
Tri-net 半监督辐射源个体识别方法*
2021-10-03 04:12吕昊远
通信技术 2021年9期
吕昊远,俞 璐
(陆军工程大学,江苏 南京,210007)
0 引言
通信辐射源个体识别技术通过获取到的辐射源信号样本,检测由于辐射源个体不同而导致的细微特征差异,提取所需的反映辐射源目标身份的信息,从而准确区分辐射源个体,针对性地把握目标属性特征,并实施有效的监控。该技术在通信网络结构分析和电子设备管制等方面发挥着巨大作用[1]。
深度学习具有强大表征能力,在多个领域中得以快速发展和应用,也为通信辐射源个体识别问题开辟了新的研究道路,即无需任何先验知识的深度网络可以直接在一个整体框架内端到端地对获取的信号样本进行特征提取和分类识别[2]。基于深度学习的通信辐射源个体识别方法不仅大大节约了科研成本,还有效地提升了识别准确率;因此,吸引了众多科研人员的关注。但通信方式在多数情况下都是非合作的,所以实际的电磁环境中存在少量的有标签信号样本和大量的无标签信号样本,这严重阻碍了有监督深度学习个体识别方法的发展[3]。如何根据现有的信号数据研究出基于深度框架的半监督个体识别方法就显得尤为重要。
伪标签半监督通信辐射源个体识别方法在面对“小样本”问题时取得了一定的效果,但此方法中深度模型性能会受伪标签质量的影响而产生较大波动。本文提出基于协同训练Tri-net 的半监督通信辐射源个体识别方法,增加深度网络数目,并采取轮次标签的伪标签赋值有效提升信号样本伪标签的质量。实验中在实际采集的通用软件无线电外设(Universal Software Radio Peripheral,USRP)通信辐射源信号数据集上进行验证,并和全监督方法、单一的伪标签半监督方法以及改进前的Tri-net 半监督方法对比。实验结果表明本文方法具有更高的识别准确率和更强的鲁棒性。
1 协同训练
协同训练作为一种半监督训练方法,可以有效缓解由于有标签样本数目过少带来的网络过拟合问题。本节内容介绍了协同训练中多视图学习的概念和Tri-net 模型的算法过程。
1.1 多视图学习
作为协同训练的前提思想,面对大量的无标记样本时,多视图学习假设可以从不同的视觉角度对每个数据进行学习[4],然后根据从不同角度训练出的深度网络再对无标记样本进行分类,挑选出高置信度的无标记样本以及其伪标签作为新的有标签样本加入训练集中[5]。协同训练的目标就是学习独特的预测函数为各个视图下的数据建模,并共同优化所有用于提高泛化性能的功能,不同视图的结果相互补充,达到不同网络可以相互协作以提高彼此的性能[6]。
1.2 Tri-net
Tri-net 是一种扩展的协同训练模型,它从3 个分类网络的角度对样本进行协同训练,模型的训练过程如图1 所示。整个模型中网络架构分为两部分,其中共享模块(Shared Module)为底层部分,3 个独立个性模块(Module1,Module2,Module3)为高层部分[7]。
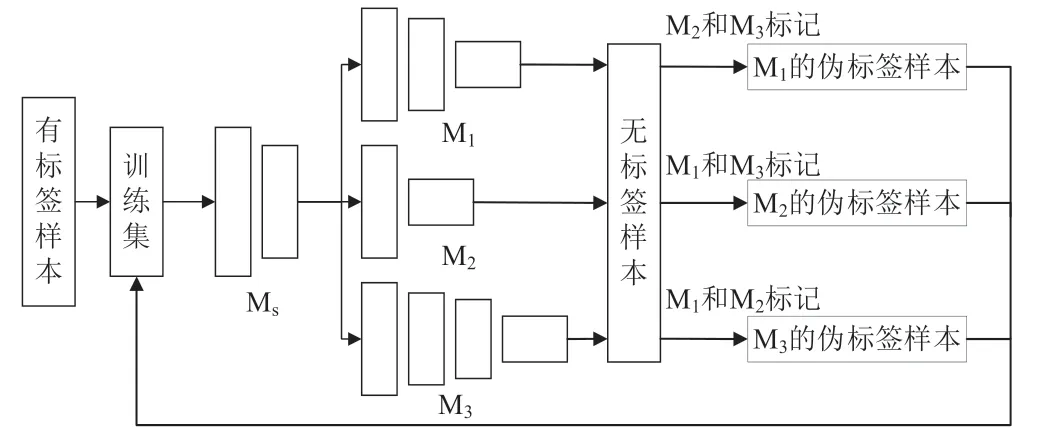
图1 Tri-net 模型训练过程
Tri-net 在半监督协同训练过程中,首先,对有标签信号样本进行随机加噪,获得3 个有标签训练集,通过对少量有标签信号样本预训练从每个训练集产生一个分类网络;其次,每个网络分别对无标签信号样本预测其标签值,如果其中两个网络对同一个无标记信号样本的预测标签值相同,则该样本及其伪标签就被认为具有较高的标签置信度,并作为有标签样本加入第3 个网络的训练集[8]。由此可见,Tri-net 中每个网络所获得新的有标签信号样本都由另外两个网络协作提供。
2 Tri-net 半监督个体识别方法
本文提出Tri-net 半监督通信辐射源个体识别方法,并且为提高伪标签的质量而改进算法的训练过程,在伪标签赋值中加入加权平均的轮次标签法。
如图2 所示,Tri-net 半监督辐射源个体识别方法包括3 个步骤。

