
多特征混合模型文本情感分析方法
2021-10-14 06:34李文亮杨秋翔
计算机工程与应用 2021年19期
李文亮,杨秋翔,秦 权
中北大学 软件学院,太原 030051
文本情感分析,也称为观点挖掘,是文本分析领域中的一个热点问题。它以文本中的主观信息为研究对象,识别主观信息所表达观点的情感取向。因此,在文本情感分析研究之前,首先需要将文本分为主观和客观两部分,然后再对文本情感进行分析。
文本情感分析是一项艰巨的任务,它在文本情感表达、文本格式和文本语言等方面面临很多问题。在文本情感表达方面,文本情感不透明,例如:“这座山很高”和“山里噪声很高”,两种表达都使用“很高”形容,却表达了两种相反的情感极性;在文本格式方面,大量文本主要来自互联网,具有不同的长度和格式;在文本语言方面,中文文本与英文文本的自身属性有很大的不同:中文文本需要分词,而英文文本的每个单词被空格分开。上述问题为文本情感分析任务中的文本向量化表示和语义特征提取带来了极大的挑战,直接影响文本情感分析的准确率。近年来,深度学习方法被广泛应用到文本情感分析任务中,为文本向量化表示和语义特征的提取提供了有效的方法。
近年来,深度学习方法被广泛应用到文本情感分析,为文本情感分析提供了有效的方法。其中文本卷积神经网络(Text Convolution Neural Network,TextCNN)最具代表性。但是TextCNN 的语义特征提取存在以下缺点:卷积层针对句子长度执行一维卷积,只能提取句子维度的语义特征,丢失词嵌入维度的语义特征;池化层采用单个最大池化操作,会造成部分语义特征的丢失;受局部窗口大小的限制,无法学习文本的长期依赖关系。针对上述缺点,本文提出了基于BiLSTM-MFCNN混合模型的文本情感分析方法,以获得更好的文本情感分析效果。该方法首先通过BiLSTM 学习文本的长期依赖关系。同时,对TextCNN 的卷积层进行改进,提出四种不同的卷积算法,获取句子维度和词嵌入维度的语义特征。其次,对TextCNN 的池化层进行改进,分别使用最大池化和平均池化算法获取句子维度和词嵌入维度的最大池化特征和平均池化特征。以此来发掘文本隐藏的语义信息,提升文本情感分析效果。
本文在NLPCC Emotion Classification Challenge数据集、COAE2014 数据集和Twitter 数据集进行实验,并和多种基准模型进行了对比。实验结果表明本文提出的BiLSTM-MFCNN 模型在上述三个数据集上取得了比NBSVM、TextCNN、DCNN、MVCNN、BiLSTM 和RCNN 等一些基准模型更好的文本情感分析效果。综上,本文的贡献如下:
(1)改进TextCNN,提出了多特征卷积神经网络(Multiple Features Convolution Neural Network,MFCNN)。
(2)结合BiLSTM 和MFCNN 模型的优势,利用BiLSTM-MFCNN混合模型在中英文三个数据集上实验,验证了该混合模型在文本情感分析任务中的有效性。
1 相关工作
随着文本情感分析研究的发展,文本的情感粒度越来越详细,从传统的二元情感(正负)到三元情感(正,中性和负)。由于人类情感的复杂性,上述简单的情感极性划分并不能很好完成实际的文本情感分析任务。因此Wu 等[1]进一步将情感分为32 类,使情感的表达更加精细。上述文本情感粒度的详细划分为文本情感分析方法的研究提供了良好的基础。
传统的文本情感分析方法主要依靠高质量的情感词典实现。但对于文本情感分析的某些特定任务,通常使用合并,扩展和重建情感词典的方法提升情感分析效果。
随着机器学习的快速发展,许多学者将机器学习的相关算法应用于文本情感分析。例如:Arunachalam等[2]分析了情感极性分析中常用的机器学习算法,包括贝叶斯算法、LDA(Linear Discriminant Analysis)算法、朴素贝叶斯算法(Naive Bayes,NB)、支持向量机(Support Vector Machines,SVM)、最大熵算法和KNN(K-Nearest Neighbor)算法。上述基于情感词典和机器学习算法的文本情感分析方法,不仅需要手动构造高质量的情感词典和相应的特征工程,而且会耗费大量的人力资源,很难在开放领域的文本情感分析任务中得到广泛应用。
近年来,深度学习在文本情感分析任务中取得了很大的成就。例如:Vieira等[3]提出了一种句子维度的卷积神经网络,为不同情感类型的句子设置不同的超参数进行训练,实现句子维度的文本情感分析任务,为句子维度情感分析提供了很好的方法,之后许多学习者以此为基础,从多通道特征和多视图特征两个方面对文本情感分析方法进行了更加深入的研究。例如:Yoon等[4]使用多通道词嵌入的CNN-BiLSTM 模型进行文本情感分析,能够捕获到文本中的高级语义关系和长期依赖关系,并在Twitter提供的情感分析数据集上取得了很好的效果。Chen 等[5]提出了多通道信息交叉(Multi-channel Information Crossing,MIX)模型,MIX比较不同粒度的文本片段,形成一系列多通道相似性矩阵,并与另一组精心设计的注意力矩阵交叉使用,提取出更加丰富的句子特征。Yin等[6]提出了一种多通道和可变卷积大小的卷积神经网络(Multichannel Variable-size Convolution Neural Network,MVCNN)用于句子分类。MVCNN 使用多通道输入的方法,集成不同特征的词嵌入矩阵表示文本信息。然后,使用不同大小的卷积核提取句子的语义信息,实现句子的分类。实验结果表明MVCNN 在Twitter 情感预测以及主客观信息分类任务中取得很好的效果。上述基于深度学习的文本情感分析方法,无论是与句子长度相关,还是与多通道特征和多视图特征相关,都是通过提取各式各样的句子维度的语义特征,提高文本情感分析的准确性,完全忽略了文本的词嵌入维度和长期依赖的语义特征。
2 BiLSTM-MFCNN混合模型的结构
BiLSTM-MFCNN混合模型结构如图1所示,由输入层、BiLSTM-MFCNN混合模型层、输出层三部分组成。

