
数据驱动的航空发动机材料设计研究进展*
2021-10-15 08:24袁睿豪廖玮杰樊江昆寇宏超李金山
航空制造技术 2021年18期
袁睿豪,廖玮杰,唐 斌,樊江昆,王 军,寇宏超,李金山
(西北工业大学凝固技术国家重点实验室,西安 710072)
航空发动机是现代工业技术的明珠,航空发动机材料是高性能航空发动机的基础。伴随着航空发动机的发展,其主要部件所采用的材料也在不断地更新换代。例如,从早期一、二代发动机主要使用金属结构材料如高温合金,到第四代发动机中复合材料的引入[1]。近年来,新一代航空发动机对推重比、压气机增压比、涡轮前入口温度等性能指标提出了更高的要求。因此,设计和开发新型的航空发动机材料,满足在更高温度、更高压力、更高速度等极端环境下的长期服役要求,具有重要的理论意义和工程应用价值[2]。但是,复杂的成分构成和加工工艺使得航空发动机材料的设计和开发耗时较久,成本较高。以传统的高温合金为例,多种合金元素可用于合金化,导致了巨大的未知成分空间;另一方面,为了优化合金的微观组织结构,需要同时调控热处理温度、时间、变形量等多种加工工艺参数,产生了巨大的未知工艺参数空间[3]。针对这些问题,传统的材料研发方法如试错法和经验法难以实现材料的快速筛选、设计和开发,亟须发展新的研究手段,提升航空发动机材料的研发效率。
材料基因工程是近年来新兴的材料研发新范式,通过融合高通量试验、计算和大数据技术,实现材料研发时间和成本的同时减半[4]。其中,基于高通量试验和计算产生的数据,利用大数据技术,挖掘材料数据中潜在的模式或者物理规律,加速新材料的设计与开发,是近几年来的研究热点。与传统的计算和理论模拟不同,数据技术如机器学习等仅需要从数据出发,构建成分、工艺、组织等和目标性能之间的映射关系,实现对所需性能的正向预测,或者基于构建的预测模型,逆向指导最佳成分或工艺参数的选择[5]。这一研究方法在一定程度上避免了理论模型难以处理复杂材料体系的难题,例如,相图计算方法需要大量的热力学数据,对于多元体系的计算精度难以保证;第一性原理计算能够保证计算精度,但是计算规模通常是几百个原子,限制了在复杂多元体系中的应用[6]。值得注意的是,基于机器学习的材料开发是从数据出发的,意味着这一研究方法不受限于特定尺度,可以实现微观、介观、宏观的多尺度建模。
最近,数据驱动的研究思路也逐渐被用于航空发动机材料的研究中,以提升材料的研发效率,预测极端条件下的服役性能等。本论文主要从以下3 个角度进行讨论:首先,以最近广泛应用的主动学习为例,详细讨论如何进行数据库构建、机器学习建模和模型评估、优化算法指导材料选择以及试验或计算的验证;其次,以航空发动机材料,即高温合金、钛合金、复合材料、热障涂层为例,介绍了机器学习在其中的具体应用;最后,对机器学习在材料中的应用进行总结,针对航空发动机服役环境的复杂性,讨论了机器学习在航空发动机材料的研究中所面临的难题,并提出了可能的解决思路。
数据驱动的材料研究进展及基本思路
