述,MobileNet 无论是在计算量、参数量还是在内存消耗上,均比VGG 网络更加适用于CPU平台下的目标检测。因此,本文将SSD 中VGG 基础网络替换为MobileNet 网络,引入MobileNet-SSD 实现监控视频中佩戴安全帽人员[17]和未佩戴安全帽人员的检测,MobileNet-SSD 结构如图2 所示。
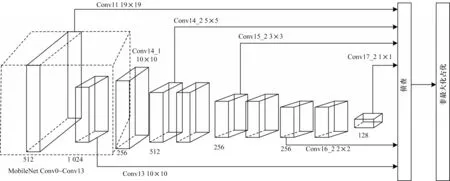
图2 MobileNet-SSD 网络结构Fig.2 MobileNet-SSD network structure
1.2 迁移学习训练策略
迁移学习[18]是将网络中每个节点的权重从一个训练好的网络迁移到另一个全新的网络。在实际应用中,通常不会针对新任务从头开始训练神经网络,因为此操作较为耗时,尤其是当训练数据无法达到类似ImageNet 数据集的规模时,想要训练出泛化能力足够强的深度神经网络[19]极为困难。且即使数据集足够,从头开始训练将付出较大的训练代价。使用迁移学习策略能够加快安全帽检测模型的训练速度,训练过程简单且在相同的训练时间内能得到更高精度的检测模型。
1.3 安全帽分类和位置定位
MobileNet-SSD[20]需要对输入图像中的目标具体位置进行定位,其次将定位好的目标分类为Hat 类或Person 类。具体过程为:定义输入样本x,根据具体分类和定位任务同时调整位置误差损失函数和置信度误差损失函数,损失函数如式(1)所示:
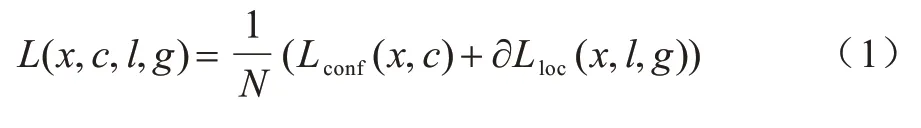
其中:N是先验框的正样本数量;α的作用是调整位置误差与置信度误差之间的比例,默认设置为1;c为类别置信度预测值;l为边界框的先验框位置;g是真实目标的位置参数;x为指示参数,具体形式为∊{1,0},当=1 时,第i个先验框与第j个真实目标相匹配,即对第j个真实目标来说,第i个先验框是其正样本,且真实目标的类别为p;当=0 时,对 第j个真实目标来说,第i个先验框是其负样本,同样真实目标的类别为p;位置损失函数Lloc使用SmoothL1损失函数,具体形式如式(2)~式(7)所示:
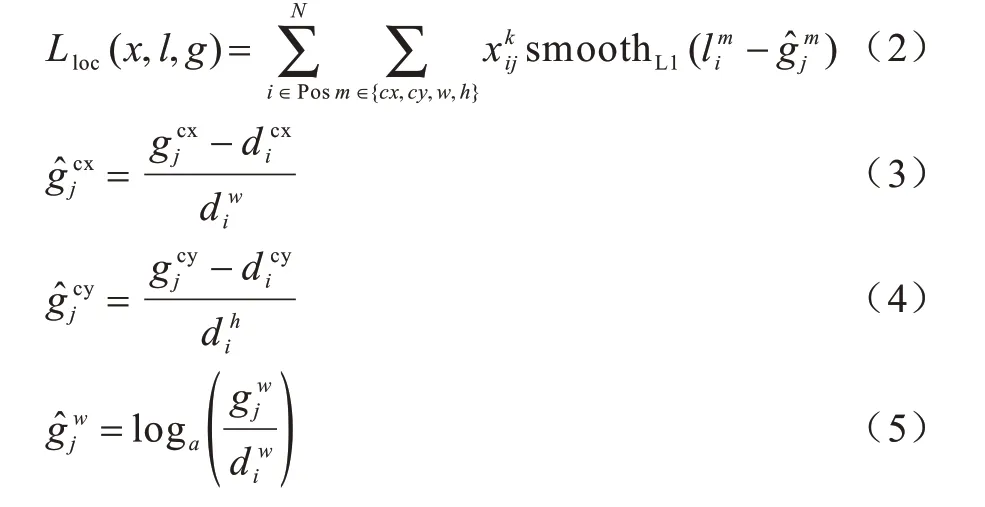

由于的存在,位置误差损失函数中只有正样本参与训练。对于类别置信度误差采用softmax loss函数,如式(8)所示:
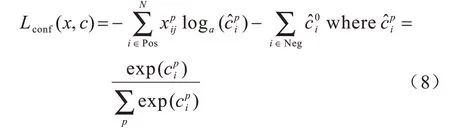