图1 BiLSTM-MFCNN混合模型结构图Fig.1 BiLSTM-MFCNN hybrid model structure diagram
(1)输入层:该层使用Word2Vec 语言处理工具的Skip-Gram模型实现文本的词嵌入向量化表示。
(2)BiLSTM-MFCNN 混合模型层:该层由BiLSTM模型和MFCNN模型组成。BiLSTM模型用于学习文本的长期依赖关系。MFCNN模型包含卷积层、池化层和全连接层。卷积层,使用不同的卷积算法提取词嵌入矩阵中句子维度和词嵌入维度的语义特征;池化层,使用最大池化和平均池化算法获取句子维度和词嵌入维度的最大池化特征和平均池化特征;全连接层,对最大池化特征和平均池化特征降维,得到包含文本语义特征的一维向量。
(3)输出层:该层使用激活函数对全连接层的一维向量进行计算,输出文本情感分析结果。
2.1 输入层
Word2Vec 模型通过训练可将文本内容映射成为n维空间向量,以此来表示文本语义关系。Word2Vec 通过CBOW 和Skip-Gram 两种语言模型实现词语的向量表示,其中CBOW 语言模型主要根据上下文词语预测中心词语的概率,而Skip-Gram语言模型主要根据中心词语来预测上下文词语的概率。本文使用Skip-Gram语言模型对维基百科中文语料库进行训练生成词向量。Skip-Gram语言模型结构如图2所示。
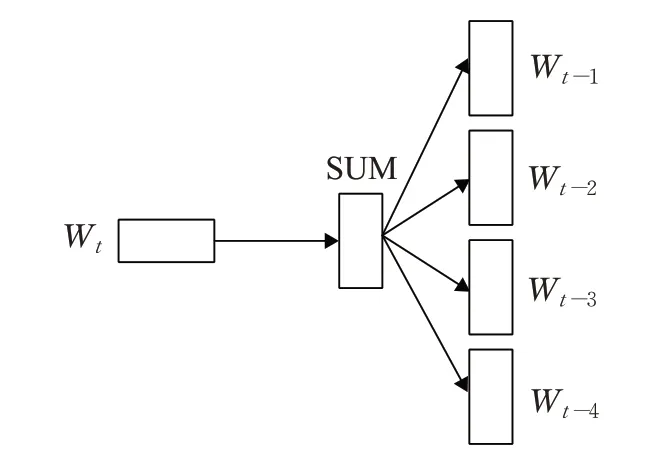
图2 Skip-Gram语言模型结构Fig.2 Skip-Gram language model structure
Skip-Gram语言模型将每个词语表示成两个n维向量,用来计算输入的中心词和将要预测的背景词之间的件概率,如公式(1)所示:

