
基于双重注意力机制的渔业标准实体关系抽取
2021-10-12 10:53孙哲涛刘巨升杨惠宁张思佳于英囡
农业工程学报 2021年14期
杨 鹤,于 红,孙哲涛,刘巨升,杨惠宁,张思佳,孙 华,姜 鑫,于英囡
(1.大连海洋大学信息工程学院,大连 116023;2.设施渔业教育部重点实验室,大连 116023;3.辽宁省海洋信息技术重点实验室,大连 116023)
0 引 言
数字渔业是中国乡村振兴战略的重要组成部分,也是数字中国的重要内容。渔业现代化和渔业标准化是数字渔业发展的重要方向[1],渔业现代化需要智能养殖技术服务[2]做支撑,渔业标准化需要以精准的标准服务为依托。知识图谱对解决领域问题有重要作用[3],张善文等[4]提出一种基于知识图谱和 BiLSTM模型结合的小麦锈病预测方法,提高了病害预测的精度,为小麦条锈病的预报预警和综合防治提供科学依据。奥德玛等[5]利用自然语言处理和文本挖掘技术,构建了中文医学知识图谱CMeKG,为智慧医疗提供专业知识基础。渔业标准知识图谱是表示渔业标准文本中实体之间关系的语义网络系统,是精准描述养殖技术和标准信息的重要载体,可以为渔业生产技术人员提供高质量知识,是实现智能养殖技术服务和标准精准服务的基础。关系抽取是构建知识图谱的关键技术,有效的关系抽取技术可以提升构建知识图谱的质量和效率,进而推动渔业现代化的进程,助力乡村振兴。
渔业标准命名实体识别和渔业标准实体关系抽取是构建渔业标准知识图谱的基础工作。程名等[6]提出了融合注意力机制和BiLSTM+CRF的渔业标准命名实体识别,取得较好的结果,但没有解决部分实体样本分布稀疏,导致识别效果不好的问题。杨鹤等[7]针对该问题,提出了多元组合数据增广方法,有效扩充了数据集,提升了命名实体识别的整体效果。上述研究可知,针对渔业标准文本命名实体识别的研究已经取得了较好效果,但还没有针对渔业标准文本关系抽取任务的研究工作。
早期关系抽取任务主要是基于规则[8-10]和机器学习[11-12]的方法,基于规则的方法严重依赖于规则制定,难以解决海量信息和复杂的信息抽取任务,基于机器学习的方法可以解决这一不足,并且能够明显提升召回率,应用领域也更广泛,但其需要手动提取文本特征,模型泛化能力较差。
基于深度学习的实体关系抽取方法不需要人工提取特征且具有较高精确度,近年来逐渐成为研究热点[13-16]。丁泽源等[17]基于深度学习方法提出了中文生物医学实体关系抽取系统,对于识别的准确率有较大提升,使更多关系得到正确识别;郑丽敏等[18]针对实体关系抽取受中文复杂语法特性限制的问题,提出一种基于深度学习的新闻文本的实体关系抽取方法,取得较好效果。与通用领域相比,渔业标准文本领域的语料包含渔业标准号以及大量专有名词,其信息抽取任务难点在于指标名特殊性和实体间存在较多的重叠关系,为了解决该问题,本文提出了一种基于双重注意力机制的渔业标准实体关系抽取方法并改进了 Zheng等[19]的标注方法,提出了句式分类的标注策略。主要研究如下:针对渔业标准文本中存在大量重叠关系而传统标注方法对重叠关系没有明确定义这一问题,提出句式分类标注策略,添加重叠标签,以解决渔业标准文本重叠关系无法抽取问题;为了识别结构化信息和位置信息并利用字级别注意力机制和句子级别注意力机制,更好的分配权重、排除噪音、提高准确性,提出基于双重注意力机制与 BERT-BiLSTM-CRF的渔业标准关系抽取模型,以期为其他领域的信息抽取任务提供参考。
