
基于大数据岗位分析推荐系统
2021-09-27 08:15程栋桧高琪琪
智能城市 2021年16期
刘 飘 程栋桧 高琪琪 鲁 琛
(无锡职业技术学院,江苏 无锡 214121)
在数据量快速增长的时代,大数据正迅速成为许多组织的社会需求和标准结构。通过人们整理、分析、提取和集成大量数据,能够发现新的数据,并可以创造出新的价值,让标准化的认知、判断、思维方式、服务模式和产品形式形成崭新的外观和发展方向。随着互联网岗位需求增加,人们需要从大量职位信息中寻找出适合自己的岗位。以往人们需要从许多职位信息中对比、分析这个职业在当前社会的需求和前景。但这样烦琐的方式已难以满足当前人们的需求,使得大数据分析快速发展。通过大数据岗位分析系统帮助高校学生透析职位市场需求变化,预测就业前景,给出现阶段符合自己条件的岗位。
1 大数据岗位分析推荐系统环境需求
本系统采用B/S体系架构,设计开发采用Linux开发模式,先在Windows上进行系统和前端的编码实现,再在Linux上进行测试部署大数据集群环境。
1.1 数据分布式抓爬虫
使用Python开源爬虫框架Scrapy并结合redis数据库,实现从招聘网站分布式爬取职位信息数据,大幅度提高爬虫的效率。使用Scrapyd提供的Scrapyd JSON API请求管理爬虫任务,再结合Gerapy可视化管理工具调用Scrapyd提供api,实现对爬虫任务的打包部署、删除、停止、监控、日志分析等功能的可视化管理。
1.2 大数据平台环境
搭建分布式Hadoop集群系统,在此基础上建立HBase非关系数据库,对爬取的职位信息进行存储,以便后续进行数据分析。
1.3 数据分析挖掘Spark
搭建Spark计算引擎,并采用Yarn进行资源分配,进行数据转移的分布式计算,以升高程序运算的速度,并把职位信息的分析结果存储到Mongodb非关系数据库中。
1.4 Web端的应用
用户访问网页并发送http响应请求,由Python开源框架Django进行相应响应,如用户发送数据可视化请求,使用Django调用Mogodb数据库调用数据,并将其结果进行响应返回。
2 大数据岗位分析推荐系统实现功能需求
随着当代互联网蓬勃发展,大量的工作岗位在网上发布,学生或求职人员需要从大量的数据中分析和了解当前行业的技能要求、薪酬、岗位地区分布、学历要求、工作经验、职位发布数量等信息,较为困难。亟须一套能够帮助学生和求职人员分析岗位信息,将处理好的数据直观地展示给人们的软件程序。本系统基于近期行业对人才需求信息进行分析,主要实现了对职位信息分布式爬取、对信息分析处理、对处理完的信息可视化展示、用户给出需求经行岗位推荐。
3 大数据岗位分析推荐系统特点
当前,大多数国内招聘网站使用基于内容的协同过滤算法来对用户进行推荐。基于用户的筛选和基于职业的筛选显著提高了推荐的质量,但是用户通常受到特定职位要求的限制或对行业或环境的了解不清,因此无法更好地选择职位。
(1)使用大数据技术进行分析,采用大数据分析算法,对工作行业分布、城市分布、工资分布、学历信息、各个地区的用户等数据进行分析,让用户对行业和企业工资有清晰了解。系统可以帮助求职者选择自己的职业,以便求职者可以更好地了解自己的环境。