其中wt为中心词,wo为背景词,t和o为词语在句子中的位置,μo为背景词的词向量,vt为中心词的词向量,μi为词语的初始向量。
2.2 多特征混合模型层
2.2.1 BiLSTM模型
BiLSTM由前向LSTM模型和后向LSTM模型组成的双向语言模型。单向LSTM 模型进行语义特征提取时会造成语义特征的丢失,严重影响文本情感分析的准确率。以细粒度文本情感分析为例,在进行文本情感分析时需要特别注意情感词、程度词、否定词之间的交互。例如:“这个酒店脏得很厉害”“很厉害”形容“脏”的程度,BiLSTM 模型能够更好地提取类似的语义特征,提高文本情感分析的准确率。BiLSTM 模型的结构如图3所示。

图3 BiLSTM模型Fig.3 BiLSTM model
其中{T1,T2,…,Tn}表示每一时刻输入BiLSTM模型的文本信息,{Y1,Y2,…,Yn}表示经过BiLSTM 模型学习得到的每一时刻的文本特征,W0表示输入层与向前层之间更新语义信息的权重矩阵,W1表示前一时刻隐含层与当前时刻隐含层之间更新语义信息的权重矩阵,W2表示输入层与向后层之间更新语义信息的权重值,W3表示向前层与输出层之间更新语义信息的权重矩阵,W4表示后一时刻隐含层与当前时刻隐含层之间更新语义信息的权重矩阵,W5表示向后层与输出层之间更新语义信息的权重矩阵,LSTM 模型的结构如图4所示。
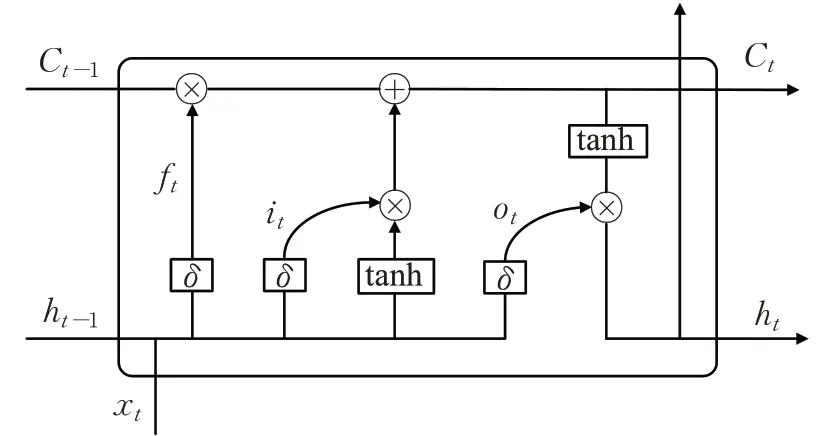
图4 LSTM模型Fig.4 LSTM model
其中包括遗忘门ft、输入门it、和输出门ot。t时刻LSTM模型信息的更新如下式所示:


其中σ表示sigmoid 激活函数,Wf表示遗忘门权重矩阵,Wo表示输出门权重矩阵、Wi表示输入门权重矩阵,Wc表示当前文本信息权重矩阵,bf表示遗忘门偏置值矩阵,bi表示输入门偏置值矩阵,bo表示输出门偏置值矩阵,bc表示文本信息偏置值矩阵,Ct表示t时刻文本信息,Ct-1表示t-1 时刻的文本信息,xt表示t时刻输入的文本信息,ht-1表示t-1 时刻的隐含层文本信息,ht表示t时刻隐含层文本信息。
2.2.2 MFCNN模型
MFCNN 模型分别在句子维度和词嵌入维度设计不同的卷积运算提取语义特征。句子维度的卷积过程(MFCNN_S)如图5 所示,其中词向量的维度为3,句子长度为4,卷积核大小为3×2。
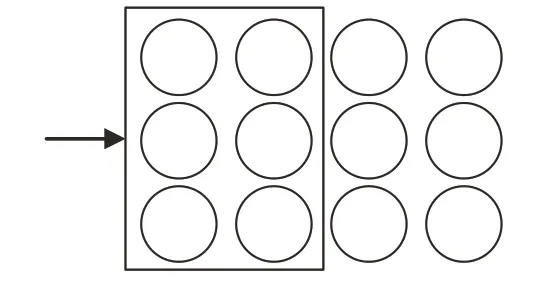
图5 句子维度卷积过程Fig.5 Sentence dimension convolution process
词嵌入维度包含整个词嵌入维度(MFCNN_1),单个词嵌入维度(MFCNN_2)、词向量的相邻语义维度(MFCNN_3)和词向量的单个语义维度(MFCNN_4)4种不同的卷积过程(如图6所示)。其中句子长度为4,词向量维度为3,MFCNN_1有1个1×2的卷积核,MFCNN_2有3 个1×2 的卷积核,MFCNN_3 有1 个2×4 的卷积核,MFCNN_4有3个1×4的卷积核。

