
基于文本挖掘的高校环境在线评论研究
2021-10-08 10:21邱均平孙月瑞杭州电子科技大学中国科教评价研究院管理学院
图书馆理论与实践 2021年5期
邱均平,孙月瑞,b(杭州电子科技大学.中国科教评价研究院,b.管理学院)
自20世纪90年代我国逐步引进国际科技期刊的评价体系以来,我国科研能力迎来了巨大的提升,作为培养优秀高等人才的高等院校,科研素养和学术成果成为评价一所大学的核心标准。但近些年一些部门对该标准的过度依赖,大学评价在实践应用中逐渐趋向单一化。
大数据时代的来临促使数据挖掘技术日益成熟,合理利用机器学习等手段能够较为准确、快速地发现知识、总结规律。其中,文本挖掘作为数据挖掘的一个重要分支,近些年来获得了巨大发展。目前,对网络评论的文本挖掘研究主要集中于商品评论、网络舆情这两个方向,而对学校环境的在线评论研究关注不足。微博、知乎等社交媒体已经成为大学生了解信息、相互讨论、表达诉求的主要渠道[1],本研究以浙江工业大学、杭州电子科技大学和浙江师范大学为例,通过收集评价大学的在线评论数据,利用文本挖掘技术对评论进行文本拆分,对生成的各评论语句集进行情感分类,探寻产生消极评论的主要问题,并对教学的非消极评论进行词频统计,所获得的实验结果可以洞悉大学生对所在学校的生活服务、学习体验的集中情感,把握学校的热门专业和学科特色。
1 相关研究
目前,我国对于高校的评价以学术评价为主。占侃[2]对我国高校主要评价体系做了对比分析,发现各机构单位都重点考量高校的创新能力,但由于评价的实体指标各有侧重,高校评价结果往往并不相同。大数据时代,很多学者提出了对大学评价体系的质疑和改进措施,如汤建民等对高校科研业绩评价是否科学、如何改进提出了意见[3],唐晓波等[4]构建了依托大数据技术的信息云平台和智能服务框架。在学校的内部评价中,很多研究工作转向于学生教学评价文本,如范宇辰等[5]利用词典匹配法与情感词库统计中文教评文本的情感得分,刘毓等[6]结合Word2Vec与支持向量机方法实现对科教短文本数据的情感分类。
随着互联网的高速发展,人们能够在虚拟的网络中畅所欲言,将凝聚个人情感的评价信息发布于网络,形成了许多以某一对象为中心的海量的、富有内涵的评论集,如何从中挖掘出有价值的知识成为学者研究的热点问题。陆泉等[7]利用朴素贝叶斯分类和“密度—距离”快速搜索聚类实现了专业领域稀疏环境下微博评论的热点主题挖掘;李金海等[8]从百度贴吧中收集本校的言辞信息,探索高校舆情形成的原因和影响;杨单等[9]从两所高校的网络舆情热点出发,利用Rost、Gooseeker等工具进行情感分析,合理地判断了网络舆情的走势。但是,除了上述研究方向外,对于网络用户(特别是正在就读或曾就读过的学生)对大学环境的在线评论的研究却少有开展。