其中:含义与位置损失函数中的含义一致,但因为i∊Pos,因 此的值只能为1,表示第i个先验框(正样本)与第j个真实目标相匹配且真实目标的类别为p;表示该第i个先验框是p类目标的置信度,由于已知该第i个先验框是p类,因此在训练过程中越大越好,这与训练时应该不断减小损失函数相悖,因此在log前添加负号,以达到训练时不断减小损失函数而增大的目的表示第i个先验框是0 类即背景类的置信度,由于i∊Neg,因此第i个先验框一定是背景类,且在训练时越大越好。与上述相同,在损失函数中在前添加负号,以达到损失不断减 小不断增大的目的。
显然,通过类别置信度误差函数能同时减少安全帽特征向量间的差异及人脸特征向量间的差异,并增大安全帽与人脸特征向量间的差异,即减小类内差异,增大类间差异。从大量的训练样本中学习该特征空间的更鲁棒、更具可区分的距离度量,将原本在原始空间中分辨困难的数据进行维度规约,降低干扰影响,提升识别精度。
2 实验结果与分析
2.1 数据集构建
针对目前安全帽数据集规模较小、网络难以充分拟合特征这一问题,依托互联网平台大量采集安全帽图像,并从施工相关视频中获取真实环境下的安全帽样本以构建本文安全帽样本集。数据集中包含5 034张佩戴安全帽图片,共13 325个佩戴安全帽目标、4 340 张人脸图片、人脸目标111 514 个。佩戴安全帽的图像收集于网络,人脸图像来自部分SCUT-HEAD 数据集。
将样本数据集分为训练集和测试集,训练集为4 034 张安全帽图像和3 340 张人脸图像,测试集为1 000 张安全帽图像和1 000 张人脸图像。真实场景下的部分数据集如图3 所示。

图3 真实场景下的部分数据集Fig.3 Part of the data set in the real scene
2.2 实验环境
本课题的实验平台配置:系统为Ubuntu16.04;GPU 平台版本为NVIDIA GTX 1080Ti(x2);编程语言为Python3.5;标注工具采用LabelImg;加速工具为CUDA10.0;模型的搭建、训练和结果的测试均在Caffe 框架下完成,使用CUDA 并行计算架构,同时将Cudnn 加速库集成到Caffe 框架下以加速计算机计算能力。下文未佩戴安全帽的人脸识别使用同样的环境配置。
2.3 评价指标
目标检测模型的检测精度衡量指标有召回率(Recall)、精确度(Precision)和均值平均精度(mean Average Precision,mAP)等,模型的检测速度衡量指标有每秒帧率(Frame Per Second,FPS)等,本文使用上述评价指标对安全帽的佩戴检测模型性能进行衡量。
召回率和精确度的计算过程如式(9)和式(10)所示:

其中:TP 为真正例,表示模型分类正确,原本属于正类的样本分为正类;FP 为假正例,表示模型分类错误,原本属于负类的样本分为正类;TN 为真负例,表示模型分类正确且原本属于负类的样本分为负类;FN 为假负例,表示模型分类错误且原本属于正类的样本分为负类;Recall 表示分类器认为是正类且原本确实是正类的部分占所有原本属于正类的比例;Precision 表示分类器认为是正类并且原本确实是正类的部分占所有分类器认为是正类的比例。
