
基于改进随机森林算法的共享单车需求量预测*
2021-10-08 13:56聂文惠
计算机与数字工程 2021年9期
张 徐 聂文惠
(江苏大学计算机科学与通信工程学院 镇江 212013)
1 引言
随着城市化进程的快速推进,交通拥挤问题愈发严重[10]。共享单车作为城市公共交通的创新形式,有力缓解了人们出行困难的现象。然而各城市在逐步推进共享单车建设的同时,也伴随着一系列的问题,“租车难,还车难”成了共性问题[1]。因此预测城市共享单车需求量对于整个共享单车系统来说,具有重要的现实意义。
共享单车是一种极容易受环境影响的交通方式,在时间和空间分布上存在高动态性和高关联性[7~9]。准确高效地对共享单车需求量预测可以优化单车系统的布局,提高系统车辆调度能力。在高需求量的租赁区域,运营商可以投放较多的车辆,而一些偏远或使用较少的区域则可以减少运营维护。这样不仅可以节约运营成本,还可以提高服务质量和用户体验。
对于城市共享单车需求量预测,Kaltenbrunner A等[2]通过对巴塞罗那社区的共享单车数目和当地人口流动数据的分析,提出了ARIMA模型,对站点单车需求量和状态进行了预测。Singhvi D等[3]利用线性回归模型来预测来预测纽约市站点共享单车的需求量;Zhang Y等[4]利用中山市共享单车系统的用户历史数据,采用多元线性回归模型,研究了中山市各个景点对出行需求的影响及站点需求与供给的比例。
以往共享单车需求量预测的算法,绝大部分是通过历史借还数据建模来进行预测[6]。实际上,由于目前智能信息较为发达[12],共享单车系统能够提供更详细准确的单车租还数据,包括借还时间、借还地点、用户信息等。另外结合天气,温度,风速等数据,利用数据分析技术,挖掘影响出行的时空环境因素,可以准确地预测区域实时需求量。
鉴于城市共享单车租赁状况分布不平衡,在既有研究的基础上,本文针对RF(Random Forest)算法在处理存在大量冗余数据的数据集方面的缺陷[13],分析RF中各棵树的强度和相关度之间的关系,提出了FWRF(Feature Weighting Random Forest)算法。改进原有算法的特征选择,通过增加特征权重,划分特征区间,组成新的特征子集,从而避免重复选择冗余数据进行建树。实验结果表明,该改进算法能够提高泛化精度,增强模型的精确度。
2 相关研究
2.1 RF的数学定义
定义1边缘函数(Margin Function)
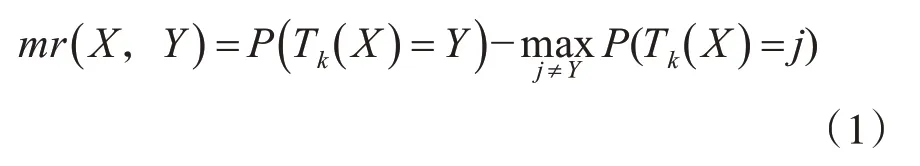
其中:P(Tk(X)=Y)为正确分类的概率;为错误的分类的概率的最大值;Y为正确的分类向量;j为不正确的分类向量。
显然,边缘函数越大,分类器的置信度就越高。
每一颗决策树在森林构建的过程中,存在一个初始数据集和一个未抽取的数据集[18],将未抽取的数据集定义为Ok(x)。Qk(x,yj)为随机向量x在Ok(x)中分类类别为yi的比例,则其中:
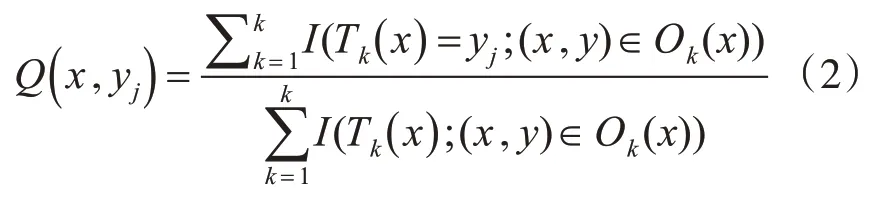
分子为在未抽取数据集Ok(x)中决策树对应正确分类个数之和;分母为所有未抽取数据集的个数之和;将Q(x,yj)作为RF正确分类的概率估计。
定义2分类强度是评价森林中分类器总体分类能力的量。其值是随机森林边缘函数的期望,即:

将式(2)代入到式(3),则分类器的强度估计为
对森林中的每棵树而言,分类强度越大,则RF分类性能越好。
定义3RF中树之间的平均相关度为边缘函数的方差与森林的标准差的平方。即:
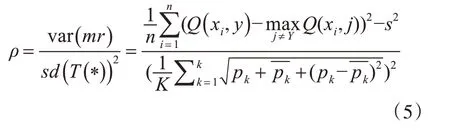
其中:


2.2 RF的性质
性质1RF的收敛性
所有森林中的决策树的泛化误差都收敛于:

其中,k为森林中树的数目。
泛化误差:

随着树的增加,泛化误差PE*将趋向一个上界[11],这表明RF算法对未知的实例有很好的扩展,不会随着决策树的增加而产生过度拟合的问题[5],但可能会产生一定限度内的泛化误差。
性质2泛化误差上界
泛化误差的影响因素:一是决策树之间的相关度ρ,二是强度s。
泛化误差的一个上界:

研究发现泛化误差界与分类强度s成负相关,相关度ρ成正相关[14],即分类强度s越大,相关度ρ越小,则泛化误差界越小,随机森林分类准确度越高。
为了降低RF的误差上界[15],本文从提高决策树的分类强度s,降低决策树之间的相关度ρ等方面进行理论分析和实验验证。
3 FWRF算法
3.1 特征评估
共享单车的需求量预测大都采用的是RF模型[8]。RF在建树过程中用到两次随机选择[12],第一次使用Bagging方法选择样本,第二次是随机选择特征进行建树。
RF算法建立决策树过程中,其中一个重要过程就是随机特征的选取。在进行节点特征选择时,并不是全体特征都参与选择[16],而是从全体特征中随机选择F个特征。随机特征选择保证了RF算法分类精度,这个过程增加了决策树构建时的随机性[11]。
但是如果数据中存在较多冗余特征时,可能会在一定程度上影响RF的泛化能力[17]。在随机选择一定数目的特征时,可能同时选中一些冗余特征,这样建立的“森林”强度将严重影响预测结果。
根据冗余特征这一问题,本文认为首先使用一种评估特征重要性的方法来衡量特征与总量的相关程度。本文中选用CCS(Correlation Coefficient Scores)作为对特征进行评估的方法。CCS统计指标是卡尔·皮尔逊设计来衡量两变量之间关联程度。其值是通过积差方法计算,以变量与各自平均值的离差为基础,通过两个离差相乘来反映两变量之间相关程度。CCS计算公式如下。