2 数据收集
本研究从各网站中收集网络用户对浙江工业大学、杭州电子科技大学、浙江师范大学这三所院校的在线评论,主要以“某某大学怎么样”的提问方式收集评论,获取信息的主要平台有百度知道、中国教育在线、知乎和职朋校友圈,发表评论的时间跨度定为2016年1月1日至2021年1月1日。通过剔除重复评论,最终获得5,889条评论,其中浙江工业大学1,771条、杭州电子科技大学2,441条、浙江师范大学1,677条。所获得的评论样例见表1。

表1 学校评论样例
3 文本拆分
本研究最初收集到的评论大都是对院校的综合评价,为了更合理地对评论文本进行分类分析,笔者对评论进行拆分。在细粒度文本抽取上,康月等[10]利用句法特征对评论的实体、属性、情感进行标注,形成训练集后对BERT词嵌入的BILSTM-CRF注意力机制模型进行训练,取得了良好的效果。周清清等利用评论中高频名词作为候选属性词,利用word2vec模型词向量表示并进行AP聚类,通过降噪等处理,较好地实现了细粒度属性抽取[11]。
本研究获得的大部分在线评论的内容跨度非常大。通过观察,笔者发现这些评论主要围绕吃、住、景、学习这四个主题展开。为了解决评论内部细分问题,笔者利用StanfordNLP工具对其进行词性标注,提取评论中的名词,再结合word2vec模型,形成名词的词向量形式,通过AP聚类形成初始类簇,达到词语词义相近则相聚的效果。接下来,笔者对分类的各词集进行评论语句重现,将其作为辅助参考,对形成的各个类簇进行人工分类,最终构成以“饮食”“景色”“教学”“住宿”“其他”为类别的评论语句集。
3.1 名词提取和表示
对三所院校的评论数据进行变换。具体地,对各院校的评论进行切分,以逗号、句号、问号等有句间停顿意义的符号作为分割点,形成新的评论语句集,再利用StanfordNLP工具对评论集进行词性标注,抽取名词(带有“NN”和“NR”标注的词语)并删除代词后,生成关键词,最终得到6,779个关键词。
本研究借助word2vec模型对关键词进行词向量表示。word2vec是Mikolov等提出的,这种词向量表示方式名为“Distributed Representation”,能有效避免“One-hot Representation”维度高、词间相似难以比较等问题[12-13]。利用语料库对word2vec进行训练,可以表示词语的词向量,并且意思越相近的词语在向量空间上的位置越接近。word2vec有两个训练模式,分别为Skip-Gram和CBOW,前者以输入词来预测上下文,后者是以输入上下文来预测当前词。本研究采用的训练模式为Skip-Gram,该模式的模型是一个三层神经网络,选择5作为上下文窗口参数,250作为词向量维度。笔者以维基百科、微信公众号文章的海量文本集作为语料库,对word2vec模型进行训练,在训练好的word2vec模型中输入去重后的关键词,表示出关键词的词向量形式。
