
高吞吐率低时延图像DCT 处理器设计*
2021-10-01 02:39刘思军秦明伟刘多强
电子技术应用 2021年9期
刘思军 ,秦明伟 ,刘多强
(1.西南科技大学 信息工程学院,四川 绵阳 621010;2.中国直升机设计研究所,江西 景德镇 333000)
0 引言
DCT 变换运算量大,是图像处理中计算复杂、耗时长的运算单元。目前学界提出了两种快速DCT 变换算法:一类是寻求类似于FFT的蝶形算法来计算DCT[1],另一类是根据DCT 变换的规律寻求快速算法[2]。在第二类算法中,最常用的快速算法是行列分解法,该算法最初由Chen 等人提出[3]。典型的图像DCT 处理器的输入端采用串行输入机制,在进行DCT 变换前进行串并转换[4],吞吐率不高,耗时长,实时性差,无法应用于高分辨率、高帧率视觉测量场景。
针对高速大容量图象的处理,马林[5]等人针对2 048×2 048 像素、帧频为150 f/s的高速图像数据设计了存储与实时显示系统,便于延长记录时间和显示;杨志勇[6]等人针对星载图像高速大容量存储的文件化坏块管理进行了设计。本文从图像压缩变换角度延长记录时间和节省数据存储空间,针对高速风洞试验中视觉测量设备产生的分辨率可达5 120 像素×5 120像素、帧率达80 f/s 以上的高分辨率、高帧率海量图像数据的实时压缩问题,研究设计了一种应用于高速图像JPEG 压缩编码的高吞吐率、低延时的DCT 处理器。
1 DCT 算法
1.1 DCT 变换定义
若{X(m)|m=0,1,…,N-1}是对带宽有效信号x(t)取样得到的数据序列,共N 个样值,其1D-DCT 定义为[7]:
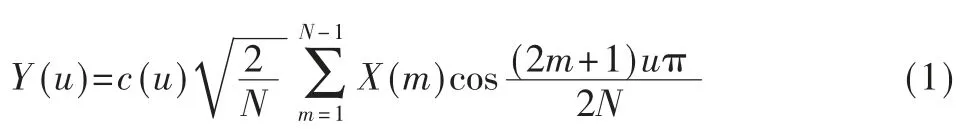
式中,Y(u)为第u 个离散余弦变换系数,u 为广义频率变量,u=0,1,…,7。当u=0,c(u)=;其他情况下,c(u)=1。
1D-DCT的定义可推广到2D-DCT。设一个大小为N×M的像素块,{X(i,j)|i=0,1,…,M-1;j=0,1,…,N-1}为二维图像信号数据矩阵,其二维离散余弦变换定义为[8]:

1.2 DCT 变换快速算法
若直接按照式(2)计算一个8×8的图像矩阵,则一次2D-DCT 变换共需要4 096 次乘法和4 032 次加法,不论是通过软件还是硬件实现该算法,都需要消耗大量资源。观察定义式(2)可知,2D-DCT 变换具有正交性和和对称性,基于此规律,很多2D-DCT 快速算法被提出。为方便描述,将N=8的1D-DCT 变换的定义式重写如下:

若将式(3)写成矩阵的形式,则可表示为:

其中,i=0,1,2,…,7;j=0,1,2,…,7。
根据式(5)和系数约束条件,可得到相应的系数矩阵:

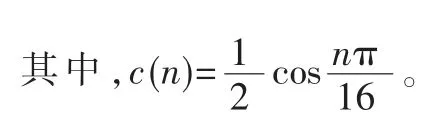
式(6)第一行作了数据上的处理,根据式(6) 和系数约束条件,可计算出第一行为定值,刚好等于c(4)。
设X=[X(0),X(1),X(2),X(3),X(4),X(5),X(6),X(7)]为输入的一行信号序列,Y=[Y(0),Y(1),Y(2),Y(3),Y(4),Y(5),Y(6),Y(7)]为1D-DCT 变换后输出的一行信号序列。根据式(4)和式(6),可得:

式(7)进行展开计算后,利用对称性进行奇偶分解,可得到:
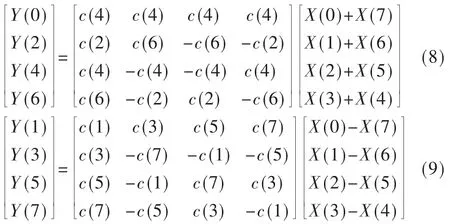
根据上式计算8 点1D-DCT 只需要32 次乘法和32次加法。
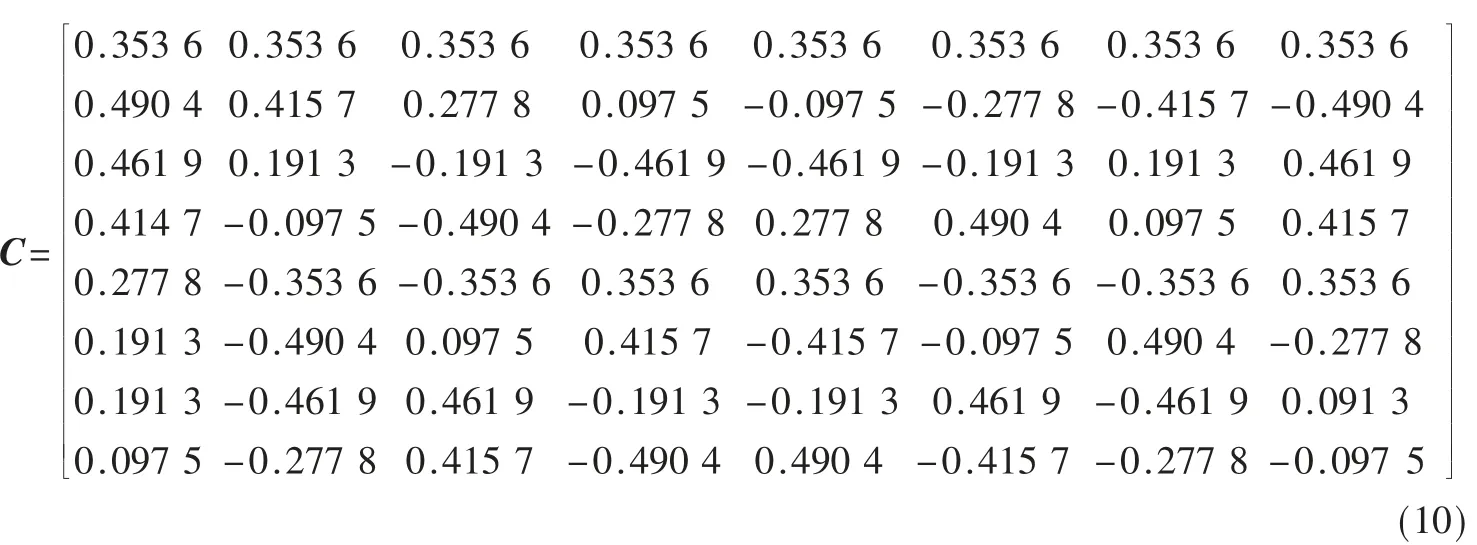
式(8)、式(9)两式展开,可以得到如图1 所示的1DDCT 算法流图。
2D-DCT的矩阵表示为:

其中,C 为DCT的系数矩阵,CT为C的转置。令Z=CX,则:

所以8×8的图像矩阵的2D-DCT 变换分为两步:首先计算Z=CX,得到1D-DCT的结果(逐行计算),第二步是将中间结果Z 进行转置后作为第二次1D-DCT 变换的输入,再次计算1D-DCT(逐列计算),得到的结果为图像块的2D-DCT 变换结果Y的转置YT,基于该思想即可实现DCT 变换的行列分解快速算法。
在对2D-DCT 变换硬件设计时,1D-DCT 一般采用分布式算法(Distributed Arithmetic,DA)[9-10]或者流图算法(Flow-Graph Algorithm,FGA)[11]实现。DA 算法是一种基于查找表和累加器计算结果的位级重构算法,其基本思想是通过查找ROM 表,利用ROM 和累加器代替乘法器[12-13]。DA 算法并行处理时需要使用大量ROM 资源,查询后经过累加移位等操作,控制变得复杂。由于对ROM的频繁访问和位串行实现算法结构的采用,数据处理速度受到限制,难以获得很高的时钟频率[14]。本文采用基于图1 所示的流图算法,计算过程采用流水线处理方式,提升处理速度,减少运算时间。

图1 1D-DCT 算法流图
2 架构设计
2.1 一般DCT 变换结构
根据行列分解算法可知,将2D-DCT 分解为两次1D-DCT 变换。行列变换法实现2D-DCT 有两种硬件实现结构:分时循环结构和全流水结构。前者行列变换采用同一个1D-DCT 变换单元,其结构如图2所示,该结构虽然节约资源,但是限制了2D-DCT 变换的速度,实时性差。全流水结构如图3 所示,采用两个1D-DCT 变换核分别处理行变换和列变换,采用乒乓操作进行中间数据的存储和转置操作,实现流水线处理。

