
多分支融合局部特征的行人重识别算法
2021-09-26 10:45肖雅妮范馨月陈文峰
计算机工程与应用 2021年18期
肖雅妮,范馨月,陈文峰
1.重庆邮电大学 通信与信息工程学院,重庆400065
2.光通信与网络重点实验室(重庆邮电大学),重庆400065
在当今社会,各地政府在公共场所关键点、交通路口、生活小区、停车场等区域安装大量摄像头,因此获得了海量的行人数据,而针对如何在复杂场景下获取人脸、步态等信息,并进行行人检索的问题,就需要行人重识别技术。行人重识别是指在已知来源与非重叠摄像机拍摄范围的视频序列中识别出特定行人的技术,即指给定某摄像头拍摄到的某行人图片,在资料库中检索该行人被其他摄像头拍到的图片[1]。由于摄像头位置、角度和参数设置不同,行人姿态频繁变化,以及背景干扰、遮挡和成像质量不稳定等原因,同一行人在不同时刻不同摄像头拍摄的图片中存在较大差异[2],这使得行人重识别的研究具有很大的挑战性。而深层网络可以提取到的行人细节相比传统算法效果更显著,因此目前的行人重识别研究主要以深度学习的方向为主。
由于人体结构具有强分辨[3],所以大部分算法的研究重心放在如何使模型获得更多的行人表征特征上。目前大部分算法是从整体图片获取到行人的特征,具有代表性的如文献[4]提出的是行人重识别最基础的网络框架,相比传统算法效果得到了一定提升但由于特征学习部分未引入增强机制,错失对局部的学习、算法效果不显著。文献[3]在行人身份ID的基础上,额外增加行人属性,算法效果提升一些的同时增加了复杂度,由于忽略了部分不显著或不经常出现的详细信息,相比文献[4]算法效果增益小,且仅使用全局特征在算法的测试部分不利于分辨不同行人和同一个行人不同摄像头的照片。为了进一步提高算法效果,行人重识别的研究针对特征学习,将重点从全局转移到局部。因为加强网络对局部特征的学习,能更多地获取行人细节信息。如文献[5]通过对定位人体骨骼来学习身体区域的特征,相比仅使用全局特征的方法得到了提升,但由于对骨骼定点大大增加网络复杂度,同时关注行人姿势大于对局部的学习,因此最后的效果增益较小。文献[6]先将行人分开再对齐学习特征、最后测试部分使用融合特征,虽然该方法有对局部特征的学习,但缺乏对局部注意力特征的学习和多分支网络更好的融合设计。而文献[7]是加强网络对于人体姿势的学习,因此引入行人姿势估计的算法,需要提前预训练,这大大提升了算法难度。综上所述,为强化网络学习行人特征信息和保证网络的复杂度、训练难度,本文设计了一种端到端的多分支网络机构,一共三个分支:随机擦除的分支、全局学习分支、局部学习分支。
在算法结构中全局学习分支的引入有两个目的,一是联合训练确保算法精度,二是获取人体的驱干信息。局部学习分支在本文的网络结构中是对被均分成三等分后的特征图部分分别进行学习,其分支能获得行人局部细节信息,随机擦除分支通过固定面积的掩膜随机地对特征图进行遮挡,加强网络对未遮挡部分的注意力特征学习,可看做是一种加强特征学习的策略,因为遮挡使用的掩膜无网络参数,所以不会增加网络规模。考虑到会有噪音干扰,本文的三个分支在结构上仅共享骨干网络部分,其余部分独立,最后本文结合最小二乘法,根据实验数据,做损失函数的权重分配。最后本文使用三个分支得到的融合特征进行测试,实验结果表明,本文提出的方法在Market-1501数据集、DukeMTMC-reID数据集、CUHK03-Label、CUHK03-Detect数据集上都取得了更好的准确率。
