
基于深度学习的二维化攻击流量分类*
2021-10-03 04:13李少晗周程昊程永新
通信技术 2021年9期
李少晗,周程昊,程永新,杨 栋
(1.海装装备项目管理中心,北京 100071;2.电子科技大学,四川 成都 610054;3.中国电子科技集团公司第三十研究所,四川 成都 610041)
0 引言
多年来,随着信息通信技术(Information Communications Technology,ICT)的发展,网络在各个国家人们生活的方方面面扮演着重要角色,同时对ICT 系统的攻击也在日益增长。因此,信息通信系统对有效的网络安全解决方案需求迫切。入侵检测系统(Intrusion Detection System,IDS)是一种在网络安全管理中使用广泛的方法,实现了对各种类型攻击的检测与分类。第一个针对入侵检测(Intrusion Detection,ID)的工作是John Anderson于1931 年为美国空军完成的一份报告《Computer Security Threat Monitoring and Surveillance》[1],提出了利用审计跟踪数据监视入侵活动的思想。后来,文献[2]详细综述了在2001 年到2013 年间出现的网络攻击及其技术。
IDS 通过监视计算机网络来检测恶意事件,防止非法操作影响计算机安全和网络安全。通常,根据网络入侵检测的方式,将IDS 分类为基于主机的ID 系统(Host-based Intrusion Detection System,HIDS)和基于网络的ID 系统(Network Intrusion Detection System,NIDS)。HIDS 依赖于系统中的日志文件、系统日志、软件日志以及文件系统等其他信息。NIDS 则在流量流中检查每个流量包。本文将主要聚焦于NIDS。
目前,市场上现有的商业NIDS 大多基于统计机制和阈值计算机制。这两种机制都使用特征选取,如分组长度、到达时间、流量大小和其他网络传输参数等特征,将它们做成一个特定时间窗口内的模型。
自学习系统是当下处理网络攻击的有效防御手段之一。它使用机器学习中的有监督、半监督和无监督的学习策略,通过一个庞大的正常和攻击连接语料库来学习正常和恶意行为模式之前的差异。虽然已经有了各种机器学习解决方案,但在早期商业系统中的适用性并不强[3]。现有的机器学习方法有较高的误报率和庞大的计算开销[4]。
深度学习是机器学习的子领域,可以通过神经网络自动完成特征的提取和融合。深度学习在图像处理、语音识别、自然语言处理和许多其他领域的任务中取得了振奋人心的成果。这些成果很多已经转换成为网络安全领域的重要任务[5-7]。本文基于深度学习的方法使用循环神经网络(Recurrent Neural Networks,RNN)、卷积神经网络(Convolutional Neural Network,CNN)、长短期记忆网络(Long Short-Term Memory,LSTM)等轻量级网络实现KDDCup 99 的5 分类任务,通过流量二维化和相关预处理操作使分类平均准确率达到94.1%。
1 相关工作
本次工作中使用的数据集为KDDCup 99 挑战赛的公开数据集,包含了5 种类别的攻击流量数据,分别为Normal(正常记录)、DoS(拒绝服务攻击)、Probe(监视和其他探测活动)、R2L(来自远程机器的非法访问)和U2R(普通用户对本地超级用户特权的非法访问)。该数据集是从一个模拟的美国空军局域网上采集的9 个星期的网络连接数据。测试数据和训练数据有着不同的概率分布,包含了一些未出现在训练数据中的攻击类型,使得入侵检测更具有现实性。数据分布如表1 所示,大部分方法在使用此数据集评估算法时都只使用了官方提供的10%训练集进行训练。本次工作内容中模型均在10%训练集中训练完成。