(2)利用Spark算法库对职位信息内容进行特征抽取分词,并转换为哈希成特征向量。使用关键词提取的方法对职位所需的具体技能进行提取,通过Spark机器学习将相同职位所需要掌握的技能,使用贝叶斯算法进行分类建立模型,再使用建立的模型为求职者进行智能推荐。
4 大数据岗位分析推荐系统模块功能介绍与设计
4.1 运行的基础平台
大数据基础平台采用三台服务器搭建,一台作为主节点,另外两台服务器为从节点。大数据集群主要搭建和使用Hadoop大数据平台、Zookeeper分布式协调服务、Spark计算引擎、Hbase数据库和Mongodb数据库等。
4.2 数据爬取
使用三台服务器对python开源框架Scrapy结合redis数据库的分布式爬虫,在主节点上对需要招聘信息的url地址经行爬虫,并将其存入redis数据库中。另外两台从节点从redis数据库中调用url进行对招聘网站上职位信息的爬取,并将爬取的职位信息数据存在Hbase数据库中,再结合使用Scrapyd和Gerapy可视化管理爬虫集群。
Scrapy是一套纯Python语言开发的、用于爬取网页内容或各种图片并提取结构化数据的开源网络爬虫框架,可以应用于数据挖掘、信息处理或存储数据等一系列操作中,是目前Python中使用最受欢迎和最广泛的爬虫框架。
Redis是遵循键值存储原理的非关系数据库,内存中键/值存储主要作为一个应用程序的高速缓存或快速响应数据库。Redis将数据存储在内存中,不存储在磁盘或固态驱动器(SSD)上,Redis提供了速度、可靠性和性能。
Scrapyd是一个应用程序,可以在服务器上部署爬虫并计划爬网作业,并提供对爬虫项目的API管理。
Gerapy用于Scrapyd集群可视化管理,对Scrapy日志分析、自动打包和部署、启动和停止服务、在线修改代码、监控和警报以及Web应用程序。
4.3 数据存储
系统数据的存储分为分布式HBase存储和Mongodb存储。
HBase是一个基于在HDFS上开发的分布式数据库,不同于常见的关系数据库,其非常合适键/值对数据存储的数据库,主要用以存储庞大的结构化数据。逻辑上,HBase存储用于表、行和列的数据。与Hadoop类似,HBase可以针对企业进行水平扩展,通过增加廉价商业服务器的发展,提高学生计算和存储管理能力。
HBase是面向列的NoSQL数据库,虽然类似于包含行和列的关系数据库,但不是关系数据库。关系数据库面向行,HBase面向列。
在此系统中需要处理和分析大量半结构化或非结构化数据,在线分析处理大量数据,并进行挖掘与分析,采用HBase这种非关系数据库存储大量数据比关系数据库更具有优势。
MongoDB是一种分布式非关系数据库,MongoDB数据结构如键值对构成,类似一个JSON文档。Mongodb可以储存更多的复杂的数据结构,查询语言系统强大,语法结构相似于高级语言的查询方式,如java语言面向对象的方式查询。此外,还可以实现类似关系数据库的查询功能单表,提供对数据索引的最大支持。