1 相关工作与多分支网络设计
虽然深层的网络仍可根据人体不同的身体部位语义信息来初步区分,但缺失关键和细微的行人特征信息和学习到额外的背景信息都会导致算法增益小。且文献[8]和表1的结果数据显示,当网络结构分支增加、图片细分增多,将增强网络单个分支对图片的注意力,提高算法效果。因此本文在网络结构的设计上,选择的不是单分支的结构而是多分支的结构。而本文在分支的选择上考虑单个分支的算法效果与运算量以及训练难度,同时结合上述理论。
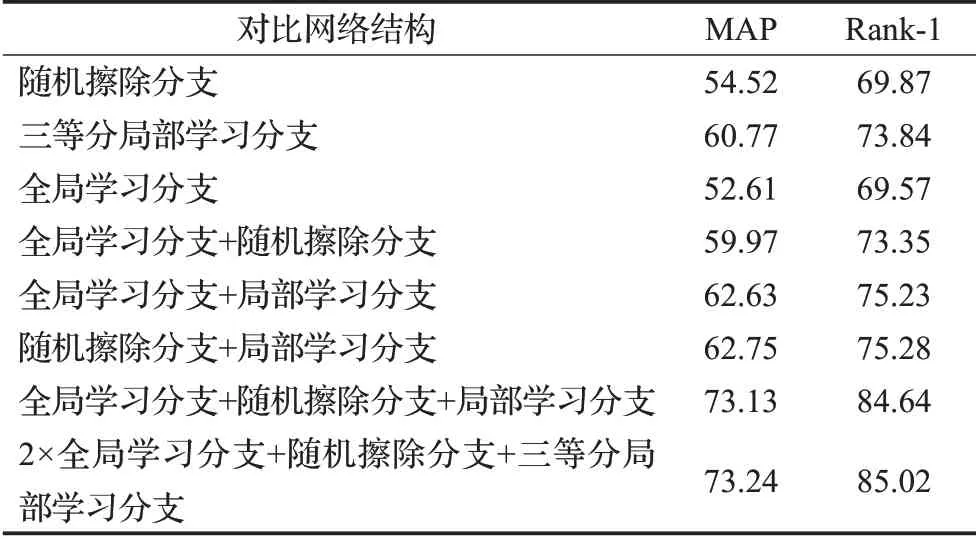
表1 在数据集DukeMTMC-reID上未调权重的对比实验Table 1 Comparative experiment of unadjusted weights on DukeMTMC-reID dataset %
根据文献[8-9],本文首先选择了三个分支:全局学习分支、局部学习分支、随机擦除分支。其中,全局学习分支强调对行人驱干和行人图片全局的学习,局部学习分支强调的是对行人局部以及图片局部的学习,而随机擦除分支的引入目的是在前两个特征学习分支上,增强网络对局部注意力特征和弱特征部分的学习,同时有助于缓解因行人姿势改变和重叠导致局部特征在训练卷积神经网络时被抑制的问题。全局学习分支的结构设计参照最基础的单分支网络,未引入任何加强特征学习的机制。而局部分支的设计,考虑网络随着特征分支数量的增加,提升对局部注意力的同时也会增加复杂度。经本文实验获知,单个分支相比,均分四分支的算法运算量比均分三等分的分支大,且尝试与其他分支组合的训练的过程中,模型收敛慢、训练不稳定,同时且算法效果也仅比三等分高零点几点精度。所以本文选择的是均分三等分的局部学习分支,在此基础上,为保证训练精度、缓解各个分支间训练时产生的干扰,在局部学习分支上又引入一个全局学习分支作为联合训练。第三个随机擦除分支参照局部学习分支也引入一个全局学习分支作为联合训练,包含掩膜用于对未遮挡部分学习的分支将对网络输出的一个batch的特征图进行操作。
确定分支类型后,在选择分支数量和类型的问题上,本文先在数据集DukeMTMC-reID上做了网络结构的对比实验,一是仅有单分支的网络结构:随机擦除分支、局部学习分支、全局学习分支。二是两个分支的组合:全局学习分支和随机擦除分支,全局学习分支和局部学习分支,随机擦除分支和局部学习分支。三是三个分支:全局学习分支和随机擦除分支、局部学习分支,四是在三分支的基础上增加全局学习分支的四分支网络结构,表1中未包含随机擦除分支和局部分支分别加在三分支的实验数据,一是因为开始训练时服务器因为内存报错,二是降低了训练的batchsize和epoch后与其他实验数据对比误差大。