图6 词嵌入维度卷积过程Fig.6 Word embedding dimension convolution process
MFCNN 模型的在句子维度和词嵌入维度的特征提取过程如图1所示。该模型主要对BiLSTM模型训练得到的语义矩阵进行卷积、池化和全连接运算。
(1)输入
输入层n表示句子长度,k表示词嵌入维度,卷积核宽度为h。句子维度,xi表示第i个词的词向量,xi:j表示从第i个词到第j个词的词向量的链接,输入矩阵x可以表示为包含长期依赖关系的k维n个词向量的链接(如公式(1)所示)。词嵌入维度,xi代表词向量维度中第i个词的句子向量,xi:j代表从第i个词到第j个词在词嵌入维度中的句子向量链接。输入矩阵x可以表示为包含长期依赖关系的n维k个句子向量的链接(如公式(9)所示)。公式(8)和(9)中表示向量拼接。

(2)卷积运算
卷积层对句子维度和词嵌入维度的向量进行卷积运算。句子维度的卷积运算,对输入矩阵第i个词向量xi:j+h-1进行卷积运算得到特征 如公式(10)所示,其中f表示非线性函数,Ws表示句子特征提取的权重矩阵,bs表示句子特征提取的偏置矩阵。句子特征Cs如公式(11)所示。

词嵌入维度的卷积运算,MFCNN_1 属于二维卷积运算,对输入矩阵第i个词嵌入维度的第j列向量进行卷积运算得到特征如公式(12)所示,其中W1表示MFCNN_1 特征提取的权重矩阵,b1表示MFCNN_1 特征提取的偏置矩阵。设计卷积窗口为,第i个词嵌入维度的特征 如公式(13)所示,n表示句子长度,则MFCNN_1特征提取结果CMECNN_1 如公式(14)所示,k表示词嵌入维度。

MFCNN_2 属于一维卷积运算,每个词嵌入维度都有对应的卷积核,共有k个卷积核,卷积核大小为1×h,分别对输入矩阵第i个词嵌入维度的第j列向量进行卷积运算得到特征如公式(15)所示,其中W2表示MFCNN_2 特征提取的权重矩阵,b2表示MFCNN_2特征提取的偏置矩阵。第i个词嵌入维度的特征如公式(16)所示,则MFCNN_2 特征提取结果CMFCNN_2如公式(17)所示。
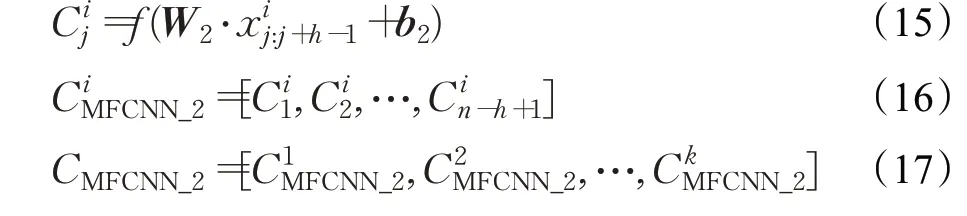
MFCNN_3属于一维卷积运算,卷积核大小为n×h,对输入矩阵的第i个词嵌入维度的向量xi:i+h-1进行卷积运算得到特征如公式(18)所示,其中W3表示MFCNN_3 特征提取的权重矩阵,b3表示MFCNN_3特征提取的偏置矩阵。MFCNN_3 特征提取结果CMFCNN_3如公式(19)所示。

MFCNN_4 属于一维卷积运算,每个词嵌入维度都有对应的卷积核,共有k个卷积核,每个卷积核的大小为n×1。对输入第i个词嵌入维度的向量xi进行卷积运算得到特征如公式(20)所示,其中W4表示MFCNN_4特征提取的权重矩阵,b4表示MFCNN_4 特征提取的偏置矩阵。MFCNN_4 特征提取结果CMFCNN_4 如公式(21)所示。

(3)池化操作
池化层对句子维度的特征Cs和词嵌入维度的特征Ce(CMFCNN_1,CMFCNN_2,CMFCNN-3,CMFCNN_4) 进行最大池化运算(max)和平均池化运算(mean),得到句子维度特征,词嵌入维度特征如下列公式所示。

(4)全连接运算
全连接层对Cp进行全连接运算得出全连接层的输出结果Cf如公式(27)所示,其中Relu 表示全连接层激活函数,Wf和bf表示全连接层的权重矩阵和偏置矩阵。

2.3 输入层
输出层对Cf进行softmax激活函数处理,输出文本情感分输出文本情感分析结果Cy如公式(28)所示:

3 实验与分析
为验证本文混合模型的有效性,本文在英文Twitter数据集[7]、中文Natural Language Processing Emotion Classification Challenge(NLPECC)数据集[8]和Chinese Opinion Analysis Evaluation(COAE)数据集[9]进行实验。从Twitter 数据集中标注6 940 带有情感极性的数据,其中积极情感极性1 734条,中性情感极性3 473条,消极情感极性1 733条。从NLPECC数据集标注44 875条数据,数据分为其他、喜好、悲伤、厌恶、愤怒和高兴6种情感,情感类型的标号依次为{0,1,2,3,4,5}。从COAE 数据集中标注6 000 条带有情感极性的数据,其中正面情感极性3 022条,负面情感极性2 987条。详细的数据集划分信息如表1所示。

表1 数据集划分详细信息Table 1 Data set division details
3.1 数据预处理
首先,去除Twitter、NLPECC 和COAE 数据集中与情感分析无关的噪音数据(例如:停用词(标点符号等)和网站链接等)。然后,根据数据集的实际情况进行句子长度对齐,将句子的长度设置30,如果句子长度太短用
3.2 评价指标
本文采用分类模型常用的准确率P(Precision)、召回率R(Recall)和F值(F-value)作为评价指标,如下列公式所示。以NLPECC 数据集中“悲伤”的文本情感分析结果为例:P值表示分类模型预测文本情感类型是“悲伤”的数目中,实际是“悲伤”情感的文本数目的占比;R值表示所有表达“悲伤”情感的文本数目中,被成功预测为“悲伤”情感的文本数目的占比;F值是对P值和R值的综合评价指标。评价指标的计算如下列公式所示,其中A表示预测是“悲伤”情感,实际是“悲伤”情感的文本数目,B表示预测是“悲伤”情感,实际不是“悲伤”情感的文本数目,C表示预测不是“悲伤”情感,实际是“悲伤”情感的文本数目。

3.3 实验模型参数设置
本文BiLSTM模型的训练过程使用文献[11]提出的Adagrad 方法来更新参数,并在测试数据集上选择文本情感分析效果最好的模型参数,如表2所示。
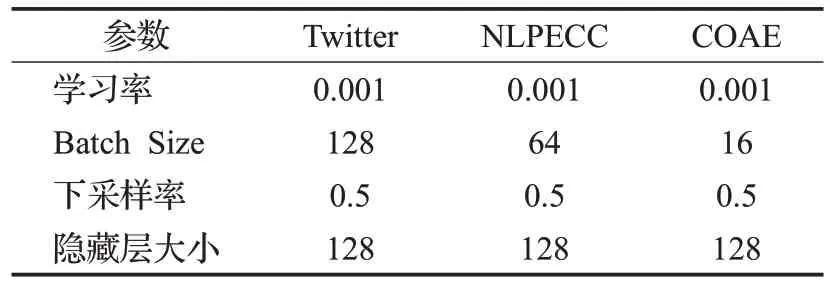
表2 BiLSTM模型超参数设置Table 2 BiLSTM model hyper parameters setting
为确定本文混合模型的最优参数,验证本文模型有效性,提升文本情感分的准确率,本文分别选取不同的句子长度和向量维度在NLPECC、Twitter、NLPECC 和COAE数据集上进行对比实验。其中,句长度根据数据集的实际情况设置为20、30、40 和50,词向量维度根据维基百科文词向量模型和Glove 词英文次向量模型设置为100、200、300和400,学习率为0.01,批量训练的大小Batch Size 为50,λ 大小为10-8。不同句子长度和词向量维度设置下,3种数据集的文本情感分析F值如表3和表4所示。

表3 不同句子长度文本情感分析F值Table 3 Sentiment analysis F value of text with different sentences length %