其中,r为属性与分类属性之间的关联度。
相较于离散数据可以直接通过CCS值大小发现两个属性之间的相关程度高低,连续数据则需要先对属性进行离散化,通过建立属性相关表,然后计算CCS值分析两属性间的相关度。
需要说明的是,当样本数量n较小时,CCS值波动较大,存在部分样本CCS值接近于1。当样本数量n较大时,CCS值容易偏小。因此在数据样本容量n较小时,仅凭CCS值判定属性之间的密切关系是不严谨的。
共享单车实时租赁产生的数据容量较大[10],故本文采用CCS对特征值进行评估,验证每一个特征对总量的影响程度,然后通过优化特征选择,提高RF模型的分类学习能力。
3.2 算法原理
综上分析,增加分类强度,需要提升森林中随机树的平均精度。在RF算法建立决策树的过程中,随机性特征选择一定程度上降低树之间的相关性,提高树之间的差异性,理论上让所有特征都有可能参与到森林的构造中[13]。但是共享单车系统由于数据集大,产生的冗余数据也会多,随机特征选择时更容易出现重复选中冗余特征的状况。
为了增加“森林”的强度,本文在利用CCS评估算法对特征重要性进行评估的基础上,首先分析特征与总量之间的关联度,计算出一个度量关联度的值。然后将关联值作为每个特征的权值,这些权值表示特征和总量的关联度强弱。最后对权值进行排序,让特征选择局限在排序后的特定的范围。这样建立的“森林”可以提高单分类树的精度。
从增加分类强度和减少树相关度两方面出发,根据权值排序,将特征空间划分为两部分,高相关区间和低相关区间。在选择特征时,分别从高相关区间选择ρ比例的特征和低相关区间选择(1-ρ)比例的特征,组成新的特征子集进行建树,最终完成森林的构建,如图1所示。
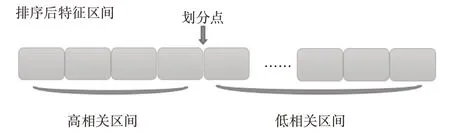
图1 特征空间选择示意图
Algroithm:FW Random Forest
Output:FW Random Forest
1)Calculate the correlation coefficient value of each feature and assign a weightWto each feature;
2)Use Baging's selection method to select a certain proportion of samplesD=;
3)Sort according to the weightW;
4)Dividing the feature interval into a high correlation interval[1,P]and a low correlation interval[P,N];
For(i=1 toT)
1)use a Bagging selection method to select a certain proportion of samples;
2)Select S features from[1,P],and select N-S features from[P,N],and combine them as new feature subsetsF'=;
3)Output the ensemble of trees
FWRF算法数学定义:
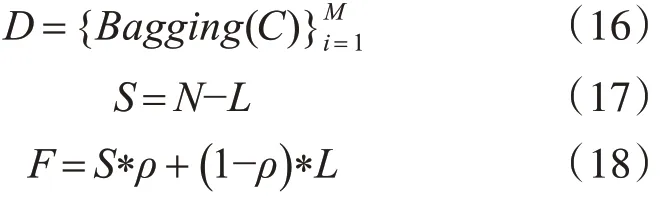
其中,N为特征个数;S为高相关区间选取特征的个数;L为低相关区间选取特征的个数;T为分类树的个数;F′为特征子集。
则FWRF算法输出为

RF算法的一个重要优点是可以很快完成对训练集的分类[11],采用CCS算法对特征加权,只需要在建立决策树之前计算一次,在时间复杂度上,影响非常小,且不会降低森林的速度。
4 实例分析
4.1 特征选择
本文选取的数据集来源于NewYork CityBike官网公开数据,实验的样本是2014.8.1~2014.8.15的租赁数据以及当地气象数据。
在对租赁区域的实时共享单车数据进行预处理时发现,工作日平日里的整个单车流量都是类似的,包括早上高峰时段,白天时段,晚上高峰时段和晚上时段,而周末时段也是相似,包括夜间小时,行程时间和晚上时段。如图2所示,工作日的整个使用量比休息日的使用量要大得多,而在高峰时间的使用量要比其他时间段的要大得多。所以我们确定两个时间特征:一天中的一小时和一周中的两天(工作日一天和休息日一天)。

图2 时间对租借数的影响
从图3中可以看出,温度与用户租借数之间有着正相关的关系。在骑行最适宜温度范围内,租借数会随着温度的上升而有所增加。当温度过低或过高时,用户租借数会有明显下降。

图3 温度风速对租借数的影响
风速在一定程度上影响共享单车的使用量。图3说明在不同风速下用户租借数的分布。可以看出,最适宜的骑行风速为4MPH~9MPH。随着风速超过10MPH,共享单车的租借数呈下降趋势。所以我们发现,风速与用户租借数之间有着负相关的关系。
天气在很大程度上影响着人们选择共享单车出行,甚至有着决定性作用。这里研究了晴天,阴天、小雨、雷雨四种情况下的用户租借数的变化规律。如图4所示,一般情况下,人们更喜欢晴天选择共享单车出行,但在阴天和小雨天也会有部分人选择共享单车出行。在雷雨等极端恶劣的天气下,几乎无人选择共享单车出行,由此可见,天气对共享单车租借数有着重大的影响。