从表1获悉,两分支和三分支的网络结构算法结果相比单分支的网络结构,其精度提到了至少10点以上,并且两分支放在同一网络都会在原有基础上提升算法效果,这侧面反映了分支在网络结构中具有互补的作用,随机擦除分支与全局学习分支学习到全局信息,并增加对局部和弱特征注意力。全局学习分支与局部学习分支的组合学习到了全局信息与局部信息。随机擦除分支与局部学习分支的组合在二分支的网络结构里效果最好,分析原因可能与随机擦除分支能缓解局部特征在训练时被抑制的问题,同时随机擦除分支也有助于网络学习弱特征和注意力的区域。因此两两分支放在同一个网络中,能互相增强彼此对特征的学习。虽然在三分支基础上增加全局学习分支的四分支结构的算法结果最高,但训练过程中,由于分支过多,导致网络收敛慢,测试部分耗时,最后的结果也仅比三分支的效果高0.11。综上所述,根据算法结果和训练难易,本文最后使用的是由全局学习分支、随机擦除分支、局部学习分支构成的三分支网络而不是四分支的网络结构。三个分支仅共享骨干网络部分,在训练过程中分别学习其他分支未注意到的特征部分,通过这样的网络设计,使得模型的注意力不仅仅关注行人的驱干部分,而是融合三个分支的注意力,增强网络提取特征的能力。在单个分支的对比中,局部学习分支获得的效果最好,这可能与网络越深越会注重区域的局部学习和监督学习本身会强迫网络不断地去获取具有强辨别力的特征有关。
2 多分支算法介绍
2.1 三个分支的介绍
由于ResNet-50在其他行人重识别算法中取得了良好的结果,所以在本文中采取的骨干网络是ResNet-50,其框架相比于其他网络,具有网络层数深、获取到的特征信息更为丰富,引入残差块、避免梯度爆炸和梯度消失的优点。在本文图1所示的算法结构中,与ResNet-50有所区分的是后面的输出分支被分为三个分支。在图1中,方块表示的是特征图,为了方便显示采取的是三维的立方体,从ResNet-50 stage1,2,3开始分开的三分支从上往下,分别是随机擦除分支(RE branch)、全局学习分支(Global branch)、局部学习分支(Part branch),在每个分支上继续编号,从上往下分别是R_0、R_1、G_0、P_0、P_1。

图1 算法网络框架Fig.1 Algorithm network framework
随机擦除分支(RE branch)包含R_0、R_1分支,在R_0分支上,数据通过ResNet-50 stage1,2,3后,进入到resnet的con4和conv5后,为了保留足够的信息,没有在res_conv5_1区块使用下采样,之后为防止过拟合会通过一个bottelneck,之后特征图会经过平均池化层,核大小为24×8,经实验验证,本文网络使用平均池化层优于最大池化,分析原因,平均池化层比最大池化层保留的特征信息更多,这有助于各个分支学习强调的特征内容。经过池化层,特征图再通过掩膜(mask),其掩膜比例经过多次试验调试确定为(1,0.33)。其中,随机擦除分支掩膜部分会对特征图像按照比例掩膜进行随机擦除,最后得到特征图像,再经过正则化、1×1卷积层后特征图维数会降维到256得到特征zp_0,之后通过全连接层得到特征zp_0_0,在整个过程中,全连接层不共享参数,每个分支到损失函数的路径也独立。
