
综合能源系统整体架构设计及负荷预测
2021-09-23 14:00胡瑞琨吴煜宇郑豪丰李思维贾睿杨国华
宁夏电力 2021年4期
胡瑞琨,吴煜宇,郑豪丰,李思维,贾睿,杨国华
(宁夏大学物理与电子电气工程学院, 宁夏 银川 750021)
0 引 言
综合能源系统(integrated energy system,IES)是一种在规划、建设以及后续运行环节,针对能源自产生到消费环节协调优化后构建的能源产供销一体化系统[1-2]。相较分布式能源系统而言,综合能源系统内部更多引入可再生能源提升供能多样性,并通过各类能量存储/转换装置提升综合利用率[3]。针对此类系统做出精确负荷预测,有助于提升整体调度水平与稳定运行能力,与此同时,负荷预测作为当前人工智能技术与能源系统衔接最紧密的领域之一,国内外学者对此展开了广泛探索:文献[4]将历史负荷数据作为输入,采用卷积神经网络提取高维特征,并将特征向量用于门控循环单元网络输入,引入Attention机制修正状态变量权重,最终完成负荷预测;文献[5]将深度置信网络与多任务回归相结合,深度置信网络用于提取抽象特征,在此基础上多任务回归输出预测结果。
综合能源系统规模及量级差异较大,若针对各个分立系统建模,普适性有限且难以推广,不利于整体预测。为此本文在剖析综合能源系统架构的基础上,引入能源节点作为最小单元划分能源系统,在此基础上就能源节点的负荷特点设计IES负荷预测模型。本文模型适配综合能源系统架构,可作为统一方案用于IES负荷预测。
1 IES整体架构设计
为实现综合能源系统整体互补协调,以能源节点作为最小单位设计IES整体架构。能源节点内部集成若干地理位置相近、供能呈现互补特征的供能系统,能源节点聚合构成区域能源网络。区域能源网络中的能源节点通过调度中心交互调度信息,控制能源节点能量交互水平。集群方式互联可规避节点间连接松散。方案设计思路见图1。
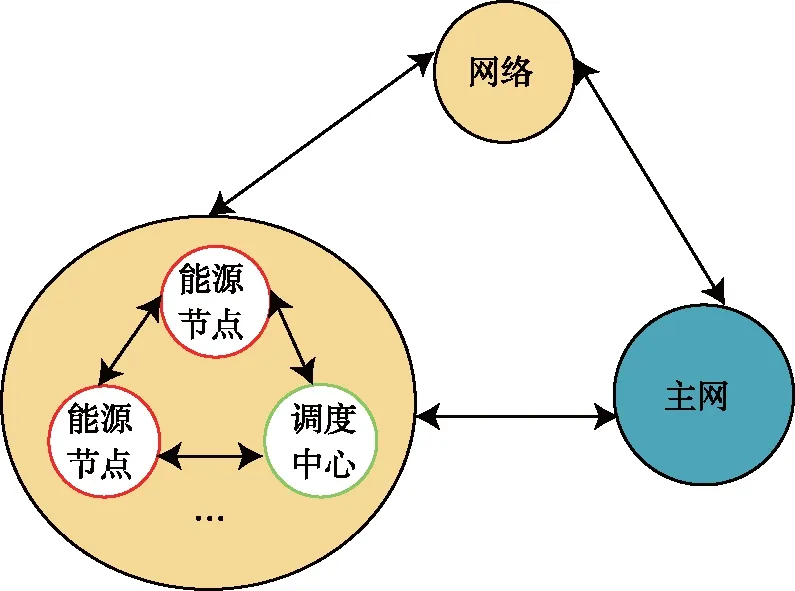
图1 能源节点及区域能源网络
能源节点可视作综合能源系统最小组成单元,电能供应由分布式电源供电、能源节点间电能交互、配电网直接供电三部分构成。其中,节点内部供能在电能供应环节占据主导地位。仅靠节点内部供能存在缺额时,采用能源节点间电能交互及主干电网直接供能两种形式加以补充。冷/热负荷则以冷热电三联供设备为代表的多能耦合设备保障,阶段调峰热能可由储热设备加以补充。