图4 天气对租借数的影响
综上分析,一共选取了气象因素(温度、风速、天气情况)和时间因素(工作日、非工作日、小时)六个特征,结果分析如下。
4.2 结果分析
分别计算出六个特征的CCS值,然后对它们进行特征排序。
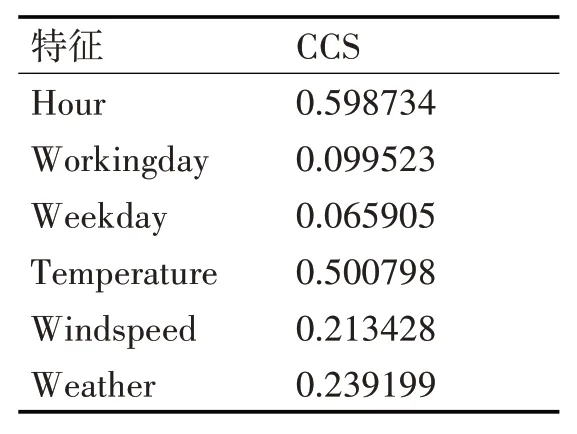
表1 特征的CCS值
根据计算结果,新特征空间为Hour,Temperature,Weather,Windspeed,Workingday,Weekday。本文设置P的值为4,则高相关区间为Hour,Temperature,Weather,Windspeed,低相关区间为Workingday,Weekday。
为了验证FWRF算法的有效性和通用性,本文随机选取了一个区域的某一工作日和某一休息日进行了预测,并且与其真实值进行了比较。预测结果如图5、6所示。

图5 共享单车需求量工作日预测结果
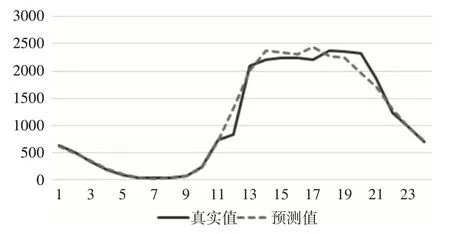
图6 共享单车需求量休息日预测结果
实线表示真实值曲线,虚线表示预测值曲线。如图可知,预测值曲线与真实值曲线具有较高的拟合度,能够较好地跟踪各个区域每天每个时段内的共享单车需求量。
为了进一步说明改进后的FWRF模型的优越性,本文将其与默认随机森林模型在相同条件下进行了实验。实验结果如表2。

表2 模型对比
可以看出,改进后的FWRF模型误差率明显好于RF模型,并且R2得分也高于RF模型。
5 结语
为解决城市共享单车租赁区域借还车不平衡现状,本文对租赁区域进行使用需求量预测。通过分析影响共享单车需求量的因素,挖掘租赁总数在气象因素和时间因素双重影响下的变化。利用RF算法在处理分类预测问题的优越性,提出一种改进的RF算法FWRF算法。首先通过分析RF算法中各决策树的分类强度和相关性之间的关系,提出一种降低分类误差的特征选择算法。该算法在建立决策树前,通过CCS值对特征加权,依据权值的大小进行特征区间划分,将特征选择局限于新的特征子集中,调整选择方式,从而提高泛化能力。实例分析表明,该模型和算法在模型误差率方面有较大改进,提高了预测使用需求量的精度。
猜你喜欢
数学大王·中高年级(2021年6期)2021-09-27
科学与信息化(2019年28期)2019-10-21
科学与财富(2016年32期)2017-03-04
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
建筑工程技术与设计(2015年21期)2015-10-21
决策与信息·下旬刊(2013年1期)2013-03-11