根据式(9)和式(10)计算Recall 和Precision 值,并以Recall值为x轴,Precision 值为y轴绘制P-R 曲线,AP即为曲线所包围的面积,在测试集上求每一类目标的AP 值再取平均。mAP 的计算过程如式(11)所示:

2.4 运算复杂分析
探究MobileNet-SSD 相对于SSD 的优越性,对其检测速度和检测精度进行对比。
保持硬件平台相同,分别统计SSD 算法在GPU和CPU 设备下的检测速度,测试视频来自互联网的工地施工视频,其中包含大量安全帽佩戴人员样本。结果如表2 所示。

表2 SSD 在不同平台下的检测速度比较Table 2 Comparison of SSD detection speeds under different platforms(frame·s−1)
由表2 可知,GPU 平台下检测速度达到了15 frame/s 左右,即每秒可以处理大约15 张图像,而CPU 平台下检测速度仅为1 frame/s 左右,图像处理速度较慢,由此可知SSD 在GPU 平台下的检测速度远快于在CPU 平台下的检测速度。
使用相同的测试视频,分别统计MobileNet-SSD 算法在GPU和CPU设备下的检测速度,结果如表3所示。
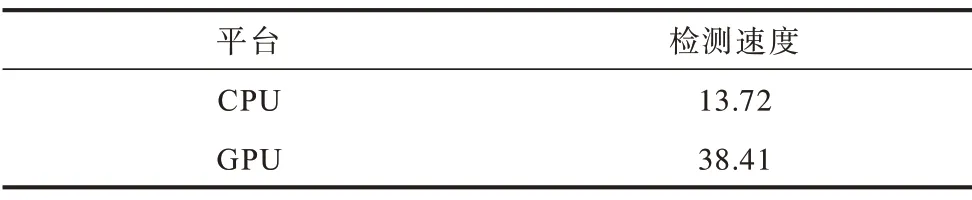
表3 MobileNet-SSD 在不同平台下检测速度比较Table 3 Comparison of detection speed of MobileNet-SSD under different platforms(frame·s−1)
与SSD 在CPU 平台下的速度(1.24 frame/s)对比,轻量型MobileNet-SSD 的检测速度是其10.6 倍左右。对比SSD 的检测精度(90.51%),MobileNet-SSD 的检测精度为87.32%,较SSD 下降了约3.2 个百分点。因此可以认为,在基于智能视频监控的安全帽佩戴检测中,轻量型MobileNet-SSD 仅在损失很小精度的情况下,极大地提高了安全帽的检测速度,使得安全帽佩戴检测能够在CPU 平台下顺利实现。
2.5 结果分析
本文首先使用ImageNet数据集训练VGG 网络[21],将得到的参数初始化后输入MobieNet-SSD,并在此基础上使用自建数据集进行进一步优化训练。此过程中,初始学习率设置为0.001,迭代次数为50 000 次,学习率调整策略为Multistep,步长分别设置为10 000、20 000、30 000,动量(Momentum)为0.9,衰减系数(Delay)为0.000 5。MobileNet-SSD 和SSD 算法的损失随迭代次数的变化曲线如图4 所示。
