
一种代价敏感的旋转森林分类算法*
2021-10-08 13:55周尔昊
计算机与数字工程 2021年9期
周尔昊 高 尚
(江苏科技大学 镇江 212001)
1 引言
近年来,分类器集成思想成为机器学习领域研究的一大热点。其中的Bagging[1]和AdaBoost[2]算法是该领域具有代表性的集成策略。文献[3]指出提高集成分类器的分类效果的方法基本从两方面展开:一是提高基分类器之间的差异性,二是提高各个基分类器的分类精度。如文献[4]中的ROFCO算法通过向训练集中加入差异性数据来减少基分类之间的相关性;再如文献[5]中以多层感知机作为Bagging的基分类器,提高了基分类器分类精度,以得到更好的分类结果。目前,以各种决策树(ID3、C4.5、CART)等作为基分类器的集成算法因其在分类问题上的良好表现,越来越受到集成研究者的重视。Rodriguez[6]等于2006年提出的一种新的集成算法——旋转森林(ROF)算法,该算法以决策树作为基分类器,通过特征变换增大基分类器之间的差异性,以获得更好的集成效果。
随着研究的深入,集成学习越来越多的被应用于解决不平衡问题。不平衡数据分类问题是机器学习领域一大难题,日常生活中会在很多行业面临此问题,比较常见的如电通行业中的欠费预测、医疗行业中的病情诊断等[7]。然而,目前大多数机器学习分类算法并不能很好解决不平衡数据分类问题。代价敏感集成学习是一种不平衡数据分类方法,主要有三种实现方式,分别是:1)从学习模型出发,针对算法本身的改进;2)从贝叶斯风险理论出发;3)从预处理角度出发,将代价用于权重的调整,如AdaCost算法。
本文提出了一种代价敏感的旋转森林算法(CROF),首先通过旋转森林算法实现数据的预处理,然后以CART分类树作为基分类器,在训练基分类器过程中引入误分类代价,改变CART分类树属性分裂原则,得到代价敏感的CART分类树,最后采用置信度这一指标来确定样本的最终类别。该方法不仅通过旋转森林算法减少了基分类器之间的相关性,还通过引入误分类代价提升了基分类器对于不平衡数据的分类能力。通过实验对比分析,该方法能够有效处理不平衡数据分类问题。
2 相关技术
2.1 代价敏感学习
代价敏感学习(CSL)最初来源于医疗诊断问题[8]。在医疗诊断过程中,将一位患者诊断为健康所付出的代价远大于将一位健康的人诊断为患者。在机器学习中,CSL指为不同类别赋予不同的权重,在训练过程中使机器更加“重视”那些拥有更高权重的类别,从而获得理想的模型。这一思想更多地被运用来解决不平衡数据分类问题,因为类别的分布不平衡,分类算法往往过度训练多数类而牺牲了少数类的分类精度。由于CSL是以最小化分类代价为目标的[9],所以通过赋予少数类更高的分类错误代价,使机器在分类过程中大大提高了模型对于少数类的分类精度,从而有效解决了不平衡数据的分类问题。可以用代价矩阵表示分类器错分时付出的代价[10],设CL为少数类,CM为多数类。代价矩阵如表1所示。

表1 代价矩阵
其中,C(i,j)表示将j错分为i的代价。
代价矩阵确定后,用贝叶斯构建风险函数,类别x被划分为类别i的最小期望代价:

其中:p(j|x)表示把样本x划分为j类的后验概率。
2.2 旋转森林
旋转森林(Rotation Forest)[11~14]于2006年 提出。该算法的核心是特征变换思想。先将属性划分为大小相等的K个不重叠子集,然后通过PCA、旋转矩阵等变换方法获得新的样本数据。由此得到的各子样本数据相互有所区别,从而提高了各基分类器的差异性和准确性。
现设定F表示属性集,D1,D2,…DL表示L个基分类器,用N×n的矩阵X表示有N条数据记录的训练样本集,n表示样本特征数。模型构建步骤如下。
1)将F随机划分为大小相等的K个子集,则每个子集约有M=n/K个属性。
2)用Fij表示训练第i个分类器Di所使用的训练集的第j个子属性集,对训练集进行75%重采样,产生一个样本子集X’ij,通过主成分分析(PCA)对Fij中的子属性进行特征变换,得到Mj个主成分:,。
3)重复步骤2),得到K个子属性集,将其主成分系数存入系数矩阵Ri:
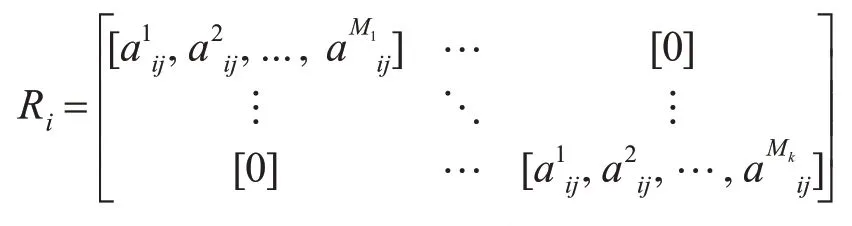
根据原始属性集排列顺序重新旋转矩阵Ri得,然后通过XRi’操作得到分类器Ci的训练集,在此训练集上训练基分类器Di,重复以上步骤L次得到L个基分类器。这里基分类器采用决策树类型算法,因为其对特征的旋转较敏感,得到的各个分类器有更大的差异性。
4)最终分类结果以最大置信度来决定,对于一个样本x,用di,j(xR'C)表示用分类器Di预测x属于c类可能性,label表示所有可能的类别,则x属于c类的置信度为

由此可以通过式(3)判定x的最终类别:

3 代价敏感旋转森林算法
传统随机森林算法在特征子空间构造决策树,降低了数据维度,本身适合处理高维数据,若向其中引入代价因子,可以同时处理高维不平衡数据[15]。但其在有噪音或树数量设定不当的情况下存在过拟合问题。相比于传统随机森林算法,旋转森林算法通过特征变换得到的各基分类器的差异性和准确性都变大,在降低数据维度的同时也可以较好地避开过拟合问题,在此基础上向基分类器引入代价因子得到代价敏感旋转森林,相比于传统的代价敏感方法以及现有的与随机森林相结合的代价敏感方法,代价敏感旋转森林算法可以更好地处理高维不平衡数据。
3.1 代价构造
本文采用的代价敏感学习方法从学习模型出发,主要对决策树算法进行改进,从分裂标准的选择方面引入代价矩阵,使之能在不平衡数据集上有良好表现。
代价敏感旋转森林算法的基分类器采用CART决策树算法。在旋转森林算法得到的新的训练样本上构造不剪枝的CART分类树。CART决策树的每个节点可选的分裂属性为一固定数量M,且M≤F,F为样本所有的特征数目,每次分裂从F中有放回的取M个属性计算最佳分裂属性。CART分类树采用Gini指数来选择划分属性及划分点。Gini指数是一种不等性度量,又叫做“不纯度”指标,表示一个随机选中的样本在子集中被分错的可能性。也就是说,当一个节点中所有样本都是一个类时,指数不纯度为零;而当节点类别分布均与时,指数应该很大。Gini指数的定义如下:
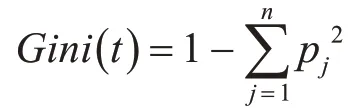
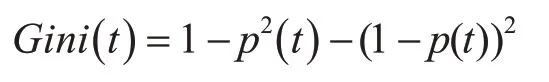
其中p(t)表示节点t处少数类个体比例,1-p(t)表示多数类个体比例。
在CATR分类树属性分裂过程中,算法选择下一个分裂节点的原则是使不纯度下降最快的属性,即使Gini指数变化量最大的属性,其计算公式如下:

其中:q代表左边节点的实例比例,1-q代表右边节点的实例比例。现在向Gini指数计算中引入误分类代价因子:
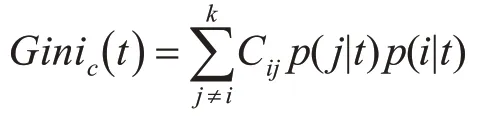
其中:Cij代表误分类代价,为一固定数值,根据研究样本实际分布决定。中分子,Π(j)为类别j的先验值。分母。此时,不纯度下降落差更新为