表1 KDDCup 99 数据描述
在深度学习的方法兴起之前,有很多的传统机器学习方法为攻击流量分类任务提供解决思路,如Scikit-learn 库[8]中集成 的LR、NB、KNN、DT、AB、RF 和SVM。以上传统机器学习算法的测试结果在表2 中给出[9]。
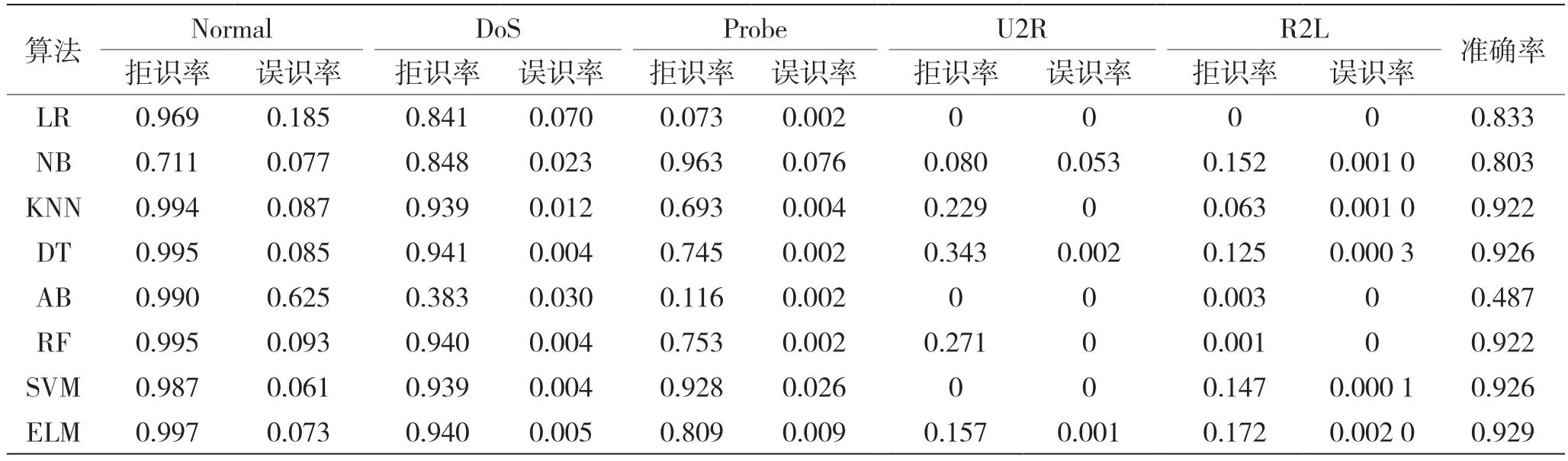
表2 传统机器学习算法在KDDCup 99 中多分类实验结果
之后有很多人在该数据集上进行了更多的尝试和改进。文献[10]讨论了在训练阶段仅考虑普通数据的非参数密度估计方法。文献[11]讨论了各种集合学习方法。文献[12]使用遗传算法,旨在模拟时间和空间信息,以识别复杂的异常行为。文献[13]讨论了基于内核机制的实时IDS,还提出与离线入侵检测系统相比,具有最小二乘的支持向量机分类器的在线特征提取机制表现良好。文献[14]讨论了多层感知机(Multilayer Perceptron,MLP)在NIDS 中的应用。文献[5-7]详细讨论了浅层网络和深层网络的效果。
2 二维化攻击流量分类方法
首先,对原始数据集进行预处理,将数据处理成可直接读取的csv 格式;其次,通过dataset 处理数据转变成二维化的数据,再使用二维卷积以更好地进行特征提取;最后,经过线性层完成分类。
2.1 数据集预处理
本方法采用KDDCup 99 公开数据集中的网络入侵检测数据包kddcup_data_10percent。该数据包是对kddcup_data 数据包(约490 万条数据记录)10%的抽样。在该数据集的41个固定的特征属性中,9 个特征属性为离散型,其他均为连续型。预处理过程主要分为4 步。
(1)字符串转换。原始数据中很多列的属性为字符串,如TCP、Normal 等。这些字符串类型的数据无法进行训练。本方法通过一个详细的对应表将这些字符串类型的属性转化为离散的数字。
(2)数值归一化。将所有字符串转变为离散数字后,这些数字的范围尺度大小不一,有的是0、1离散数据,有的跨度为0 到几百万,一定程度上会对模型训练产生影响。但是,从另一个角度来看,某些巨大的数字也许是更明显的特征,也许能更好地帮助模型进行分类。具体任务需要通过消融实验进行探究。
(3)数据增广。通过表1 可以看出,使用的训练集中的数据分布并不均衡,其中U2R 只有52条数据供训练,可以预见U2R 类别的召回率比较低。为了改善这个问题,本方法采取一种简单的复制数据增广方式提升样本数少的分类的训练条数。
(4)二维化。为了更好地利用属性间的关系,本方法尝试适合序列数据的RNN 和LSTM,略微提升了精确度,说明利用属性间关系可以一定程度上提升分类准确率。本方法又尝试将一维数据转化为二维数据,使用二维卷积提取特征来提升准确率。
图1 为KDDCup 99 数据集预处理流程。