目前,基于机器学习的数据驱动材料研究主要集中于以下3 个方面: (1)通过构建成分、组织、结构与性质、性能之间的定量预测模型,加速新材料的开发; (2)基于大量的数据,提取潜在的规律,获得新的物理知识; (3)通过融合已有的成熟理论模型,进一步加速数据模型的性能优化效率。例如,通过直接构建高温合金成分与γ′相溶解温度的数据模型,实现对具有高γ′相溶解温度合金成分的快速筛选[7];构建材料的描述符,通过特征工程,确定影响材料性能的关键基因,指导新材料的设计[8];通过将已有的理论与数据模型结合,对未知材料空间进行预先筛选,实现高性能铁电材料的快速开发等[9]。其中,基于主动学习的材料开发策略在不同的材料体系中均获得了成功[10]。因此,本文将以主动学习为例,简要介绍数据驱动材料设计的思路和关键步骤,主要包括以下5 个部分:材料数据库的特点及构建;材料描述符的构建及筛选;机器学习模型的构建和评估;优化试验设计;试验/计算验证及反馈。
1 主动学习简介
与传统的基于机器学习的材料设计思路相比,主动学习包括优化试验设计和数据反馈环节,这一环节能够在迭代的过程中快速提升机器学习模型的性能,进而加快材料研发效率。如图1 所示[10],首先,基于文献或实验室累计数据,构建所需的数据库,并利用数据算法,对数据进行清洗、降维等处理,以满足后续机器学习建模的需求;其次,根据对所研究材料的理解,构建材料描述符,增强后续机器学习模型的预测能力;再次,不同的机器学习算法均能够用于数据模型的构建,因此,需要利用标准误差等判据对数据模型的性能进行评估;相对于未知数据,已有数据体量通常较小,导致预测过程存在不确定性,基于预测值和伴随的不确定性,结合优化算法推荐最具期望的新材料进行验证;最后,基于算法的推荐,进行样品的制备、测试与表征(或者第一性原理计算),并将数据反馈到初始数据集,进行下一轮迭代,直至找到满足要求的目标材料[10]。在主动学习中,迭代停止准则可以基于以下3 个方面考虑:材料已经满足目标性能;优化算法的提升指标已经收敛;预算难以满足更多次迭代。
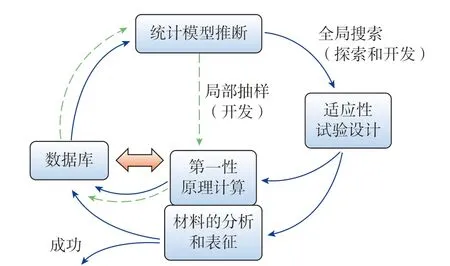
图1 基于主动学习的材料设计 Fig.1 Materials design based on active learning
2 数据库的构建
高质量的数据库是保证数据模型的预测精度和外推能力的基础。对于主动学习,数据库需要包括输入变量和输出变量,输入数据通常包括材料的元素含量、种类、晶体结构、加工工艺、微观结构等,输出数据包括材料的目标属性如力学性能、物理性能、化学性能等。在实际应用中,难以快速获得高质量的试验数据和理论模拟数据,需要借助文献中已经发表的数据或者已开放的数据库。对于文献数据,可以采用文本挖掘结合自然语言处理实现对数据的快速提取[11–12]。另外,目前存在多个开源数据库,例如Materials Project[13]、AFLOW[14]以及无机晶体结构数据库(ICSD)[15]等,包含数十万条数据,能够为模型提供大量的数据进行训练。值得注意的是,由于试验条件或者操作方式不一致,文献中的数据可能存在较大的不确定性,即对同种材料同种工艺,可能会产生偏差很大的结果,这需要在使用过程中仔细甄别。同时,已有的开源数据库通常基于理论模拟计算,和试验测试数据之间不可避免地存在偏差,如何将理论模拟数据用于指导试验设计,需要研究人员进行合理的考量。基于文献或者开源数据库建立的数据集,可能存在数据缺失或者重复的问题,可以利用机器学习算法对数据进行清洗、补全等处理,保证后续高性能机器学习模型的建立。