图2 方法步骤
伪标签赋值过程中使用加权平均的轮次标签法,其中每个训练周期迭代结束后得到的伪标签是之前所有训练周期得到预测值的加权平均和[9]。
网络训练前初始化设置Z=0[N×C]、=0[N×C],分别表示每个训练周期的标签预测值和最终经过轮次标签法后得到的标签预测值,其中:N表示样本数目,C表示类别数(标签采取one-hot 向量编码)。标签预测值的迭代计算方式为:

式中:t为训练迭代周期数;B为每次迭代过程中的小批次信号样本集;i是小批次中的每个信号样本;j为3 个高层网络的编号。
每个训练周期结束后计算所有周期预测值的加权平均结果,计算方式为:

式中:α表示加权平均的平衡系数。为了避免训练初期网络的错误预测,就需要减弱初期的标签影响力,所以在加权平均后通过偏差校正得到最终的本轮次标签值。
在进行有标签信号样本初始化训练Tri-net 前,通过在有标签信号样本中添加随机噪声为3 个高层网络分别构建训练集,使得高层网络多样化,从而代表了不同的视图学习。为了防止网络训练趋于一致化,无标签信号样本训练过程中,每3 个轮次为训练集中的信号样本添加随机噪声,继续增强多样化,结合原本Tri-net 模型中的多网络投票机制,由此,Tri-net 半监督算法在增强伪标签样本的稳定度和可靠性方面发挥出了作用。
网络训练过程中,xl为无标签信号样本,表示其在每个高层网络对应的伪标签,Ly为交叉熵损失函数。将3 个高层网络的损失值相加并取平均构建出的半监督总体训练损失函数为:

图3 展示了Tri-net 半监督辐射源个体识别方法具体算法过程。

图3 Tri-net 半监督算法过程
3 实验与分析
3.1 样本集准备
如图4 所示,样本集的准备工作包括前后3 个环节。

图4 样本集准备过程
实验中使用LabVIEW 软件平台设计信号收发的程序,基于此,搭建采集环境,调整采样参数,完成信号的发射与接收[11]。实际采集到5 台USRP N210 通信设备的信号数据。在接收端经过解调得到同向、正交(In-phase、Quadrature,IQ)两路载波信号数据后进行预处理操作,具体包括采用数据清洗的方式去除采样初始阶段帧间切换时产生的不稳定暂态信息,进行功率归一化的比例变换。得到信号样本的形式为二维数组,其中数组宽度为2 表示IQ 两路载波数据,数组长度设置 为128。
对于5 台USRP 辐射源通信设备,将辐射源个体进行类别编号,即所有的信号样本设置5 类标签值,接着将样本集按照一定比例分为训练集和测试集,其中训练集中包括有标签信号样本和无标签信号样本两部分,最终完成样本集的构建。
本文实验的硬件条件为i7 10870H 的CPU 和RTX 2070 Max-Q 的GPU,软件条件为PyCharm+Anaconda(2020.02)+PyTorch(1.7.1)的开发环境。
3.2 网络结构设计
本节根据实际的深度网络需求关系,设计出适合于本文使用的USRP 信号样本的Tri-net 网络结构。MS、M1、M2、M3具体的网络结构组成如表1 所示。
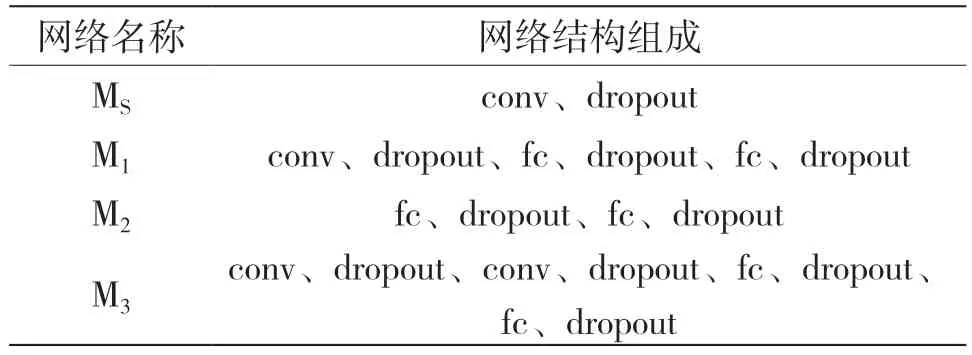
表1 不同网络的结构组成
其中,MS包括一个卷积层,卷积核大小为(1×3);M1包括一个卷积层和两个全连接层,卷积核大小为(2×3);M2包括两个全连接层;M3包括两个卷积层和两个全连接层,卷积核大小为(1×1)和(1×3)。每次卷积或者全连接操作之后都有dropout 正则防止训练过拟合,设置其参数值为0.3,每个高层网络最后都连接softmax 分类层。实验中选用Adam 优化器和交叉熵损失函数。
3.3 结果分析
实验中将加入轮次标签的Tri-net 半监督个体识别方法与全监督个体识别方法、单一的伪标签半监督方法以及改进前的Tri-net 半监督个体识别方法进行对比。在包含900 个信号样本的测试集上进行实验,训练集中设置不同的有标签信号样本数与无标签信号样本数的比例大小,通过100 次蒙特卡洛实验得出4 种方法的识别准确率。表2 和表3 分别展示了当有1 000 和2 000 个标签样本数时,4 种方法的识别准确率,其中,带*为加入轮次标签的Tri-net 半监督个体识别方法。
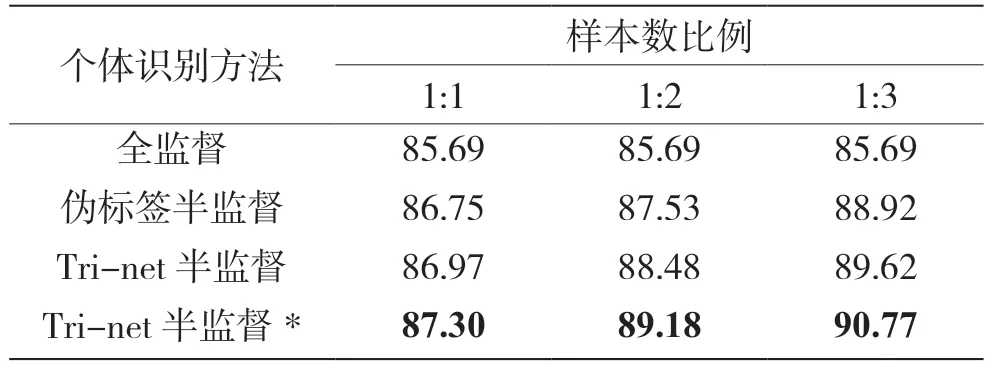
表2 识别准确率(1 000 个有标签样本) %
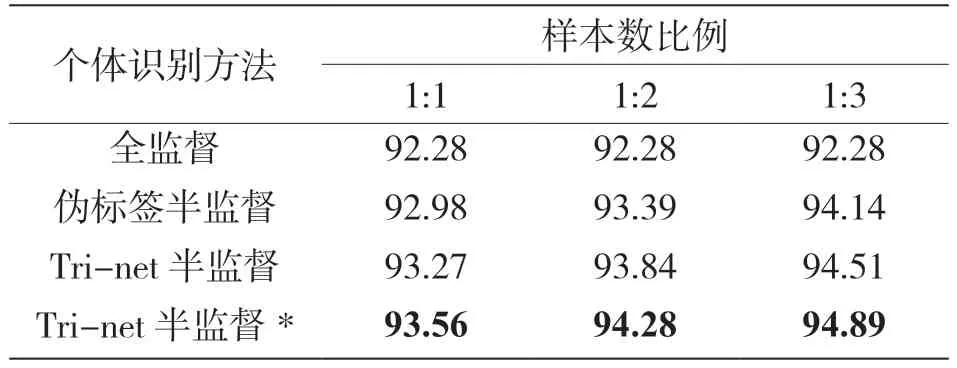
表3 识别准确率(2 000 个有标签样本) %
现对表中的一些数值进行解释并分析。因为全监督方法不使用无标签信号样本,所以改变样本数比例大小其识别准确率值不变;在一定范围内增大无标签信号样本数的比例,半监督方法的识别准确率有所提升;相比之下Tri-net 半监督个体识别方法的效果更好。Tri-net 模型为无标签信号样本赋予了伪标签,对作为训练数据的有标签信号样本起到了扩充作用。此外,3 个网络的协同训练选择高置信度的伪标签信号样本,也有效地避免了错误伪标签对于网络训练的干扰,而加入轮次标签之后达到了最好的性能表现,这是因为轮次标签可以平滑掉训练初始阶段网络的错误预测,增强模型对于错误预测的容忍,有效增强伪标签的质量,最终加强Tri-net 模型的鲁棒性。
比较表2 和表3 中的数据可以看出,表2 中添加轮次标签的Tri-net 半监督方法相比于全监督方法的性能提升更为明显。这也说明了Tri-net 半监督方法在标签信号样本数目较少的情况下性能提升更明显。
在固定有标签与无标签的信号样本数比例为1:3,分别计算标签信号样本数目为1 000 和2 000 个情况下,得到添加轮次标签后Tri-net 半监督方法在测试集上的识别准确率的混淆矩阵,如图5 和图6 所示。
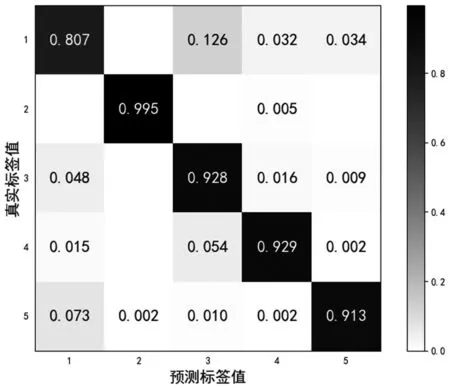
图5 有标签样本数为1 000 的混淆矩阵

