
面向书脊图像的特征提取与匹配技术研究*
2021-10-08 13:56任明武
计算机与数字工程 2021年9期
乔 笑 任明武
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
近年来,随着科学技术的迅猛发展,图像匹配技术已成为近代信息处理特别是图像信息处理领域中的重要技术。尺度不变特征变换(Scale-invariant Feature Transform,SIFT)[1~2]就是图像匹配领域内的一种用于描述图像局部特征的算法,被人们广为使用。由于我们目标图像是书架上的书脊,存在拍摄图像与数据库存储的书脊图像,具有尺寸、倾斜方向、拍摄亮度和角度都不一样的特点,所以我们选择Sift算法作为特征提取算法。它与其他特征提取算子的区别在于,特征信息具有旋转不变,尺度不变,亮度不变等特点,并且提取的特征信息量丰富,独特性好,准确率高。但是SIFT算子具有一个显著的缺点,就是其算法的复杂度十分高,从而导致提取特征信息的耗时过长,在一些具有实时性要求的应用场景下,不太能满足要求。随着时代的发展,之后出现了基于SIFT算子改进的许多变种算法[3~8],但都存在一些性能问题或者稳定性问题,都不能直接取缔SIFT算法。随着GPU[9~10]处理技术的飞速发展,它具有非常强大的计算能力,提高算法并行能力,从而使得SIFT算法加速成为可能[11~13]。
本文实现了基于统一计算设备架构(Compute Unified Device Architecture,CUDA)[14]下 加 速 的SIFT特征提取算法和特征匹配,并应用于书脊图像匹配中,使得图像匹配的实时性得到保证。
2 SIFT特征提取算法
SIFT特征点提取主要分成三大步骤:1)特征点位置定位;2)特征点方向赋值;3)特征点描述。首先为了满足SIFT算子的尺度不变性,要构造出多种尺度空间下的图像,例如地图上的比例尺。比例尺小、观测点距离景物近、景物更大、细节特征更多;比例尺大、离景物远、景物更小只能看到宏观的轮廓特征。尺度不变性就是无论在什么尺度空间观测,都能够辨认出目标。
多尺度空间的图像通常使用高斯金字塔表示形式,如图1。

图1 高斯金字塔
图像金字塔是通过将一张图像在它的不同的分辨率下的结果组成的。而对于相互紧挨的两层来说,上一层的图像是使用下一层的图像通过降采样的方式得出的。高斯函数可以对图像进行卷积操作,从而达到模糊的效果,并且应用互不相同的高斯核,通过计算可以得出模糊度不一样的图像组,由这些图像组进而可以形成一张图像的高斯尺度空间,具体公式如式(1)所示:

其中,式(1)中G(x,y,σ)是高斯核函数,具体的高斯核函数见公式如式(2)。

σ代表尺度空间因子,它的意义在于表示高斯正态分布的标准差。我们可以控制这个值来让控制图像被模糊化的程度。如果它的值越大,则代表图像被模糊的程度越大,相对应的尺度也就越大。L(x,y,σ)就代表着图像的高斯尺度空间。
构建完图像的多尺度空间后,要进行特征点的检测,科学家经过研究认为LoG[15~17]算子是提取图像特征的效果较好的算子,它的原理是通过高斯滤波去除噪声影响,然后提取图像边缘最强的点作为特征点,这也符合生活中线条轮廓越粗、颜色越分明的物体越容易被看清和辨别的规律。虽然使用LoG算子可以更加好地检测出图像中存在的特征点,但是它的计算量也非常大,所以一般使用差分高 斯(Difference of Gaussina,DoG)来 近 似 计 算LoG。设k为相邻两个高斯尺度空间的比例因子,则DoG的定义如式(3):

