
基于单哈希多维布隆过滤器的DDS自动发现算法
2021-10-15 12:49樊智勇刘哲旭
计算机应用与软件 2021年10期
樊智勇 腾 达 刘哲旭
1(中国民航大学工程技术训练中心 天津 300300) 2(中国民航大学电子信息与自动化学院 天津 300300)
0 引 言
数据分发服务DDS是一种高性能的中间件,能够以较小的开销实现可预测的数据分发。对象管理组织(Object Management Group, OMG)先后颁布了Version1.0、Version1.1和Version1.2规范[1-3]。该规范定义了一个与用户具体使用的平台、语言、所处位置都不相关且可扩展的基础服务模型[4]。DDS采用以数据为中心的发布/订阅通信模式,使分布式系统能够实现数据高效、可靠的发布与订阅[5]。目前,DDS已经被成功应用于海军作战管理、空中交通管制和船舶等系统[6]。
针对DDS自动发现过程,RTI(Real-time Innovations)提出了基于简单发现协议的自动发现算法SDP_ADA(Simple discovery protocol automatic discovery algorithm)[7]。该算法在中小型实时系统中取得了良好的效果,但当系统的规模增大时,大量的数据需要频繁地交换,会产生网络数据传输量和内存消耗较高的问题。文献[8]将DDS简单发现协议和标准布隆过滤器Bloom结合,提出了一种自动发现算法SDPBloom。在自动发现过程中,SDPBloom通过Bloom存储端点描述信息,有效地解决了 SDP_ADA中存在的高内存消耗和高网络数据传输量等问题,增强了DDS的可拓展性。但是SDPBloom的实现需要大量的哈希函数运算,导致CPU资源消耗过多,并在分布式系统中产生了一定的延迟。为解决这一问题,本文提出了一种基于单哈希多维布隆过滤器的自动发现算法。该算法中的OMBF通过一个哈希函数和取模运算代替SDPBloom中多个哈希函数,降低了参与者端点匹配过程的计算量。
1 DDS简单发现协议
域是一个虚拟网络概念,它有助于隔离和优化分布式应用程序之间的通信。只有同一个域中的域参与者才能相互通信[10]。域参与者由发布者和订阅者组成,每个发布者和订阅者分别管理一个或多个数据写入者和数据读取者。本文将数据写入者和数据读取者统称为端点。只有数据写入者和数据读取者具有相同的主题时,域参与者才能建立通信。域参与者之间的数据传输通过自动发现协议完成。
