
基于阈值自适应调整的图像特征均匀分布ORB算法改进
2021-10-14 08:31:10时培成杨剑锋梁涛年
汽车安全与节能学报 2021年3期
时培成,杨剑锋,梁涛年,齐 恒
(1. 安徽工程大学 汽车新技术安徽省工程技术研究中心,芜湖 241000,中国;2. 芜湖伯特利汽车安全系统股份有限公司,芜湖 241009,中国)
汽车工业的蓬勃发展使得近年来无人驾驶汽车成为了人们的研究热点。无人驾驶汽车要想在环境中自主运动,就必须获取详细的周围环境地图以及精准的自身定位信息。所以,同步定位与地图构建变成实现无人驾驶汽车应用的必要前提条件[1],它包含了定位和建图。通常,无人驾驶汽车通过摄像头拍照来定位和建图,称无人车视觉同步定位与地图构建 (simultaneous localization and mapping, SLAM) 算法,而要从图像中获取车辆运动信息,必须对图像提取特征点并进行特征匹配,进而估计相机的运动,再反推出车辆的所处位置[2]。目前,常用的图像特征点提取方法有 SIFT(scale-invariant features transform)[3]、SURF (speededup robust features)[4]和ORB (Oriented FAST and Rotated BRIEF) 算法。其中,ORB算法相比于SIFT算法和SURF算法提取速度高,可以满足无人驾驶汽车SLAM系统实时性的要求[6]。
传统ORB算法因实时性较好,被广泛应用于视觉SLAM系统中,但它也有比较明显的缺陷,如提取的特征点在图像中分布不均匀、聚集严重,从而导致后续图像匹配精度较差,使相机位姿估计结果出现较大偏差。为此,文献[7]在提取特征点后,采用四叉树算法对图片进行区域划分,将特征点平均分配到这些区域中,通过计算Harris响应值[8]保留响应值最大的特征点,但是该算法消耗时间较长,实时性不好。