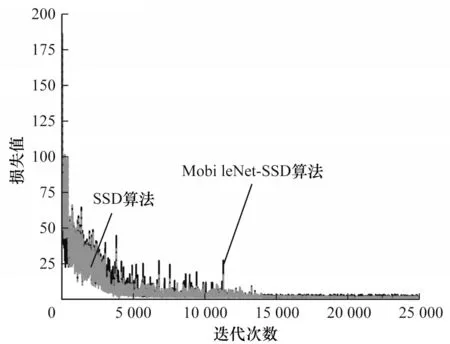
图4 训练损失曲线Fig.4 Training loss curve
由图4 可知,在整个训练过程中SSD 算法具有更低的损失值,且迭代到14 000 次左右时,SSD 和MobileNet-SSD 算法的损失值均不再震荡而是趋于稳定,SSD 收敛到更低的损失值。
由于计算机内存限制,因此训练和验证不同时进行,而是每训练5 000 次保存一组算法,并在保存的算法上对测试集进行测试,以探究算法在特定的迭代次数时对图像数据中目标的检测能力。测试集在MobileNet-SSD 算法上得到的Hat 类和Person 类的召回率和精确度分别如图5 和图6 所示。
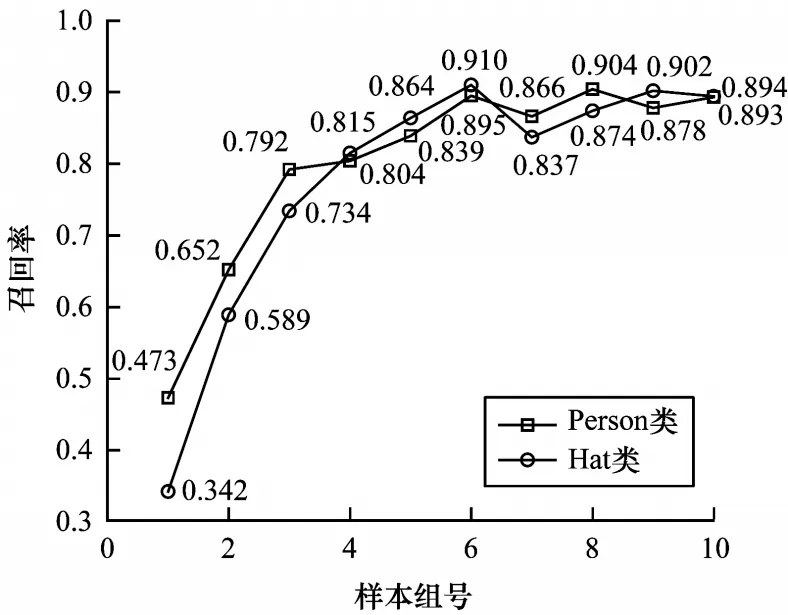
图5 MobileNet-SSD 各组算法的召回率统计结果Fig.5 Recall statistics of each group algorithm of MobileNet-SSD
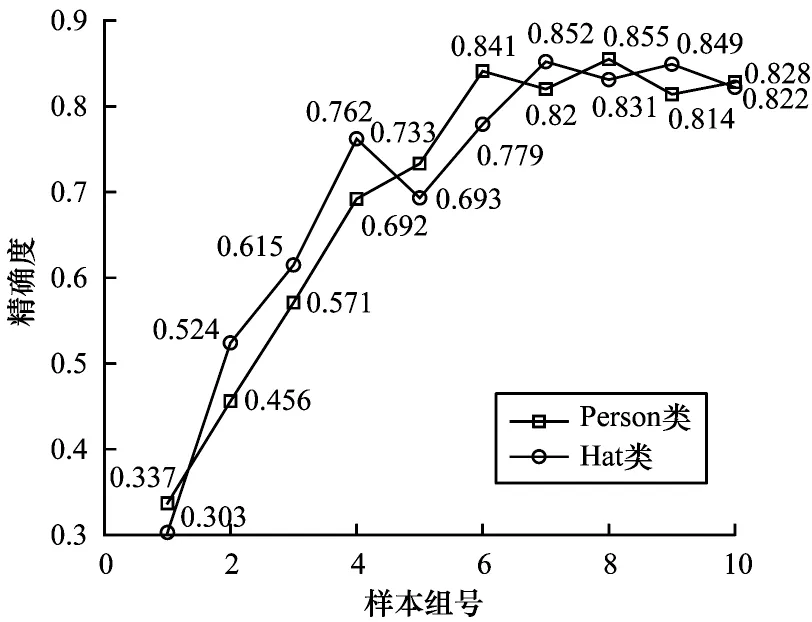
图6 MobileNet-SSD 各组算法的精确度统计结果Fig.6 Accuracy statistics results of each group algorithm of MobileNet-SSD
由图5 和图6 可知,随着MobileNet-SSD 算法的训练加大,召回率和检测精度不断上升,之后逐渐趋于稳定并在小范围内震荡。当训练到30 000 次(第6 组模型)和45 000 次(第9 组模型)时,Hat 类和Person 类取得了最高的召回率,分别为91%和90.46%;当训练到35 000 次(第7 组)和40 000 次(第8 组)时,Hat 类和Person类取得了最高的精确度,分别为85.2%和85.5%。分析图4 还可发现第8 组即SSD 模型训练40 000 次时,检测精度达到最大为90.51%,第9 组MobileNet-SSD 模型即训练45 000 次时,检测精度达到最大为87.32%。
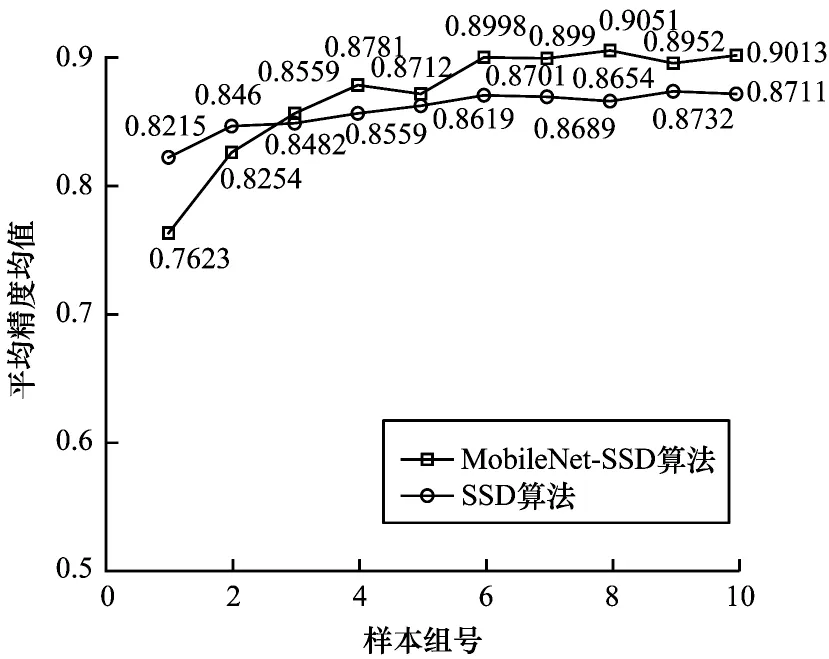
图7 MobileNet-SSD 和SSD 在各组模型的mAP 统计结果Fig.7 mAP statistical results of MobileNet-SSD and SSD in each group of models