1 数据采集与标注
1.1 数据采集
试验数据来自渔业生产技术人员日常养殖参照的渔业标准文本,该类标准文本大部分以书籍、PDF文件、图片等形式存在且缺少公开的数据集,通过爬虫技术、图文转换等方法收集数据并进行人工校对,构建DLOU-FSI语料库,共计343篇,36万字符。
针对DLOU-FSI语料库中7种关系类型进行抽取工作,分别为引用、规定、发布、提出、起草、归口和比较。关系类别及实例如表1所示,在标注过程中取所有关系类别的字符拼音首位字母作为对应标签,例如,引用关系对应“YY”标签。
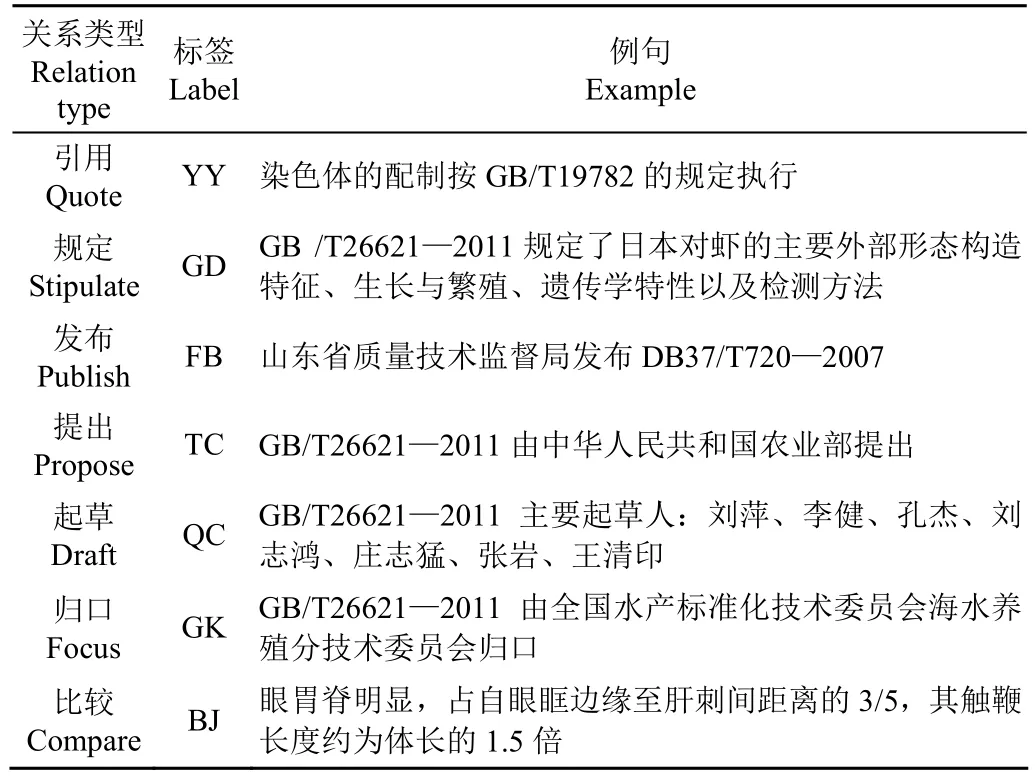
表1 渔业标准文本中的关系类型实例Table 1 Examples of relation types in fishery standard texts
1.2 语料标注
通过对渔业标准文本特性分析,发现渔业标准文本中存在大量重叠关系,因此,改进了Zheng等[19]的标注方法,针对其方法无法解决重叠关系抽取问题,提出了句式分类标注策略,实体关系抽取标签由4部分组成分别为:实体边界[20]、关系类别、重叠句式标签、位置标签[21]。
Zheng等[19]的标注策略使用最近距离匹配原则抽取句子中的关系三元组,且遵循每个实体只能参与 1个关系的抽取规则,因此,其无法解决渔业标准文本中重叠关系的抽取问题。针对渔业标准文本存在的重叠关系问题,对含有重叠关系句子进行分类,主要分为3种类型,如表2所示。3种重叠关系句式分别由标签7、8、9来定义,其中7表示普通关系类型即单个实体1对应单个实体2,生成一个三元组。8表示一对多重叠关系即单个实体1对应多个实体2,生成多个三元组。9表示多对一重叠关系即为多个实体1对应单个实体2,生成多个三元组。通过不同的标签来决定三元组的组成方式。渔业标准文本中的三种重叠关系句式类型如表2所示。
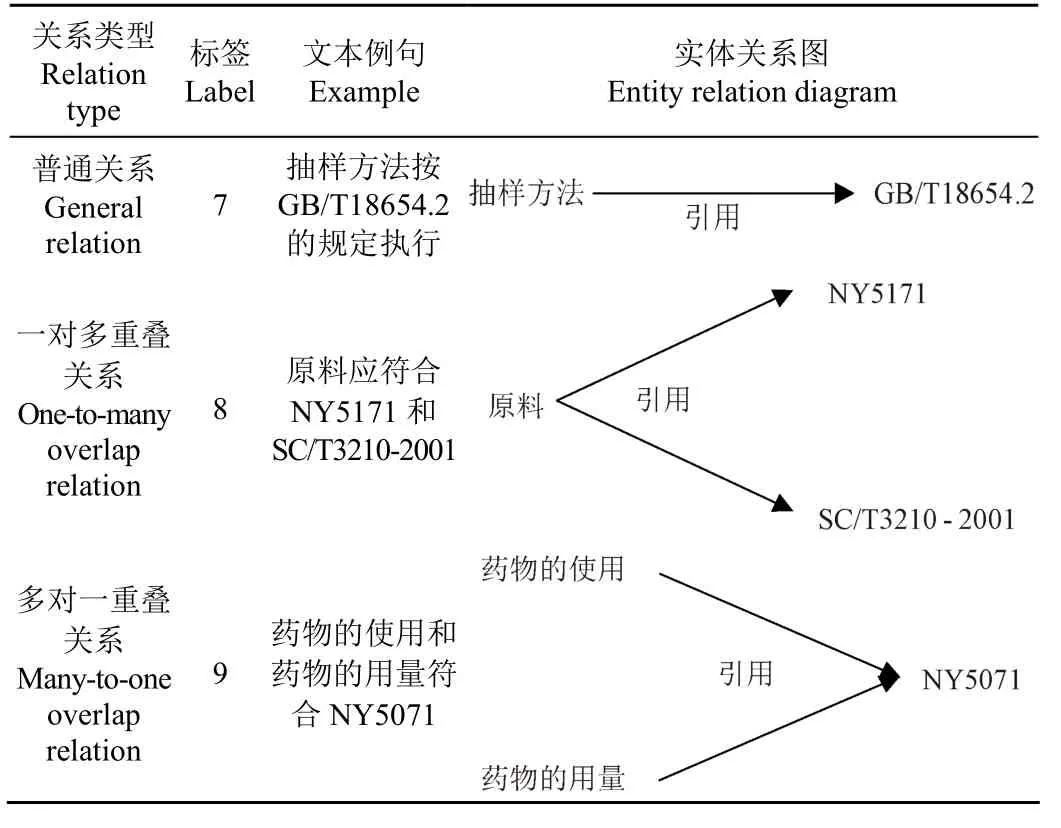
表2 渔业标准文本中的关系句式类型实例Table 2 Examples of relation sentence types in fishery standard texts
实体位置标签是由1和2来定义的,1表示该实体是三元组中的头实体,2表示该实体是三元组中的尾实体。当实体位置标签为1时,向后查找最近的实体2与之匹配,当实体位置标签为2时,向前查找最近的实体1进行匹配。普通关系类型最后抽取结果为:{实体 1,关系类型,实体 2}。在一对多重叠关系类中抽取结果为:多组{实体1,关系类型,实体2(1、2、3....n)}。在多对一重叠关系类中抽取结果为:多组{实体1(1、2、3....n),关系类型,实体2}。句式标注实例如图1所示。
