
共享核空洞卷积与注意力引导FPN文本检测
2021-10-04 11:46:36孟月波刘光辉徐胜军韩九强石德旺
光学精密工程 2021年8期
孟月波,金 丹,刘光辉,徐胜军,韩九强,石德旺
(西安建筑科技大学 信息与控制工程学院,陕西 西安 710055)
1 引 言
图像中的文本信息可以传达丰富而准确的高层语义信息,具有高度的概括性和抽象的描述能力,是理解图像场景内容的重要线索。自然场景文本检测技术使用边界框精确捕捉与定位场景中的文本实例,在智能交通、基于内容的图像/视频检索以及可穿戴/便携式视觉系统等诸多领域具有重要的应用[1-2]。
深度神经网络因其具有较强的深层次特征提取能力以及非线性拟合能力,相较于传统文本检测方法,能够较好地解决复杂自然场景下的文本图像到文本位置和文本内容的映射问题[3],并且已取得了诸多的研究成果。按照文本目标的排列方向不同,这些方法可以分为水平方向文本检测方法[4]、倾斜方向文本检测方法[5-11]、弯曲文本乃至任意方向文本检测方法[12-16]。文献[4]针对水平方向文本首次利用垂直锚点回归机制得到固定宽度的竖直矩形文本区,通过卷积神经网络和循环神经网络联合预测文本的位置和类别,最终定位水平文本行;但垂直锚点结构的设计,使得该方法无法检测倾斜文本。文献[5]利用局部信息连接文本行切片,实现倾斜文本检测;但信息的切片与连接过程会引入一定的误差,影响检测精度。为降低中间步骤对性能的影响,文献[8]直接 通 过 全 卷 积 网 络[17](Fully Convolutional Net‐works,FCN)产生文本框的预测,实现了端到端的训练和优化;但受感受野限制,对较长文本框检测效果欠佳。文献[9]提出了将长文本检测问题转换为检测文本头部和尾部边界问题的新思路,但当该模型应用于各种形状及大小共存的自然场景文本检测任务时,鲁棒性较差。至此,实现弯曲乃至任意形状大小的文本检测成为难点问题。文献[13]通过对输出层采用不规则卷积核来适应文本长度变化,克服了较大长宽比对文本检测任务的影响;但该模型在比例变化剧烈的情况下效果仍不理想。文献[15]结合回归思想,通过提出新的文本边缘点回归方式,克服了对文本目标长宽比大小的限制,实现多边形文本重构;但由于回归方式的约束,该方法对于弯曲程度较大的文本检测效果不佳。文献[16]首次提出了一种基于实例分割的掩模文本检测方法,通过掩膜分支完成文本实例的分割任务,打破了形状与大小的限制,且有效避免了同一图片中多目标的类间竞争问题,实现了任意形状文本区域的检测,检测精度提升显著。
随着科技水平的不断进步,高分辨率图像越来越普及,逐渐成为文本检测的主要对象。该类图像特征尺度差异较大,想要获取其多尺度信息,需要有更丰富的感受野,否则在提取文本目标特征时,会造成细粒度特征难以捕获、多尺度特征不佳问题。同时,复杂场景中的文本实例具有极端长宽比特点,现有候选框筛选方式难以实现伪目标的精细过滤,导致检测结果存在掩膜过度重叠问题,影响检测性能。