3 材料描述符的构建与筛选
材料描述符需要具有以下性质:相对于目标性能更容易获得、维度适中、具有可解释性。优异的描述符在提升数据模型性能的同时,能够增强模型的可解释性。材料描述符的构建可以采用手动和自动两种方式。前者通常包括以下3 类: (1)材料的物理特性如原子半径、电负性等; (2)材料晶体结构的坐标等; (3)对结构或者成分的二进制编码表示(One–hot)[7,16–17]。后者可以采用神经网络模型等对已有数据如组织结构图片进行建模,提取能够代表图片信息的关键潜在变量,即描述符,进行图片的重构和后续优化[18–19]。由于描述符的数值在数量级上会存在较大差别,可能导致模型偏向于某一特定描述符。因此,在建立数据模型之前,通常需要对描述符进行归一化处理,即将描述符映射到某一特定数值区间内,常用的归一化公式有:
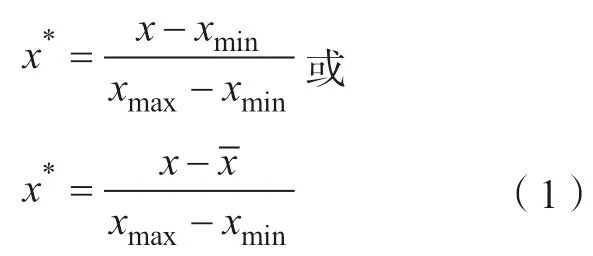
分别可以将数据映射到[0,1]和[–1,1]区间,其中xmax和xmin分别表示某一描述符数据的最大值和最小值;x-为该描述符数据的均值[20]。
描述符维度过高一方面会降低模型的训练效率,另一方面,不同描述符可能代表着类似的信息。为此,需要对描述符进行预先筛选,提取与目标性能最相关的描述符。评估描述符本身与目标性能之间的相关性的算法有多种,如皮尔逊相关系数(Pearson correlation coefficient,PCC),这一算法可以表征两个变量之间的线性相关性,但对于一些非线性的关系则难以捕捉[21];最大互信息系数(Maximal information coefficient,MIC)能够评估描述符间的复杂函数关系,如抛物线、三角函数等非线性关系。常用的描述符相关性表征算法和特点如表1 所示[22]。除了相关性分析,还有重要性排序算法如Lasso、随机森林、决策树等,能够根据描述符对目标性能的影响程度进行重要性排序[27–28]。经过筛选的描述符,可以进一步通过最佳子集选择、遗传算法等,确定最佳的描述符组合。
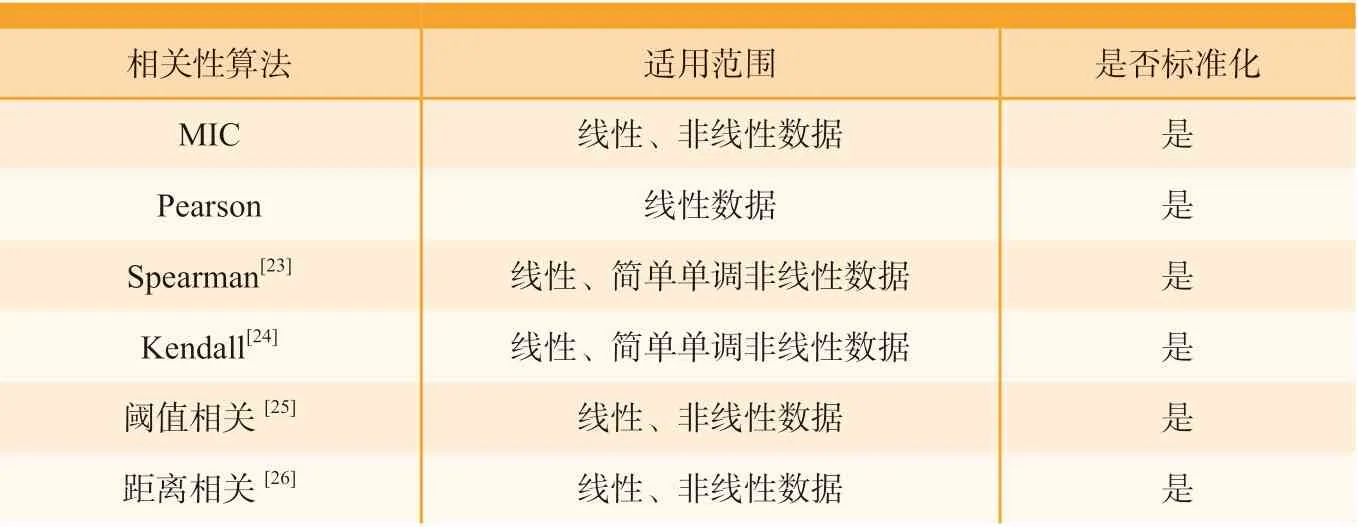
表1 相关性算法与特性Table 1 Correlation algorithms and characteristics
4 机器学习模型的构建与评估
基于构建的数据库,可以用多种机器学习算法训练代理模型,例如,线性模型、多项式模型、支持向量机、神经网络等。线性模型和多项式模型是基于最小二乘法,通过将均方误差最小化确定模型的参数。这一算法形式简单、容易解释,但效果通常难以满足要求。对于具有复杂模式的数据,需要更加复杂的算法如支持向量机和神经网络等。支持向量机在处理小数据量问题时展现了优异的性能,基本思想是利用核函数将数据映射到更高维度的空间,通过最大化不同类之间的超平面,实现分类效果,如图2 所示,其中少数支持向量决定了最终结果,这使得该模型不仅算法简单,而且可以抓住关键样本,去除冗余样本对分类的影响[29]。