2 基于双重注意力机制关系抽取模型
针对渔业标准文本实体关系抽取任务中长序列前段语义稀释和向量权重分配不合理的问题,提出了基于双重注意力机制与 BERT-BiLSTM-CRF( Bidirectional Encoder Representations from Transformers-Bi-directional Long Short-Term Memory-Conditional Random Field)渔业标准实体关系抽取模型。自下而上分别为:BERT层、BiLSTM层、字注意力机制、句子注意力机制和 CRF输出层五部分。BERT模型是预训练模型,利用其双层双向转换解码的特性,自动学习句子特征信息,获取句子的向量表示;BiLSTM模型从BERT输出中学习到目标实体的上下文特征信息;字级别和句子级别注意力机制层用来提高目标词语和句子在段落中的权重;CRF解码器把注意力机制层的输出以序列标签形式输出。基于双重注意力机制与BERT-BiLSTM-CRF模型框架如图2所示。
2.1 BERT
BERT预训练模型网络架构使用了多层 Transformer编码器[22]进行编码,随后采用自注意力机制将句子中的每一个词建立了线性相关,得到更为全面的词向量、段向量和位置向量,有效解决了自然语言处理任务中长期依赖问题。
在渔业标准文本实体关系抽取任务中,渔业标准号结构较为复杂均是由多个字母、数字组合而成,所以词向量、段向量和位置向量在渔业标准文本任务中具有重要作用,同时 BERT模型可以获取更多特征信息和上下文信息,提升实体关系识别效果。因此将 BERT模型引入渔业标准实体关系抽取模型框架中。BERT模型输入表示实例如图3所示。
2.2 BiLSTM
为了解决RNN在自然语言处理任务中容易出现梯度消失和梯度爆炸问题,研究者们提出了LSTM,LSTM是一种特殊的循环神经网络模型,可以实现长序列记忆功能。通过对渔业标准文本的分析发现,渔业标准文本中实体长度较长,且与上下文存在着较大依赖关系,虽然LSTM解决了文本任务中长距离依赖问题,但是只能得到目标实体的上文信息,所以引用 BiLSTM[23]模型取代LSTM模型。BiLSTM模型是由正反两个LSTM模型叠加而成,弥补了目标实体无法接取到下文信息的问题。BiLSTM模型结构如图4所示。
2.3 双重注意力机制
注意力机制提出后在计算机视觉领域得到了广泛应用[24-26],后被引入文本领域[27]。本文采用双重注意力机制,分别为字注意力机制和句子注意力机制。字注意力机制是在一个句子中将更高的权重赋予需要抽取的目标字符,例如:GB/T27520—2011规定了暗纹东方鲀的种质检测,抽取结果为{GB/T27520—2011,规定,暗纹东方鲀的种质检测},基于字注意力机制在抽取过程中会赋予“规”“定”及两个实体更高的权重以得到正确结果。在进行关系抽取任务过程中语料内很多句子不包含关系三元组,不能作为我们目标句子进行关系抽取,例如:暗纹东方鲀为一次产卵型鱼类。虽然包含了暗纹东方鲀实体但是不存在关系三元组,对关系抽取任务是无效的,因此使用句子注意力机制对存在关系三元组的目标句子赋予更高的权重,能够有效地提高关系抽取结果。因此引用了字级别和句子级别双层注意力机制,相对于单层注意力机制能够更好地排除噪音干扰,提高准确性。