同样地,选择能使不纯度变化量最大的节点作为最佳分裂属性。
通过以上操作,成功的将惩罚代价Cij引入到了CART算法中,经过修改的CART算法在每一次选择新的属性进行分裂时都考虑到了实际样本的不平衡性,由此得到的CART分类树能够更好地处理不平衡数据集。
3.2 算法步骤
1)根据实际样本多数类与少数类比例计算误法类代价C(CL,CM),C(CM,CL);
2)运用旋转森林算法处理原始训练样本集,得到D1,D2,…,DL个用于训练基分类器的新的数据集;
3)在D1上建立不剪枝的CART决策树,引入误分类代价,修改CART决策树的属性分裂计算方法;
4)重复步骤3),直到得到L个构造完成的基分类器;
5)以最大置信度为标准输出样本的最终类别。
4 实验及分析
4.1 实验数据集、评价标准与参数设置
为验证算法有效性,从UCI中选择了五组数据集,由于CROF算法着重解决二分类的不平衡数据问题,故通过调整类别数使这五组数据呈现出二分类上的不平衡性。修改过后的数据集如表2所示。
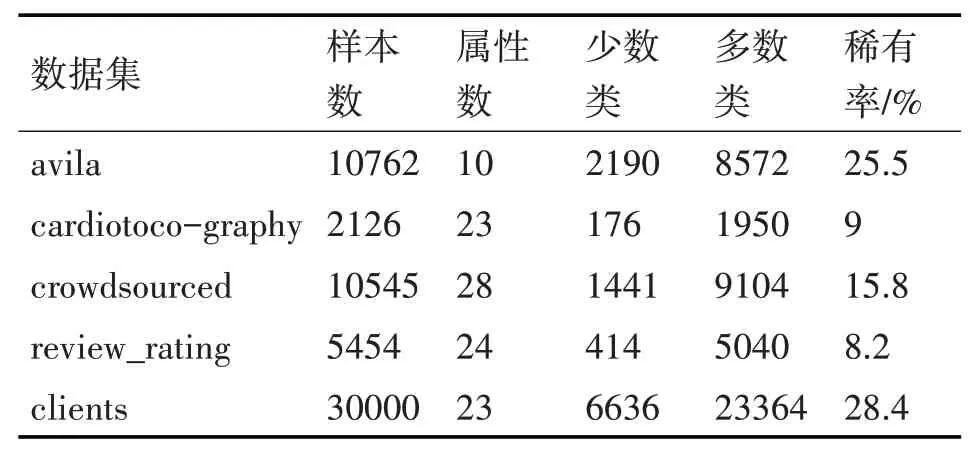
表2 修改后的数据集
通常通过混合矩阵来衡量分类算法的性能,如表3所示。

表3 二分类混淆矩阵
本次实验中,选取AUC值、真正例率(TPR)、f-度量(f-measure)来衡量算法性能。AUC值是一个比精度好得多的指标,它可以反映多数类及少数类的平均分类情况,对于不平衡类别的分类问题,使用AUC进行模型评估通常比使用精度更有意义。TPR度量的是少数类样本中有多少被预测为少数类;f-measure是准确率(PPV)和真正例率(TPR)的调和平均,由于同时考虑了准确率和真正例率,所以它对于不平衡的二分类数据集来说是一种较好的度量。
对于误分类代价Cij设置则根据所选取数据集实际情况而定,如clients数据集中,多数类与少数类比例为3.5,设CL为少数类,CM为多数类,若C(CL,CM)设为1,则C(CM,CL)应设为3.5,以此体现若误分少数类将带来更大的惩罚。
4.2 实验结果与分析
将CROF算法分别于CART决策树算法、RF(随机森林算法)、ROF(旋转森林算法)进行比较。四种算法的AUC值如图1所示。

