
面向OSD 语言检测对照表的匹配定位算法*
2021-10-01 02:39林珊林志贤郭太良
电子技术应用 2021年9期
滕 斌 ,林珊 玲 ,林志贤 ,郭太良
(1.福州大学 物理与信息工程学院,福建 福州 350116;2.中国福建光电信息科学与技术创新实验室,福建 福州 350116;3.福州大学 先进制造学院,福建 泉州 362200)
0 引言
OSD(On Screen Display)是人机交互的通道[1]。在生产中为避免OSD 菜单出现文字错误,利用人工根据标准表格进行OSD 菜单的文字检测工作,然而人工检测存在成本高、误检率高等问题,故实现检测的自动化显得至关重要。
自动化检测主要包括两大部分:(1)正确识别OSD 上的文字并输出;(2)将识别结果与对照表对比确定最终检测结果。根据OSD的实际使用需求,对照表存在行数多、单行文字少以及多次重复的特点。本文结合Excel 表的编码方式,分析研究了BM[2](Boyer-Moore)、AC[3](Aho-Corasick)算法,提出了一种应用于OSD 自动化检测系统的面向Excel 表的匹配定位算法。
1 OSD 语言自动化检测系统
OSD 语言检测系统是一个容错率极低的系统,实际运行过程中主要通过两方面来达到要求,一是系统通过多次检测的方法来降低识别正确率不足带来的影响;二是通过设计优化的对照表匹配定位算法来提高定位的准确性,进一步降低检测系统的误检、漏检情况。OSD 语言自动化检测系统识别部分主要通过摄像头采集OSD图像信息,对采集的图像结果进行二值、降噪等必要的预处理,然后利用分割算法将图像中有效的文字部分进行分割,最后对分割好的文字经行识别操作并输出识别结果[4]。
结合多种品牌显示器和多层级的设置界面不难发现,OSD 菜单具有单项文字少、层级多、项目总数多以及同一单项名在不同界面多次出现等特点。常见显示器OSD 图像如图1 所示。图2 是图1的实测识别结果,结果按行排列展开。用于确定最终检测结果的对照表同样也是按行展开,每行单元格对应OSD中的单项菜单的内容。图3 即图1 所示的OSD 界面的对照表信息,其中74 项的亮度为64 项亮度设置展开后的二级菜单的第一个菜单项,此处9 行表格就出现了1 项重复内容,因此如何在重复率高的对照表中找到识别内容的准确位置就显得尤为重要。

图1 OSD 图像

图2 识别结果

图3 标准对照表
2 经典的模式匹配算法
2.1 模式匹配
模式匹配[5]是数据结构中字符串的一种基本运算。例如:给定某字符串T 长度为n,则存在T=T0T1T2T3…Tn-1,有一子串P 长度为m,则存在P=P0P1P2P3…Pm-1。在给定字符串T中匹配字串P,若存在TiTi+1Ti+2Ti+3…Ti+m=P0P1P2P3…Pm-1则模式匹配成功,反之失败。
模式匹配按同时匹配子串的个数,可以分为单模式匹配和多模式匹配,其中常见的KMP[6](Knuth-Morris-Pratt)、BM 是单模式匹配算法,AC、WM[7](Wu-Manber)是多模式匹配算法,以下主要介绍BM、AC 算法。
2.2 BM 算法
BM 算法是一种非常高效的字符串搜索算法[8],其核心是两大规则,即坏字符规则和好后缀规则,通过这两大规则来决定匹配过程中向右跳跃的距离[9-10]。
BM 算法的基本流程如下:给定一个字符串长度为n,子串P 长度为m,首先将字符串T 和子串P 左对齐,然后从右向左进行比较,如图4 所示。
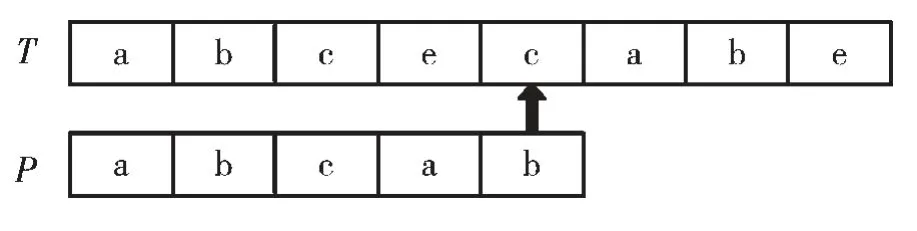
图4 BM 算法匹配方法
利用坏字符规则和好后缀规则来计算字串向右移动的距离[11],如图5 所示,从右往左看,已匹配的cab 字符为好后缀,未配的e 字符为坏字符。