文献[9]在文献[7]基础上对传统四叉树算法进行改进,提高了特征点的均匀度,但没有限制节点的分裂次数,算法运行时间仍然较长。文献[10]通过设定阈值限制每层图像提取的特征点数目,使算法运行时间大大减少,但是却造成了特征点分布不均匀,降低了后续图像的匹配精度。文献[11]通过设置不感兴趣区域来剔除那些在初始化时无法提取特征点的栅格,加速了特征点的提取,但是分布均匀度较低,影响后续图像匹配精度。
本文针对以上算法的缺点,提出了一种阈值自适应调整的改进的ORB (advanced ORB,A-ORB)算法,该算法运行时间短,提取的特征分布均匀度高。A-ORB算法依据图像大小,来计算需要构建的图像金字塔层数,避免了过度增加金字塔层数而造成算法运行时间延长;并在每层图像金字塔上设立特征点提取阈值,当提取的特征点数目满足阈值条件时,则终止该层图像特征点的提取,减少特征点的冗余。A-ORB算法在利用四叉树算法剔除每层图像上的冗余特征点时,限制四叉树算法分裂的节点数,不但能提高算法的运行效率,也能提高特征点的分布均匀度。
1 ORB算法原理
1.1 FAST关键点
图像的特征点可以形象的理解为图像中更加重要的像素点,例如图形边缘点,灰度值变换较大的点等。ORB算法利用FAST特征点检测算法来对图像提取特征点[12]。如图1所示,FAST算法通过比较图片中某一个像素点和其周围的灰度值,如果满足一定条件则认为它是特征点。
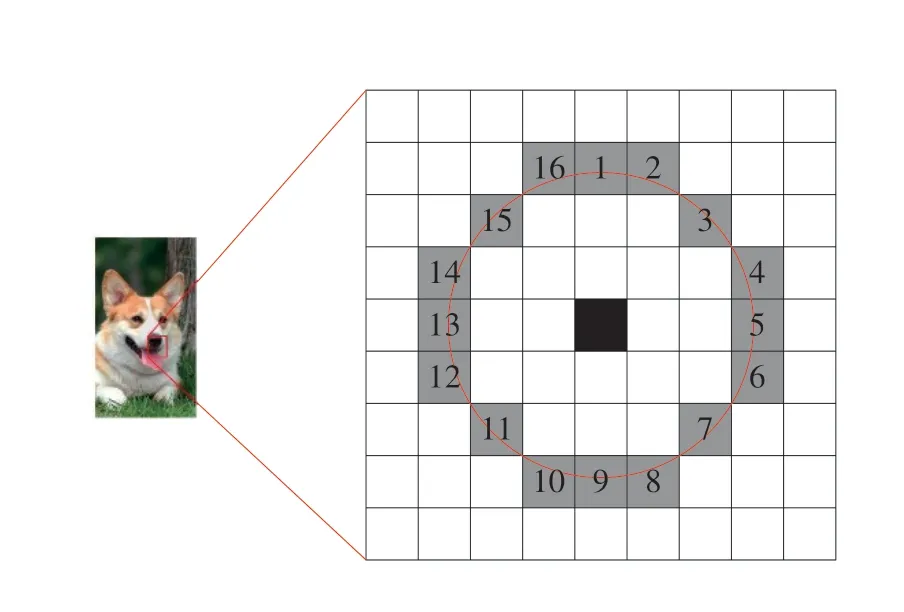
图1 FAST算法提取示意图
其具体计算过程如下所示:
步骤1:在待提取的图像中选取某个像素P;判断是否可以作为特征点,假设该点的灰度值为IP;
步骤2:人为设定一个阈值T,比如说IP的30%;
步骤3:选取P为圆心,3为半径的圆上的16个像素点;
步骤4:假如这16个像素点中有连续L点的灰度都大于IP + T或者小于IP-T,判定P为一个特征点(L一般取12)。