夏季联供设备侧重制冷,而冬天则侧重于热力取暖。气类供应则分系统直接利用及应用电转气技术制备天然气两方面。当分布式电源出力水平较高,负荷水平有限且无法完全消纳电能时,电转气设备可利用这部分盈余电能制备天然气,这一部分天然气可回流至对应能源节点,降低整体的运行成本,整体结构见图2。能源节点可分为自治型、非自治型能源节点两类:自治型节点可视为区域能源网络中的非活跃方,主网直接供能作为辅助手段;当能源节点内部负荷等级或发电单元规模出现明显变化时,能源节点可由自治型能源节点转化为受、供能节点为代表的非自治型节点,有能力与外界发生能量交互,从而参与动态调度。
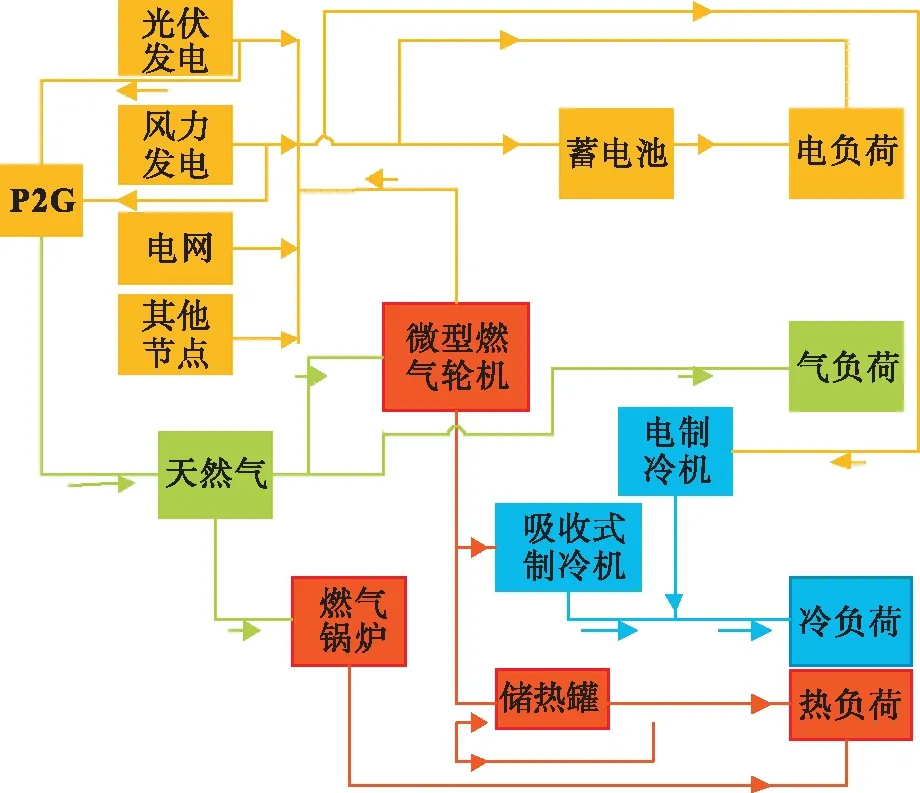
图2 能源节点内部结构
2 负荷预测策略
2.1 负荷特征
能源节点内部组成及负荷量级各异,负荷呈现横向及纵向周期性、强波动性、强历史相关性三大特点:
1)横向及纵向周期性。受日常用电习惯及工业用电场所生产特点的影响,能源节点的日负荷存在横/纵向周期性。以星期作为单位横向分析,同一区域能源网络下各能源节点每周的工作日期间负荷与非工作日期间负荷呈现周期性;以星期作为时间单位纵向分析,每隔7天对应日期的负荷存在周期性。
2)强波动性。能源节点自身规模多数较小,负荷波动性强。考虑到天气、节假日等因素影响,负荷特征也会呈现剧烈变化。
3)强历史相关性。通常相近日期因负荷组成及负荷类型具有强相似性,负荷曲线常呈现出相同的负荷分布规律,而相隔时间较长的历史负荷数据,由于长时间尺度下负荷组成与负荷类型会因天气、温度等自然条件及人类建设活动等因素发生改变,结果呈现弱相似性。
由此,在选取历史负荷数据进行负荷预测时,应尽量选择离预测日期较近的历史负荷数据作为参照,或提高相近日期历史负荷数据对结果的贡献度,从而达到更好的预测效果。综上,在针对能源节点内部负荷进行精准预测时,应根据负荷特性选取合适的预测方法,并克服负荷特性所带来的负面影响。
2.2 负荷预测策略
机器学习技术的迅猛发展,为负荷预测提供了崭新的解决思路,其中集成学习受到了人们的青睐。在集成学习中每个独立的小模型被称作学习器,这些学习器单独训练时受到训练算法限制,对数据的处理存在局限,学习器只在某一方面表现较为出色,而在针对其他情况处理则不是很完备[6],这些独立的学习器仅可视作与最终预测结果呈现弱相关度的模型,不能直接拿来进行预测。集成学习将此种弱相关度的学习器整合,对于某一学习器可能出现的预测错误,通过学习器间的互补与相互纠错,将结果优化,最终输出性能更为优异的结果[7],因此设计了一种基于Blending集成学习的IES负荷预测模型,如图3所示。