图1 网络流量预处理流程
2.2 递归神经网络
在深度学习中,递归神经网络(RNN)是一类善于处理序列数据的网络。人类对事物的认知不是一蹴而就的,而是一点点深入的。人类会根据已经阅读过的内容来理解后面的内容,不会把之前的东西都丢掉重新进行思考,对内容的理解是贯穿的。传统的神经网络很难做到这一点,而RNN 极大程度上解决了这个问题,是具有循环的网络,允许信息持续存在,如图2 所示。

图2 递归神经网络
虽然RNN 具有信息持续存在的特点,但是随着距离的增加,RNN 无法有效利用历史信息。长短期记忆网络(LSTM)[15]是为了解决长依赖问题提出的。和RNN 类似,LSTM 也拥有这种链状结构,但是重复模块拥有不同的结构。与神经网络简单的一层相比,LSTM 拥有4 层。这4 层以特殊的方式进行交互,网络结构如图3 所示。

图3 LSTM 网络
2.3 卷积神经网络
卷积神经网络是一种带有卷积结构的深度神经网络。卷积结构可以减少深层网络占用的内存量,其中有3 个较为关键的操作:一是卷积核局部感受野;二是权重共享;三是pooling 层。这3 个操作有效减少了网络参数量,缓解了模型的过拟合问题。
数据集本身数据条目信息量较少,因此使用更深层次的网络结构会由于过拟合的导致精度下降。所以,本工作只采用了类似图4 的简单卷积网络结构。

图4 卷积神经网络
3 实验
3.1 实验细节
实验中的模型均是在python 3.6、pytorch 1.6.0环境下进行搭建,并在Nvidia 1060 6 GB 的显卡上进行训练。其中,网络训练的batchsize 大小设置为1 024,学习率设置为0.000 1,使用RMSprop 优化器和ReduceLROnPlateau 学习率调整策略进行20 次迭代优化。
3.2 实验数据
本文使用KDDCup 99 作为实验数据集进行五分类任务。该数据集包含4 种网络攻击流量和1种正常流量。KDDCup 99 数据集使用的是DARPA 1998 DataSet 的原始数据,在DARPA 98 数据集的基础上进行预处理,提取出以“连接”为单位的一条条记录。DARPA 98 数据集是MIT Lincoln 实验室搭建的一个模拟US 空军局域网的环境,捕获了9周的原始数据包,包含多种攻击。
3.3 实验评价指标
本次任务主要通过多分类各类别的精确率、召回率、F1 分数和准确率作为评价指标。评价指标主要由混淆矩阵中概念计算得出,混淆矩阵如表3 所示。

表3 混淆矩阵
精确率(Precision)计算的是所有被认为是正样本的条目中预测正确的比例:

召回率(Recall)计算的是所有正样本中被成功找出的条目的比例:

F1 分数(F1-score)是分类问题的一个重要衡量指标,是精确率和召回率的调和平均数,计算方式为:
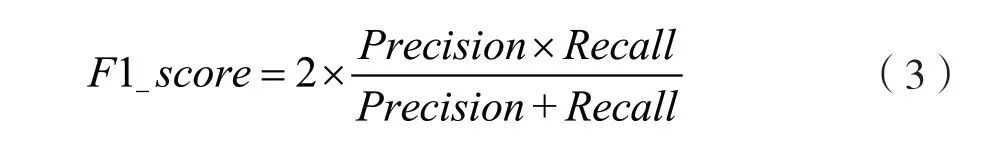
3.4 实验结果分析
本文首先对训练数据增广方法和数据归一化方法在本任务中是否适用进行了消融实验,具体见后续实验结果分析。
从表1 可以得知,U2R 类型的训练数据只有52 条,R2L 的训练数据只有1 126 条。这两种类型的训练数据和其他类别相比极不均衡。从表4 可以看出,如果不进行训练,数据的增广U2R 类型的数据甚至出现了塌缩,且R2L 类别的 F1-score 也都比较差。在使用训练数据增广方法后,两个类别的F1-score都出现了一定程度的提升,同时测试集整体的准确率变化很小,在一定程度上解决了训练集数据分布不均衡的问题。表4中模型后的参数为数据组织维度和线性层/卷积层层数。
根据表4 得出的结论,认为训练数据增广方法对本任务具有一定的效果,所以在后续任务中均默认使用训练数据增广方法。从表5、表6 和表7 中可以看出,在本任务中使用常见的数据归一化会降低分类的准确率。根据数据分析认为,该项任务中偏大的属性本身是该类别较为突出的特征,进行归一化后反而会影响对该类别特征的提取,进而影响最后的分类效果。

