
基于超大内存节点的波动方程逆时偏移高效实现
2021-09-28 12:58包红林
石油物探 2021年5期
包红林,李 敏,张 萌
(中国石油化工股份有限公司石油物探技术研究院,江苏南京211103)
1 问题分析
波动方程逆时偏移成像主要由双程波动方程延拓和波场成像两步构成,先对震源波场采用双程波方程正向外推,并保存外推波场数据;然后对接收波场采用双程波方程反向外推,并在外推过程中读取记录的震源外推波场快照,应用成像条件获取成像值,所有时间步求和得到单炮成像数据体。随着油气勘探向深层目标体和精细勘探方向发展,野外勘探普遍采用高精度与高密度地震采集技术,地震数据规模不断增大。对逆时偏移计算而言,地震数据规模增大,使得单炮数据成像空间规模增大,波场外推计算量与波场数据量增大。对大规模地震数据进行逆时偏移计算时,巨大的计算与存储需求成为制约逆时偏移计算效率的主要因素[1-3]。
随着GPU技术出现,利用GPU强大并行计算能力进行逆时偏移波场有限差分延拓计算,节点内采用CPU/GPU异构协同平台进行炮集逆时偏移计算[1-3],使用一定规模计算节点组成的集群进行多炮数据的并行计算,已成为大规模地震数据逆时偏移计算的标配模式,基本满足了其对海量计算的需求。但逆时偏移的大数据量波场数据存储需求一直没有得到有效解决,严重影响了逆时偏移计算的效率提升。
逆时偏移集群计算节点,通常配置2个Intel多核CPU和2个GPU(硬件架构见图1),每个CPU采用6个高速内存通道连接12个内存插槽,GPU采用PCIe3.0×16通道连接CPU,GPU0读写CPU0直连内存的速度可达12GB/s,构成1个高带宽、低延迟互联的CPU/GPU计算单元。理想条件下,每个计算节点可由2个CPU/GPU计算单元同时进行两炮数据的偏移计算。计算节点使用DRAM内存,因DRAM内存的密度及功耗受制造工艺限制,内存条存在容量低、价格高与功耗大的问题,内存条容量多为16GB或32GB,计算节点的24个内存插槽最多可配置768GB内存,内存总价高,功耗也会变得更高,因此,集群计算节点一般最多配置为192GB或256GB内存,需配置大容量的SAS或SSD硬盘来满足应用数据存储需求。
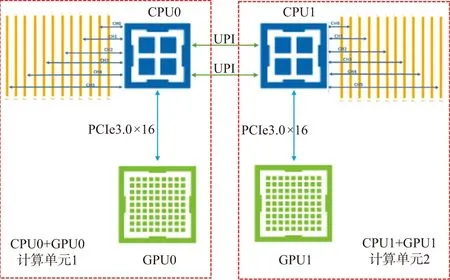
图1 计算节点硬件架构示意
单炮逆时偏移先进行震源波场正传计算,需要存储相关成像计算所需的震源波场数据,数据存储规模很大。以实际生产处理的某大规模地震数据为例,该地震数据共87838炮,成像范围为2901(Nx)×2901(Ny)×1501(Nz)(Nx,Ny,Nz分别为x,y,z方向的成像网格点数),成像网格为20m×20m×10m,单炮7027道,成像计算网格数为563×487×1501,偏移最大外推时间为6s,采样间隔为0.7ms,延拓总步数Nt为8285,每隔10步进行一次相关成像计算,因此震源波场数据需要存储830步,每步波场数据存储量约为1.533GB,单炮震源波场数据总存储量约为1272.5GB。常用计算节点配置的256GB内存,难以满足波场数据存储需求,为此逆时偏移计算通常使用以计算换存储的震源波场重构方法(或波场存储策略)来降低波场数据存储量。文献[4]提出了基于边界存储和基于检查点技术的有效边界存储策略,并测试对比了不同存储策略的计算量与波场存储量;文献[5]对比了随机边界存储、基于吸收边界的全波场存储、检查点存储、有效边界存储等4种存储策略的计算成本与存储量需求,讨论分析了随机边界和有效边界存储策略的计算效率和成像精度;文献[6]对比了随机边界法、有效边界法和检查点技术等波场重构方法的优缺点,提出了基于优化检查点技术的波场插值重构方法。由此可知,在常用的波场重构方法中,随机边界存储策略无需存储波场数据,但在浅层边界处会产生较为明显的噪声干扰,检查点与有效边界存储策略则需要通过本地硬盘存储波场数据[4-6]。