3.2 名词聚类
聚类指将许多实在或者抽象的对象按自身某些属性或动作之间的相似情况进行划分,形成不同类别的集合。本文对关键性名词的词向量进行AP聚类。AP(Affinity Propagation)聚类算法由Frey[14]等提出,该算法将所有样本当作潜在的聚类中心看待,定义样本对每一个其他样本具有两个属性,分别为吸引值(responsibility)和归属值(availability)。在聚类过程中,不断更新样本对每一个其他样本的属性值,直至两值(吸引值和归属值)稳定或达到最大迭代次数,两值相加后得到最大的、相对应的样本对象作为该样本的聚类中心。AP聚类无须设置初始聚类数目,聚类过程依托于样本之间的相似度,适合多维度的数据集。相似度量方法有余弦系数、曼哈顿距离、负欧式距离等多种,本研究采用负欧氏距离和余弦系数进行聚类并对结果进行对比。负欧氏距离公式和余弦系数公式分别如公式(1)和公式(2)所示。
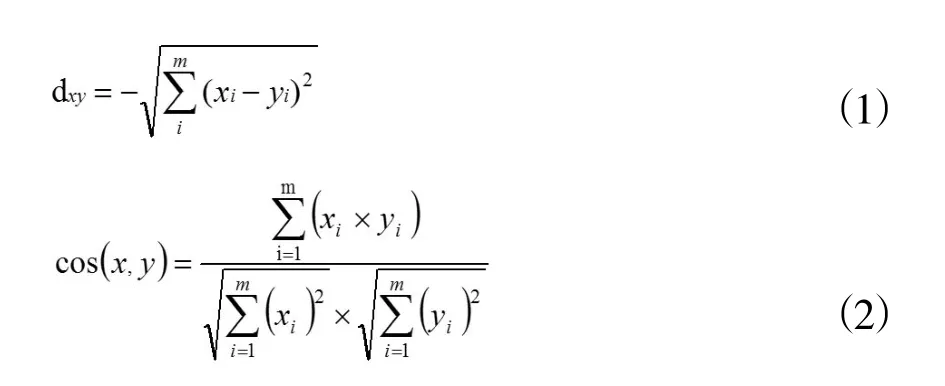
其中,x与y分别代表两个样本,xi与yi分别代表这两个样本在i维特征的数值,m代表词向量的总维数,dxy和cos(x,y)代表两个样本间的相似度。
笔者以距离中值为参考度,阻尼系数为0.5,对关键词分别进行聚类,得出的部分聚类结果见表2。

表2 部分聚类结果样例
通过对比分析,以负欧氏距离为相似度量的方法表现更优,更有利于接下来的人工分类。因此,本研究使用负欧氏距离作为聚类的距离计算方式,聚类最终形成439个簇。笔者对含有聚类词语的原有评论语句进行还原、重现,重点参考每个聚类的聚类中心,以簇为单位进行人工区分,以“饮食”“景色”“教学”“住宿”“其他”进行分类。由三位经过培训的志愿者进行分类,对分类结果进行一致性检验,Cohen's kappa系数[15]分别为0.826(标准误差为0.025)、0.843(标准误差为0.024)、0.97(标准误差为0.11),P小于0.001,可见上述三人的分类结果具有较强的一致性,分类效果具有高信度。按分类结果对各评论进行不同地标号,同时附上学校代号,得到五类评论语句集(见表3)。
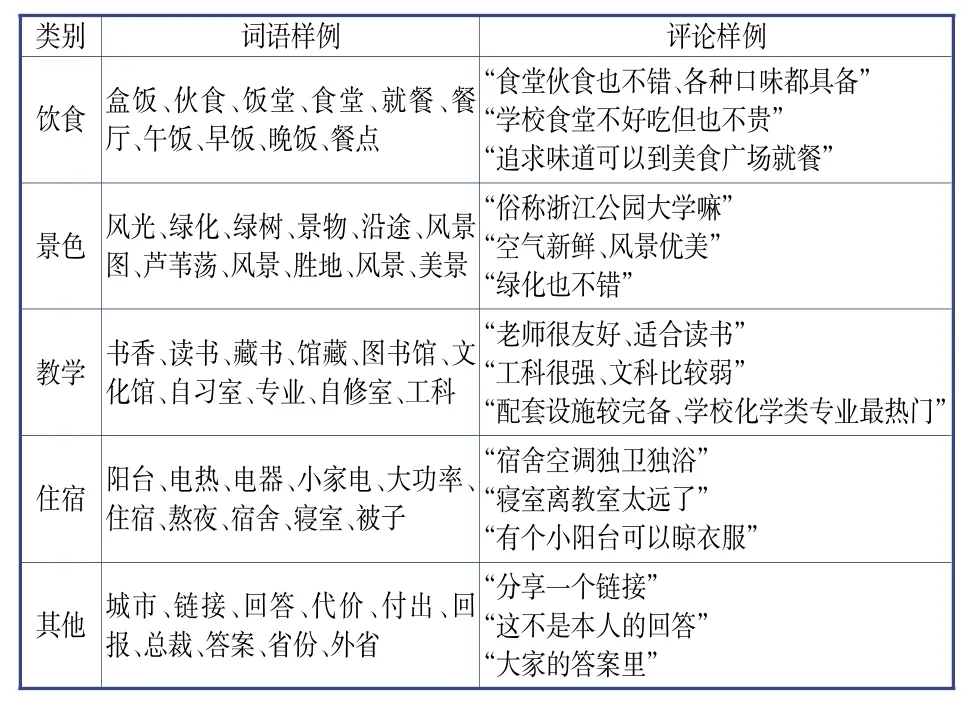
表3 五类词语集和评论语句集样例