在FAST算法实际提取中,可以通过如下方法加速特征点检测:直接对圆上第1、5、9、13个像素点的灰度值进行比较,如果他们均满足判定条件,那么目标点才有可能是特征点;如果不满足判定条件,则直接跳过该点,判断下一个像素点。依照此方法计算图像中的每一个像素点,直到结束。
FAST算法只依靠图像中像素点灰度值的对比来确定,所以依靠此方法检测出来的待选点作为特征点非常不可靠,在图像发生平移或者旋转变化时,往往会造成特征点冗杂或者丢失的情况。针对此类缺陷,ORB算法添加了特征点尺度和旋转的描述。ORB算法通过构建图像金字塔为提取的特征点添加尺度描述。图像金字塔是计算机视觉中一种常见的处理方法。金字塔的底层是原始图像,每往上一层就对原始图像进行一定倍率的缩放,从而得到不同分辨率的图像。在每层图像金字塔上提取特征点后,在进行特征匹配算法时,可以匹配不同层上的图像,从而实现了尺度不变性。
ORB算法利用了图像块的灰度质心为特征点添加旋转的描述。具体方法如下:
1) 在一个图像块A中,定义图像块的矩为

式中:I(x,y)为图像中像素点(x,y)处的灰度值,p、q的取值范围均为{0,1}。
2) 定义图像块的质心为

3) 连接图像块几何中心与质心得到一个方向向量OC,将特征点的方向定义为

1.2 BRIEF描述子
在提取了Oriented FAST 特征点以后,ORB算法使用BRIEF描述子来对特征点进行描述。BRIEF是一种二进制描述子,其描述向量由多个0和1组成[13]。其具体思想是在特征点P周围以特定模式选取N点对,比较灰度值的大小(比如x,y)。若x比y大,则取1,反之就取0,即:

式中:P(x)、P(y)分别为点x、y处的灰度值大小。故BRIEF描述子可以表示为
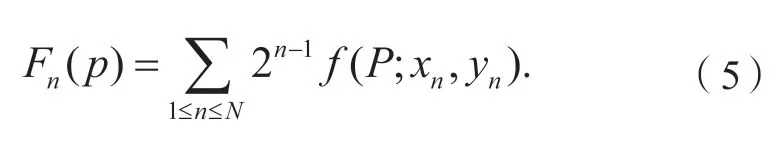
如图2所示,假设像素点V1绕图像中心点旋转θ角至像素点V2,r为像素点距图像中心距离。设像素点V1坐标为(x1,y1),像素点V2坐标为(x2,y2),由三角关系可知:
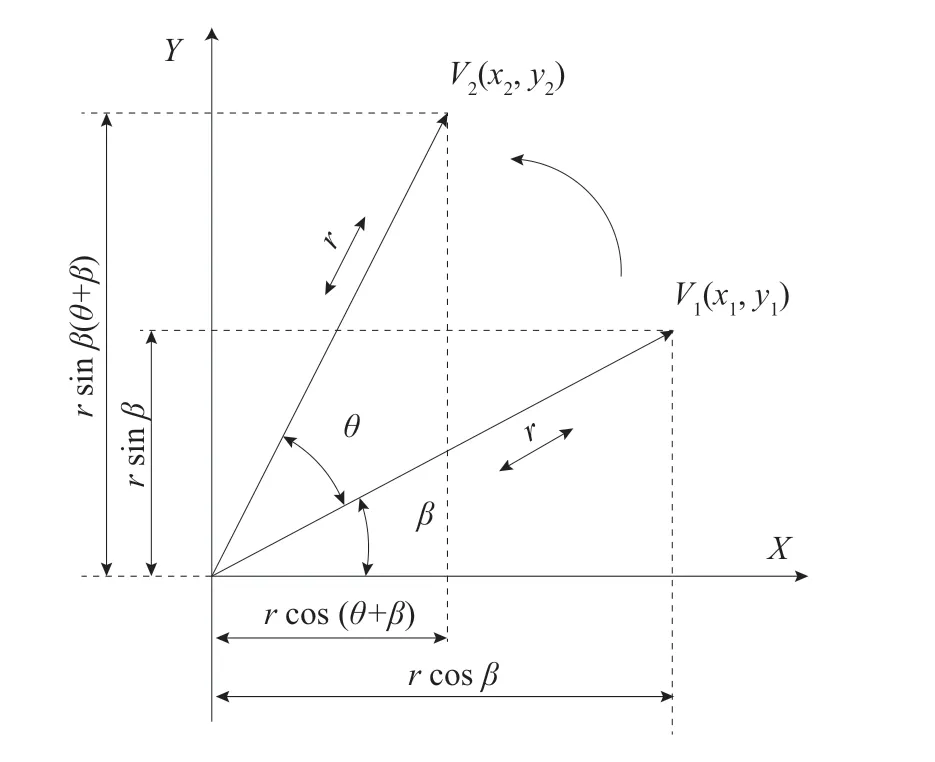