全局学习分支(Global branch)仅包含G_0分支,G_0与随机擦除分支的R_1、局部学习的P_0,在结构和设置的区别仅在于res_conv5_1区块使用下采样和没有引入bottelneck、池化层设置的核大小为12×4,而R_1与P_0的池化层核大小为24×8。在该分支,数据经历骨干网络后,通过平均池化层,从1×1卷积层输出特征fg_1,从全连接层输出特征fg_1_0。而R1分支是从1×卷积层输出特征fg_0,从全连接层输出特征fg_0_0。与R_1的构造一致的P_0分支,从1×1卷积层输出特征fg_2,从全连接层输出特征fg_2_0,
局部学习分支(Part branch)包含P_0、P_1分支,而P_1分支的数据通过ResNet-50 stage1,2,3、进入到resnet的con4和conv5后,也没有在res_conv5_1区块使用下采样,同随机擦除R_0的分支一样,也引入了bottelneck,通过核的大小为24×8的平均池化层后的特征图会被均分成三等分然后分别送往1×1卷积层分别获得特征fp_0、fp_1、fp_2,从全连接层输出特征fp_0_0、fp_1_0、fp_2_0。在算法测试部分,本文使用的是每个分支经过降维后的输出特征融合在一起的特征,如公式(1)所示:
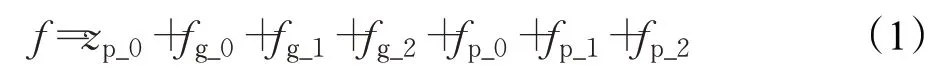
在图1的算法网络框架中,一共包含七个小分支的三个大分支的融合特征的过程如图2所示。在图2中,左图为数据集Market-1501的训练图片,分支上的符号为上文的特征图名称,分别相加后获得测试使用的融合特征f。
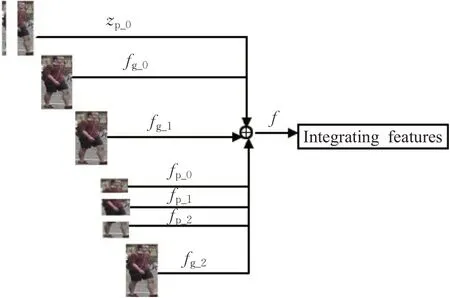
图2 融合展示Fig.2 Fusion display
表2为三分支与四分支网络结构输出的融合特征图维数对比。结合数据计算可得三分支网络结构(RE branch、Global branch、Part branch)加上全局学习分支的四分支网络结构的融合特征维数为2 048,同理在三分支网络结构的基础上加上随机擦除分支和局部学习分支,其融合特征维数分别在三分支融合特征维数的基础上增多512和1 024,由于大分支里又包含小分支而在本文设计里骨干网络后分支独立,因此增加一个大分支,除了增大特征图的维数还会增加池化层、卷积层、全连接层的数量,所以三分支结构的算法训练更快,测试时大约每秒处理2.8帧。而四分支网络结构算法在前期训练除了加上全局学习分支的四分支结构,其余的四分支算法如果不降低epoch和batchsize,就会在训练时出现问题。所以在实验的对比上,四分支只选了维数增加最少的三分支基础上加入全局学习分支的四分支网络组合。其在训练测试时大约每秒处理1.5帧。这从侧面反应了三分支的网络相比四分支测试速度更快,而网络结构也比四分支的更为简单,通过实验,也获悉训练时,三分支的网络比四分支更加容易收敛。