4 情感分析
为了解网络用户对不同院校的情感倾向,本研究对分类后新的评论语句集进行情感判断。在情感分析上,朱军等[16]通过判断评论是否含情感词,如果有则利用情感词典和朴素贝叶斯分类进行情感判断,没有则利用支持向量机进行判断,在酒店评论集上取得了良好效果。陈玉婵等[17]利用情感词典和SnowNLP工具相结合的方法对学生的评教文本进行情感分析,在测试集上取得了不错的分类效果。近年来,典型的深度学习方法如循环神经网络、卷积神经网络等在文本分类上取得了良好效果,其中预训练语言模型的方法效果十分出色。BERT模型[18]是Google提供的预训练语言模型,它利用双向Transformer网络结构来获取文本语义信息,它具有迁移学习的能力,针对文本分类、实体识别、语言翻译等不同下游处理任务时,在外接输出层下利用该预训练模型进行参数微调训练,就可满足任务需要。ERNIE模型是BERT的中文改进增强模型,由百度提供,在掩码语言模型训练阶段上,增加了短语级与实体级掩码,即将掩码层次从字提升到了词。
本研究利用ERNIE预训练模型外接线性分类器的方式进行情感分类,直接使用已经发布的ERNIE预训练模型,进行参数微调训练。从SnowNLP工具包中获取带有情感标注的训练集,将它作为ERNIE模型微调所需的主要训练语料。同时将许多事实性语句,如学校简介、景点介绍、食品说明等,标为非消极类别,归入到训练集中。
4.1 效果验证
为了考察该情感分类方法是否对本次评论语句集有效、是否能准确识别出消极评论,笔者从评论语句集中随机抽取200个评论进行人工标注。由于其中消极评论较少,所以从网络中搜索了90份酒店消极评论和90份教学消极评价进行补充,形成测试集。
SnowNLP的情感分类器是基于贝叶斯模型生成的,来源于Python的第三方库。笔者将情感词典和SnowNLP相结合的情感分类方法作为本次验证效果的对照组方法,总体流程见图1,其中SnowNLP分类器以本次训练集进行过二次训练。

图1 基本流程
本研究使用精确率(precision)、召回率(recall)与F1值(F1 measure)进行效果验证(见表4)。精确率指正确预测某一类别数目跟全部预测为该类别数目之间的比,召回率指正确预测某一类别数目跟实际上是这一类别的全部数目之间的比,F1值指精确率与召回率的调和平均数。需要注意的是,在情感词典和SnowNLP相结合的方法中,分词使用了Jieba工具,停用词参考了百度资料,情感词典大部分来自知网中文情感词典和大连理工大学的中文情感词汇本体库[19];在利用ERNIE模型的方法进行训练时,Learning rate为1e-5,epoch为3。