图2 BRIEF描述子旋转不变性示意图

写成矩阵形式:
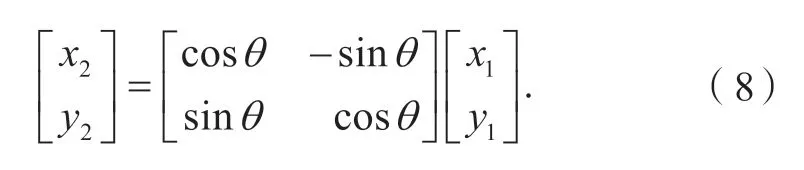
故对于N点对,可以得到如下式的描述子矩阵Sθ:
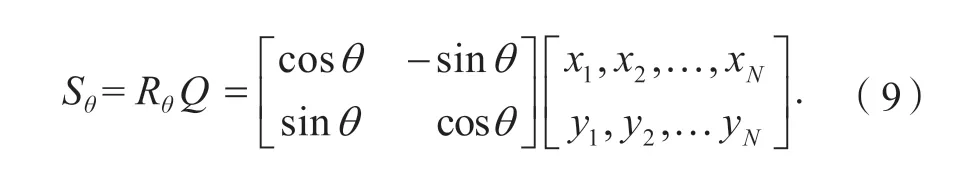
在计算旋转后,描述子为
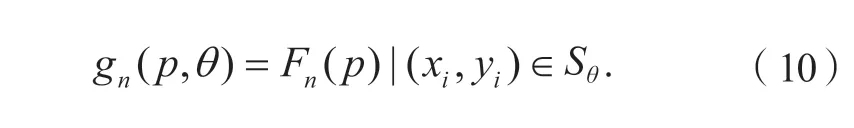
2 A-ORB算法设计
本文提出的A-ORB算法,首先通过图像尺寸大小来确定所需要构建的金字塔的层数;接着针对每层金字塔图像的大小来划分网格;然后利用图像的灰度值来计算特征点的提取阈值,对每层图像金字塔中的网格按照一定顺序提取特征点,若提取特征点数目满足每层设定的特征点数便提前结束,以提高计算效率;最后采用四叉树算法对提取的冗余特征点进行剔除。A-ORB算法流程如图3所示。

图3 A-ORB算法流程图
A-ORB算法关键步骤如下:
1) 通过图像的大小构造图像金字塔,将其分为M层,若设图像的宽度高度分别为W、H,则M层设定为:

式中:round[·]为取整函数。
2) 设定图像的缩放因子为s(0<s<1),设需要提取的特征点总数为N,分别计算出每层图像金字塔的面积,将特征点均摊到每层图像上。设图像金字塔的总面积为S,则有:
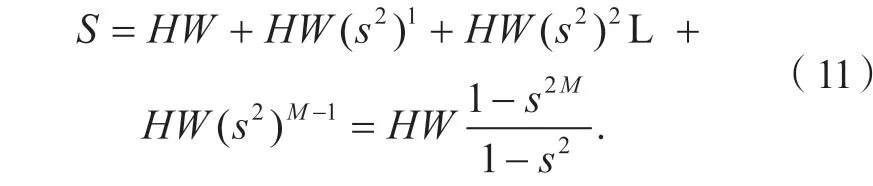
单位面积的特征点数X为
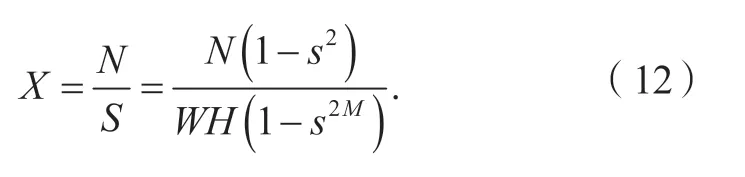
第i(0 ≤i≤ (M-1))层需要提取的特征点数目为

在划分特征点时往往不能完全划分完整,将剩余的特征点全部归于图像金字塔的顶层:
高校基层行政人员的职业生涯基本都是单调无趣的。这就要求高校在工作之余,为他们搭建其他兴趣交流平台,让他们在工作的同时学习到自身感兴趣的知识和能力,只有这种氛围持续存在,员工才会自我要求进步,只有进步才能推动工作的动力,提高工作效率。