图1 CATR,RF,ROF,CROF的AUC值比较
从图1中可以看出,以集成为基础的RF算法相较于普通的CART决策树算法可以一定程度上缓解过拟合问题,但其对于少数类的分类不敏感,AUC值表现一般。ROF算法通过特征变换,在避开过拟合的同时其分类器的准确性有所提升,对比RF算法AUC值有了提升。而CROF算法在此之上通过引入代价因子,能够处理高维不平衡数据,其AUC值比之ROF算法又有了进一步提升。这说明CROF算法对多数类及少数类的分类均有良好表现。
由于算法着重于解决不平衡数据的分类问题,所以对于少数类的分类精度有着更高的要求。表4、表5分别是四种算法在各数据集上的TPR和f-measure的平均值,图2、图3则是对表格数据的直观反映。
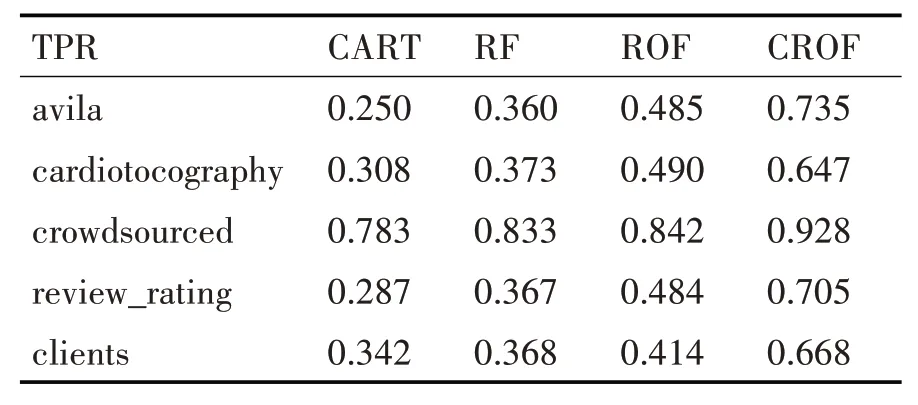
表4 四种算法下各数据集的TPR值

表5 四种算法下各数据集的f-measure值

图2 各数据集下四种算法TPR比较
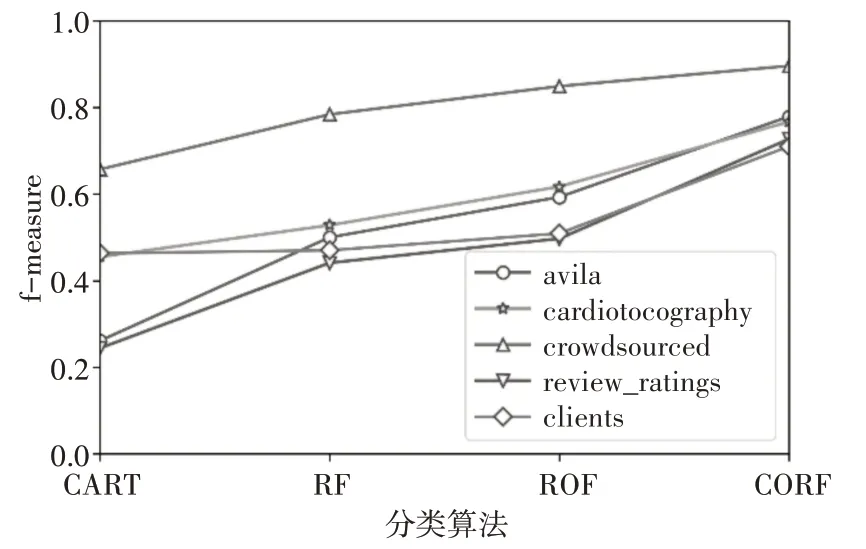
图3 四种算法下各数据集f-measure比较
从图表中可以看出,CROF算法对于数据集中少数类的分类精度优于其他三种算法,在AUC值较其他方法略有提升的基础上,CROF算法对于少数类的分类准确率有较大提升。以上实验说明CROF算法可以更好地处理不平衡数据。
5 结语
传统算法处理不平衡问题时往往基于类别平衡的假设,当应用于不平衡数据时性能并不理想[16]。CROF算法利用集成思想,通过ROF模型实现了数据的预处理,向CART算法中引入误分类代价,改变了CART属性分裂计算规则,使得分类器不仅多样性与准确性均得到改进,而且能有效处理不平衡数据问题,进而提高集成后的分类器分类性能。提出的CROF算法与传统算法相比有更好的AUC、TPR及f-measure值。说明该算法在不平衡问题上是有效的。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
科学与信息化(2019年28期)2019-10-21
语文世界(初中版)(2018年10期)2018-11-06
语文世界(初中版)(2017年5期)2017-06-22
软件导刊(2017年4期)2017-06-20
作文与考试·初中版(2017年12期)2017-04-19
科学与财富(2016年32期)2017-03-04
决策与信息·下旬刊(2013年1期)2013-03-11