本文以采用检查点技术的TTI介质逆时偏移方法为例,此方法通过使用无损压缩算法,进一步降低波场数据本地硬盘存储量,其计算流程如图2所示。主要步骤包括:①GPU震源波场正传计算,CPU将检查点震源波场数据压缩后存储到硬盘,从最后一个检查点对应时间(Nc)开始至延拓计算最大时间,CPU将相关成像计算所需的震源波场数据存储到内存;②GPU检波点波场反传计算,从延拓计算最大时间至最后一个检查点对应时间(Nc),CPU从内存读取其对应时间的震源波场数据,传送给GPU进行相关成像计算;③GPU检波点反传计算前,CPU先从硬盘读取压缩后的检查点波场数据到内存解压,并传送给GPU进行震源波场重构计算,将重构震源波场中相关成像计算所需的震源波场数据存储到内存;④GPU检波点波场反传计算,CPU从内存读取对应时间的震源波场数据,传送给GPU进行相关成像计算。重复进行步骤③与步骤④,最终获得整个成像结果。由此可见,采用检查点技术进行波场重构,使得总的偏移计算量由2Nt增加到接近3Nt(Nt为总的计算时间步),计算量约增加1/2,增加波场重构计算是影响逆时偏移计算效率的一个主要因素。由于需要通过本地硬盘进行检查点波场数据存取,以前面提到的大规模地震数据为例,单炮偏移计算时,因采用无损压缩检查点波场数据的方法,需本地硬盘存储的所有检查点波场数据中最大存储量约为3.1GB,SSD磁盘写入数据需要9s,读取数据需要7s;SAS磁盘存储读或写入数据需要22s,SAS磁盘读写时间约是SSD硬盘的3倍。通过采用GPU计算与CPU硬盘异步读写的优化方法,可以部分隐藏硬盘读写时间。但是因本地硬盘低速读写性能引起的较长数据读写时间仍是影响逆时偏移计算效率的一个因素。

图2 常规检查点技术逆时偏移计算流程
2 解决方案
随着IT技术的发展,研究新计算机技术用于逆时偏移,使其更加高效地进行大规模地震数据处理,一直是逆时偏移应用发展的一个重要研究方向。本文从逆时偏移目前存在的震源波场数据存储问题出发,通过研究分析存储技术发展和新产品应用,提出计算节点超大内存配置与波场数据内存存储方案,提升逆时偏移的计算效率。
2.1 混合内存技术与性能分析
随着大数据时代的来临,处理数据量迅速增长,以Apache Spark为代表的大数据内存计算正被广泛部署应用,内存计算是将处理数据全部存放在内存中进行实时计算与处理的高性能并行计算,摆脱低速磁盘性能限制,大幅提升数据吞吐量与读写速度,成为海量数据分析的利器[7-8]。基于Spark内存计算框架的逆时偏移成像技术研究也已开展[9]。面对动态随机存取存储器(dynamic random access memory,DRAM)的存储密度与功耗受制造工艺限制问题,近几年一些新型非易失性随机存储(non-volatile memory,NVM)介质相继推出,具有存储密度大、静态能耗低、价格低廉等特性,但因存在写性能低及写寿命有限等问题,目前难以全面取代DRAM,因此利用DRAM与NVM各自性能优点的混合内存体系被广泛关注。