表4 不同词向量维度文本情感分析F值Table 4 Text sentiment analysis F value of different word vector dimensions %
从表3的实验结果可以看出,句子长度为20文本情感分析的F值较句子长度30、40 和50 降低了29.22%,说明句子长度设为20 会丢失大量的语义分析,影响文本情感分析结果。句子长度为30、40和50,文本情感分析的F值没有变化,因此,本文将句子长度设置为30,既能合理利用计算机存储空间,又能得到最优的文本情感分析结果。
从表4 的实验结果可以看出,词向量维度为100 和200,文本情感分析的F值在有所提高,词向量维度为300,3 个数据集的F达到最大,分别为80.18%、84.55%和89.03%,词向量维度为500,F值有所下降。由此可知,向量维度为100 和200,训练结果存在欠拟合情况,词向量维度较大(400维)会出现过拟合情况。因此,本文将词向量维度设为300。
综上所述,本文得出了如表5 所示的MFCNN 模型卷积核参数设置。
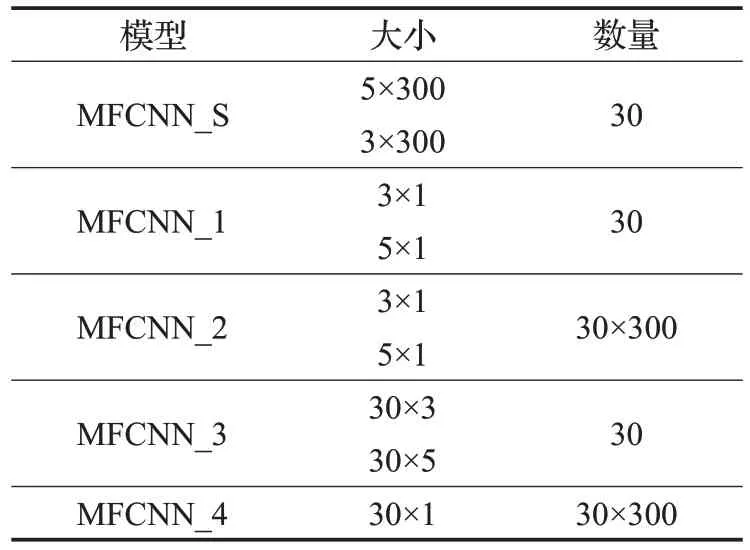
表5 MFCNN模型卷积核参数设置Table 5 MFCNN model convolution kernel parameters setting
3.4 实验结果分析
将本文的BiLSTM-MFCNN混合模型的方法与以下方法在如表1 的数据集上进行实验。本文的对比方法分为3 组:传统机器学习方法、单一深度模型方法和混合深度模型方法。下面对上述3组方法进行简单介绍。
(1)传统机器学习方法
NBSVM:该方法使用本文Tri-gram 方法提取文本特征,然后将朴素贝叶斯SVM模型作为分类器,实现文本情感分析。
(2)单一模型方法
TextCNN[12]:该方法在句子维度进行卷积运算获取句子维度的语义信息,通过最大池化运算得到表示文本的语义特征。
DCNN[13]:该方法使用动态卷积神经网络对句子的语义表示进行建模,模型由一维卷积层和动态k-max池化层组成。其中,一维卷积层使用宽卷积运算更有效的提取句首和句尾的语义特征;动态k-max池化层通过k值得设置,动态地提取更丰富的语义特征。
MVCNN[14]:该方法首先使用多通道输入的方法实现文的向量化表示,然后使用可变大小的卷积运算对每个通道的不同粒度的短语特征进行提取,最后使用动态k-max池化运算得到文本的语义特征。
BiLSTM[15]:该方法通过正向LSTM 和反向LSTM学习文本的长期依赖关系,提取文本上下文的语义特征。
(3)混合模型方法
RCNN[16]:该方法采用双向循环神经网络获取文本上下文语义信息,利用最大池算法获取文本情感分析最重要的特征,经过softmax 函数处理后得到文本所表达的情感。
LSTM-CNN[17]:该方法充分利用两种不同神经网络模型的优势,分别使用LSTM 提取文本的长期依赖关系,使用卷积神经网络(CNN)提取文本的语义特征。
BiLSTM-MFCNN:本文提出的基于BiLSTM-MFCNN混合模型的文本情感分析方法。
首先,从表6、表7 和表8 的文本情感分析实验结果可以看出,在3个数据集上,本文提出的BiLSTM-MFCNN混合模型的F值最高为80.18%、84.55%和89.03%,并且在NLPECC 数据集上F值提升最明显,为1.56 个百分点。图7、图8和图9直观地反应出BiLSTM-MFCNN混合模型的F值最高,这表明BiLSTM-MFCNN混合模型不仅适用于中文和英文不同语言的文本情感分析任务,而且能够在细粒度的中文文本情感分析任务中取得更好的效果。同时,在3 个数据集上BiLSTM 混合模型和比NBSVM 模型的F值提升了18.49 个百分点、14.4个百分点和17.64个百分点。这表明BiLSTM混合模型能够提取到比传统的机器学习方法更高层次的语义特征,取得更好的文本情感分析效果。