DDS简单发现协议可以分为简单参与者发现阶段和端点发现阶段[11],两个阶段的发布/订阅关系如图2所示。

图2 SDP自动发现过程
简单参与者发现阶段:域参与者之间进行相互发现。本地域参与者通过数据写入者向其他域参与者发送数据包,同时也会通过数据读取者读取其他域参与者发送的数据包。
简单端点发现阶段:本地域参与者与其他域参与者进行相互匹配。它们相互交换包含主题名称、主题类型和服务质量策略等信息的数据包。
在DDS简单发现协议中,每个本地域参与者需要将自己所有的端点信息发送给其他域参与者,同时也会接收其他域参与者发送的所有的端点信息,这会产生大量的内存消耗和网络传输量。事实上,每个域参与者只关心与自己订阅主题相关的端点信息。因此,本文提出了基于单哈希多维布隆过滤器的自动发现算法。
2 算法设计
为降低标准Bloom的哈希计算量,本文提出了一种新型布隆过滤器OMBF。为降低DDS自动发现过程中的内存消耗和数据传输,本文将OMBF与DDS简单发现协议结合,提出了自动发现算法SDP_OMBF。
2015年9月,沙特阿拉伯和巴林签署价值约3亿美元的新输油管道铺设合同。该管道由沙特阿美石油公司和巴林石油公司共同管理,将把原油从沙特阿美公司位于沙特东部的布盖格炼油厂输送到巴林石油公司炼油厂。
2.1 OMBF
OMBF是一种高效率的空间随机数据结构,它用位数组简洁地表示一个集合,并可以判断一个元素是否属于这个集合。OMBF是一个多维向量,每一维向量分为k个分区且初始值为0。向量维数用t表示,每一维向量分区i的大小用mi(1≤i≤k)表示。
OMBF的哈希函数计算过程分为以下三个阶段:
(1) 哈希阶段:A→B。A是将要存储或查询的集合中的元素,B是经过哈希函数映射之后的机器字。
(2) 选维阶段:B→C。C是OMBF向量某一维,通过对B取模得到,即|B|(h(x)modt)。每次取模的结果选中OMBF向量某一维。
(3) 取模阶段:B→D。D是OMBF向量某一维中的位置,通过对B取模得到,即|B|(h(x)modmi)。每次取模的结果使OMBF向量某一分区中某一位置为1。