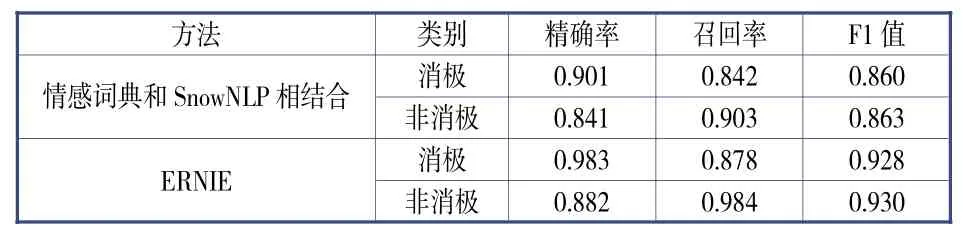
表4 评估指标得分
可见,在精准率、召回率、F1值这三个指标上,不论是消极类别还是非消极类别,基于ERNIE模型的情感分类方法都能很好地实现分类效果,且效果优于通过情感词典和SnowNLP相结合的方法。
4.2 情感分类
笔者对以“饮食”“景色”“教学”“住宿”为类别的四种新评论语句集进行情感分类,得出不同类别下不同院校的情感分布(见图2)。
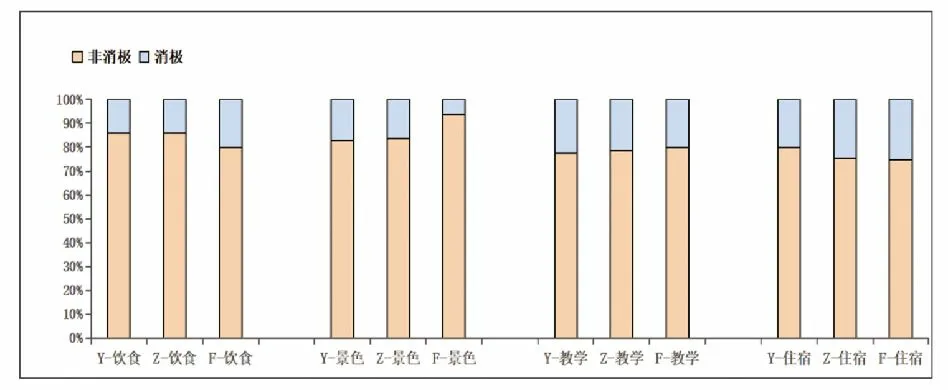
图2 不同类别下不同院校的情感分布
由图2可得:纵向比较上,三所院校在饮食、景色、教学、住宿上均以非消极评价居多;横向比较上,三所院校在各类别上的消极程度各有差异,但并不明显。为了探究学校在各类别上产生消极评论的主要原因,本研究对消极评论做来源统计分析,使用公式(3)得出图3,使用公式(4)得出图4。

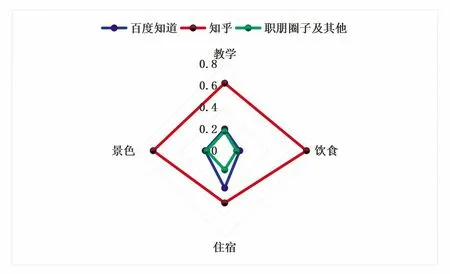
图3 消极评论来源分布

图4 消极评论在来源评论中的占比
由图3、图4可知,在所有类别评论语句集中,来源于知乎的消极评论占比最高且在来源于知乎的评论中发现消极评论的可能性最高,因此本次重点分析各类别中来源于知乎的消极评论。这也表明,知乎作为互联网问答社区,可以作为学校考察自身管理是否存在不足的有效途径。
考虑到消极评论的真实性和可信度,笔者分别统计知乎各类别消极评论中所反映各个问题的次数(以所来源的评论用户为统计单位),并主要统计2019年后的评论内容(见表5)。

表5 多类别问题
通过评论细分、情感分类和来源分析可以较好地洞悉网络用户对院校各方面的评价及院校管理服务上的遗漏,对学校改善学校服务水平具有极大的现实意义。
4.3 词频分析
为了深入分析三所院校在教学特色方面的差异,寻找出能使社会公众(特别是学生家长、企业招聘单位、外部评价机构)了解院校教育优势所在的方法,本研究对非消极的教学评论语句集进行了词频分析。
具体地,对三所院校的非消极教学评论语句集以评论用户为单位进行合并,在对新的评论集进行去除表情符号、学校的名称与俗称、数字、字母与标点符号等处理后,再对其进行分词、去停用词和去重,构造出每个评论对应的词语集合,然后以每个词语集合所对应的院校进行分类,分别汇集成有关Y、Z、F三所院校的词语列表,并对词语进行频率统计,将每个列表最靠前的五个专业视为热门专业(见表6)。

表6 高频专业