针对上述问题,本文借鉴文献[16]的掩膜文本检测思想,提出一种共享核空洞卷积与注意力机制引导FPN(Kernel-sharing Dilated Convolutions and Attention-guided FPN,KDA-FPN)的文本检测方法。特征提取部分通过具有共享核的空洞卷积,扩大感受野,深挖感受野细粒度特征,获取多尺度特征;同时,减少参数量,提升计算效率。并引入上下文注意模块与内容注意模块,加强对特征间语义关系与空间位置信息的关注,得到更全面的特征表达,提升特征融合质量。文本后处理部分,提出最小交集的候选框筛选策略(Intersec‐tion Over Minimum,IOM),将候选框中面积最大的框与相邻文本框之间区域的交集面积占较小框面积的比值作为候选框筛选评价指标,抑制采用交并比(Intersection Over Union,IOU)[28]策略衡量两个集合的重叠度时,因文本区域长宽比和大小的剧烈变化导致掩膜重叠的问题,实现候选框精细筛选,从而提高检测 精度。ICDAR2013[21],ICDAR2015[22]以及Total-Text[23]数据集的实验结果表明,本文方法显著提高了文本检测性能。
2 共享核空洞卷积与注意力引导FPN文本检测模型
2.1 网络结构
本文方法整体结构如图1所示,具体包括4个部分:特征提取网络、候选框生成网络(Region Proposal Network,RPN)[20]、分类与回归网络、Mask分支。特征提取网络以Resnet50为主干网络采用自底向上的前向传播方式,得到多尺度特征图{F2、F3、F4、F5},通过共享核空洞卷积与注意力引导的特征金字塔网络KDA-FPN,提升特征的辨识能力。候选框生成网络通过anchor锚框机制[20]生成大量文本候选区域,本文anchor的大小设置为{32×32,64×64,128×128,256×256,512×512},长宽比为{0.5,1,2},候选区域经ROI Align[24]实现输出与输入像素的一一对应。候选框生成网络RPN可看作文本区域粗检测过程,经ROI Align后的本文候选框区域为文本类别,非候选框区域为背景类别。分类与回归网络采用Fast RCNN模型[25],分类分支通过全连接层输出置信度大小,将候选框生成网络RPN得到的文本区域进一步细分为文本区域与背景区域两类;回归分支将全连接层作为边界框回归器,通过真值与预测值的偏差权重,取得分类分支得到的本文区域的坐标位置信息。Mask分支用于像素级别的文本实例输出,通过非极大值抑制NMS[18]以及提出的IOM最小边界框生成策略精细过滤候选框,生成与目标文本区域大小、形状一致的Mask掩模。

图1 整体结构Fig.1 Overall structure
2.2 基于核共享空洞卷积与注意力引导的特征提取网络