表6 Twitter数据集实验结果Table 6 Twitter dataset experimental results%
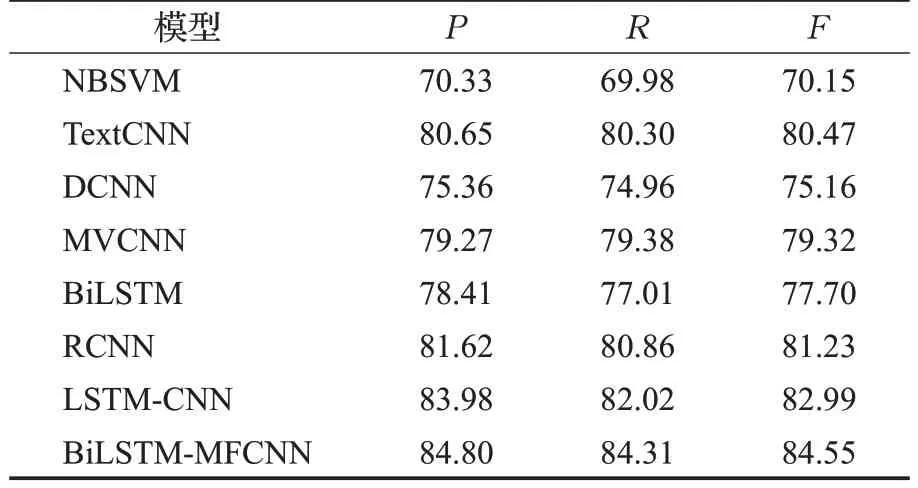
表7 NLPECC数据集实验结果Table 7 NLPECC dataset experimental results%
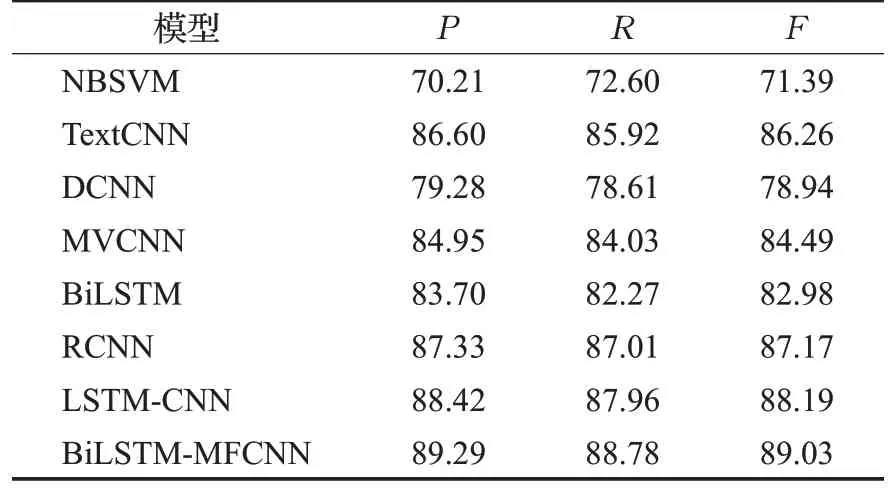
表8 COAE数据集实验结果Table 8 COAE dataset experimental results%

图7 Twitter数据集实验结果直方图Fig.7 Histogram of experimental results on Twitter dataset
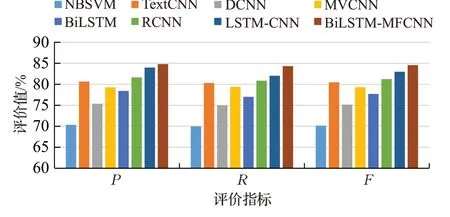
图8 NLPECC数据集实验结果直方图Fig.8 Histogram of experimental results on NLPECC dataset

图9 COAE数据集实验结果直方图Fig.9 Histogram of experimental results on COAE dataset
其次,在3 个数据集上BiLSTM-MFCNN 混合模型的F值均大于TextCNN、DCNN、MVCNN 和BiLSTM单一模型的F值。这表明TextCNN模型句子维度的语义特征提取、DCNN模型的动态语义特征提取、MVCNN模型的多通道语义特征提取和BiLSTM 模型的上下文语义特征提取,都会造成语义特征的丢失,而BiLSTMMFCNN 混合模型能够充分利用不同深度神经网络的优势,不仅可以学习到上下文的长期依赖关系,而且能够从句子维度和词嵌入维度提取丰富的文本语义特征,取得更好的文本情感分析效果。
最后,在3 个数据集上BiLSTM-MFCNN 混合模型的F值大于RCNN 和LSTM-CNN 混合模型的F值。这表明BiLSTM 双向语言模型比RNN 和LSTM 单向模型语言模型的语义特征提取效果更好,同时改进后的MFCNN 模型能够从句子维度和词嵌入维度提取文本隐藏的语义特征,并且很好地解决了单个最大池化运算造成的语义特征不足的问题,因此BiLSTM-MFCNN混合模型能够进一步提升文本情感分析的效果。
3.5 经典样例分析
为进一步分析BiLSTM-MFCNN混合模型比其他模型在文本情感分析任务中的优势,本文通过几个具体样例进行分析。如表9所示,从NLPECC数据集的测试集挑选出一些经典样例的文本情感分析结果进行对比分析。