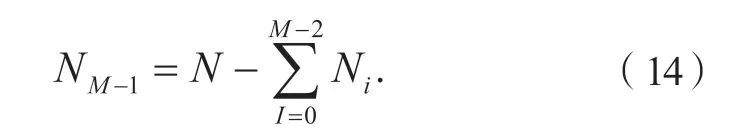
3) 传统ORB算法采用的检测阈值T为一个常数,鲁棒性较差,当场景明暗变化明显时,容易造成特征点丢失的情况。本文算法根据图像灰度信息计算出一种自适应提取阈值,若此阈值提取的特征点数目不满足要求,则降低阈值至T/2,直到提取的特征点数目达到要求。

式中:λ为比例因子,一般取0.01;m为图片中像素点的个数;分别为每个像素点的灰度值以及该图像的灰度平均值。
4) 对每层图像进行网格划分,分成L×Z个大小相同的区域。划分网格之后,从图像金字塔的第一层开始遍历网格进行特征提取,奇数层从图像的左上方开始按照先行后列的方式往下提取特征点,偶数层从图像的右下方按照先行后列的方式往上提取特征点。在提取过程中,对每个网格提取的特征点进行计数。如果总数大于等于Ni,则退出循环,结束该层特征点的提取。
5) 通过以上方法提取的特征点存在冗余,故本算法也采用四叉树算法对冗余特征点进行剔除[14]。四叉树算法中每个节点下至多有4个子节点。具体做法是:将输入的图像划分成4个区域,逐步判断每个区域中包含特征点数量,若该区域特征点数量大于1,则继续分裂成4个节点,若等于1,则该区域不在划分子节点并将该节点储存,若等于0,则剔除该节点。这种划分方法虽然能够保证特征点均匀化,但是容易造成分割次数过多,降低算法运行速度,故本文在四叉树算法分裂时限定分裂次数。当四叉树算法分裂的节点数大于等于所需要提取的特征点数时便停止分裂,此时计算四叉树算法节点内Harris响应值,保留最大值对应的特征点,其余剔除。若只有一个特征点,则不进行计算,直接保留。具体流程如图4所示。
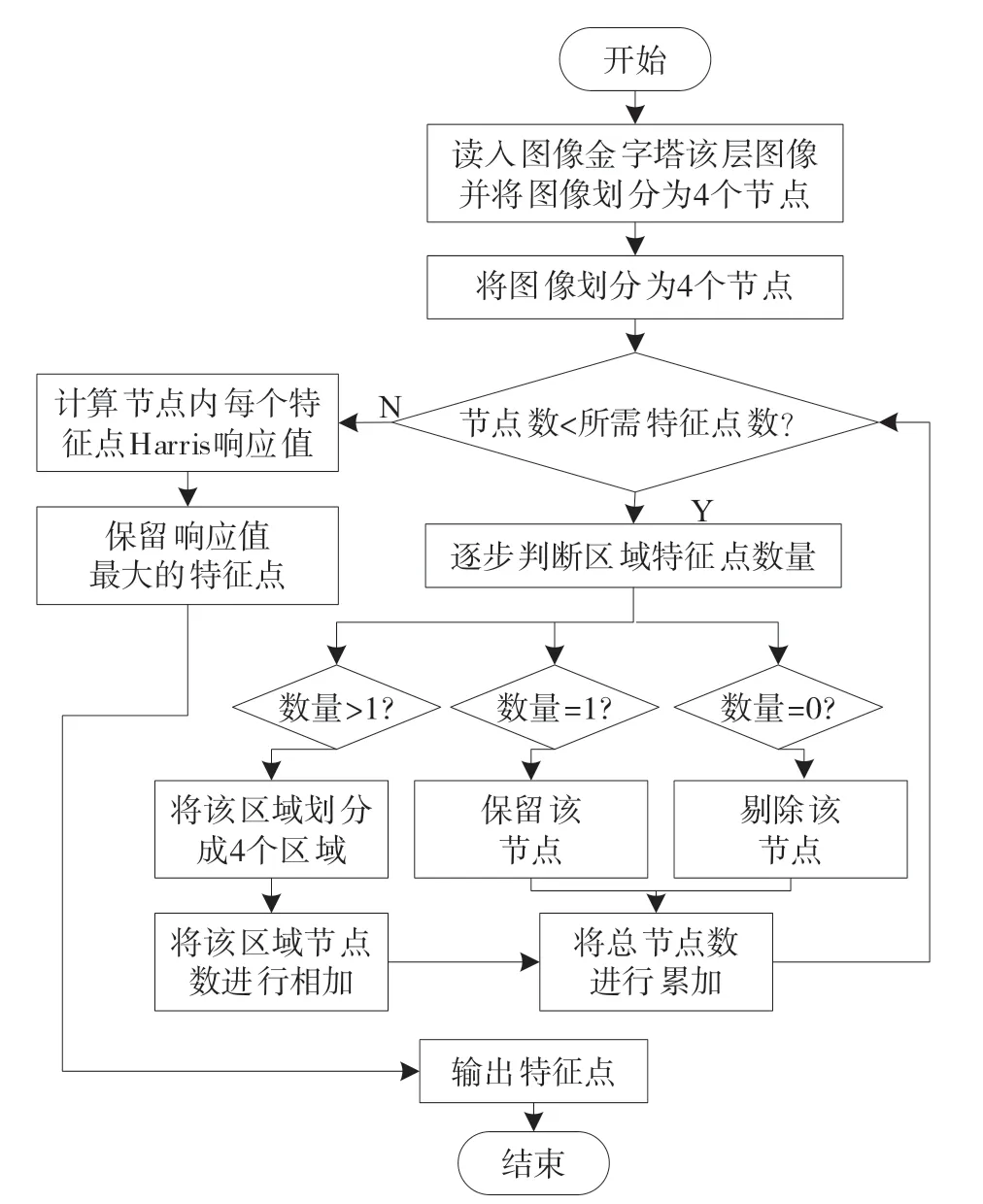
图4 改进四叉树算法流程图
6) 本文算法在对图像提取特征点之后,也需要去除图像的高频部分,增加算法鲁棒性。故先对图像进行Gauss模糊处理,再计算图像的描述子[15]。本文采用Gauss函数用于对图像进行模糊处理。二维Gauss函数表达为