特征金字塔网络FPN在文本检测任务中特征提取效果显著,但对高分辨率图像而言,其粗细粒度特征的尺度差异悬殊,使得模型捕获特征能力受到限制,造成部分细节信息缺失;同时,多尺度感受野间信息缺乏沟通,导致特征图质量欠佳。本文提出一种共享核空洞卷积与注意力引导的特征金字塔网络KDA-FPN,具体结构如图2所示,该网络通过共享核空洞卷积,在减少参数量的同时改善多层次特征捕获能力,引入自注意力机制获得更强的语义和更准的定位信息,增强特征图辨识能力。

图2 共享卷积核空洞卷积与注意力引导的特征金字塔KDA-FPN网络结构图Fig.2 Shared convolution kernel dilated convolution and attention-guided FPN structure diagram
2.2.1 共享核空洞卷积模块
共享核空洞卷积模块(Kernel-sharing Dilat‐ed Convolution Module,KDM)结构如图2所示,通过共享3×3卷积核的空洞卷积扩大输入特征F5的感受野,挖掘深层次细粒度特征,利用共享机制加强各感受野间的联系,减少参数量,降低模型复杂度;同时,对F5进行上采样得到全局粗粒度信息描述特征,并将其与获取的细粒度特征进行融合,得到模块KDM的输出特征F。图2中,⊕表示特征融合操作。
2.2.2 注意力引导模块
特征F虽包含丰富的感受野信息,但由于冗余信息的存在,会降低检测精度。本文通过引入注意力引导模块(Attention-guide Module,AM),获得语义与定位信息之间的依赖关系,精确定位,提升特征质量,进而提高检测精度。AM模块如图2所示,由两部分组成:上下文注意模块(Context Attention Module,CxAM)以及内容注意模块(Content Attention Module,CnAM)。其中,CxAM模块强化相关区域间特征的语义关系,使输出特征语义表达更加清晰;CnAM模块加强对空间位置信息的关注,弱化共享核空洞卷积对特征几何特性的影响,精确目标位置。最后,将CxAM、CnAM与KDM模块的输出特征融合,得到更全面的特征表达F'。
2.2.2 .1上下文注意模块CxAM
如图3所示,通道数为C、高度为H、宽度为W的输入特征图F经式(1)~式(3),获得通道数为C'的隐层子区域特征Q、K以及图像增强特征
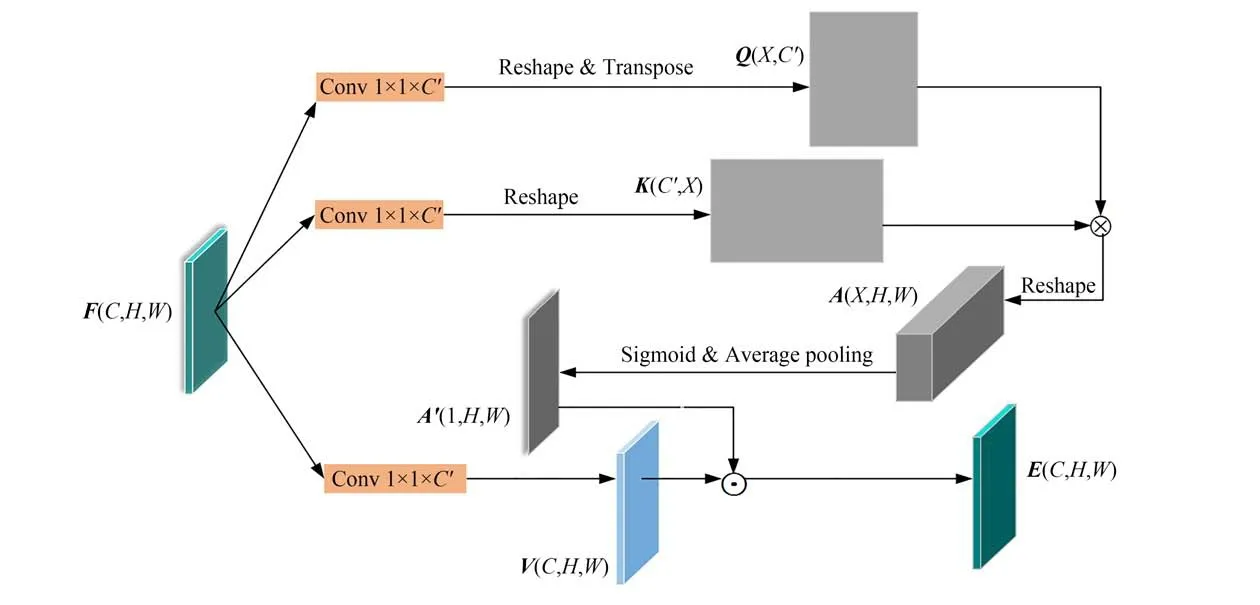
图3 上下文注意模块Fig.3 Context attention module
V,{Q,K}∈RC'×H×W,V∈RC×H×W:
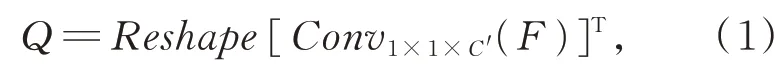
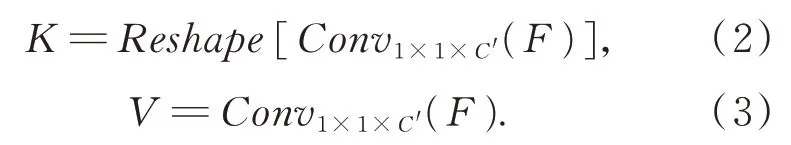
采用公式(4)计算Q和K的关系矩阵A,A∈RX×H×W,X=H×W。通过sigmoid激活函数和平均池化操作,得子区域特征相关性注意力矩阵A',A'∈R1×H×W。
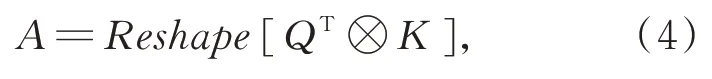
式中,⊗表示张量相乘。