已有研究设计了线性统一编址混合内存、DRAM作为NVM缓存的混合内存、分层混合内存等3种混合内存硬件体系结构,并开展了体系结构、操作系统、编程模型等软件方面的研发,来实现大幅提升服务器的内存容量并降低成本,满足内存计算快速增长的内存容量需求[7-8,10-11]。2015年推出了一种全新的非易失存储技术3D Xpoint,采用多层次的三维交叉点阵列结构,相比DRAM存储密度提高10倍,基于此技术的Intel Optane SSD硬盘能够提供高达4GB/s的带宽[10-11]。2018年推出了基于3D Xpoint技术的傲腾内存,其与DDR4内存插槽兼容,具有接近DDR4内存的读写速度和延迟,提供128,256,512GB 3种规格内存条;需要Intel第二代至强可扩展处理器支持,采用混合内存架构,DDR4内存用作三级高速缓存,傲腾内存用作主内存;1台双CPU服务器的24个内存插槽通常采用12个DDR4与12个傲腾内存条或12个DDR4与8个傲腾内存条配置模式,最高可配置6TB傲腾内存。傲腾内存技术为大内存计算及人工智能提供平台基础支撑,也为逆时偏移等大数据量存储需求的地震数据处理方法研究及软件研发提供了一个全新的内存存储解决方案。
2.2 计算节点超大内存配置和波场数据内存存储方案设计
基于傲腾内存配置,我们设计了超大内存计算节点配置方案。计算节点配置2个支持傲腾内存的Intel第二代至强可扩展处理器。基于逆时偏移存储需求分析及性价比考虑,选用128GB傲腾内存条及8GB DDR4内存条,采用12×128GB傲腾内存+12×8GB内存配置模式,共配置96GB DDR4内存+1536GB傲腾内存,可满足逆时偏移内存存储需求。节点安装RedHat7.6及以上操作系统,操作系统与应用程序无需修改就可运行。
基于超大内存计算节点,可根据震源波场数据大小,采用内存直接存取或内存无损压缩存取的方法,实现逆时偏移波场数据内存存储。以前面的大规模地震数据为例,单炮偏移计算时存储的相关成像计算所需的震源波场数据量约为1272.5GB,无损压缩后的存储量约为626.8GB,此时单台计算节点的内存可满足两炮同时偏移计算的波场数据存储需求。针对单计算节点单炮偏移计算而言,如果延拓计算总步数为10000,每隔10步进行一次相关成像计算,那么需要存储1000步的震源波场数据。以1536GB傲腾内存容量为例进行测算,可满足不超过3110GB的震源波场数据无损压缩后的存储,每步震源波场的最大存储量为3.11GB,由此推算出最大成像计算网格数可达913×913×1001或745×745×1501。在此情况下,单炮偏移计算采用计算节点内2个CPU/GPU计算单位协同计算的方法,以满足其对GPU显存及GPU计算性能的需求,并通过GPU计算与边界数据交换异步执行的优化方法实现边界数据交换时间的隐藏[1-3]。