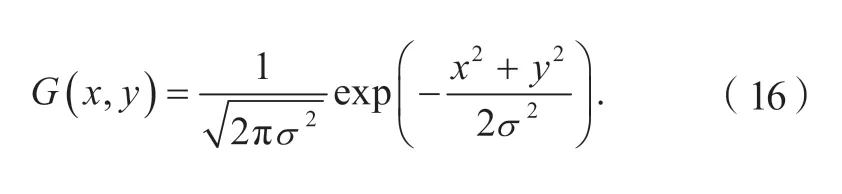
式中:x、y分别为像素点到x轴、y轴的距离;σ为Gauss函数的标准差。
3 实验结果与分析
本实验中,使用了OpenCV 3.2.0的计算机视觉库,在Ubuntu 18.04操作系统上进行算法验证,计算机的中央处理器(CPU)为AMD Ryzen5, 16 GB内存。原始图像来自于Mikolajczyk开源图像库,该图像库中 包 括Bark、Bikes、Boat、Leuven、Ubc、Graf等一系列图像[2]。对图像库中包含图像旋转、图像平移、视角变化、光照变换等不同图像检测实验,验证本文算法与传统的ORB算法、文献[7]所提的MA算法以及文献[10]所提的S-ORB算法进行比较,检测算法的优劣性。
为了不失一般性,每组图片均进行20次实验,最后结果采用平均值。为了量化分布均匀度,采用文献[2]的计算方法:从竖直、水平、45°和135°等4个方向以及中心、外围对图像进行区域划分,分别统计每个区域内的特征点数目,将其记作区域统计分布向量,计算该向量的方差V,均匀度u计算表达式如下:

根据式(17),均匀度越小,分布均匀度越高,特征点在图像中分布越均匀,后续图像匹配的精度就会越高。采用均匀度u和运行时间t作为评价指标,对图像数据集进行测试。原始图片以及测试结果见图5。均匀度与运行时间统计见表1。

图5 原始图片及图像提取4种算法结果
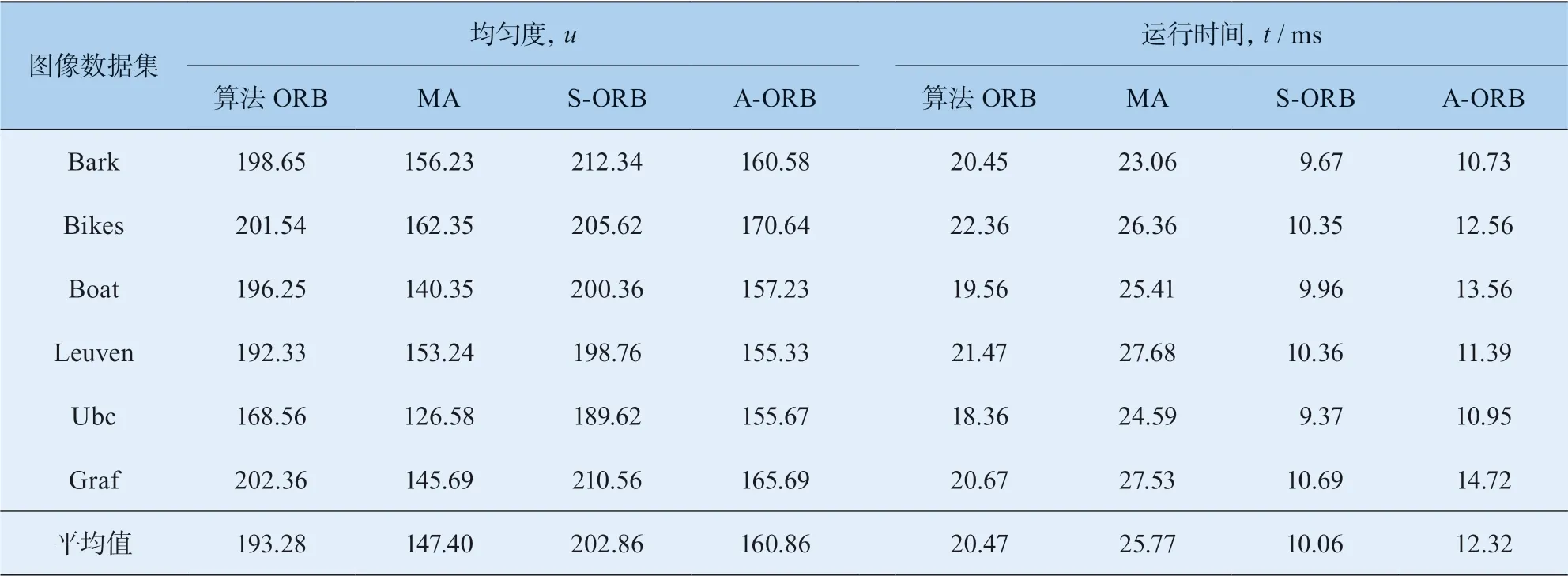
表1 分布均匀度与耗时比较
根据图5及表1,在提取相同数目的特征点时(这里提取500个特征点),A-ORB算法相比传统的ORB算法提取的特征点分布均匀度平均提高了16.77%,运行速率提高了39.81%,说明A-ORB算法优于传统的ORB算法。相较于MA算法,A-ORB算法运行速率提高了52.19%,分布均匀度下降了9.13%,分布均匀度下降的原因是因为MA算法是过量提取特征点,这虽然会提高分布均匀度,但会增加算法耗时。