最后,采用公式(5)获取区域间特征语义关系的注意力表征E,E∈RC×H×W:

式中,⊙表示按元素相乘。
2.2.2 .2内容注意模块CnAM
Resnet50网络中通道数为C''、高度为H、宽度为W的F5特征图包含丰富空间位置信息。如图4所示,将F5特征图作为输入,经公式(6)和(7),获得通道数为C'的隐层子区域特征P,Z;通过公式(8)生成其关系矩阵S;之后,经sigmoid激活函数和平均池化操作,得子区域特征相关性注意 力 矩 阵S'。{P,Z}∈RC'×H×W,S∈RX×H×W,X=H×W,S'∈R1×H×W。

图4 内容注意模块Fig.4 Content attention module

式中,⊗表示张量相乘。
最后,将S'结合式(3)生成图像增强特征V,通过式(9)获取区域间特征空间位置信息的注意力表征D,D∈RC×H×W:

式中,⊙表示按元素相乘。
2.3 IOM后处理算法
检测任务通常采用非极大值抑制算法(Non-Maximum Suppression,NMS)[18],通过计算边界框之间交集与并集的比值IOU过滤多余候选框,寻找最佳检测位置。然而,文本数据具有长宽比变化剧烈特点,候选区域经IOU筛选后,预测的结果仍会出现掩膜重叠现象,影响检测效果。
本文提出一种IOM(Intersection Over Mini‐mum)的后处理筛选策略,实现候选框的精确过滤,具体步骤如下:
(1)同一文本区域预测得到N个候选框,分别计算候选框面积,并按照面积大小将其排序,记作Si(i=1,2…,N),S1>S2>…>SN。
(2)将当前面积最大候选框S1分别与其他候选框按照公式(10)计算评价阈值Tj,j=1,2…,N-1,将依据该阈值进行候选框筛选。
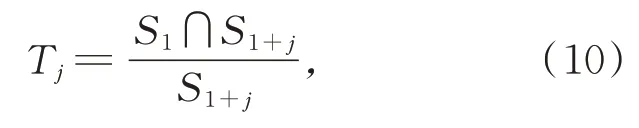
其中,分子部分描述两个对比候选框的交叠面积,评价阈值Tj反映对比候选框的交叠程度:
i.若Tj>0.5,说明候选框交叠程度占比较大,将S1+j移出候选框集合。为防止有效信息丢失,移除S1+j前需保留两部分的最小外接矩形;
ii.若Tj<0.5,说明候选框交叠程度占比较小,分别保留两个对比候选框S1与S1+j。
(3)计算当前候选框个数,假设个数为N',令N=N',重复步骤(1)操作,直到Tj均小于0.5,得到筛选结果。
2.4 损失函数
本文采用如式(11)所示多任务损失函数,具体包括RPN网络损失Lrpn,Fast Rcnn模块损失Lrcnn和掩码损失Lmask三部分。
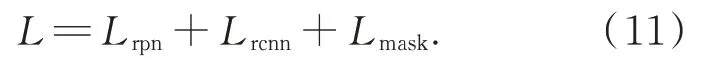
Lrpn和Lrcnn采用Faster RCNN中的损失定义形式[20],掩码损失Lmask采用交叉熵损失形式,计算如式(12)所示:

式中,M表示所有像素数目,xm和ym表示第m个像素的坐标位置(m=1,2,…,M),S表示sigmoid函数。
3 实验及分析
3.1 实验环境和数据集