由于词语列表中有关三所院校的相同高频词语(如大学、学校、浙江省等)较多,使一些真正有价值的词语不容易察觉。为了解决这一问题,笔者将Y、Z、F院校所涉及的词汇视为元素,分别组成Y、Z、F集合,制作韦恩图(见图5)。其中,DG、EG、FG区域分别表示Y集合与Z集合的词汇交集、Y集合与F集合的词汇交集、F集合与Z集合的词汇交集(这里的交集指多个集合中相同的词语并且该词语在原有列表中的频率相除不超过2且不低于0.5),G区域表示Y、Z、F三者集合的词汇交集,A、B、C区域分别表示Y、F、Z集合中除了上述交集词汇外的特有词汇。将韦恩图中的词汇继续绘制成词云图(见图6),词语频数参考原有词语列表中的频率,交集区域中的词语频率为该词语在含有该词语的多个词语列表中的频率平均值。
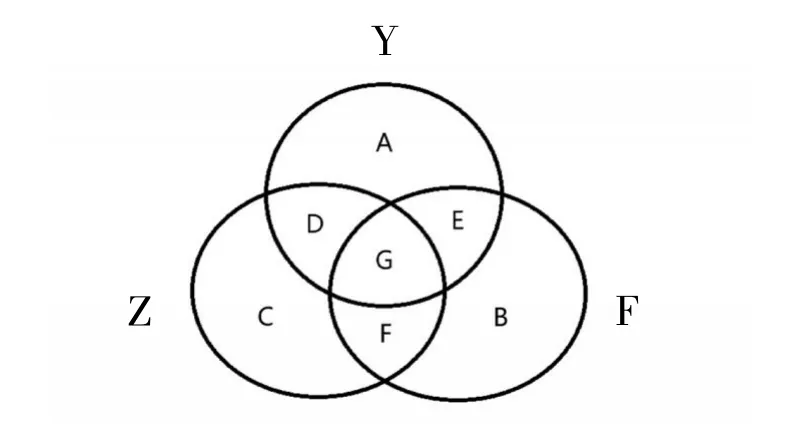
图5 集合样式

图6 三所院校的集合词云
由表6及图6可知,有关这三所院校的非消极教学评价各有侧重点,三所院校在学科特色方面具有较大差异。在涉及Y院校的高频专业名称中,化工、机械、制药、化学被高频提及,结合图6表明Y院校在工科教学方面的能力较为突出;在涉及Z院校的高频专业名称中,计算机、电子信息、通信工程、自动化这些学科被高频提及,结合图6表明Z院校在信息处理领域的教学能力较为突出,同时会计作为经济管理类专业也出现在了表格上,表明该专业受到网络用户的重点推荐;在涉及F院校的高频专业名称中,汉语言、英语、体育、数学被高频提及,结合图6表明F院校在教育相关专业的教学能力较为突出,受到了评论用户的普遍认可。同时,计算机专业均出现在这三所院校的高频专业里,说明三者有关计算机的专业实力得到了网络用户的普遍认可。
总体上,该研究结果有利于学校加强自身管理,达到改善学生体验的效果,同时,本研究所涉及的评论研究方法有利于外部评价机构更加多方位评价一所院校,给出合适结论。当然,该研究过程中还存在不足:如在评论拆分上,是通过句间停顿进行句子切分,在极少部分评论中,后句是前句的补充,并且不含名词,可能会被遗弃而丢失重要的评价信息;在情感分类上,精确率和召回率虽然分值很高,但在消极评论上仍存在误判,在情感分类的效果上还有较大的提升空间。
猜你喜欢
新世纪智能(语文备考)(2020年4期)2020-07-25
现代计算机(2018年27期)2018-10-25
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
小学阅读指南·低年级版(2015年11期)2015-09-10
海峡姐妹(2015年3期)2015-02-27
小学生·多元智能大王(2014年6期)2014-07-09
小雪花·初中高分作文(2009年8期)2009-11-16
金点子生意(2009年7期)2009-09-29