但是,支持向量机算法在应对大规模样本时会耗费大量的机器内存和运算时间从而难以实施,对于多分类问题也需要结合其他算法或组合多个二分类支持向量机解决。神经网络模型理论上可以映射任何复杂的非线性关系,但一般需要很多数据训练模型,同时,过多的超参数使得模型训练耗时长、成本高,并且模型通常难以解释。
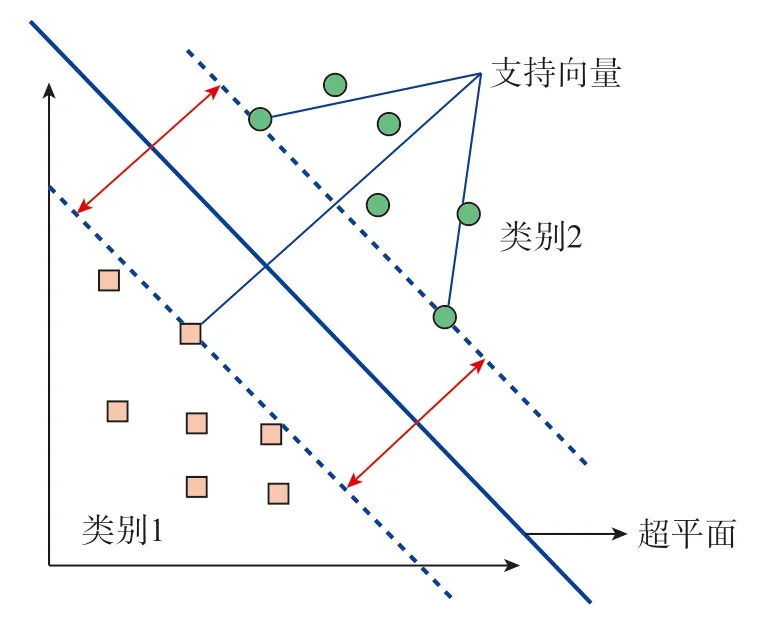
图2 支持向量机算法的二维平面表示Fig.2 Two-dimensional plane representation of support vector machine algorithm
在数据模型构建之后,为了避免过拟合和欠拟合,需要对模型性能进行评估。通常采用交叉验证的方法,将初始数据集划分为训练集和测试集,计算模型的误差或者精度。例如十折交叉验证是将训练数据集等分为10 个子集,每次选用其中9 个子集作为训练集训练模型,剩余的一个子集用作测试集测试模型性能,依次迭代10 次,直至每个子集都曾被用作测试集。由于十折交叉验证利用训练集的子集进行了测试验证,因此能够避免预测模型的过拟合,更可靠地评估模型的泛化能力。对于分类模型,常用的性能评估指标有准确率、错误率、ROC 曲线等。对于回归模型,常用的指标有平均绝对误差(Mean absolute error,MAE)、均方误差(Mean squared error,MSE)、决定系数(R2)等,表达式分别如下:
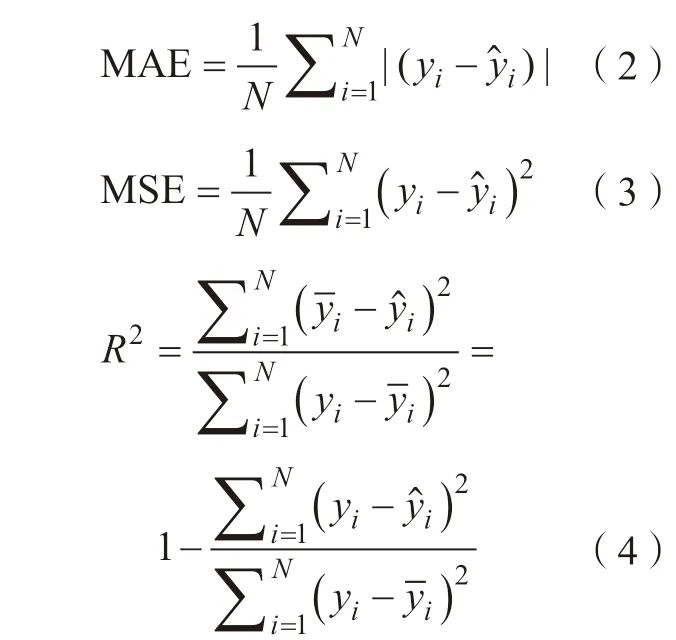
式中,yi表示目标性能的实际值;表示实际值的均值;表示模型的预测值;N为数据集材料的个数。
5 优化试验设计
未知材料空间巨大,无法对所有候选材料组分或者工艺参数进行验证。因此,需要借助优化算法,推荐最有可能提升材料性能的成分或者工艺参数组合,最大程度减少试验验证的次数[10]。常用的优化算法基于以下两种策略的平衡,即探索(Exploration)和开发(Exploitation)。探索的策略主要考虑选取未知材料分布中预测值不确定性最大的成分点,反馈到初始数据集,最大程度矫正数据模型对预测不准确的数据点的评估,但是,所推荐成分的性能通常难以满足要求。开发的策略基于对未知材料的预测,直接选择具有最大预测值的材料进行试验验证,虽然能够发现高性能材料,但可能会限于局部极值。因此,需要能够同时平衡开发和探索的策略,即全局优化算法(Efficient global optimization),可 以同时考虑预测值和伴随的不确定性,在保证推荐高性能材料的同时,能够跳出局部极值,最终提升新材料的开发效率。
6 验证和数据反馈