本文及所对比算法均在Ubuntu系统下进行,GPU型号为TitanV,环境配置为CUDA9.0+ana‐conda3+python3+tensorflow1.11.0。采用自然场景文本数据集ICDAR2013[21],ICDAR2015[22]和Total-Text[23]进行实验,验证本文方法的有效性。
3.2 评价指标
准确度、召回率和F度量值是文本检测任务常采用的评价指标,具体计算如式(13)、(14)和(15)所示。准确度表示预测为正的样本中预测正确的数目,常用P表示;召回率表示正样本被预测正确的数目,常用R表示;F度量值是基于准确度和召回率的调和平均值,常用F表示。


其中,TP表示正样本被判断为正确样本的数目,FN表示正样本被判断为错误样本的数目,FP表示负样本被判断为正确样本的数目。
3.3 网络训练
主 干 网 络ResNet50选 择ImageNet[29]预 训 练结果作为初始化参数,其余模块的初始化参数采用随机生成方式。采用随机梯度下降算法SGD对网络参数进行训练,动量、权重衰减系数以及初始学习率分别设置为0.9,5×10-4,0.001。网络训练过程中,Batch Size均设置为8,IC‐DAR2013数据集设置迭代次数为5 000次,IC‐DAR2015数据集设置迭代次数为50 000次,To‐tal-text数据集设置迭代次数为60 000次。以IC‐DAR2015数据集为例对网络训练过程进行分析,其损失下降曲线如图5所示。可以看出,网络训练初期损失下降较快,迭代到26 000次左右时损失曲线下降趋于平稳,最终收敛在0.2左右,说明本文网络参数的训练结果较为理想。
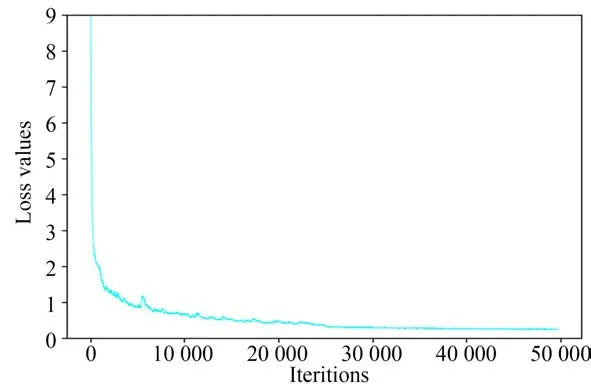
图5 损失下降曲线Fig.5 Loss decline curve
3.4 KDA-FPN各模块特征提取实验
本文KDA-FPN网络的特征提取过程如图6所示,首先利用Resnet50主干网络获取多尺度特征图{F2、F3、F4、F5};然后采用共享核空洞卷积KDM模块改善多层次特征的捕获能力;之后通过AM模块中的上下文注意模块CxAM、内容注意模块CnAM分别强化特征的语义关系和空间位置信息,提高特征表达能力;最后采用特征金字塔网络FPN将特征图{F2、F3、F4、F5}与其相邻特征图通过上采样和1×1卷积进行横向链接合并,得到描述不同语义信息的特征映射{P2、P3、P4、P5}。
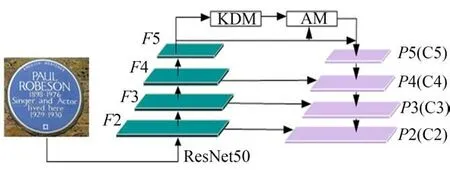
图6 KDA-FPN特征提取过程Fig.6 KDA-FPN feature extraction network process
本文以图1展示的文本图像为例,对上述各模块文本特征提取过程进行实验说明。待检测图像经Resnet50主干网络提取到的多尺度特征{F2、F3、F4、F5}如图7所示,KDM、AM中的CxAM和CnAM模块特征提取与融合结果如图8所示。