相较于S-ORB算法, A-ORB算法的分布均匀度提高了20.70%,运行速率减少了22.47%。这是由于S-ORB算法在特征提取时,易提前检测,特征点也有冗余,虽然算法运行时间很快,但分布均匀度较差,造成后续图像匹配进度不高。
在SLAM过程中,由于输入图像的清晰程度、复杂程度等不同,采用固定阈值ORB算法很难在一次图像遍历中获得所需要的特征点,在遇到纹理缺失的场合(例如墙面)很有可能造成特征点丢失的情况出现,对后续相机位姿估计以及地图构建带来较大误差,采用自适应阈值则可以增加算法的鲁棒性。为了验证动态阈值对于特征提取时间以及特征分布均匀度的影响,采用固定阈值传统ORB算法以及自适应动态阈值ORB算法对同一图像进行特征提取。采用运行时间t和特征点均匀度u作为指标,对图5中的原始图片进行测试,测试结果见图6。
由图6可以看出:在不同图像序列中,使用自适应阈值对图像进行特征点提取比使用固定阈值消耗时间更少,平均减少了10%以上,所得到的特征点分布度平均提高了12%以上。

图6 固定阈值和自适应阈值ORB算法提取图像数据集
提取特征点的目的主要是为了后续图像匹配从而计算运动信息,故匹配精度也是衡量特征提取算法优越性的重要指标,故本文采用图像库中的图片对本算法以及其他3种算法进行匹配验证,验证本文算法在匹配精度方面的有效性。原始图片如图5所示,验证结果见图7,匹配精度与匹配时间对比见表2。
由图7、表2可知:在匹配光照条件不同的Leuven图片时,A-ORB算法在匹配精度上优于传统ORB算法63%以上,优于MA算法17%以上,优于S-ORB算法30%以上,在匹配时间上优于传统ORB算法3%以上,优于MA算法8%以上。
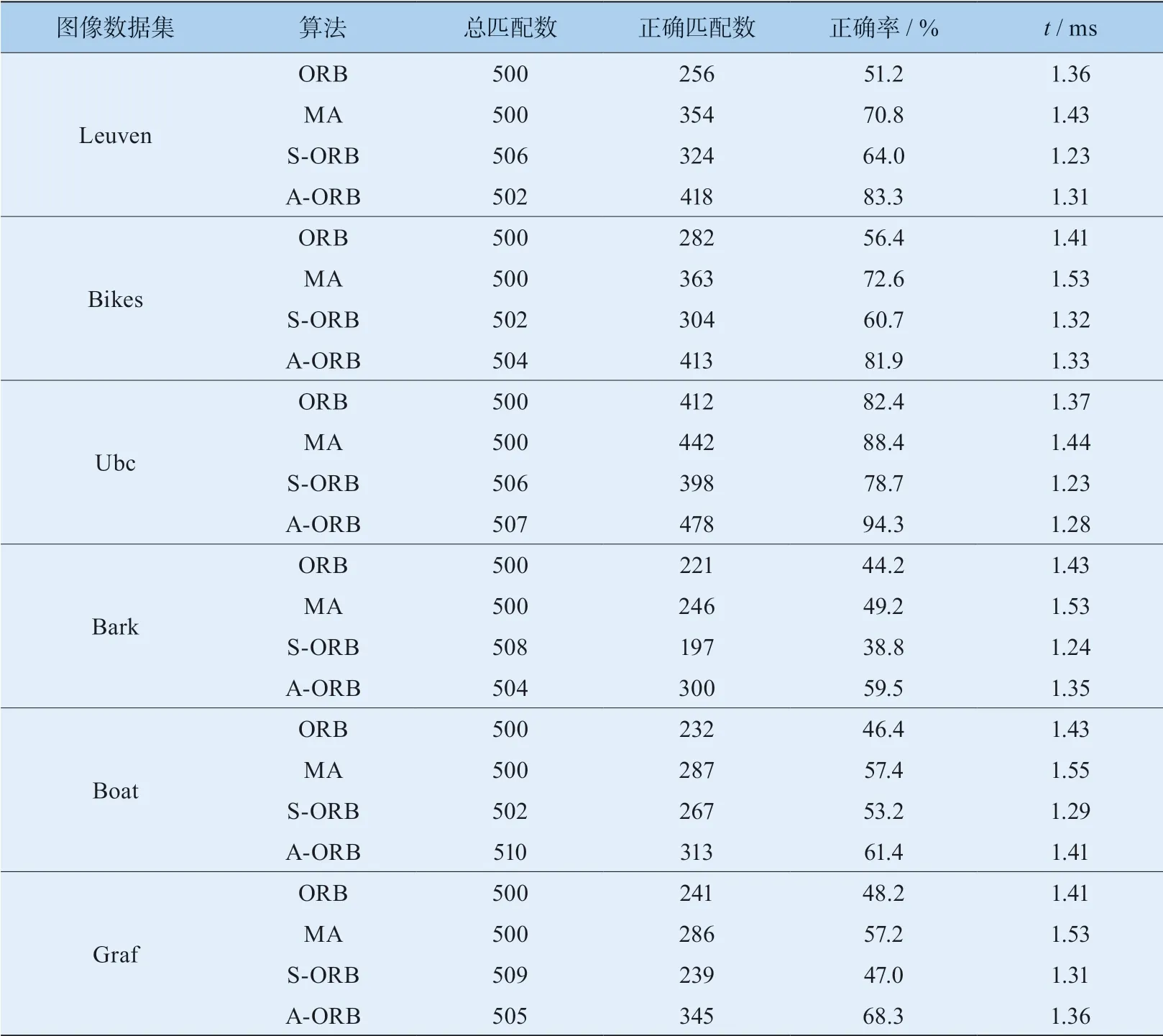
表2 匹配精度与匹配时间对比

图7 4种算法匹配原始图像部分结果