2.3.1 字级别注意力
基于字级别注意力机制:通过计算每个字符与预测目标实体的匹配程度,构建字级别的权重矩阵,将字向量组合成句子向量,从而得到每一个句子的分布式表达,具体算法[28]流程如下
式中H是上一层BiLSTM的输出集合;M是全连接的隐藏表示;α是权重矩阵;β是训练好的参数;βT和T α为β和α的转置;r′是句子分布式表达式;r为最终分类句子表达式。
2.3.2 句子级别注意力
基于句子级别注意力机制:以字注意力机制层的输出作为输入,通过计算每个实体对句子与预测的关系类匹配程度,构建句子级别权重矩阵,最终得到句子的向量表示,具体算法[29]流程如下
式中s是字注意力机制层的输出向量表示;αi是每个句子向量ri的权重;函数ki表示每个句子ri与输入句子r预测关系的准确性;N为权重α的对角矩阵;T为所有关系向量组成矩阵;s为实值向量;b是偏置矩阵;O为神经网络的输出。
2.4 CRF
CRF层[30]以BERT层、BiLSTM层和双重注意力机制层提取的上下文特征向量为输入,其主要功能是对语句进行序列标注。CRF能充分考虑到标签与标签的依赖关系,利用先前学习到的正确标签信息,来为当前位置进行标签预测,在输出标签时,CRF模型可以为标签添加约束,避免出现不合法的标签输出序列,输出全局最优解。
在进行关系抽取的标注任务中,对于目标句子X(x1,x2,x3...xi)的识别与标注流程为:首先,通过学习特征向量与标注结果的依赖关系,获得特征到标签的预测概率,由此得到每一个字符xi对应的标签,得到句子X预测的标签序列y(y1,y2,y3...yi),最后,运用句式分布的标注策略对预测的标签序列Y进行约束和调整,即可得到目标句子X的最佳标签序列。CRF层具体算法流程如下
式中A为转移矩阵,Pi,yi表示句子中第i个字的第y个标签的概率;输入序列为X;输出序列为y。
2.5 试验设置
本文全部试验都是在Windows 10下进行,所使用显卡为GeForce RTX 2080Ti,其配置如表3所示。

表3 GeForce RTX 2080Ti显卡配置Table 3 GeForce RTX 2080Ti graphics card configuration
试验环境为基于Google公司的机器学习框架Keras,Python版本为3.6。整个网络的权重按照均值为0,标准差为0.1的高斯分布进行初始化。考虑到Adam优化算法[31]具有所占资源少,模型收敛快等优点,因此采用Adam 算法。