图7 Resnet50主干网络多尺度特征提取结果Fig.7 Resnet50 network multi-scale feature extraction re‐sults
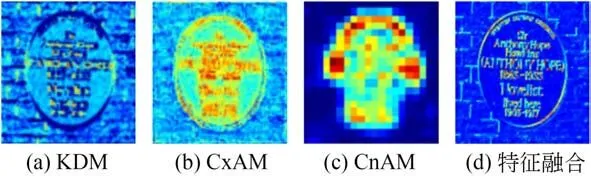
图8 KDM,CxAM和CnAM模块特征提取与融合结果Fig.8 KDM,CxAM and CnAM module feature extrac‐tion and fusion results
由实验结果可以看出,KDM模块提取的特征图细节表达更丰富;CxAM模块提取到的特征图更为关注语义信息;CnAM模块提取到的特征图对空间位置关系更敏感;将三个模块输出的特征进行融合,为后续文本检测提供了强辨识能力特征图。
为进一步说明KDM与AM模块作用,此处对两个模块引入前后特征金字塔网络FPN特征提取结果进行对比分析。如图6所示,不引入KDM模块、AM模块时,将特征金字塔网络FPN得到的特征映射记作{C2、C3、C4、C5},具体实验结果如图9(a)所示;引入KDM模块、AM模块时,将特征金字塔网络FPN得到的特征映射记作{P2、P3、P4、P5},实验结果如图9(b)所示。由实验结果可以看出,相较于{C2、C3、C4、C5},{P2、P3、P4、P5}特征表征能力更强,文本信息捕获更全面。
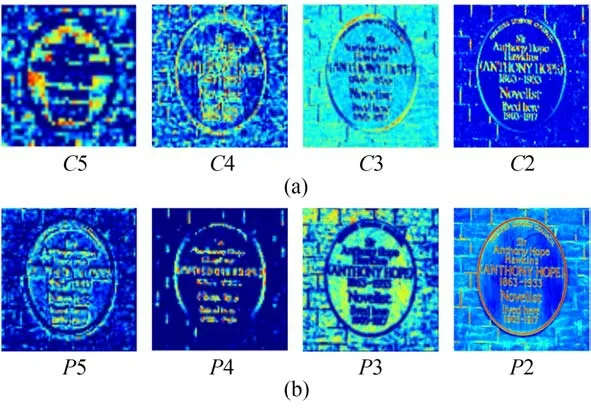
图9 特征金字塔网络FPN特征提取实验结果Fig.9 Feature pyramid network FPN feature extraction experimental results
3.5 IOM后处理策略实现过程
IOM后处理策略是一个迭代过程,这里仍以图1展示的文本图像为例,通过其某一文本区域的一次迭代过程对IOM策略的实现进行说明。
待检测图像的当前次迭代输入如图10(a)所示,红框位置文本区域包含6个交叠候选框,按照面积大小将其排序,记为S1,S2,S3,S4,S5,S6,如图10(b)所示。将S1与S2按照 公 式10进 行计 算 交叠阈值T1,可以看出T1>0.5,因此将S2移除并保留S1与S2的最小外接矩形S'1,该过程如图10(c)、图10(d)所示。继续重复上述操作,最终得到该区域候选框筛选结果,如图10(e)所示。
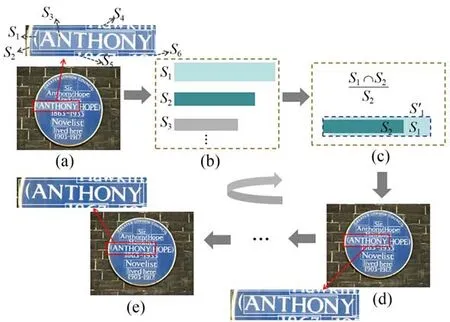
图10 IOM后处理过程Fig.10 IOM post-processing process
3.6 ICDAR2013数据集实验及分析
该数据集是在2013年ICDAR阅读挑战赛中提出的,包含229张训练样本和233张测试样本,样本为外景街拍的水平文本图像,一幅图像中存在多种尺寸和多种字体的文本区域。实验结果如图11所示,多算法性能结果对比如表1所示。

图11 ICDAR2013数据集结果对比图Fig.11 Comparison of ICDAR2013 data set result