主动学习中的关键一步便是数据的反馈,因此,基于优化算法推荐的成分或者工艺,需要进行试验或者模拟验证,将数据反馈到初始数据集,快速提升数据模型的性能,提升迭代的效率。目前,所用的验证方法主要为试验。但是,对于某些极端条件或者电子尺度的性能,试验表征难以实现,可以选择理论模拟的手段进行验证。例如基于密度泛函理论(Density functional theory,DFT)可以计算晶体在0K 下的各种性质如弹性模量、带隙等[30];基于热力学理论的CALPHAD(Calculation of phase diagram)计算可以模拟和预测材料的相图[31];分子动力学(MD)和有限元模拟(FEM)可以分别在微观尺度和介观尺度上预测材料的相变和力学行为[32–33]。
数据驱动方法在航空发动机材料中的应用
航空发动机材料的恶劣服役环境给材料的研发带来了巨大的挑战,新材料从开发到应用可能要经过数十年的时间。本部分将以典型的航空发动机材料为例,如高温合金、钛基合金、陶瓷基复合材料、热障涂层等,介绍基于机器学习的数据驱动方法在其中的应用及最新进展。
1 高温合金
针对高温铁基奥氏体不锈钢的抗蠕变性能,Shin 等[34]将热力学计算的高温下相体积分数、相元素含量等作为输入变量建立模型,发现这些基于热力学计算的参量对蠕变性能的数据模型有较大影响。之后,该团队结合热力学参数和机器学习预测了9%~12% Cr 铁素体/马氏体钢在不同温度下的屈服强度,发现在较低温度下模型的R2可以达到0.9 以上,但是,随着温度升高,模型的准确率迅速下降,这可能是高温下数据缺乏和变形机制的改变所导致的[16]。在机器学习预测钴基或镍基高温合金性能的研究中,Yu 等[7,35]采用合金成分,元素性质和时效温度、时间等热处理工艺参数作为描述符,成功预测了高温合金中γ′相的溶解温度和体积分数等;Zou 等[36]采用多重扩散法(Diffusion–multiple approach)获得了1375 个具有γ/γ′两相区的材料成分和γ′相的体积分数,利用建立的数据库,通过随机森林、深度神经网络等算法构建了能够准确预测高温合金γ′相体积分数的机器学习模型。此外,Tamura 等[37]利用机器学习建立了气体雾化过程参数与晶粒尺寸的关系,所得结果与Lubanska 提出的公式中的趋势一致,并以此优化了Ni–Co 基高温合金粉末冶金过程的工艺参数。镍基高温合金中拓扑密堆相(TCP)的存在会消耗强化元素并促进裂纹的产生,针对这一问题,Qin 等[38]基于高通量试验获得的数据库,以合金成分和元素的混合熵、价电子浓度等物理参数为描述符,利用机器学习预测了合金中拓扑密堆相的存在,可以指导合金成分的快速筛选。上述利用材料微观结构的研究都采用了人工识别的方法,而在另外一项研究中,Khatavkar 等[18]利用图像识别技术提取材料微观结构信息作为描述符,如图3 所示[18]。首先将CMSX–6 和DZ125 两种镍基高温合金的原始扫描电镜图像(图3(a)和(d))进行阀值处理,产生只有黑白两种颜色的图像,如图3(b)和(e)所示;之后通过图像识别技术提取图片信息如图3(c)和(f)所示,作者将这种描述符用于机器学习并实现了对镍基高温合金硬度的精确预测。

图3 通过图像识别技术得到镍基高温合金微观结构信息Fig.3 Microstructure information of Ni-based superalloys obtained through image recognition technology