采用震源波场数据内存存储的逆时偏移计算流程见图3。主要步骤包括:①GPU震源波场正传计算,CPU将相关成像计算所需的震源波场数据直接或无损压缩存放到内存中;②GPU检波点波场反传计算,CPU从内存直接或解压读取对应时间的震源波场数据,传送给GPU进行相关成像计算。重复进行步骤②,获得最终成像结果。采用震源波场数据内存存储的方法,将单炮偏移总计算量从3Nt降到最小计算量2Nt,计算效率提升1/3。由于操作系统将96GB DDR4内存用作三级缓存,CPU在DDR4内存中进行波场数据的读写及压缩或解压存储,操作系统根据混合内存管理策略,在DDR4内存与傲腾内存间自动进行数据迁移,因此,CPU读写混合内存数据的速度与仅使用DDR4内存基本相当。利用DDR4内存高速存取特性,摆脱了低速硬盘读写性能瓶颈。以每步1.533GB波场数据为例,其内存读写时间仅需0.13s,这个读写时间可通过GPU计算与波场数据读写异步执行的优化方法完全隐藏掉。因此,采用震源波场数据内存存储的逆时偏移计算方法,避免了常规检查点技术逆时偏移计算方法存在的低速硬盘
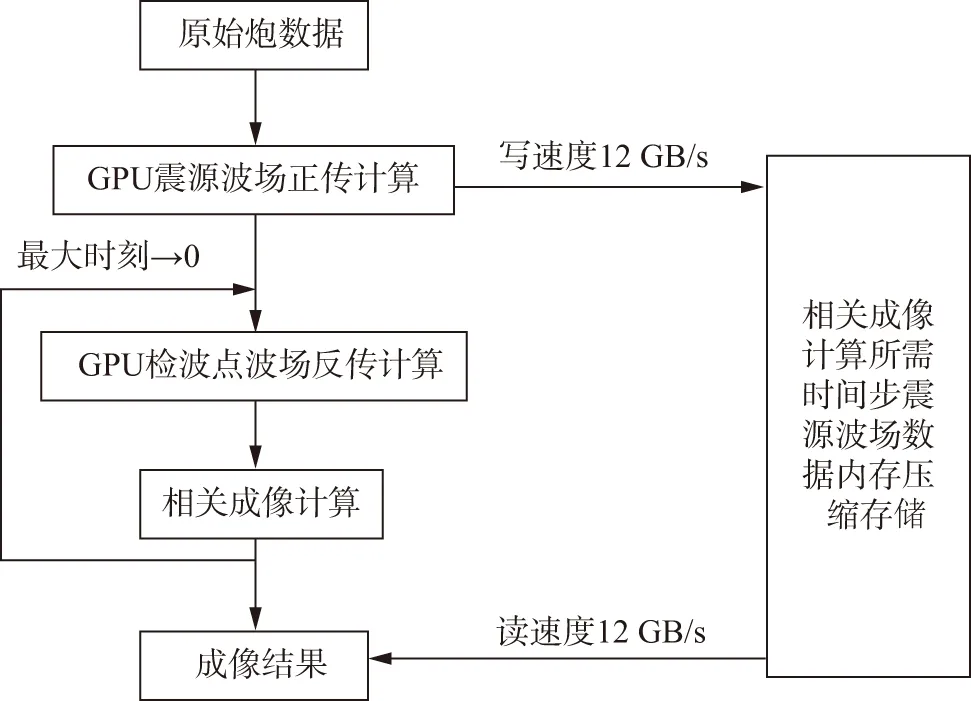
图3 超大内存逆时偏移计算流程
读写与震源波场重构计算等影响计算效率的问题,通过降低计算量与隐藏波场数据读写时间,大幅提升了偏移计算效率。
3 测试分析
采用实际生产数据进行应用测试。从测试环境与测试数据选择两方面考虑测试方案。测试环境方面,现有100个节点的集群计算节点配置2个Intel 6132 CPU(第一代至强可扩展处理器)、256GB DDR4内存、2块16GB显存的V100 GPU,由于该型号CPU不支持傲腾内存,现有计算节点不能实施超大内存方案,为此采用1台配置2个Intel 6226R CPU(第二代至强可扩展处理器)、1.5TB傲腾内存(12×16GB+12×128GB傲腾内存)、2块V100S GPU的节点作为测试计算节点,设计了不同平台的单节点对比测试方案。测试计算节点采用震源波场数据内存存储逆时偏移计算方法,与现有计算节点采用检查点技术逆时偏移计算方法对比,分析震源波场数据内存存储的逆时偏移计算方法的应用成效。
3.1 不同平台常规地震数据对比测试
选用了9864炮密度较低的常规地震数据,成像范围为561(Nx)×861(Ny)×1001(Nz),成像网格为25m×25m×10m。TTI介质包含速度、ε、δ、地层方位角和倾角等5个参数模型,每个参数模型数据量为2GB。偏移计算最大频率为70Hz,单炮1677道,成像计算网格数为282×259×1001,延拓计算总步数为8368,每隔10步进行一次相关成像计算,因此需要存储837步相关成像计算所需的震源波场数据。采用检查点技术逆时偏移方法计算时设置了6个检查点,波场数据内存存储逆时偏移计算采用波场数据内存直接存取的方法。两种偏移计算方法对比测试结果见表1,超大内存单炮偏移计算用时缩短了37s。

表1 不同平台单计算节点常规地震数据单炮偏移计算测试结果
3.2 不同平台高密度地震数据对比测试
高密度地震数据选用前文所述大规模地震数据,TTI介质的5个参数模型数据量均为47GB。因偏移计算最大频率为90Hz,现有计算节点的V100 GPU显存为16GB,节点需采用一炮2个GPU协同计算模式,并将单炮成像网格Nz方向的值由1501减至770,成像计算网格数变为563×487×770,需要存储830步相关成像计算所需的震源波场数据。采用检查点技术逆时偏移方法计算时设置了3个检查点,波场数据内存存储逆时偏移计算采用波场数据内存压缩存取的方法。两种偏移计算方法对比测试结果见表2,超大内存单炮偏移计算用时缩短了217s。

表2 不同平台单计算节点高密度地震数据单炮偏移计算测试结果
3.3 相同平台高密度地震数据对比测试