如果每维向量中每个分区大小为互质,那么OMBF中这种不均匀的分区方法将会产生相互独立的取模结果。更确切地,如果gi(x)=h(x) modmi,每个分区满足条件(mi,mj)=1,1≤i≤j≤k,即mi、mj为相对素数,那么g1(x)、g2(x)、…、gk(x)相互独立。
图3表示OMBF的结构,其中假设k=3,集合S{x1,x2}中的元素通过一个哈希函数h(x)和取模运算存储在OMBF中。
通过实例说明OMBF的工作原理。假设m1=11、m2=13、m3=19。当存储元素x1时,首先,在哈希阶段通过哈希函数h(x)转换成机器字h(x1),设h(x1)=9 655;然后,在选维阶段d=h(x1) modt,即将元素x1映射到OMBF向量中第d维;最后,在取模阶段机器字h(x1)分别对各分区进行取模。g1(x1)=h(x1) modm1=8,g2(x1)=h(x1) modm2=9,g3(x1)=h(x1) modm3=3,即第d维三个分区对应第8位、第9位、第3位。当查询某一元素是否属于集合S时,将待查询元素经过3个阶段运算之后,检查相应3个位置是否为1,如果是,则判定该元素属于集合S。
2.2 OMBF性能分析
OMBF和Bloom一样,在元素查询过程中也会发生误报。OMBF误报由两个因素导致:(1) 在哈希阶段,由机器字冲突发生的误报,用a表示;(2) 在取模阶段,在机器字不发生冲突的情况下,机器字取模余数发生冲突导致的误报,用b表示。OMBF总的误报率用FOMBF表示,计算如下:
FOMBE=P(f)=P(f|a)P(a)+P(f|b)P(b)=
P(a)+P(f|b)(1-P(a))
(1)
(2)
同理,可以得到机器字取模余数发生冲突导致的误报率为:
(3)
通常机器字的长度远大于OMBF向量,所以P(a)接近于0。OMBF的误报率可以简化为:
(4)
由于SDPBloom中的哈希函数数量等于SDP_OMBF中每一维的分区数,即哈希函数数量为k,其误报率FSBF为[12]:
(5)
(6)
2.3 SDP_OMBF
在OMBF和简单发现协议SDP的基础上,本文提出了一种新的自动发现算法SDP_OMBF。SDP和SDP_OMBF的自动发现执行过程如图4所示。

(a) SDP执行过程