图2 分时循环DCT 变换结构

图3 全流水线DCT 变换结构
对于这两种DCT 变换结构,输入端数据经过8 个时钟完成串并转换后,再将8 个像素并行送入1D-DCT 变换单元,这样的结构能够处理低速图像,吞吐率受限。例如,一个DCT 处理器在200 MHz的工作时钟下,每个时钟输入一个8 bit 像素,则吞吐率为200 MB/s。但对于图像源的数据率可达2 GB/s的高速图像处理系统,为了保证图像数据在处理过程中不丢失,则必须保证图像处理系统的吞吐率可达2 GB/s 以上,因此必须考虑设计新的DCT 处理器结构。
2.2 DCT 变换结构设计
整个DCT 处理器设计结构如图4 所示,主要分为三部分:读控制器、数据预处理、DCT 算法处理单元。读控制器从图像行缓存模块FIFO 阵列中读取数据,然后传输至DCT 算法处理模块完成后续操作。前级的图像行缓存的数据源按照Camera Link 通信协议[15]从外部模块写入,包含4 个视频数据信号:帧有效信号FVAL、行有效信号LVAL、数据有效信号DVAL 和数据DATA。从图4中可以看出,整个设计架构是一种并行流水线处理结构,设计了两个DCT 变换核,以此提高处理器吞吐率。
3 详细设计
3.1 读控制器设计
读控制器完成从图像缓存器中读取图像数据,读数据过程通过一个状态机实现。图4中的FIFO_A 阵列和FIFO_B 阵列构成乒乓缓存,每个FIFO 阵列由8 个FIFO组成,用于缓存8 行图像。系统启动后,读控制器首先从8 个FIFO 均已写满的FFIO_A 阵列中的第一个FIFO 开始读取一个128 bit 有效数据,第二个时钟时在状态机的切换控制下读FIFO_A 阵列的第二个FIFO。以此类推,读了第8 个FIFO 后又回到读第1 个FIFO,如此循环操作,读空FIFO_A 阵列,接着以同样的方式读FIFO_B 阵列。
3.2 数据预处理
该模块主要功能是将每次输入的128 bit 数据分割为16 个数据段,每个数据段即为一个8 bit 像素值,然后将每个像素值都减去固定值128 后转变为有符号数输出,送入DCT 变换处理单元。数据传输至DCT 处理单元时,将输入数据高位分割出来经过有符号化处理后的8 个数据发送至DCT_A 模块,将低位分割出来经过有符号化处理后的8 个数据发送至DCT_B 模块,16 个数据并行输出。
3.3 DCT 变换单元设计
从图4 所示的架构图可以看出,DCT 变换单元分为DCT_A 和DCT_B 两个结构完全相同的模块,数据处理时相互独立,完全并行操作。因DCT_A 模块与DCT_B 模块结构完全相同,在此仅给出DCT_A 模块的设计结构,如图5 所示。在输入数据有效时,同时输入8×8 图像块的一行8 个有符号数据,然后依次完成一维DCT 变换换、转置、第二次一维DCT 变换。该模块一个时钟并行处理8 个输入数据,完成DCT 计算后,同时输出8 个计算结果。
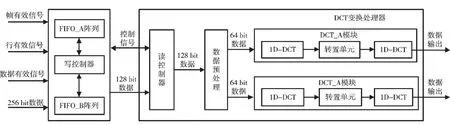
图4 2D-DCT 处理器设计结构

图5 DCT_A 模块设计结构图
由于FPGA 处理浮点数将消耗大量资源,需要将浮点数转化为定点整数进行运算。在设计中,考虑到计算精度,将变换系数扩大4 096 倍,然后取整作为固定系数参与运算。结合式(9),扩大4 096 倍并四舍五入取整后的c(1)~c(7)依次为2 009、1 892、1 703、1 448、1 138、784、400。根据式(9)和式(10),采用3 个处理步骤完成1D-DCT 运算。实现1D-DCT 变换的具体过程可以通过表1 说明。在计算过程中,一共使用24 个乘法器、28 个加法器。3 个步骤构成流水线处理结构,对于一个8×8图像子块的1D-DCT 变换,只需要11 个时钟即可完成。