表9 经典样例Table 9 Classic examples
如表10所示,样例1和样例2属于结构简单并且情感表达准确的文本,此类文本是表达情感常用的文本结构,BiLSTM 模型、TextCNN 模型、MFCNN 模型LSTMCNN 模型和BiLSTM-MFCNN 模型都可以准确识别此类文本的情感。
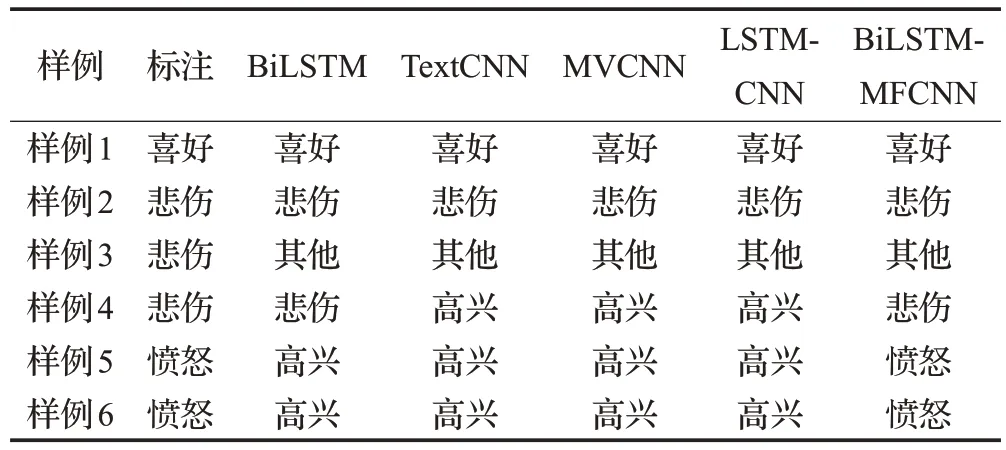
表10 样例情感分析结果Table 10 Sample sentiment analysis results
样例3 的文本包含大量的网络用语,例如“杯具”“太牛了”“霸气”等等。这些网络词在进行文本向量化表示时大部分无法识别,只能用0向量补充,同时,对于“霸气”等网络词在不同的领域所表达的情感类型也有所不同,因此BiLSTM 模型、TextCNN 模型、MFCNN 模型LSTM-CNN模型和BiLSTM-MFCNN模型都无法正确识别此类文本的情感类型。
样例4也属于文本的一种常见类型,此类文本包含大量的否定词,在进行文本情感分析时,需结合上下文语义对其进行理解。TextCNN 模型和MVCNN 模型受局部窗口大小的限制,只能提取文本的局部语义特征,由于LSTM模型独特的门结构特点,能够很好地利用上下文语义信息完成文本情感分析,因此BiLSTM 模型、LSTM-CNN 模型和BiLSTM-MFCNN 模型能够准确识别此类文本的情感。
样例5 和样例6 属于具有反问语气的文本,通过反讽的方式表达情感,此类文本结构十分复杂,所以BiLSTM 模型、TextCNN 模型、MVCNN 模型和LSTMCNN模型都无法正确识别此类文本的情感,而BiLSTMMFCNN模型在语义特征提取过程中,不仅能够学习到文本的长期依赖关系,而且通过从句子维度和词嵌入维度提取更深程度和更加细腻的语义特征,因此能够准确地识别此类复杂文本的情感。
4 总结
本文提出一种基于BiLSTM-MFCNN 混合模型的文本情感分析方法。该方法首先利用BiLSTM 模型提取文本长期依赖,然后利用MFCNN 模型的卷积层,提取文本句子维度和词嵌入维度的语义特征,利用池化层得到文本的最大池化特征和平均池化特征,最后经过全连接层和输出层的处理得到文本情感分析的结果。本文的实验结果表明,BiLSTM-MFCNN 混合模型在几个数据集上取得了较好的文本情感分析效果。但是,通过经典样例的对比分析结果能够看出,本文提出的BiLSTM-MFCNN混合模型对于包含跨领域词汇和网络词汇的细粒度文本情感分析的效果并不理想。在今后的文本情感分析研究中,会以细粒度文本情感分析的中文数据集为重点,进一步扩充网络词汇和不同领域的文档,提升跨领域的细粒度文本情感分析效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
大连民族大学学报(2015年2期)2015-02-27