由图11中箭头指向处可见,本文算法明显改善了水平文本检测任务中的掩膜重叠问题,且改进后的定位结果更加准确。
由表1可知,本文算法的准确度P较对比算法文献[16]提升了1.2,召回率R提升了2.3,F度量值提升了1.8。表明本文算法对复杂自然场景中的水平方向文本检测效果较好,优于近几年先进的文本检测算法。
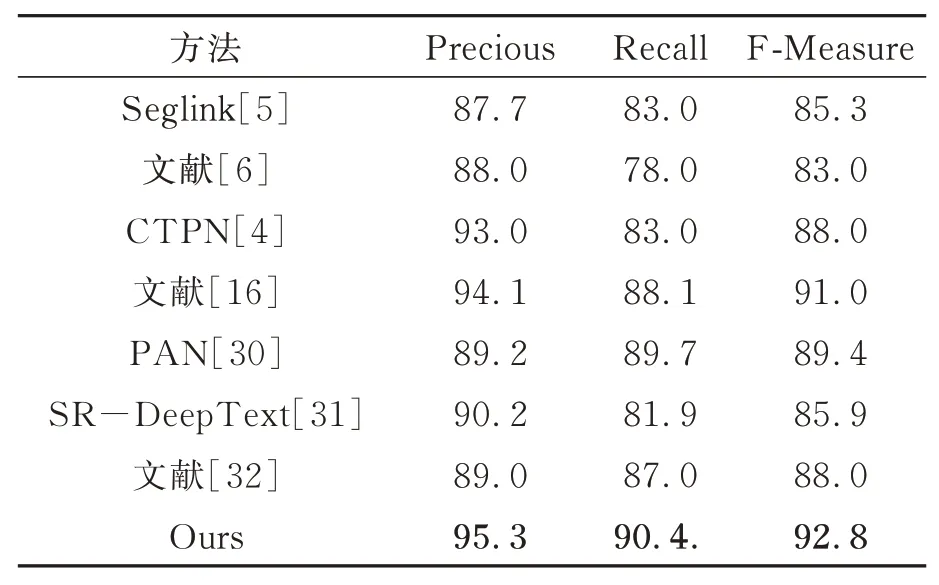
表1 ICDAR2013数据集算法性能对比Tab.1 Algorithm performance comparison of the IC‐DAR2013 dataset
3.7 ICDAR2015数据集实验及分析
该数据集是2015年ICDAR阅读挑战赛中提出的,包含1 000个训练样本和500个测试样本,样本为商场里随拍的倾斜文本图像,一幅图像中存在大小差异较大的文本区域。实验结果如图 12所示,多算法性能结果对比如表2所示。

图12 ICDAR2015数据集结果对比图Fig.12 Comparison of ICDAR2015 data set results
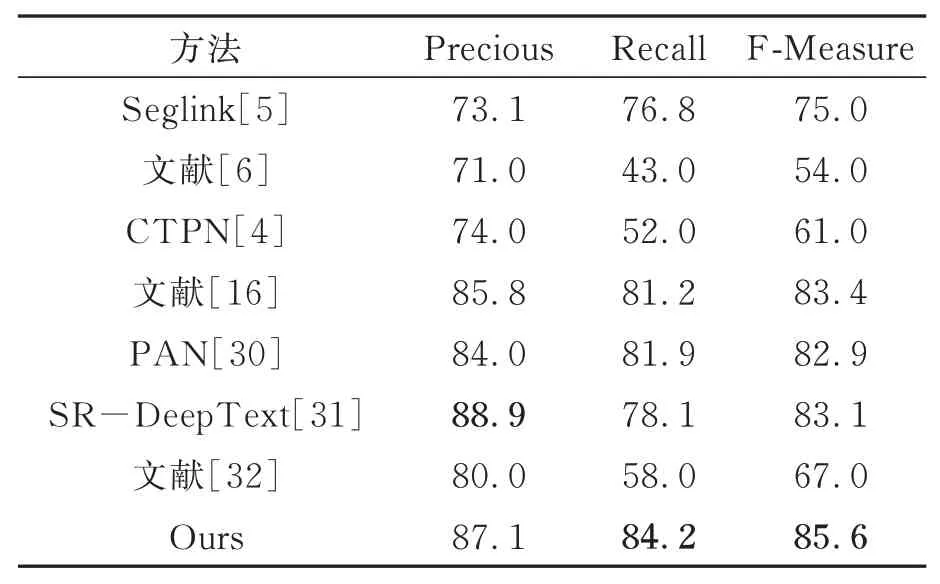
表2 ICDAR2015数据集算法性能对比Tab.2 Algorithm performance comparison of the IC‐DAR2015 dataset
从图12箭头指向处可见,本文算法明显抑制了水平和倾斜文本检测时掩膜重叠的现象,使定位结果更加准确。并且对于一些较小的文本区域,本文算法表现优异。
由表2可知,本文算法的准确度P较对比算法文献[16]提升了1.3,召回率R提升了3,F度量值提升了2.2;相较对比算法文献[31],本文算法召回率R、F度量值均较高,准确度P与其相当。表明本文算法对复杂自然场景中的倾斜方向文本检测效果较好,优于近几年先进的文本检测算法。
3.8 Total-text数据集实验及分析
该数据集包含1 255个训练样本和300个测试样本,样本多采自现实生活场景和商业标识等,图像中存在水平、倾斜和弯曲三种文本区域。实验结果如图13所示,多算法性能结果对比如表3所示。
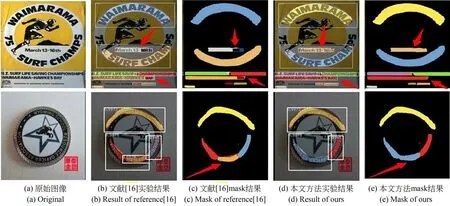
图13 Total-text数据集结果对比图Fig.13 Comparison of Total-text data set results

表3 Total-text数据集算法性能对比Tab.3 Algorithm performance comparison of the Totaltext dataset
图13中箭头处表明本文算法对于任意形状文本检测的掩膜重叠问题有明显的改善,使定位更加精准。对于图中出现的漏检情况,分析其原因主要为:受训练数据的影响,有一些“文本”区域的标记带有背景,这样的训练数据在一定程度上影响训练过程。