表1 1D-DCT 变换单元数据处理过程
在表1中,add0、add1、add2、add3、sub0、sub1、sub2、sub3为1D-DCT 第一步计算的结果,将第一步的结果作为第二步的输入得到第二步的运算结果,即q0、q1、q2、q3、q4、q5、q6、q7、q8、q9、q10、q11的值,再将第二步的结果作为第三步的输入,从而完成1D-DCT的计算。两次1D-DCT 变换结构相同,只需要将相关的数据端口和片内寄存器适配对应的数据位宽。为了减小计算误差,第一次1D-DCT 变换的结果直接送入转置单元,在第二次1D-DCT 变换输出时,通过截断丢弃低位保留高位的操作方法,将运算得到的结果缩小224倍,同时完成四舍五入取整输出。
3.4 转置单元设计
通常中间结果用RAM 存储起来,然后通过读地址操作完成行列转换,但考虑到处理速度和操作灵活性,本设计利用寄存器组完成转置操作。为了减少图像块处理时间等待消耗,采用乒乓操作技术,设计两个寄存器组实现连续读写,提高吞吐率和实现低时延。每个寄存器组由64 个寄存器组成,构成8×8的寄存器阵列,用于缓存8×8 图像块的1D-DCT 变换得到的64 个数据结果。8 个时钟后,64 个寄存器已经完成数据寄存,然后按照8×8 矩阵的列顺序读出。
4 实验与分析
4.1 MATLAB 平台算法仿真
在进行DCT 变换处理器用FPGA 进行算法硬件实现前,通过MATLAB 完成相应的算法开发和数值分析。在MATLAB 程序中,读取一幅分辨率为5 120×5 120的灰度图像,将无符号的像素值转化为有符号数,经过8×8分块,然后根据DCT 算法实现DCT 变换。为方便显示计算结果,以原始灰度图像前4 个8×8 图像块的DCT 变换结果为例,给出MATLAB 平台计算DCT 变换的结果,如图6 所示。

图6 MATLAB 平台计算DCT 变换结果
4.2 FPGA 板级调试与分析
DCT 处理器在Vivado 集成环境上设计完成,当仿真验证通过后,下载至FPGA 板卡上进行板级调试。为了测试图像处理系统的实际工作情况,DCT 处理器与图像采集、缓存和图像8×8 分块等功能模块进行合并,完成图像采集到变换的处理过程。板级测试时,硬件管理器实时捕获的待测信号如图7 和图8 所示。从图7 可以看出,图像数据从输入DCT 单元到输出,只需要16 个时钟周期,完成一个8×8 图像块的2D-DCT 变换,只需要24 个时钟周期。图8 是将数据波形观察窗口进行了放大,便于观察DCT 处理器的计算结果。

图7 ILA 捕获DCT_B 部分数据和时序

图8 FPGA 计算DCT 变换结果
从图6 和图8中可以看出,DCT 变换在MATLAB 平台上的仿真结果与在FPGA中实际计算结果完全一致。在设计验证过程中,针对不同的数据源进行重复性测试,实验结果表明,在图像分辨率为5 120×5 120、帧率为116 f/s、数据率为3 GB/s的连续帧图像数据源下,处理过程中数据无丢失,平均每帧图像的处理时间不超过10 ms。针对不同的数据率图像源进行测试,经过多次重复实验,得到DCT 变换单元的性能测试结果,如表2 所示。

表2 DCT 变换单元性能测试结果
5 结论
本文所设计的基于FPGA的高速图像DCT 处理器能够实时处理高分辨率、高帧率时序图像。采用并行流水结构设计,在DCT 处理器中设计两个DCT 变换核,可同时处理16 个像素,实现了数据率高达3 GB/s 图像DCT 变换,此时平均单帧图像处理时间在10 ms 以内,满足高吞吐率、高精度、低时延要求。设计的DCT 处理器具备灵活性和可移植性,可根据需要选择相应模块集成到图像JPEG 压缩编码器中,实现高速图像实时压缩,具有较大的应用价值。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
数学小灵通·3-4年级(2021年9期)2021-10-12
小学生学习指导(低年级)(2020年10期)2020-11-09
红领巾·萌芽(2019年8期)2019-08-27
中国与非洲(法文版)(2017年10期)2017-11-23
数学大王·中高年级(2017年2期)2017-02-08
学苑创造·A版(2016年4期)2016-04-16
CHIP新电脑(2016年3期)2016-03-10
电子设计工程(2015年12期)2015-02-27
汽车零部件(2014年1期)2014-09-21