图6 有标签样本数为2 000 的混淆矩阵
其中矩阵方格中的数值表示识别准确率,通过颜色深度可以更清晰地反映识别结果。对角线上的数值表示识别正确的概率,根据图中数值看出第2个辐射源的类内聚集度最好,与其他辐射源的区别较大,即使当有标签信号样本数目较少时,也能达到很高的识别准确率。相比之下,第1 个辐射源识与其他辐射源的差别较小,有一定的区分难度,识别准确率最低。
由于相似的通信辐射源调制方式识别问题的数据集中经常设置样本长度为128,因此,本文也借鉴这种设置方法。为探究样本长度对实验结果的影响,分别设置1 000 和2 000 个有标签信号样本,且无标签信号样本数目是有标签样本数目的3 倍,测试在不同样本长度下添加轮次标签前后Tri-net 半监督方法在测试集上的识别准确率,实验结果如图7 所示。实验结果表明,较短的样本长度划分会割裂信号样本的连续性,不利于特征提取,导致识别准确率较低;但随着样本长度的增加,在128 时识别准确率达到稳定。然而,长度继续增长,识别率不会有明显提升甚至有所降低,并且会伴随着训练时间增加,训练过拟合泛化能力减弱,所以128 的样本长度是最好的设置方式。
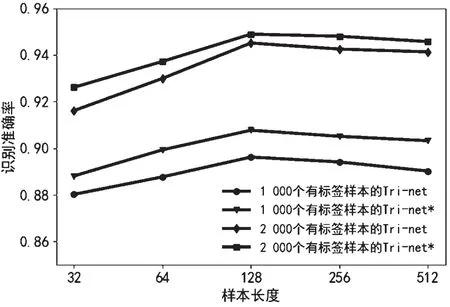
图7 不同样本长度下模型识别准确率
4 结语
深度学习方法在通信辐射源个体识别问题中经常面临有标签信号样本数目不足而导致模型性能下降状况,因此,本文提出了基于Tri-net 的半监督个体识别方法,介绍了协同训练中多视图学习的概念以及Tri-net 模型结构和训练过程,并加入了轮次标签进行方法改进。
实验阶段通过采集信号数据、预处理信号数据和划分样本集完成样本的准备,并根据信号样本的具体形式完成Tri-net中深度网络的参数设置。然后,比较分析了添加轮次标签前后Tri-net 半监督方法和全监督方法、伪标签半监督方法在测试集上的识别准确率。实验结果表明,添加轮次标签的Tri-net半监督方法的识别性能明显提升,当有标签信号样本数为1 000 和2 000,所占样本总数的四分之一时,分别得到90.77%和94.89%的最高识别准确率。
猜你喜欢
甘蔗糖业(2022年2期)2022-05-22
湖南林业科技(2021年3期)2021-12-02
甘蔗糖业(2021年4期)2021-09-26
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
上海电力大学学报(2020年5期)2020-11-17
北京航空航天大学学报(2020年10期)2020-11-14
雷达学报(2018年5期)2018-12-05