图5 坏字符和好后缀
坏字符规则存在两种情况:(1)如果字符x 在模式P中未出现,那么从x 开始的m 个文本显然不可能与P匹配成功,直接全部跳过该区域即可;(2)如果x 在模式P中出现,则以该字符进行对齐。图4 所示的匹配过程中c 字符为坏字符,且在子串P中出现,故符合坏字符规则的第二种情况,其移位效果如图6 所示。

图6 坏字符规则移位
好后缀规则也存在两种情况:(1)如果在P中位置t处已匹配部分P′在P中的某位置t′也出现,且位置t′的前一个字符与位置t的前一个字符不相同,则将P 右移使t′对应t 方才所在的位置;(2)如果在P中任何位置已匹配部分P′都没有再出现,则找到与P′的后缀P″相同的P的最长前缀x,向右移动P 使x 对应方才P″后缀所在的位置。图5 所示的匹配过程中cab 字符为好后缀即P′,且在字串P 再没有出现,ab 字符为P′的后缀P″相同的P的最长前缀x,所以符合好后缀规则的第二种情况,向右移动P 使ab 对于方才P″后缀ab 所在位置,其移位效果如图7 所示。

图7 好后缀规则移位
2.3 AC 算法
AC 自动机[12]即AC 算法。它与普通单模式字符串匹配的不同点在于同时与所有子串进行匹配[13],其核心是状态转移函数和失效函数。
图8 是一个使用多模式串he、she、hers、his 创建的自动机。初始状态都为0,读取第一个字符串he,0 状态受到第一个字符h的刺激改变为1 状态,受到e的刺激改变为2 状态,此时第一个字符串读取完毕,将末尾字符的2 状态标记为output 输出状态。然后依此读取下一个多模式串,其中读取hers 时,刺激h 已经存在,不需要创建新状态,直接到达状态1 即可,只有在当前状态下,受到的刺激是新刺激时,才会创建新状态。然后依次为所有字符串创建自动机路径[14]。图中实线即为状态转移函数。

图8 AC 算法
AC 算法的匹配过程如下:假设存在主串ushers,将其放到自动机中运行,首先,第一个字符u,0 状态不存在u的刺激,返回自身状态,s、h、e的刺激全部存在,状态依次经过3、4、5的转变,5 为output 状态,即she 字符串匹配成功。当再下一个刺激r 出现,由于当前状态不存在刺激r 出现失配情况,这时就需要用到失效函数。应该转移到的状态点为:从这个状态节点向上直到树根节点(状态0)所经历的输入字符,与从产生失效状态的那个状态节点向上所经历的输入字符串完全相同。而且这个状态节点是所有具备这些条件的节点中深度最大的那个节点。不存在满足条件的状态节点,则失效函数为0[15]。因此上述情况此时应从状态5 转变为状态2 继续执行。
3 本文算法
3.1 算法思想
针对以上分析可知,无论BM 算法还是AC 算法都是实现字符串的精准匹配,OSD 语言检测对照表的匹配定位算法需要在无法完全匹配的情况下实现准确定位。因此本文提出了一种面向OSD 语言检测对照表的匹配定位算法。
本文算法使用分类匹配和概率定位的方法来实现精准定位的需求。本文算法的流程图如图9 所示。

图9 算法流程图
3.1.1 分类匹配
分类匹配的存在是为了减少匹配次数。在真正执行匹配操作前先对照表内容和识别内容进行预处理,将表格内容从上至下每3 行单元格分为一组,计算3 行内容的字数之和N 作为分类的一级标签,中间行单元格的字数M 作为分类的二级标签;同样地对识别的结果也进行三行一组的分配,计算3 行总字数m 和中间行字数n。至此,分类操作执行完毕。
匹配流程图如图10 所示。匹配过程如下:根据每组识别结果的m 和n 值在表格分类项中查找出m=M 且n=N的组,通常有多个符合条件的组,找出这些待匹配组后,每组进行逐行逐字匹配操作。每组每行匹配一次,上下行的匹配结果用于计算定位概率,中间行的匹配结果用于最终检测结果的认定。匹配过程由上往下进行,匹配第一步是进行字数的匹配,出现字数不等情况时,直接跳过该组进行下一组的匹配。组内行之间的匹配过程是一对一跳转的逐字匹配,出现字符不匹配就跳转到下一字或单词的匹配进程中。

