
基于Linux的Hadoop平台搭建及测验研究
2021-10-11 09:37李小立
魅力中国 2021年32期
李小立
(长沙民政职业技术学院 软件学院,湖南 长沙 410000)
一、Hadoop 简介
Hadoop 是一个由Apache 基金会所开发的分布式系统基础架构,它允许用户使用简单的编程模型跨计算机集群分布式处理大型数据集[1]。其核心组件包括HDFS、Yarn 和MapReduce,其中HDFS 是分布式存储系统,用于提供高可靠性、高扩展性和高吞吐率的数据存储服务;Yarn 是资源管理系统,负责集群资源的统一管理和调度;MapReduce 是分布式计算框架,具有易于编程、高容错性和高扩展性的优点。由于Hadoop 带有用Java 语言编写的框架,因此使用Linux 系统搭建Hadoop平台更具有优势,该文将使用Linux 系统进行平台搭建。
二、Hadoop平台部署
Hadoop 支持在GNU/Linux 系统以及Windows 系统上进行安装使用,在实际开发中,由于Linux 系统的便捷性和稳定性,Hadoop 集群一般是在Linux 系统上运行的。Hadoop 集群的搭建方式分为3 种,包括独立模式、伪分布式模式和完全分布式模式。该文将使用三台虚拟机搭建一个伪分布式模式Hadoop 集群。Hadoop 集群的搭建一般需要多台机器,从而保证集群的稳定性和可靠性,但一般实验情况下,由于条件限制,通常借助虚拟机软件在一台物理机上创建多个Linux 虚拟机环境。
(一)准备工作
使用的软件包括Vmware Workstation14.0,JDK 1.8,Hadoop2.8.3,Redhat Linux7.0,集群规划如表1 所示。
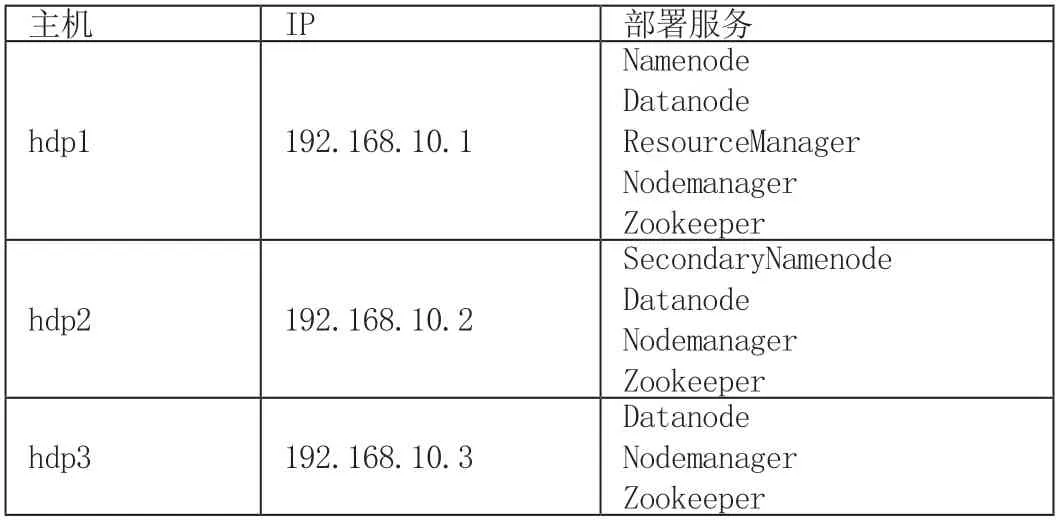
表1 集群规划
(二)软件安装及集群配置
使用Vmware Workstation 虚拟机软件构建三台虚拟机,并安装RedHat Linux 系统,安装过程该文不进行详细描述[1]。
1.Linux 系统网络配置
设置每台虚拟机的网络连接,使用仅主机的连接模式,并测试网络连通性。修改主机名与IP 地址映射配置,测试三台主机之间的连通性,分别在每台主机上使用ping 命令去ping 另外两台主机的IP 地址或主机名。
2.设置节点互信
在集群开发与使用中,主节点通常会与集群中的其他节点进行通信,由于Linux 系统的安全设置,在节点与节点进行访问时需要输入目标节点的用户名和密码,因此为了保障集群服务的连续运行,通过配置SSH 服务来实现免密登录。使用ssh-keygen-t rsa 命令生成秘钥,并使用sshcopy-id 命令将公钥拷贝至其他节点。在每个节点都进行SSH 服务配置,配置完成后使用ssh 进行访问测试,此时可在任意一个节点自由切换至其他节点且不需要输入用户名与密码。
3.为所有节点配置JDK 和Hadoop
第一步,安装JDK 与Hadoop。
第二步,配置系统环境变量,修改/etc/profile 文件,在文件末尾添加JAVA_HOME 与HADOOP_HOME 环境变量,并修改PATH 环境变量。修改完配置文件后,使用source/etc/profile 命令使配置生效,并使用 java-version 命令查看JDK 版本信息。
第三步:修改Hadoop 环境变量
三、配置Zookeeper 集群
(一)Zookeeper 安装