除了对MobileNet-SSD 检测精度进行分析外,还需探究MobileNet-SSD的检测速度。本文所使用的GPU型号为GTX 1080Ti,能有效地提高计算机的计算性能,但在实际应用场景中,视频监控一般使用普通的CPU设备,CPU 设备不具备GPU 的并行加速计算能力。本文在其他硬件平台相同下,分别在使用GPU 和CPU 设备下对最终模型的检测速度进行统计。测试集共有2 000 张图像,其中安全帽图像和人脸图像各1 000 张,包含20 196 个人脸目标和2 151 个安全帽目标,共22 348 个待检测目标。最终结果如表4 所示。
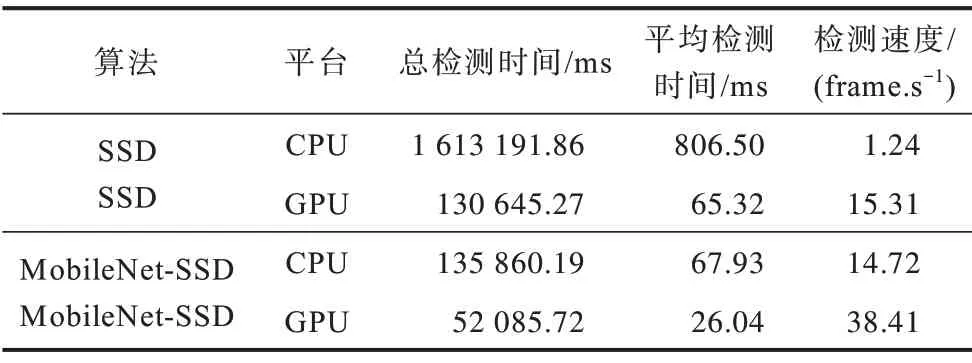
表4 不同算法分别在CPU和GPU平台下的检测速度比较Table 4 Comparison of detection speeds of different algorithms on CPU and GPU platforms
由表4可知,SSD算法在CPU平台下检测2 000张图像共用了1 613 191.86 ms,而在GPU 平台下检测2 000 张图像共用了130 645.27 ms,即SSD 算法在GPU 平台下的检测速度远高于在CPU 平台下的检测速度。此外,SSD 算法在GPU 平台下的检测速度达到了15 frame/s 左右,即每秒可以处理大约15 张图像,而在CPU 平台下的检测速度仅为1frame/s 左右,图像处理速度缓慢。因此,本文认为SSD 算法在GPU 平台下可以实现实时安全帽佩戴检测,但在CPU 平台下还需进一步优化算法以提高安全帽佩戴的检测速度。
与表4 中SSD 在CPU 平台下的速度对比,轻量型MobileNet-SSD 的检测速度是其11.9 倍左右。同时对比SSD 的检测精度90.51%,MobileNet-SSD 的检测精度为87.32%,较SSD 下降了约3.2 个百分点。因此可以认为,在基于智能视频监控的安全帽佩戴检测中,轻量型MobileNet-SSD 仅在损失很小精度的情况下,极大地提高了安全帽的检测速度,使得安全帽佩戴的实时检测能够在CPU 平台下顺利实现。
为进一步验证本文算法具有较高的检测精度和检测速度,分别使用Faster-RCNN 和YOLO 等经典算法在相同测试数据集下进行测试,结果如表5 所示。其算法采用Ubuntu16.04 系统,在版本为Intel E5 2660 的CPU 平台下进行,内存为16 GB DDR3 RAM(x2),硬盘版本为Intel 500G SSD,GPU 为NVIDIA GTX 1080Ti(x2)。
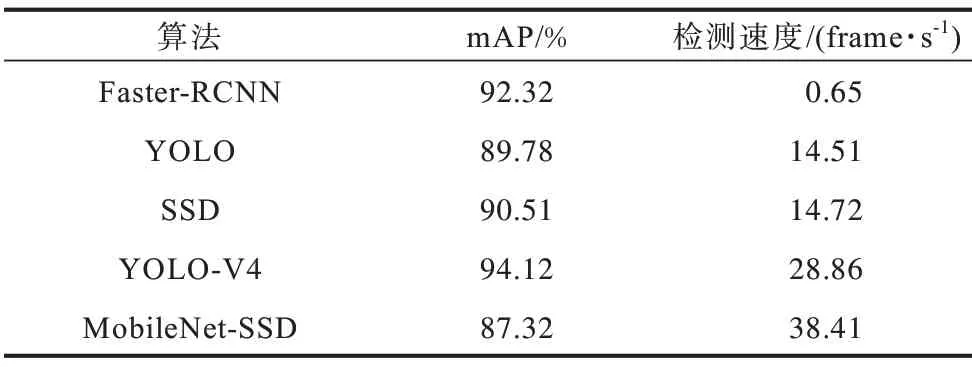