在匹配模糊程度不同的Bikes图像时,A-ORB算法在匹配精度上优于传统ORB算法45%以上,优于MA算法13 %以上,优于S-ORB算法35%以上,在匹配时间上优于传统ORB算法6%以上,优于MA算法13%以上。
在匹配压缩程度不同的Ubc图像时,A-ORB算法在匹配精度上优于传统ORB算法14%以上,优于MA算法7%以上,优于S-ORB算法20%以上。
在匹配时间上优于传统ORB算法7%以上,优于MA算法11%以上。综上所述,本文所提出的A-ORB算法不仅加快了特征点的提取速度,也使得特征点分布更加均匀,匹配精度更高。
4 结 论
1) 针对传统ORB算法所提取的特征点存在分布不均匀,聚集严重的问题,提出了一种A-ORB算法。
2) 本文所提出的A-ORB算法,相比于传统ORB算法以及MA算法,在光照强度不同、模糊程度不同、图片压缩度不同等条件下,运行效率提高了30%以上,匹配精度提高了10%以上。
3) A-ORB算法更有利于后续图像运动信息的计算。在接下来的工作中,将考虑增加描述子维度的方法等来提高特征点的区分度,进一步提高算法提取征点的分布均匀度和匹配精度。
猜你喜欢
作物研究(2023年2期)2023-05-28 13:44:14
环球时报(2022-09-19)2022-09-19 17:19:22
Contemporary Social Sciences(2021年5期)2021-11-22 10:38:10
河南畜牧兽医(2020年21期)2020-01-10 00:20:08
少儿美术(快乐历史地理)(2019年2期)2019-06-12 08:43:06
科技创新与应用(2017年35期)2017-12-19 08:33:36
智富时代(2017年6期)2017-07-05 16:37:15
童话世界(2017年11期)2017-05-17 05:28:25
纺织科技进展(2015年1期)2015-11-28 05:56:28
建筑材料学报(2015年3期)2015-02-28 02:36:27