图4用两个节点通信的实例说明SDP和SDP_OMBF执行过程,实例中本地参与者A向远程参与者B发送端点信息。SDP_OMBF的执行过程如图4(b)所示。在参与者发现阶段,将本地参与者端点描述信息生成OMBF向量,然后和本地参与者数据包一块发送至远程参与者。参与者端点描述信息使用参与者端点信息唯一标识符,本文使用主题名作为唯一标识符。在端点发现阶段,远程参与者根据自身订阅的主题对OMBF进行查询。如果存在订阅主题,则向本地参与者发送订阅信息,本地参与者将被订阅的主题数据包及服务质量发送至远程参与者进行下一步匹配,如果匹配成功,两参与者建立通信。而在图4(a)所示的SDP的执行过程中,远程参与者将会订阅和接收本地参与者所有的端点信息。本文提出的SDP_OMBF将大量的端点信息减少为一条OMBF向量信息,因此,可以有效地减少自动发现过程中的内存消耗和网络传输量。
3 实 验
本节通过仿真和实验验证SDP_OMBF的有效性。本文将SDP_OMBF与使用较广的DDS改进自动发现算法SDPBloom进行对比,验证SDP_OMBF网络传输量和内存消耗、主题查询时间和误报率。实验平台为Intel(R)CPU Core(TM) i5-3210、12 GB DDR 3(1 600 MHz)存储器和4核×2线程(2.5 GHz),软件环境为DDS分布式互联架构平台。
3.1 网络传输量和内存消耗验证
实验设置了1 000个参与者,每个参与者发布100个主题,每个主题信息是6 800字节,主题关键字为4字节。在SDPBloom和SDP_OMBF中,存储主题关键字的向量为72字节。在端点发现阶段,当查询主题关键字中成员元素的比例从10%到90%变化时,SDP_OMBF和SDPBloom的网络传输量和内存消耗如图5和图6所示。
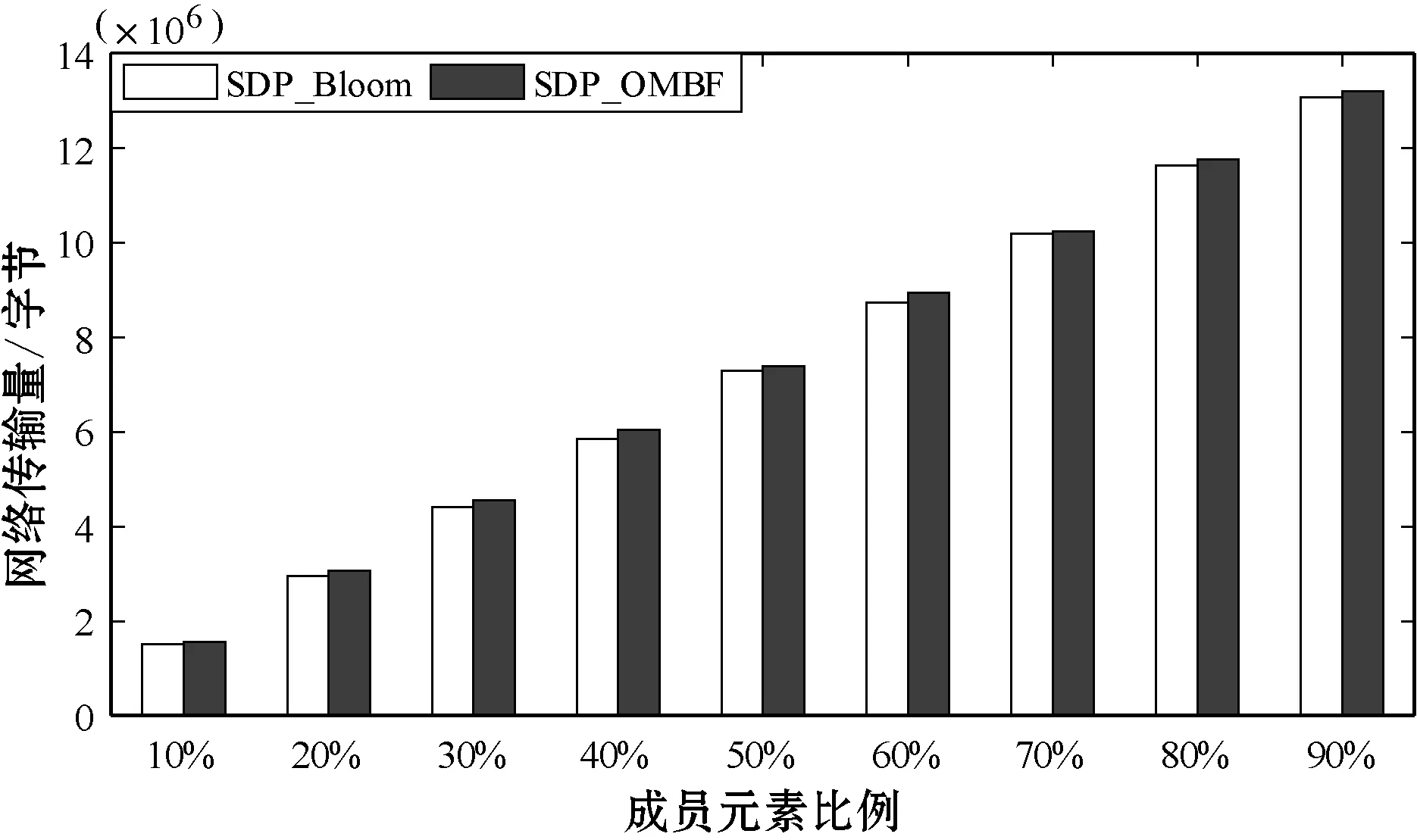
图5 SDPBloom和SDP_OMBF的网络传输量
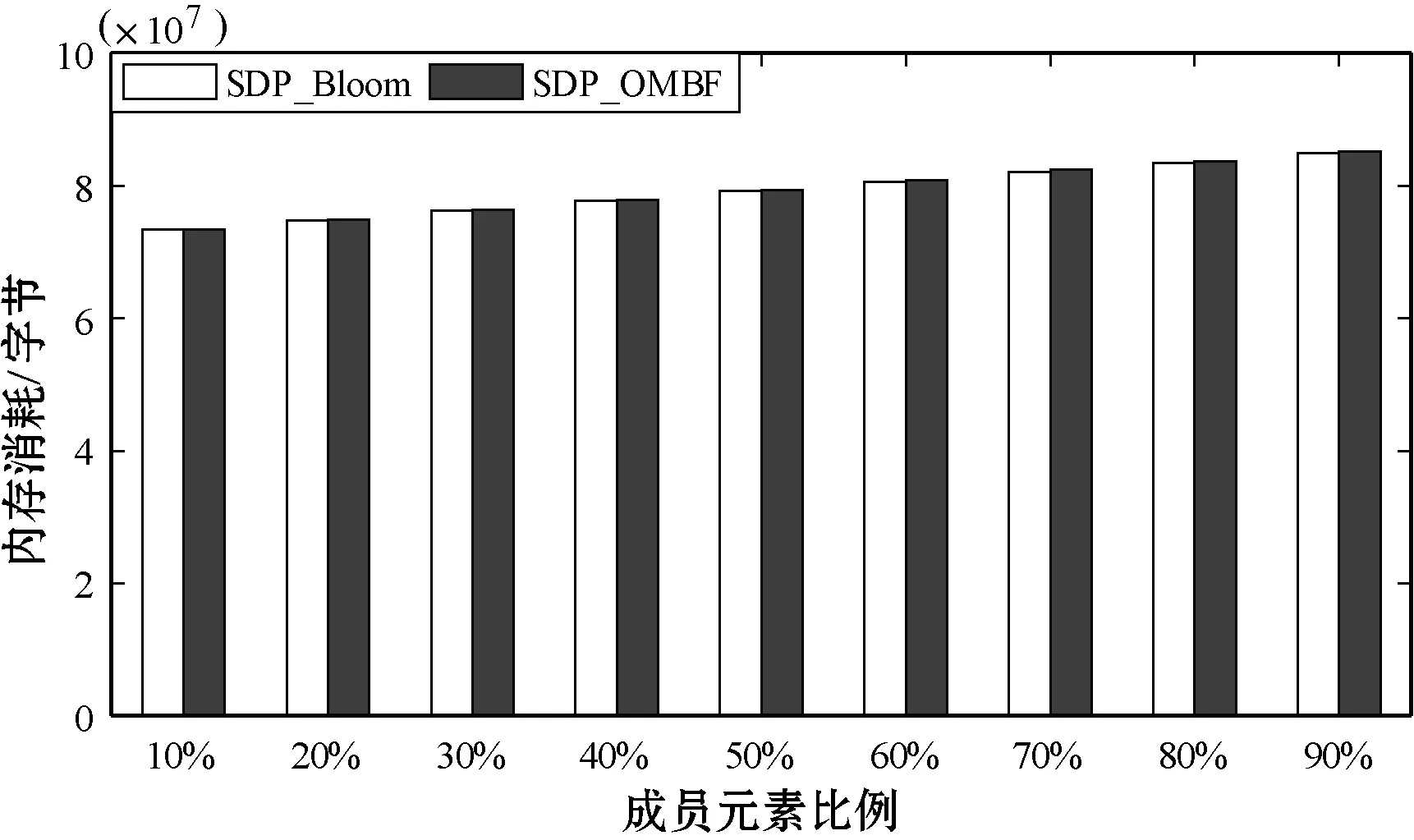
图6 SDPBloom和SDP_OMBF的内存消耗
可以看出,当端点匹配逐渐增大时,SDPBloom和SDP_OMBF中的网络数据传输量和内存消耗也逐渐增大。无论端点匹配率如何变化,两者网络数据传输量和内存消耗都近似相等。