表4 训练数据增广方法消融实验

表5 递归神经网络数据归一化消融实验

表6 一维线性分类网络数据归一化消融实验

表7 二维卷积神经网络数据归一化消融实验
在KDDCup 99 中进行的完整对比试验如表8、表9 和表10 所示,所有实验结果均采取数据增广措施。其中,递归神经网络部分的方法名后面的参数为每一层隐含单元个数和隐含层层数。从对比实验可以比较明显看出,由于数据本身信息量较少,当网络逐渐变复杂时,分类效果并不会一直提升,应该适当选取轻量级的网络。递归神经网络(RNN)的优势是记忆能力,善于处理时序信息,但是本次任务的数据虽然是序列数据但不包含时序信息,前后关联度不够紧密,因此RNN效果并不是特别好。一维线性层通过线性变化也在本任务中有着不错的表现,已经超越了表2 中所有的传统机器学习方法。本文使用的KDDCup 99 流量二维化方法则是取得了更优的分类效果,在五分类任务中获得了0.941 的平均分类准确率。在使用训练数据增广方法后,U2R 和R2L 两个类别的分类情况也有所改善。

表8 递归神经网络五分类对比实验
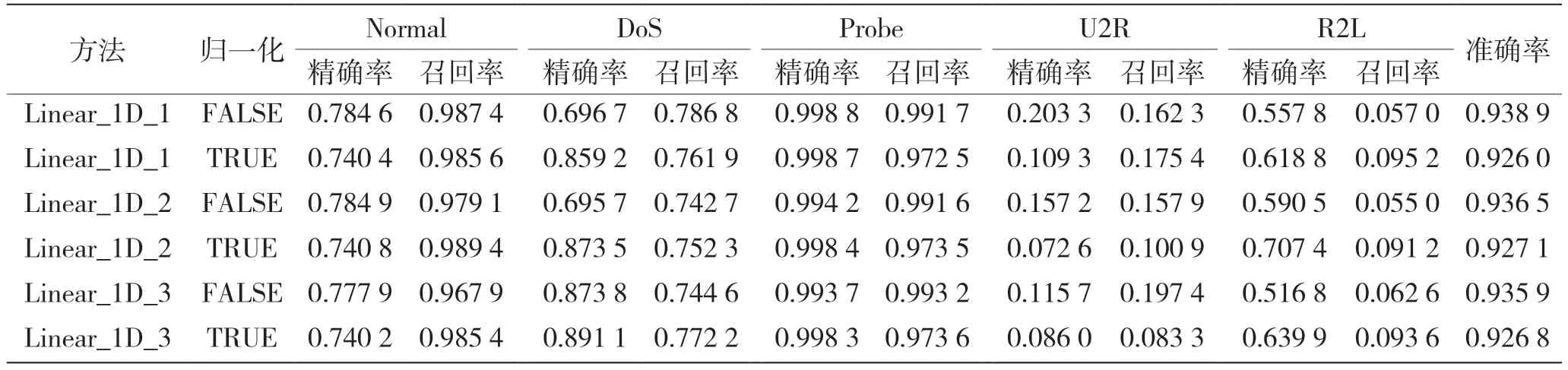
表9 一维线性分类网络五分类对比实验
4 结语
随着社会的发展,越来越多的生活场景需要接入网络,如近些年十分火热的物联网。随着网络的发展,网络安全问题变得更加重要。攻击流量的分类检测是网络安全防御的重中之重。针对攻击流量分类问题,本文使用KDDCup 99 数据集,提出了二维化的流量分类模式,同时通过消融实验验证了数据归一化和训练数据增广在该任务中的效果。对比实验结果表明,深度学习在攻击流量分类领域具有相当的优势,同时在流量二维化后使用卷积提取特征以更好地捕获流量属性间的关联,提升分类精度。未来将沿着轻量级二维化攻击流量分类的方向进行更深入的研究。
猜你喜欢
玩具世界(2022年2期)2022-06-15
现代电力(2022年2期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
房地产导刊(2021年8期)2021-10-13
出版人(2020年4期)2020-11-14
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