图10 匹配流程图
3.1.2 概率定位
检测的最终结果是否值得信赖,重点在于是否可以在对照表中找到识别结果的准确位置。为了提高定位的准确性,引入概率定位的方法,概率定位是本算法最为重要的方法。利用上下行匹配正确字数和上下行总字数的商来确定定位概率,取待匹配组中定位概率最大值所在组的中间行位置为最终定位位置,输出位置值和定位概率值,即:

OSD 语言检测系统的最终输出即:

3.2 算法实例
以中文OSD 菜单为例,考虑如下的对照表内容:第一行起,图像/亮度/对比度/色调/清晰度/高级设置/亮度/清晰度/色调/对比度/图像/高级设置,共12 行,识别输出为青晰度/色调/对比度。
不考虑汉字的转码过程,直接使用汉字演示算法执行过程。实际过程是汉字转成4 字符后执行操作。首先对对照表内容和输出内容进行分类,其中对照表内容分为3 大组以M-N的形式记录,分别是7-2、7-3、7-3、7-3;8-2、8-2;9-3、9-4、9-2、9-2,识别输出以m-n形式记录,即8-2。查找m=M 且n=N,共两组待匹配组,每组经行逐行匹配。
第一组,与对比度/色度/清晰度进行匹配,上下行成功匹配2 字共6 个字,定位概率为33.3%,中间行匹配成功结果为正确。
第二组,与清晰度/色调/对比度进行匹配,上下行成功匹配5 字共6 个字,定位概率为83.3%,中间行匹配成功结果为正确。
第二组定位概率大于第一组,选择第二组的匹配结果,最终检测结果输出为:9 行83.3%色调正确。
4 测试结果与分析
为了更好地对本文算法进行效果验证,随机编辑了2~5 字的中文词语或短语各25 个,合计100 个不同单项,并将这100 个单项重复出现5 次,共获得500 项菜单内容,将500 项随机排列生成最终的对照表。测试环境是Windows 10 64 位操作系统,使用配置为AMD R5-3500U 2.1 GHz CPU、8 GB 内存的笔记本电脑,采用C 语言编程。
预处理过程,将对照表分成了10 大组28 小组。表1所示是分组的基本情况。

表1 分组基本情况
根据对照表的内容,特意模拟了如下几种识别情况并结合传统匹配方法来检验算法效果:
第1种:OSD内容正确识别结果正确,测试结果如图11、图12 所示,本文算法准确定位出了所在行和检测结果,而传统方法只能简单查找出对照表中有5 个匹配项。

图11 本文算法测试结果

图12 传统方法测试结果
第2种:OSD 内容正确但识别结果有误,分为3种情况:(1)上下行识别有误;(2)中间行识别有误;(3)三行识别均有误。测试结果如图13~图16 所示,其中传统方法的情况一结果和图12 所示结果类似,这里不再展示。

图13 本文算法情况1

图14 本文算法情况2

图15 本文算法情况3

图16 传统方法情况2、3
第3种:OSD 内容错误但识别正确,本文算法检测效果如图17 所示,传统查找方法结果如图18 所示。测试结果不难发现,即使在内容有误或识别有误的情况下,本文算法仍旧可以进行定位并且输出识别和判断结果,而传统方法只能在OSD 和识别都无误的情况下找出相同的项,出现任一错误时就无法查找匹配。

图17 本文算法

图18 传统方法
根据以上3种情况的多次测试结果表明,本文方法对比传统的查找方法可以规避在出现不完全匹配情况时无法匹配定位的问题,同时引入的概率定位方法可以高效地在多重复项中找到目标项,日常的使用则可以兼顾定位准确性和识别确定性。
5 结论
本文通过对OSD 语言检测系统的需求分析,结合BM算法和AC 算法提出了一种面向OSD 语言检测对照表的匹配定位算法。实验表明,该算法通过分类匹配和概率定位提高了匹配速度,解决了无法定位的问题。结合OSD 菜单的发展和文字识别的发展现状,算法还可以进一步改进,使其更加适应系统需求。
猜你喜欢
无线互联科技(2020年11期)2020-12-01
电子制作(2019年13期)2020-01-14
山西教育·招考(2019年12期)2019-09-10
移动信息(2018年1期)2018-12-28
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
中国纤检(2016年3期)2016-04-07
山东工业技术(2015年21期)2015-07-27
燕山大学学报(2014年1期)2014-03-11
杂草学报(2013年2期)2013-10-24
测绘科学与工程(2013年6期)2013-03-11