表5 不同算法下的检测结果对比Table 5 Comparison of detection results under different algorithms
由表5可知,Faster-RCNN[22]具有较高的检测精度,但其检测速度缓慢,无法实现实时安全帽佩戴检测;YOLO 和SSD 算法检测速度相当,但SSD 的检测精度高于YOLO 的检测精度;对于MobileNet-SSD,其检测速度相对于SSD 有较大提升,但检测精度有所下降。此结果再次印证本文结论,即轻量型MobileNet-SSD 仅在损失很小精度的情况下,极大地提高了安全帽的检测速度,使得安全帽佩戴检测能够实时实现。
为更直观地展现MobileNet-SSD 的检测效果,本文选取单目标和多目标情形、小目标和极端小目标情形、复杂背景和其他特殊应用场景下的测试图像序列进行检测效果验证。
安全帽佩戴检测的最终目的是将佩戴安全帽人员的面部和安全帽作为一个整体区域提取出来,针对没有佩戴安全帽的人员仅提取其面部区域。图8 和图9分别为单目标和多目标检测结果,佩戴安全帽[23]的人员的具体坐标位置使用红色矩形框(彩色效果见《计算机工程》官网HTML 版)标出,未佩戴安全帽的人员人脸的具体位置使用蓝色框标出。图8 和图9 分别为选取了人脸正面、背面和多角度的3 张单目标图像的检测结果对比。通常单目标图像[25]不存在目标间的遮挡,因此其检测过程相较于多目标检测更简单。总体上,MobileNet-SSD 算法对单目标图像能做出正确的检测,检测结果基本满足需求。对于多目标图像,目标间往往存在遮挡及互相干扰,这在一定程度上增加了安全帽佩戴检测的难度。图9(a)、9(b)均为没有遮挡的情况,因此全部检测成功。从图9(c)的检测结果可以看出,当遮挡面积过大时会出现一定的漏检情况,为安全帽佩戴检测带来误差。

图8 单目标下mobileNet-SSD 的检测结果展示Fig.8 Display of mobileNet-SSD detection results under single target

图9 多目标下mobileNet-SSD 的检测部分结果展示Fig.9 shows the results of the detection part of mobileNet-SSD under multiple targets
在单目标和多目标情形、复杂背景情形和其他特殊情形下,MobileNet-SSD 的检测效果与SSD 非常接近。而对于小目标和极端小目标的情形,两者检测效果差异较大,图10 为MobileNet-SSD 在小目标和极端小目标情形下的安全帽佩戴检测效果。