2 钛基合金
人工神经网络等机器学习技术已广泛应用于钛基材料的研究中,如对Ti–6Al–4V 合金的流动应力[39]、微观组织演化[40]、机械性能[41]与工艺参数[42]的预测等。Arisoy 等[43]利用随机森林模型研究了切削速度、刀具几何形状等工艺参数对合金显微组织和性能的影响,并通过遗传算法,根据所需的组织和硬度选择合适的加工工艺。Harsha 等[44]利用神经网络算法研究了切削速度、给进量、切削时间等输入参数与刀具磨损、钛合金表面粗糙度等输出响应之间的关系。另外,有研究通过机器学习预测了Ti–6Al–4V 合金切削过程中的无颤振加工条件,并提高了工件表面的质量和刀具寿命[45]。对于其他的钛基合金,有学者利用神经网络模型,预测了纳米B4C 粒子增强型Ti–6Al–4V 合金磨损性能[46];根据钛合金成分和热处理温度预测合金中的α 相和β 相的体积分数[47];建立了Ti–2Al–9.2Mo–2Fe 合金应变量、应变率、温度和流变应力之间的预测模型,优化了热加工条件[48];以钛合金相组成、氧化温度、氧化时间、氧气和水蒸气含量作为描述符,通过梯度提升树、随机森林和k–近邻3 种机器学习模型预测合金高温氧化的抛物线速率常数,其中梯度提升树模型的R2可以达到0.92,这是一种基于梯度下降法和决策树的集成算法,泛化能力较强,可以灵活处理各种类型的数据,包括连续值和离散值[49];基于扩散复合技术产生的多组分变化数据库,通过BP 神经网络建立了新型钛合金(Ti–3Al–2Nb–1.2V–1Zr–1Sn–xCr–yMo)的成分–显微组织–性能之间的模型,并成功设计出性能优异的钛合金[50]。
3 复合材料
复合材料因其优异的耐高温、抗氧化、高比强度、抗蠕变等性能,是新一代航空发动机备受青睐的新型材料,包括陶瓷基复合材料、碳/碳复合材料、金属基复合材料等[51]。神经网络模型常应用于复合材料性能和行为的预测,如图4 所示[52],Pramod等[52]建立了预测Al2O3颗粒增强Al2075 复合材料磨损性能的人工神经网络模型,以密度、施加载荷、滑动距离和颗粒的质量分数作为描述符预测表面磨损高度,其中隐藏层的作用是把输入数据的特征抽象到另一个维度空间,使得更抽象化的特征能够更好地映射模型输出。SiCf– BN/SiC 复合材料中的纤维分布和基体形成层状结构,这种结构使得合金的陶瓷基体在横向载荷下产生的连续性受损成为引发失效事件的关键因素。针对这一现象,Patel 等[53]通过神经网络模型量化连续纤维增强陶瓷基复合材料在相关尺度下的损伤,预测出最能抵抗基体损伤的纤维微结构。Canakci 等[54]以时效温度、时间等热处理工艺参数、B4C 增强颗粒的尺寸和体积分数作为输入,硬度、抗拉强度、屈服强度和弹性模量作为输出,建立了预测Al–Cu–Mg 基复合材料性能的神经网络模型(错误率仅有2%),发现热处理工艺很大程度上决定了材料性能。随着复合材料制造技术的提升,分级、多孔、多维等复杂结构大大扩展了复合材料的设计空间,也使得结构优化变得至关重要,机器学习正是一种选择最佳结构的有效手段,从而发挥复合材料的最大潜力。