本文还对模型的学习率(learning rate)、丢弃率(dropout)、批次处理大小(batch-size)和迭代次数(Epoch)4个模型参数对模型性能影响进行分析,具体如图5所示。初始学习率的设定会对模型的识别效果产生影响,过大会导致模型不收敛,过小则导致模型收敛特别慢或者无法学习,通过试验发现,选用初始学习率为0.002时模型的效果较佳。丢弃率可以有效缓解过拟合的发生,在一定程度上达到正则化的效果,结果表明,当丢弃率为0.5时模型拟合程度较好。批量处理大小决定了数量梯度下降的方向,选用批量处理大小为32时效果较佳,过小则更难以收敛,噪声也相应增加,过大则会使梯度方向基本稳定,容易陷入局部最优解,降低精度。随着迭代次数增加,模型的准确率也随之增加,当迭代次数达到150次时模型的F1值达到最高值92.67%,随后模型的识别精度趋于稳定。
2.6 评价方法
对渔业标准文本实体关系抽取任务结果,使用 3个评价指标[32]分别为准确率(Precision)、召回率(Recall)、F1值(F1-score),F1值是P值和R值的综合评价指标。
3 结果与分析
试验使用DLOU-FSI语料库(36万字符),按8∶2的比例随机分成两部分,其中28.8万字符作为训练集,7.2万字符作为测试集,消除试验过程中训练集和测试集不同带来的结果误差。
为了验证所提出句式分类的标注策略和基于双重注意力机制与BERT-BiLSTM-CRF模型对渔业标准文本实体关系抽取效果的提升,设计了 3组对比试验分别为:标记方法间效果对比试验、添加不同注意力机制性能对比和模型对所有关系类别提升效果对比。
为了验证提出的句式分类标注策略能有效解决渔业标准文本中的重叠关系,分别使用 Zheng等[19]的标注策略和句式分类标注策略(our method),进行语料标注。试验采用本文提出的 BERT-BiLSTM-Att(s)-CRF模型和 DLOU-FSI语料库,对所有关系类型进行抽取任务,试验结果如表4所示。

表4 不同标注方法对关系抽取结果影响Table 4 The effect of different labeling methods on the results of relation extraction
Zheng的标注方法采用最近距离匹配原则,并遵循每个实体只能参加 1个关系的规则,在渔业标准文本语料库 DLOU-FSI完成关系抽取任务时会造成关系丢失,重叠关系无法抽取等问题,导致关系抽取任务召回率和F1值较低。使用句式分类的标注策略有效的解决了渔业标准文本中重叠关系无法抽取的问题,准确率、召回率和F1值分别提升了7.93个百分点、29.82个百分点和20.56个百分点,大幅度提升了关系抽取任务的召回率和F1值。说明本文提出的句式分类的标注策略有效提高了渔业标准文本实体关系抽取任务的结果。
为了验证所提出的双重注意力机制有助于提升渔业标准文本关系抽取任务的结果,分别在没有添加注意力机制[33](BERT-BiLSTM-CRF)、单层字注意力机制[34](BERT-BiLSTM-Att-CRF)、双重注意力机制(BERT-BiLSTM-Att(s)-CRF)3种情况下对所有关系类别进行实体关系抽取任务,试验结果如表5所示。

表5 不同注意力机制的抽取结果Table 5 The extraction results of different attention