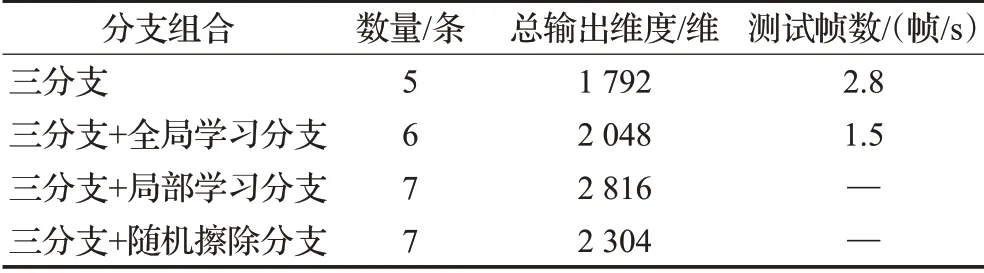
表2 分支组合维数对比Table 2 Comparison of branch combination dimensions
2.2 分支与损失函数
在全局学习分支(global branch)中使用同时使用Ltriplet[10]和Lsoftmax,网络结构中剩余的两个大分支里作为联合训练的全局学习分支R_1、P_0和其设置一样的损失函数。分别是Ltriplet和Lsoftmax,其损失函数如公式(2)、(3)所示:
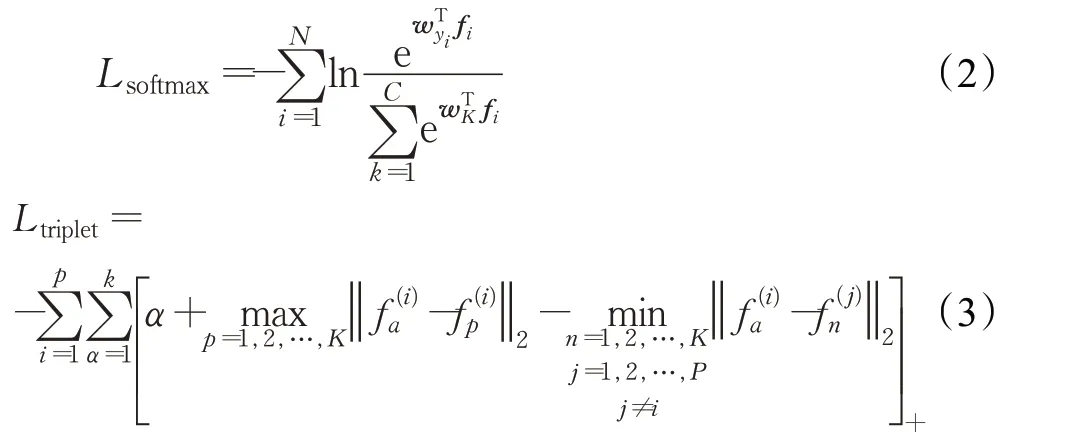
在公式(2)中,N代表训练的过程,C代表数据集,代表数据集中行人类别对应的权重向量,fi代表各个分支学习到的特征,包含图1中通过全连接层的特征。在公式(3)中,fa、fp、fn分别对应anchor的特征、挖掘到的正样本特征和负样本特征,都是从训练的minibatch获取,包含图1所示全局学习分支降维后输出的特征。p为每个batch训练时,抽取的行人数目,k对应训练中抽取每个行人抽取的图片数量。P_1分支的三个小分支和随机擦除分支的R_0分支失函数为公式(2)中的Lsoftmax。
2.3 最小二乘法的权重分配
多任务学习分支在训练过程中存在分支由于复杂度和学习率不同,从而导致分支间训练时有干扰现象。为缓解上述问题,本文在设计网络结构时,分别在随机擦除分支和局部学习分支额外引入全局学习分支进行联合训练。但还是存在一定的干扰性,因此本文又在损失函数引入权重分配。有算法[11]可对多任务学习网络进行损失函数权值调整,但本身具有不稳定性,同时也会大大提升网络复杂度。由于本文仅使用了两个loss,且公式(2)Lsoftmax的使用率远大于公式(3)Ltriplet的使用率,因此在调整权重时,为降低复杂度,本文仅关注Lsoftmax的权重值,而将Ltriplet的权重设为1,最后将总损失L定义为公式(4):
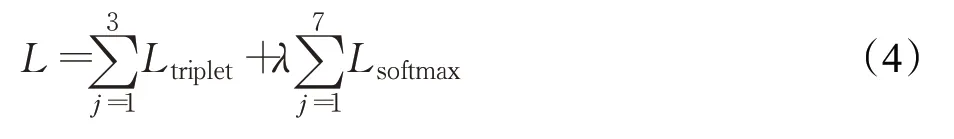
其中,λ为损失函数对应的权重,j对应本文的网络分支。
最小二乘法是在曲线预测中被使用广泛,同时高阶的非线性函数曲线易出现波峰。而本文选择的算法评判标准之一的mAP(mean Average Precision),其定义是将图片的相似度从高到低,统计从第一项到最后一项相同行人图片之间正确识别的平均概率。因此本文将mAP设为纵轴、将λ设为横轴,利用实验数据结合最小二乘法预测从低阶到高阶的mAP和λ的曲线,借此找到mAP的最高波峰对应的λ区域,然后进行loss权重λ的调节,通过这样的方式可减少不必要的工作量,其中误差公式如公式(5)所示:

在公式(5)中,mAP为本文通过实验获取的实际平均精度均值,yi为本文结合最小二乘法获得的预测值。
3 实验与结果分析