3.2 主题查询时间和误报率验证
本文实验中,参与者端点信息的每个主题关键字大小为4字节。在SDP_OMBF中,本地参与者n个主题关键字映射到OMBF向量中。远程参与者查询主题关键字成员元素比例在10%至90%之间变化。令m=150、n=100、k=3、t=3。SDP_OMBF中的哈希函数为MD5,SDPBloom中的哈希函数为MD5、MD2和SHA-1。
当m变化时,进行了100组实验,实验结果如表1、表2所示。

表1 m=561时,SDPBloom和SDP_OMBF误报率和计算时间对比

表2 m=1 413时,SDPBloom和SDP_OMBF误报率和计算时间对比
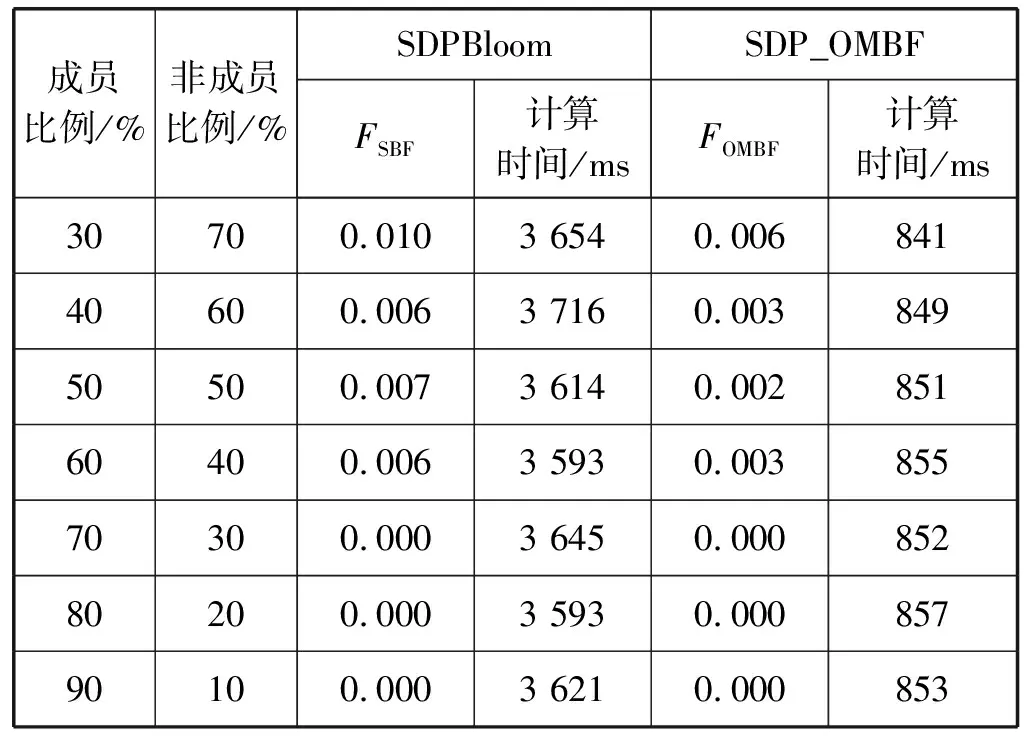
续表2
从表1和表2可以看出,当m较小时,SDP_OMBF的误报率略大于SDPBloom;当m增大时,两者误报率近似相等。然而,SDP_OMBF的运算时间始终低于SDPBloom约3 000 ms。
4 结 语
本文对 DDS 中SDP_ADA和SDPBloom自动发现算法进行了深入研究, 在分布式仿真系统规模较大时,针对数据传输过程中SDPBloom自动发现算法存在哈希函数运算量大的问题,提出一种新型的自动发现算法SDP_OMBF。通过实验验证了该算法的有效性。与SDPBloom算法相比,该算法在保证网络数据传输量和内存消耗基本不变的条件下,将哈希函数运算时间降低约78%,从而降低自动发现过程中参与者端点之间发布/订阅信息的时间,提高了分布式仿真系统的实时性。
猜你喜欢
南京理工大学学报(2022年1期)2022-03-17
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2021年1期)2021-01-13
电脑爱好者(2020年20期)2020-10-22
语数外学习·高中版中旬(2020年8期)2020-09-10
中学生数理化·教与学(2019年8期)2019-09-18
数学大王·中高年级(2018年7期)2018-08-29
青少年科技博览(中学版)(2017年4期)2017-06-13
养生保健指南(2017年4期)2017-05-26
电脑爱好者(2015年13期)2015-09-10