下载并解压zookeeper-3.3.5.tar 到/hadoop 目录,将zookeeper-3.3.5.tar 复制到另外两台机器,每个节点创建存放数据的目录/hadoop/data。
(二)Zookeeper 相关配置
1.设置Zookeeper 相关配置文件。其中需要注意的是hdfs-site.xml文件,该文件用于设置HDFS的NameNode 和DataNode 两大进程。可在该文件中设置节点个数及第二个NameNode 网络端口配置。文件中
2.启动Zookeeper 服务
修改完所有配置文件后,将配置文件复制到其他机器,并为每个节点添加id,启动zk 服务并查看状态,然后启动journalnode,在hdp1 上格式化namenode 节点及zk,格式化成功后在hdp1 节点上启动NameNode 服务并在备节点同步主节点数据,最后在主节点上启动所有服务,启动成功后在各个节点查看服务启动状态。各节点服务启动状态如表2 所示。
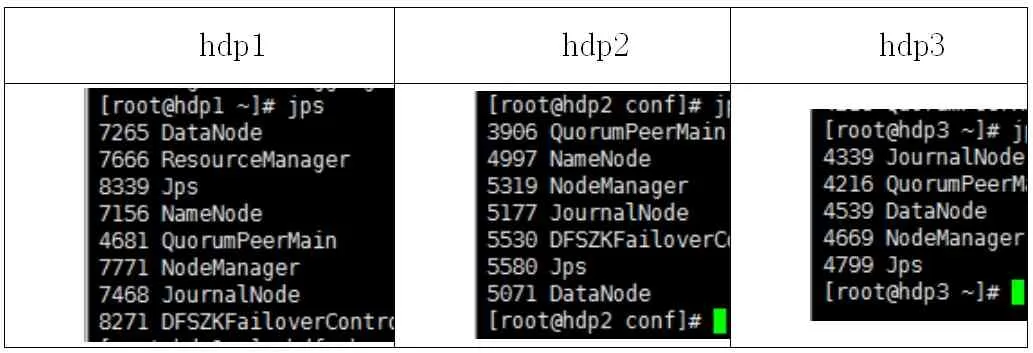
表2 节点服务器启动状态
四、集群测试
为了保证整个平台的稳定工作,在Zookeeper 引入Watch 机制,对集群的各个节点进行监听,当集群中的主节点无法正常工作时,则集群立即启用备用节点。该测试将模拟hdp1 节点故障,查看hdp2 上的NameNode 服务是否能成功激活。
(一)查看节点状态
1.查看hdp1 节点状态,如图1 所示。
2.查看hdp1 及hdp2 上的NameNode 状态,其中hdp1 为active 状态,hdp2为standby状态。表明当前hdp1节点上的NameNode服务处于激活状态。
3.模拟hdp1 节点故障,即杀死hdp1 节点上的NameNode 服务对应的进程。查看hdp1 与hdp2 节点的NameNode 服务状态,如图2 所示。
重新启动hdp1 节点的NameNode 服务,查看服务状态。此时,hdp1 节点的NameNode 服务已变为standby。至此,Hadoop平台及Zookeeper 集群均已准备就绪。
五、词频统计测试
在hdfs-site.xml 文件中,可设置进行MapReduce 计算时数据切分的数据块大小,默认为128M。在个人学习或测试中,该值设置过大,一般个人的测试数据大小为KB 或者MB 级别。因此,为了进行试验对比,该文中将数据块大小修改为1MB,分别使用大小为2.5MB的文件和2KB的文件进行词频统计[2],试验结果对比如表3 所示。

表3 词频统计结果对比
六、总结与展望
该文详细介绍了Hadoop平台部署与Zookeeper 集群部署,成功搭建了一个Hadoop 分布式架构平台,并进行了集群测试及词频统计对比实验,为以后大数据研究工作提供了一个实践平台。
猜你喜欢
煤气与热力(2021年9期)2021-11-06
军民两用技术与产品(2021年5期)2021-07-28
纺织科学研究(2021年6期)2021-07-15
电子制作(2019年22期)2020-01-14
军事运筹与系统工程(2019年4期)2019-09-11
信息化建设(2019年2期)2019-03-27
亚太教育(2018年5期)2018-12-01
长江丛刊(2017年27期)2017-12-01
知识就是力量(2017年2期)2017-01-21
燕山大学学报(2015年4期)2015-12-25