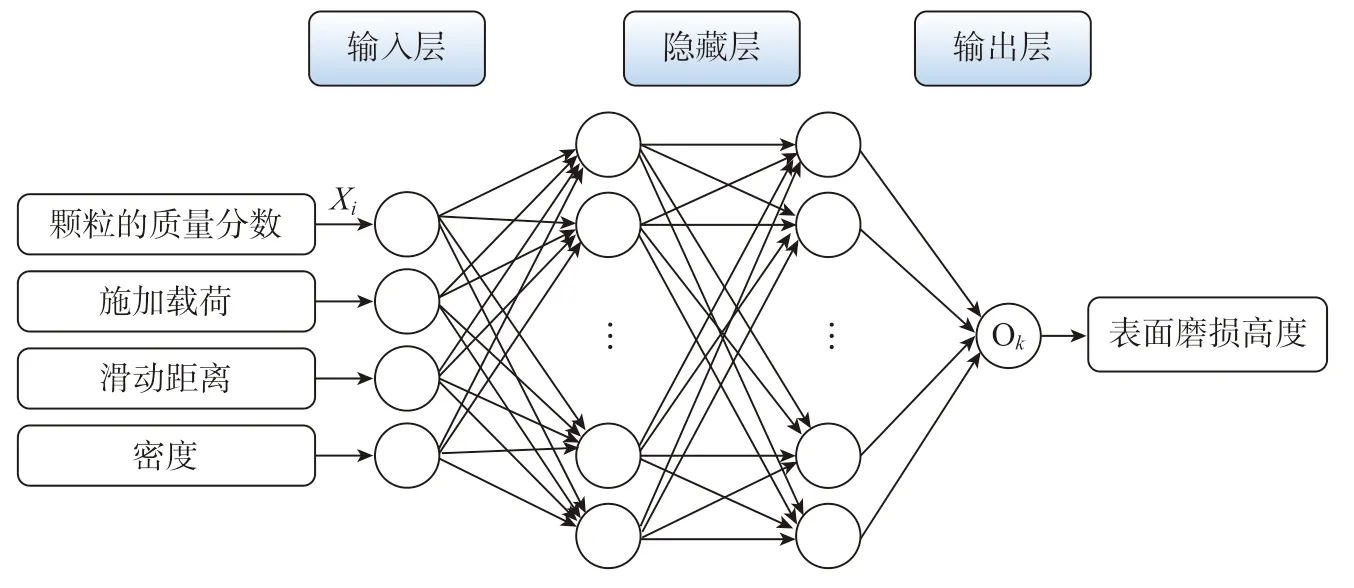
图4 神经网络模型预测复合材料的磨损性能Fig.4 Neural network model used to predict the wear performance of composite materials
4 热障涂层
晶格热导率决定了非金属材料的导热能力,是设计热障涂层的重要参数。Chen 等[55]通过基于随机森林的特征选择建立了高斯回归模型预测晶格热导率,在19 个样本的测试集里达到0.93(R2)的准确性,但由于数据集较小,存在过拟合的风险。为了提高泛化能力,Juneja 等[56]结合通过高通量计算得到的描述符,利用包含2162 种材料的数据集进行机器学习,得到了高鲁棒性的预测模型,实现了对晶格热导率的准确预测。Loftis 等[57]关注了符号回归、多层感知器的深度神经网络、随机森林回归3 种模型在347 个样本的数据集上对晶格热导率的预测能力和不同特点,随机森林通过集成学习降低了过拟合的风险;多层感知器的深度神经网络能够从数据集中准确发现非线性关系;符号回归虽然计算量大、耗时长,但会产生具有物理意义的公式,图5 所示为符号回归得到的公式和预测结果[57],公式中的符号都为数据集中包含的描述符,这对理解描述符的作用和设计具有高晶格热导率的涂层材料有很大的价值。描述符的数据可以来源于各种测量仪器,有学者利用神经网络模型学习红外成像数据,模拟热响应与热障涂层厚度的关系[58];通过BP 神经网络优化超声反射系数谱特征参数,并利用高斯回归算法预测热障涂层的孔隙率,其误差小于5.3%[59];通过多元线性回归、BP 神经网络、支持向量机3 种模型,结合涂层的太赫兹光谱特征预测材料的微观结构(孔隙率、孔隙裂纹比、孔径等)[60]。数值型、图案型、图表型等不同类型的数据都可以通过特征工程转化为可用于机器学习的数据,从而帮助理解机器学习模型和分析原始数据与目标性能的关系。
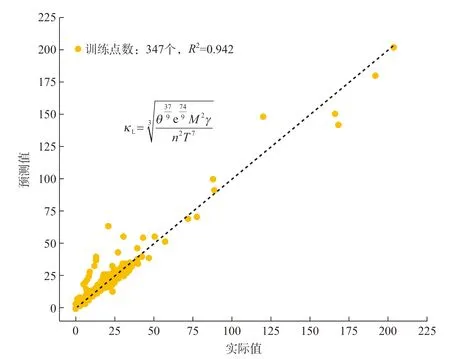
图5 基于符号回归得到的计算公式与模型的预测结果Fig.5 Calculation formula and results of model prediction based on symbolic regression
5 分析与讨论
通过机器学习模型预测材料力学性能或断裂、氧化等失效行为的关键在于寻找合适的描述符,从而提高预测模型的准确性和可解释性,因此,如何收集和选择描述符数据是材料研究与机器学习结合的重点之一。对于高温合金,材料的微观组织结构是决定其性能的重要因素,但这种信息往往需要研究人员或专家从材料的显微图像中提取,过于依赖科研人员的个人知识与经验。研发适用于材料科学的计算机图像识别技术,可以从文献资料里大量的显微图像中快速有效地提取关键信息,甚至得到一些研究人员难以直接观察到的结构信息。高温钛合金常用于航空航天发动机复杂结构件,对性能要求较高的同时也提高了加工工艺的难度,如何采集各种工艺参数及其对工件性能或结构变化的响应信息,并将其转化为可用于机器学习的数据是应用这一技术设计工艺参数的关键。