由上述公式可以推断,将两幅相邻的高斯空间图像相减,即可得到狗的高斯差分图像。在SIFT算法中,需要提取的特征点是差分图像中的极值点。为了找到这些尺度空间中的所有极值点,必须将图片上的每个像素与其图像域和尺度域中的所有相邻点进行比较。当像素值大于或小于所有相邻点时,这就是一个极值点。极值点比较示意图如图2所示,中间的监测点,要在其图像域与3×3个邻域的8个像素点进行比较,并且在尺度域中要与上下两侧的3×3领域18个像素点进行比较。
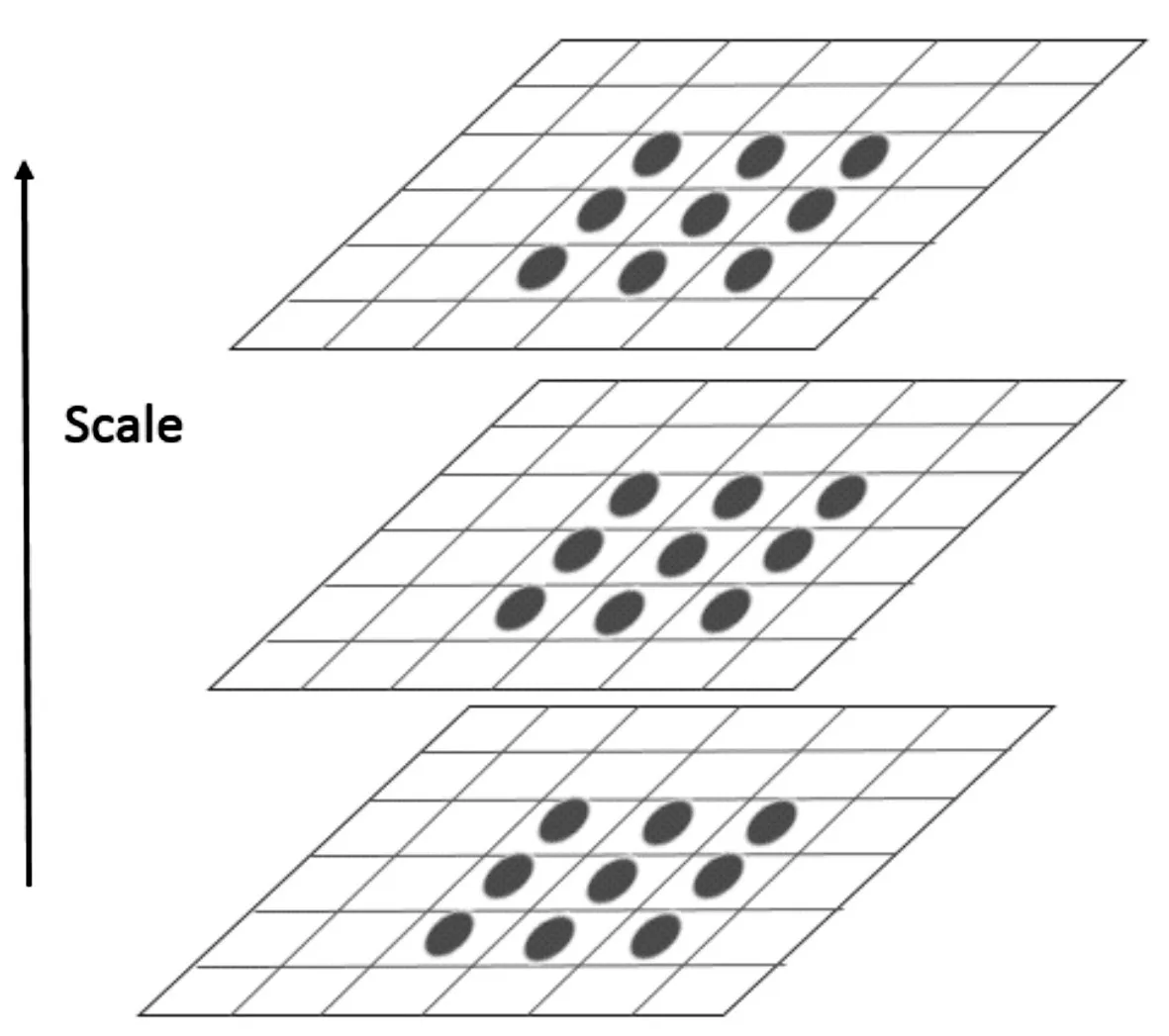
图2 相邻尺度域和图像域示意图
通过以上步骤,在不同的尺度上找到了所有的特征点。接下来,为了实现算法的图像旋转不变性,需要对检测到的特征点的方向进行分配。方向参数由特征点场中像素的梯度分布确定,然后利用图像的梯度直方图得到关键点局部结构的稳定方向。通过这个特征点,就可以找到该特征点的尺度σ,也就是可以得到该特征点所属于的尺度图像。接着计算以特征点为中心、以3×1.5σ为半径的区域图像的幅角和幅值,每个点L(x,y)的梯度的模m(x,y)以及方向θ(x,y)可以通过式(4)和式(5)求得:

经过以上所有步骤,就可以找到SIFT特征点的位置、尺度和方向信息。下一个任务是使用一组向量来描述这些关键点。这一步一般称为生成特征点描述符。该描述符不仅包含特征点,还包含对它们有贡献的特征点周围的像素。为了保证匹配的准确性,描述符必须具有高度的独立性。生成特征描述子的步骤一般包括三个步骤,如下所示。
1)校正旋转主方向,确保旋转不变性;
2)生成描述子,最终形成一个128维的特征向量;
3)为了去掉光照不均对特征点的影响,进行对特征向量长度进行归一化操作。
3 基于CUDA的SIFT特征提取
3.1 CUDA架构简介
CUDA[18]架构主要是针对具有大规格并行计算需求的问题的解决方案。在具有大量异构计算并且具有复杂性资源的领域问题下,使用CUDA架构是否有益。在该架构下,一般CUDA程序构架又两大部分组成:主机端和设备端。通常来说,主机端一般指的是CPU,而设备端一般指的是GPU。只有遇到需要并行计算任务时,才会放入GPU中执行,其他一般都在CPU上执行。遇到了并行任务,CUDA框架就会把该任务编译成GPU能够识别运行的程序,此程序在CUDA框架里称做核(kernel)。在实际计算的过程中,主机端控制台会根据需要计算的任务进行分类,将一些需要并行计算的任务与其相关数据拷贝到显存中,另一些逻辑计算的任务则留在主机端设备进行运算。需要并行计算的任务由显卡设备控制进行计算,等并行计算任务完成后,显卡设备会将计算结果送回主机端的存储中,并用于下一次计算输入。
1)线程层次模型
在GPU中所执行的线程具体结构如图3所示。它们一共有三种不同的类型,分别为一维、二维和三维。线程格(grid)常用于表示具有相同维度类型和存储大小的线程块组成。在相同的线程格内的线程具有高效的协作效率,数据通信十分方便快捷,它们拥有相同的指令地址,所以不仅可以并行地进行执行任务,而且还可以通过一些共享存储器来共享它们的数据,并同步其执行来协调存储器访问。CUDA框架中有一个非常经典的线程模型,指的是不需要进行通信的任务部分一般以线程块划分,而需要进行通信的任务,将它设计到同一个线程块,这样的话,任务之间通信会非常高效。所以一般设计并行计算任务时,会将一大块任务根据相关性分成可以独立并行计算的子任务,接着继续划分下去,变成一块块更小的子任务,它们之间可以进行通信来解决问题,这样就可以提高程序的并发度。

图3 CUDA线程层次结构示意图
2)存储器层次模型
CUDA设备中一般拥有多种类型独立的存储空间,其存储空间的基本结构如图4所示,它们的存储功能都不一样。在应用程序里,每个线程块都拥有一大块共享存储器,该存储器提供给块内的线程使用。除了这个共享的存储器,每个线程还拥有独立的存储器,除了自己可以控制读写,其他线程没有访问权限。由于共享存储器位于多处理器的内部,所以访问它的速度非常快,与寄存器差不多。在执行并行计算任务时,如何对数据有大量的读写需求,就可以使用共享存储器资源来完成。还有一种类型存储器,就是全局存储器,该类型的储存器不管什么线程都有权限使用它,对存储在该类型的存储器中的数据,可以之间访问与读写,十分方便。最后两种类型则是常量存储器与纹理存储器,它们只能提供线程只读的操作,并且只读的速率非常迅速。

图4 存储空间结构示意图
3.2 SIFT算法的可并行度分析
可并行度一般用于表示算法中可通过并行计算设计的任务占全部的计算任务的比例。在本文中,测量尺度使用时间来进行分析。假设,该算法全部串行执行一共所需要的时间记为c,而其中可以通过并行方式实现的部分执行时间记为b,如果同时使用m个处理器对它们进行加速优化处理,只在最理想的情况下考虑,那么并行加速后,该算法可以被最大化提高的倍速为T,具体计算公式如式(6):

这个最大的提高倍速是可以达到的上限。
根据上述对可并行度概念的描述可知,通过这样一个公式可以得出任何算法的实现是否还存在有提升的余地,并且可以预估出被提高的最大倍速。对于本节的算法下,SIFT算法的主要步骤有构造多尺度空间、检测并定位关键点、赋予关键点方向和关键点描述子的计算。
构建多尺度空间的主要过程是对输入图像进行灰度和下采样,然后计算每组的组内尺度和各层尺度,最后生成高斯尺度空间和微分尺度空间。上述步骤中,可以通过并行计算实现的部分包括高斯尺度空间的生成和微分尺度空间的生成。需要标准实现的部分包括图像灰度化、下采样、各层尺度和组内尺度的计算。
赋予关键点方向和关键点描述子的计算,都是可以通过并行计算实现加速的。最终分析的并行化结果如图5所示。