在测试计算节点上,选用前文所述大规模地震数据,偏移计算最大频率为70Hz,成像计算网格数为563×487×1501,延拓计算总步数为8285,需要存储的相关成像计算所需震源波场数据步数为830。先后采用检查点技术与波场数据内存存储逆时偏移计算方法,进行相同平台对比测试。采用检查点技术逆时偏移方法计算时设置了6个检查点,波场数据内存存储逆时偏移计算采用波场数据内存压缩存取的方法。两种偏移计算方法的测试结果见表3,超大内存单炮偏移计算用时缩短了279s。

表3 相同平台单节点高密度地震数据单炮偏移计算测试结果
3.4 计算效率分析
对偏移计算实测结果进行分析,得到波场数据内存存储逆时偏移计算效率见表4。高密度炮数据相同平台测试结果显示,波场数据内存存储逆时偏移计算效率提升了46.1%,其中约33%的效率提升为去除重构波场计算的成效,剩余13%为高速内存数据存取的成效,说明波场数据内存存储对计算效率提升显著。不同平台两种数据对比测试结果显示,波场数据内存存储逆时偏移计算效率提升了57.8%(高密度数据)~66.0%(常规数据),说明波场数据内存存储逆时偏移计算方法对于不同密度炮数据计算效率提升存在差别,此差别主要是由于检查点存储策略在对不同密度炮数据偏移计算时,其本地硬盘波场数据读写时间隐藏优化方法成效不同所致。

表4 波场数据内存存储单炮逆时偏移计算效率
4 结论与讨论
针对逆时偏移,利用傲腾内存构建计算节点超大内存,通过波场数据内存高速缓存,解决了大数据量波场数据存储问题,实现了最小计算量的全波场数据内存存储策略,大幅提升了大规模地震数据逆时偏移计算效率。实际生产数据测试结果表明,对于大规模地震数据,节点配置超大内存,高密度地震数据单炮计算效率提升46.1%以上,显著缩短了大规模地震数据逆时偏移计算时间,减少了计算能源消耗。该技术还可应用于其它大内存需求的地震数据处理,如角度域处理,因此具有很好的实用性和经济效益。
随着面向人工智能应用的全新Ampere架构的A100 GPU推出,其单精度浮点FP32运算性能由V100S的16.4TFlops提升到19.5TFlops,性能提升幅度有限,但其单精度浮点TF32运算性能高达156TFlops,是V100S FP32运算性能的9.5倍,因此,将逆时偏移计算从使用现有的CUDA核迁移到新的Tensor Core,利用超高的TF32计算能力,实现偏移计算效率的飞跃,将成为偏移计算未来发展方向之一。随着非易失性随机存储介质、DDR5内存及GPU Direct存储等新技术不断应用,构建多个高速数据传输通道高效协同的数据存储与传输模式,满足GPU超高计算能力对高速数据存取性能需求,也是偏移计算未来发展的一个方向。
致谢:感谢H3C和Intel公司在本研究中给予的产品与技术支持!
猜你喜欢
计算机系统应用(2022年4期)2022-05-10
天津医科大学学报(2021年4期)2021-08-21
石油地球物理勘探(2020年5期)2020-10-17
石油地球物理勘探(2020年5期)2020-10-17
石油管材与仪器(2020年2期)2020-05-11
物探化探计算技术(2020年1期)2020-04-08
计算机应用(2017年1期)2017-04-17
癌症进展(2015年3期)2015-12-18
地震研究(2014年3期)2014-02-27
船海工程(2013年6期)2013-03-11