由表3可知,相较对比算法文献[16],本文算法准确度P提升了0.6,召回率R提升了2.3,F度量值提升了1.6;相较对比算法文献[32],本文算法准确度P,F度量值均较高,召回率R与其相当。表明本文算法对复杂自然场景中的水平方向、倾斜方向以及弯曲方向文本检测效果较好,具有一定的竞争力。
3.9 消融实验
为了验证本文提出的后处理筛选策略IOM有 效 性,在ICDAR2013数 据 集、ICDAR2015数据集以及Total-text数据集上进行了测试,结果如表4所示。可以看出,相比IOU,提出的IOM后处理筛选策略在ICDAR2013数据集上将算法的准确度P提升了0.7,召回率R提升了0.6,F度量值提升了0.7;在ICDAR2015数据集上将算法的准确度P提升了0.5,召回率R提升了1.5,F度量值提升了1;在Total-text数据集上将算法的准确度P提升了0.4,召回率R提升了1.4,F度量值提升了1.1。消融实验结果表明,IOM后处理筛选策略显著提高了算法的检测性能。

表4 ICDAR2013、ICDAR2015、Total-text数据集后处理算法消融研究Tab.4 Research on ablation of post-processing algorithms for ICDAR2013、ICDAR2015 and Total-text datasets
4 结 论
本文提出了一种复杂场景下共享核空洞卷积与注意力引导FPN的文本检测方法(KDAFPN)。该方法在特征提取阶段,通过共享核空洞卷积深层次挖掘细粒度特征,同时减少参数量、降低模型复杂度。利用上下文注意模块与内容注意模块精确表达目标位置信息,促进多尺度特征融合,提高特征图质量。提出IOM后处理策略来改善文本区域长宽比变化较大所带来的掩膜重叠问题,进而实现检测性能的提升。实验结果证明:本文模型对于自然场景水平文本检测的精度和召回率分别为95.3和90.4;对于倾斜文本检测的精度和召回率分别为87.1和84.2;对于任意形状文本检测的精度和召回率分别为69.6和57.3,效果提升显著。未来的工作将考虑把复杂场景下任意形状文本的识别作为最终目标。
猜你喜欢
光学精密工程(2022年13期)2022-08-02 08:53:30
计算机工程与应用(2022年1期)2022-01-22 07:46:48
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
计算机工程与科学(2021年4期)2021-05-11 01:59:36
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年19期)2018-11-14 02:37:08
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
火力与指挥控制(2018年3期)2018-04-19 11:43:39
自动化学报(2017年11期)2017-04-04 02:52:58
噪声与振动控制(2015年4期)2015-01-01 07:08:21