另一方面,钛合金的组织与性能对热处理温度、时间等工艺参数敏感,例如合金在β 转变温度以上退火时,晶粒会迅速长大,从而降低材料的力学性能,因此,这要求机器学习模型能够准确预测材料性能并通过逆向设计推荐合适的参数。在复合材料领域,机器学习对界面的研究还比较少见,而这一因素对复合材料的物理、化学等性能有重要的影响,界面的结合状态和强度,以及界面的传递效应、阻断效应、不连续效应等都可以应用机器学习进行研究。降低热导率是设计热障涂层的首要目标,目前机器学习的应用只集中于普通材料的晶格热导率,而忽略了涂层本身的微观结构和形态也是影响其导热能力的重要因素。
结论与展望
本文回顾了机器学习在航空发动机材料中的应用,主要关注了基于主动学习的材料开发和优化策略,对主动学习中每一个步骤进行了较为详细的总结,并系统回顾了机器学习或者数据驱动算法在高温合金、钛基合金、复合材料、热障涂层等方面的应用。虽然目前机器学习正在被越来越多地用于航空发动机材料研究中,但是依然存在大量的问题,需要用机器学习技术去解决。例如,目前的方法主要集中于利用机器学习构建成分、工艺与性能之间的预测模型,但是基于预测模型进行逆向设计的研究还比较鲜见。同时,航空发动机材料的组织结构对最终服役性能至关重要,目前的研究对组织结构的关注不够。将图像识别技术应用于材料微观组织结构的量化,并充分利用机器学习逆向设计的优势设计新材料是解决这些问题的关键。值得注意的是,因为航空发动机材料的服役环境恶劣,导致服役数据难以获得,即能够用于训练机器学习模型的数据集有限。这会导致数据模型的高度不确定性,如何解决数据的缺乏问题,是这一领域面临的关键问题。这一问题有望通过以下思路解决。
(1)利用迁移学习,从容易获得的数据中挖掘信息,用于较少数据的建模,提升模型预测能力;
(2)发展不确定性评估方法,对基于小数据的预测模型进行不确定性估计,有效利用不确定性来推荐候选材料或工艺,减少试验次数;
(3)有效利用材料科学中存在的大量成熟理论如热力学和动力学模型,提升数据模型性能,缩小待探索的未知材料/参数空间;
(4)研发文本挖掘和自然语言处理技术,利用文献发表的数据,扩大样本数量。
总之,基于机器学习的材料研发是一种材料研究的新范式,将加速材料的开发效率,降低成本。这一新的研究方向结合了材料科学和数据科学、计算机科学、人工智能,是一个多学科交叉的研究领域,需要材料领域与计算机领域的专家相互协作,进一步推动其快速发展。
猜你喜欢
铝加工(2022年3期)2022-11-24
材料与冶金学报(2022年2期)2022-08-10
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
粉末冶金技术(2021年3期)2021-07-28
计算机应用与软件(2020年6期)2020-06-16
速读·下旬(2019年11期)2019-09-10
电子制作(2019年2期)2019-02-14
电影(2018年8期)2018-09-21
雷达科学与技术(2017年5期)2018-01-15