本文的实验使用的数据集是在行人重识别中具有代表性的Market-1501和DukeMTMC-reID,CUHK03-Label和CUHK03-detect。在实验指标上选择Rank-n和mAP,Rank-n指将图片的相似度从高到低排序,前n项包含被查询行人图片的概率。实验服务器GPU配置是英伟达1080Ti,框架为pytorch,为显示清楚,下文表格和正文中的数据集名称使用略写:DukeMTMC-reID(Duke),Market-1501(Market),CUHK03-Label(Label),CUHK03-Detect(Detect)表3为数据集详细信息。
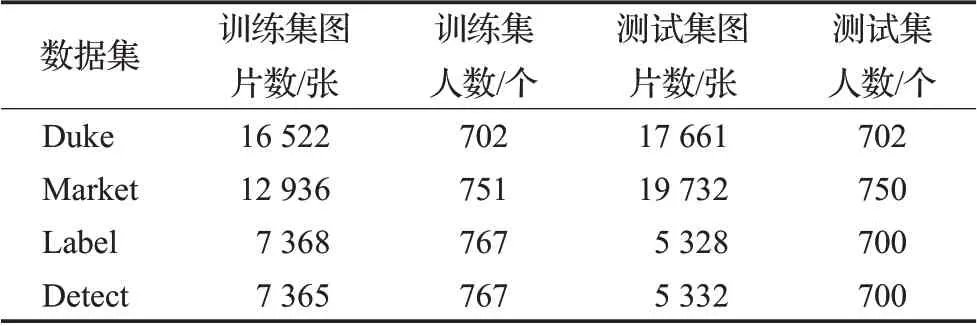
表3 数据集信息Table 3 Information of datasets
根据图3可知,数据集Market拍摄于夏日白天,因此数据集的光线比冬天拍摄的Duke和在过道拍摄的Label、Detect要亮,且场景简单,同时Duke的行人被遮挡现象更为严重,背景时而清晰时而与行人混杂,而Label和Detect存在较多行人侧面和背面的图像,同时根据表3,也可知,Detect的训练行人类型少于Label。

图3 Market、Duke、Label、Detect数据集对比Fig.3 Comparison of Market,Duke,Label,Detect dataset
因此相比之下,四个数据集的难度从易到难的排序分别为Market、Duke、Label、Detect。然后本文基于数据集DukeMTMC-reID随机地调公式(3)中的λ,分别2、5、10、12、15、20、30、40,然后运行算法获得九组mAP结果数据:75.24%、75.96%、75.58%、75.64%、74.87%、75.02%、75.66%、74.33%、73.12%,因λ大于20时,mAP下降显著,所以将横轴λ限定在0~20,同时为清晰显示,将mAP与λ的预测曲线的纵轴显示区域限定在74%~100%。因为曲线阶数越高,波动越明显,因此本文从低阶到高阶做曲线预测,即从1阶开始实验,直到预测的mAP曲线出现波峰为止,不同次数方程曲线拟合结果,从1到9阶的结果如图4所示。
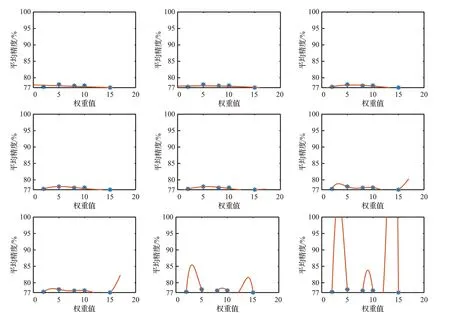
图4 最小二乘法预测曲线Fig.4 Least squares forecast curve
当预测曲线为8阶时,得到调试权重的建议即λ在2到5之间有最高的mAP出现,最后经过在两个数据集上的实验,最后使算法结果到达最佳的λ为3。综上所述,本文又分别在四个数据集进行上实验,为了提升,本文在数据处理部分加入了常用的加强算法Random Erasing[12],但精度不升反降。分析原因,可能是因为随机擦除了行人的关键特征,导致模型学习到的行人特征变少,影响正负样本的挖掘。最后本文加入Re-Rank[13]算法,精度再此提升,Re_Rank算法原理是在利用马氏距离和Jaccard距离,在模型训练完成后再进行挖掘正负样本的工作,以此更好地提升精度[13]。