图10 小目标和极端小目标下MobileNet-SSD 的检测结果Fig.10 Mobilenet-SSD detection results for small targets and extremely small targets
观察图10(a)~图10(c)可知,对于包含小目标且小目标间无遮挡的图像,轻量型Mobilenet-SSD 表现出较好的检测效果。而对于如图10(d)包含大量的极端小目标的图像,轻量型Mobilenet-SSD 仅能检测出很少一部分目标,检测效果不佳。对比SSD 对极端小目标的检测结果可知,SSD 对图像中的大部分目标检测正确,仅有小部分目标出现漏检情况。因此可以认为,若视频监控中含有大量的极端小目标,轻量型Mobilenet-SSD 会出现严重漏检的情况。但考虑到一般监控视频中多含有较小目标和正常目标,含有极端小目标的情况很少,且本文对极端小目标无法进行后续的人脸识别处理,因此极端小目标的检测并不在本文的研究范围。综合考虑,MobileNet-SSD 基本能够满足实际检测需求。
3 结束语
针对真实场景下安全帽检测所面临的背景复杂且干扰性强、待检测目标较小、对检测速度要求较高等问题,本文采用SSD 算法进行安全帽佩戴检测。由于SSD 算法在不使用GPU 加速时会出现检测速度缓慢、内存消耗大和计算复杂度高的问题,因此引入一种轻量级MobileNet 网络代替SSD 中的基础网络VGG,在迁移学习策略上训练得到MobileNet-SSD 算法。实验结果表明,该算法在CPU 下检测速度达到13.72 frame/s,检测精度达到87.32%,较SSD算法的检测速度提高了10.2 倍,MobileNet-SSD 在仅损失很小精度的情况下,大幅提升了安全帽佩戴检测的速度。本文算法虽然加快了模型的检测速度,但是其精度却有所损失,下一步将研究如何在提高检测速度的同时保持甚至提高检测精度。
猜你喜欢
星星·诗歌原创(2023年12期)2024-01-06 08:24:53
机电安全(2022年4期)2022-08-27 01:59:42
小猕猴智力画刊(2022年4期)2022-05-25 02:29:38
中学生百科·大语文(2021年4期)2021-05-12 18:04:07
电子制作(2018年11期)2018-08-04 03:25:38
发明与创新(2016年5期)2016-08-21 13:42:44
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电子设计工程(2015年3期)2015-02-27 12:03:45
河南科技(2014年14期)2014-02-27 14:11:53
华东理工大学学报(自然科学版)(2014年3期)2014-02-27 13:49:03