MongoDB的非结构数据都存储在类似于JSON的文档中,使数据的持久性和合并更容易。应用程序的代码对象已被推送到文档模型中,可以简单使用数据,架构的管理、数据的访问和各种复杂丰富的功能不会受到任何影响,且没有停机时间,可以动态更改架构,具有较好的操作灵活性。
系统需要对数据进行分析和可视化处理,对数据管道、数据搜索、图形处理以及数据的可靠性、灵活性和安全性需求较大,采用Mongodb数据库更具有效性和实用性。
4.4 数据分析
使用Python编程语言调用Spark API,实现对HBase数据库中的大量非结构化职位信息数据进行快速分析和处理,可以进行行业的学历统计、行业职业岗位统计、行业需求技能统计、行业薪酬统计、职位发布日期统计以及行业工作经验统计以及行业工作地点统计的数据处理工作,并将分析结果存储到Mongodb数据库中。
Spark是一种快速发展的新开源技术,可在计算机节点群集上工作。速度是Apache Spark的标志之一,在这种环境下工作的开发人员可以获得基于RDD(弹性分布式数据集)框架的应用程序编程接口。RDD可以将节点分离到群集上的较小分区中,以便独立处理数据。
4.5 信息展示
使用web网页方式展示信息,使用python开源框架Django。为了给用户可视化直观展示采用了Apache的ECharts开源可视化图表库,提供更直观、交互丰富、可高度进行个性化定制的数据信息可视化图表。
4.6 系统采用的推荐算法
利用Spark MLlib机器学习的朴素贝叶斯算法对职位信息进行建模,学生或求职者需要推荐合适职位时,可以通过提交表单对web法出请求,程序对其做出响应,并调用推荐算法程序进行分析,再将结果返回给用户。
Spark机器学习库(MLlib)建立在Spark上,并在分类、回归、决策树,聚类等领域提供了大量算法。Spark在内存中运行,性能较好,可以与其他模块结合使用,以执行特征转换、提取和选择。
Spark MLlib支持迭代计算,优化性能和结果质量,提供了许多ML算法的分布式实现。算法具有低级基元和实用程序,可用于优化、特征提取和线性代数。
系统整体架构如图1所示。
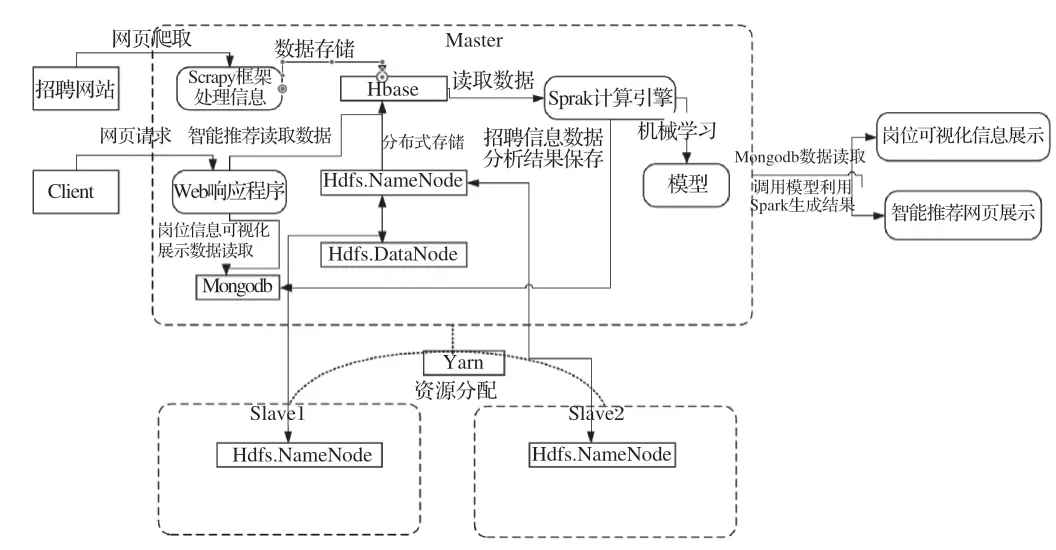
图1 系统整体架构
5 结语
本文介绍了大数据岗位分析系统功能的实现与系统的运用。通过对系统设计和系统的实现做了比较详细的介绍,并介绍了系统所依赖的各种环境并对其分析和比较其他工具的优势,如Spark计算框和数据库的选择。通过大数据岗位分析系统帮助高校学生透析职位市场需求变化,预测就业前景,并给出现阶段符合自己条件的岗位。
猜你喜欢
中国医院院长(2022年2期)2022-11-09
房地产导刊(2022年10期)2022-10-18
山东冶金(2022年2期)2022-08-08
现代信息科技(2021年21期)2021-05-07
近代史学刊(2017年2期)2017-06-06
电子制作(2017年9期)2017-04-17
河北大学学报(自然科学版)(2015年1期)2015-02-27
电子设计工程(2015年6期)2015-02-27
海外星云 (2014年22期)2015-01-19
山东女子学院学报(2014年6期)2014-03-01