图5 SIFT算法的可并行度示意图
4 实验与结果
本文的应用场景,是面向智能书柜的书脊图像特征匹配,重点在于快速根据书柜上的书脊图像,与之前已经构建好的书脊图像库中每本书脊,进行匹配,快速匹配出每次减少的书本。在这种场景下,对于匹配的算法,既要求有很高的准确率,又有速度上面的要求。所以基于CUDA的SIFT算法,正好满足这些要求。
本文中所用的实验环境都一致,具体配置如表1所示。实验中,将本文的算法与标准的SIFT算法[19~20],在特征提取和特征匹配执行效率上做比较。

表1 计算机软硬件配置
在特征点提取的实验中,图6是使用CPU方法和GPU方法分别对四张不同分别率的书脊图像,实现的SIFT特征点提取效果图。图6(a)、(c)、(e)和(g)是在CPU环境下提取的特征点图,而图(b)、(d)、(f)和(h)则是在GPU环境提取的,发现GPU实现的算法提取的特征点比CPU实现稍微多一些,在CPU提取出来特征点,绝大部分GPU也提取出来了。

图6 GPU与CPU SIFT特征点提取效果图
如表2则展示是每张图CPU和GPU提取的特征数和公共特征数。由表中数据可知,在4张图特征提取的结果中,公共提取的特征点占CPU提取的总特征点约95%,也就是说GPU提取的特征点几乎包含了所用CPU提取的特征点。在使用相同算法参数下,GPU比CPU普遍提取更多的特征点。根据分析实验结果,大致有两种因素造成CPU和GPU这两种实现关于特征点定位精度之间的差异。

表2 GPU与CPU公共SIFT特征点数对比
1)为了让计算任务更加快速的进行,在具体GPU实现时,采用了大量的CUDA框架下加速库,使用这些库函数会带来精度上损失。
2)在构建高斯金字塔的过程中,高斯函数存在大量的加乘计算,并且这个加乘计算的误差会累积到下一层中,所以会导致精度上的差异。
虽然存在一些精度上损失,但在大量的特征点中比例还是很小的,对总体算法的可行性没有太大的影响。所以GPU实现的SIFT特征点提取具有和CPU实现的算法一样的可靠性和可行性。
在特征匹配实验中,实验数据共包含四张书籍图片,分辨率分别为51×617,1440×1080,94×592,1440×1080,图7(a),图7(c)为待匹配书脊图像,图7(b)、图7(d)为搜索图像。

图7 待匹配书籍图像
实验中,算法的参数设置如下:差分金字塔的层数由分辨率确定,每组层数为5,特征点主方向分配在高斯平滑参数σ为1.6。CPU环境下,特征匹配算法使用的是基于KD树的近似最近邻算法匹配。而GPU环境下,则使用的是直接暴力搜索高维向量进行匹配。
从上述表3实验对比和图8实验结果中,可以看出CPU和GPU环境下提取的特征点数量差不多,最终匹配的特征点,CPU环境下略多一些,这可能是由于GPU中浮点运算精度导致的。尽管GPU环境下,使用暴力匹配算法,但最终算法的运行时间是CPU环境下的几倍。

表3 本文算法与标准SIFT实验结果对比


图8 匹配结果
5 结语
本文使用在CUDA框架下实现的SIFT加速算法解决CPU下SIFT算法时间长问题。为了更好更快地实现CUDA框架下的SIFT算法,先分析了该算法的可并行度。在该算法的可靠性和效率性方面,本节对CPU和GPU两种环境下实现的SIFT算法,在特征提取与特征匹配实验结果进行分析与对比。根据实验结果,发现GPU环境下不仅具有可靠性,并且还有更高的效率,提高了该算法的实时性,使应用层面变得更加广泛。
对于智能书柜这个场景,实时性十分重要。所以此基于CUDA框架下实现的SIFT算法,具有适用性,为用户带来极速的用户体验。
猜你喜欢
计算机应用与软件(2022年9期)2022-10-10
现代电子技术(2022年12期)2022-06-14
现代电子技术(2022年8期)2022-04-13
电脑报(2021年38期)2021-10-08
阅读(高年级)(2020年8期)2020-11-06
小天使·二年级语数英综合(2019年4期)2019-10-06
新高考·高一物理(2016年11期)2017-07-07
电影故事(2015年16期)2015-07-14
环球时报(2009-12-04)2009-12-04
计算机教育(2006年4期)2006-04-19