为了进一步验证算法的有效性,本文又分别选取了四个算法作对比,分别是在基础网络结构上引入行人对齐的PAN[14],一个在全连接层引入奇异值分解的SVDNet[15],一个提出深层金字塔特征学习的DPEL[16],以及本文参考仅使用全局学习分支和随机擦除分支未加入局部学习分支的论文方法BDB[9],在数据集Duke和Market的对比结果如表4所示,在数据集Label和Deteted的对比结果如表5所示。
从表4获悉,本文的算法未加强也比前三个算法在mAP和Rank-1分别高出10多个百分点,相比参考方法[9],在两个数据集上,mAP分别高出了4个百分点和1个百分点,而经过加强的本文算法结果在数据集Duke、Market上mAP更是到达了88.11%和93.19%,Rank-1分别能达到93.14%、95.5%。
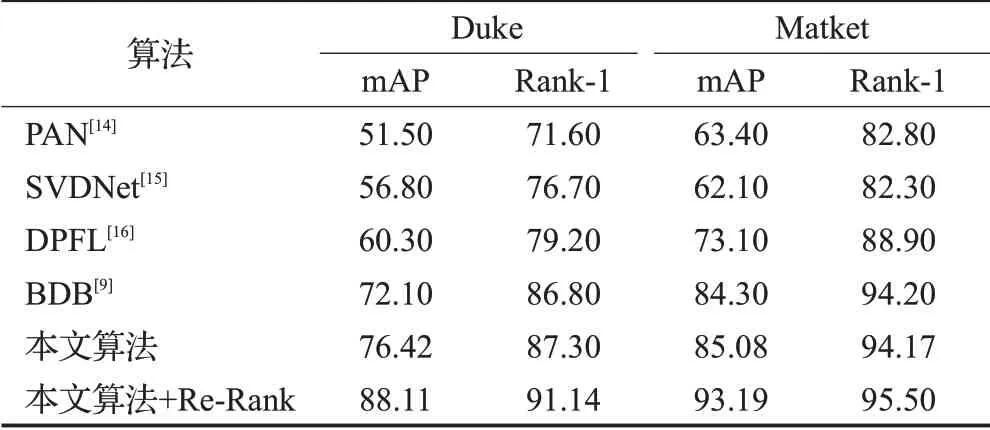
表4 Duke、Market数据集结果对比Table 4 Comparison of Duke and Market data set results %
从表5获悉,在数据集Label与Detect上,相比前三个算法精度提高了至少10个百分点及以上,而本文加入Re-Rank的算法精度更是提高了20多个百分点,在数据集Label和Detect上mAP分别到达了76.26%和74.86%,Rank-1分别到达了74.07%和72.57%。表5中,BDB[9]算法虽然在Label、Detect数据集上的结果比本文未加强的算法稍好,但本文的未加强的算法精度在Market和Duke数据集上的精度分别领先1个百分点和4个百分点,且Label、Detect数据集上,本文加强后的算法结果比其mAP,分别领先4.56个百分点和5.56个百分点。
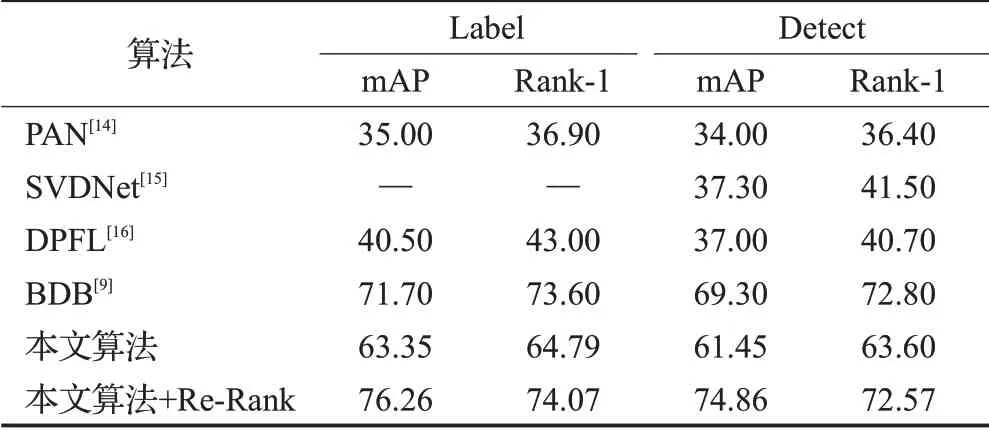
表5 Label、Detect数据集结果对比Table 5 Comparison of Label and Detect data set results %
4 结束语
本文提出了一种融合全局学习分支、随机擦除分支、局部学习分支的算法,并结合最小二乘法进行权重分配,相比对行人进行骨骼定点和增加行人属性的算法,无需预训练也不需对数据集进行额外的属性标注。最后在pytorch框架下,分别在三个数据集上,做了对比实验,其结果显示,本文融合全局学习分支、随机擦除分支、局部学习分支的算法具有有效性,在结果上相比参考算法,得到一定提升。在接下来的工作中,本文就加强网络对行人特征学习,将结合对齐框架进行下一步的研究。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
学生天地(2019年28期)2019-08-25
金桥(2018年4期)2018-09-26
数学物理学报(2018年1期)2018-03-26
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
智能系统学报(2015年4期)2015-12-27
中国卫生(2014年5期)2014-11-10