结果表明,在只添加字注意力机制情况下试验结果有一定的提升,准确率、召回率、F1值分别达到 90.49%、89.82%、90.15%。在使用双重注意力机制时,关系抽取结果有显著提升,三项指标分别提升了 2.18个百分点、2.49个百分点和 2.34个百分点,说明了 BERT-BiLSTMAtt(s)-CRF模型有效提升了关系抽取整体效果。
为验证本文提出的模型是否能够提高所有关系类型的抽取效果,对 7种实体关系进行对比试验,试验结果如表6所示。

表6 渔业标准文本实体关系识别结果Table 6 Recognition result of entity relationship in fishery standard text
由表6试验结果可知,提出的基于双重注意力机制的BERT-BiLSTM-CRF在7种关系类别的抽取任务中识别准确率均高于其他模型。其中引用关系、规定、发布、提出、起草和归口这6种关系类别准确率、召回率和F1值均有较大的提升均达到 90%以上,其原因是,本文提出的模型能够充分地利用句子结构信息,更好地分配权重,适配于渔业标准文本的关系抽取任务。但在比较关系类别对比试验中,随着模型算法的改进,关系抽取结果并没有得到较大提升,召回率还有些许回落。通过分析发现其原因是,比较关系这一关系类别句子样本分布稀疏,在 DLOU-FSI语料库中,每篇渔业标准文本只包含0-3个比较关系三元组,不足所有关系类三元组总数的1%,使模型无法学习到更全面的关系特征,导致实体关系抽取任务识别效果较差。
由上述分析可知,在渔业标准文本关系抽取任务中,除了模型算法的改进,语料库质量也十分重要,深度学习模型训练学习数据越多质量越高,模型识别效果也就越准确。在模型算法适配的情况下,试验结果达到一定数值且无法有较大提升时,需要对数据进行有效扩充,增加样本数量和多样性,以提升关系抽取的整体效果。
4 结 论
1)针对渔业标准文本中存在大量重叠关系等问题,提出了一种句式分类的标注方法,通过重叠关系标签解决了重叠关系无法抽取的问题,为其他领域关系抽取任务提供了新思路。
2)提出基于双重注意力机制与BERT-BiLSTM-CRF的渔业标准实体关系抽取模型,利用模型框架中的字级别注意力机制和句子级别注意力机制更好的分配权重,排除噪音,提高实体关系抽取的识别精度,准确率、召回率、F1值达到了92.67%、92.31%、92.49%,为构建渔业标准知识图谱提供参考。
在渔业标准文本中仍存在一些有抽取意义的关系三元组,由于其样本稀疏且句式多样导致抽取效果不够好,例如“比较”关系。因此,下一步工作是如何提高少样本关系类别的抽取结果,以提升渔业标准文本实体关系抽取的整体结果。
猜你喜欢
当代水产(2022年7期)2022-09-20
今日农业(2022年14期)2022-09-15
今日农业(2021年8期)2021-11-28
当代贵州(2020年26期)2020-08-21
中国外汇(2019年18期)2019-11-25
当代陕西(2019年5期)2019-03-21
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