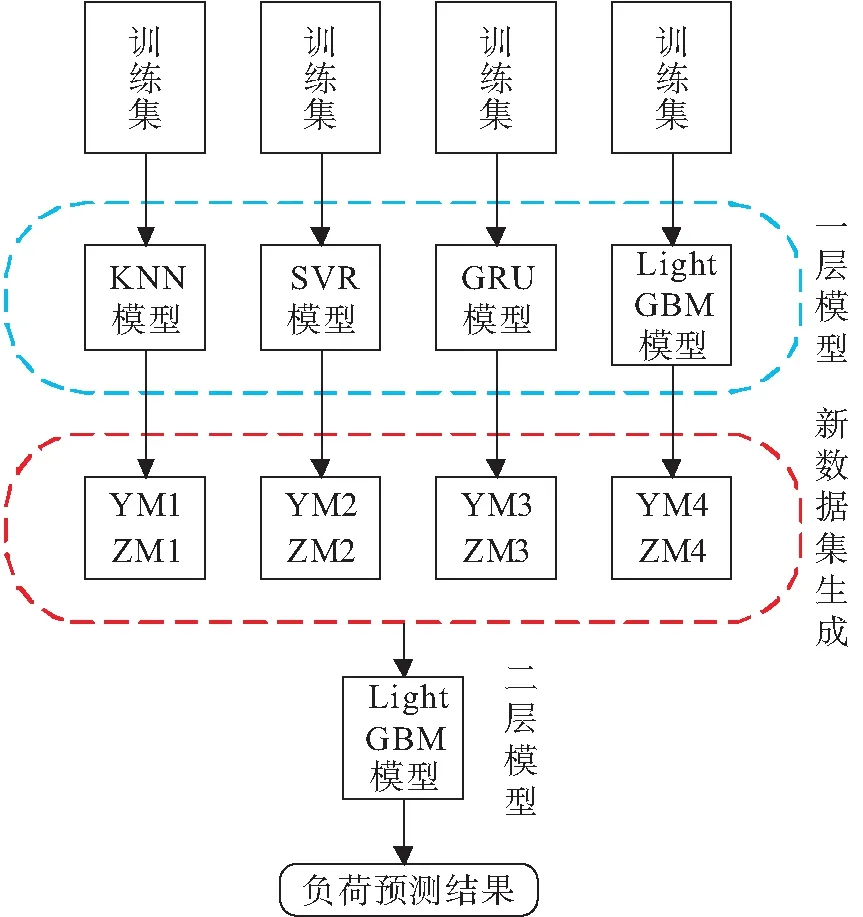
图3 基于Blending集成学习的多模型融合负荷预测模型
由图3可知,基于Blending集成学习的多模型融合负荷预测步骤如下:
1)整合电力负荷及天气数据得到负荷预测数据集。
2)把数据集按比例划分为训练集、验证集与测试集三部分。采用KNN、SVR、GRU、Light-GBM 4种算法训练第一层的学习器(M1-M4)。
3)将第一层训练得到的模型用于预测验证集,得到YM1-YM4 4组结果。将这一数据集用作第二层模型的训练集。
4)将第一层训练得到的模型用于预测测试集,得到ZM1-ZM4 4组结果。将这一数据集用作第二层模型的测试集。
5)采用LightGBM算法,训练第二层模型,测试后得到最终结果。
模型中整合多种子模型信息,以此获得更为优异的预测效果。第一层选取K最近邻判别分析法(K-nearest neighbor,KNN)、门控循环单元网络(gated recurrent unit networks, GRU)、支持向量回归机(support vector regression,SVR)、LightGBM 4种算法对基学习器加以训练,第二层选取LightGBM训练元学习器,在第一层基础上输出预测结果。
选取KNN、SVR、GRU、LightGBM分别对基学习器1、2、3、4加以训练。KNN用于训练基学习器时,K值的选择至关重要。K值较大时,泛化误差减小但训练误差增大,预测错误概率增加;K值较小时,训练误差减小但泛化误差增大,容易出现过拟合的情况;因此,在处理实际问题,依据样本特点先选择某一较小的K值,然后进行交叉验证不断修订最终选取某一合适的值。
GRU是一种在循环神经网络(recurrent neural network,RNN)及长短期记忆网络(long short-term memory,LSTM)的基础上构建的递归神经网络[6]。门控单元赋予循环神经网络控制其内部信息积累的能力,在学习时既能掌握长距离依赖又能选择性地遗忘信息防止过载[7]。
GRU的门控单元仅包含更新门与重置门两部分,针对长期状态的取舍用两个门结构加以实现。GRU这种简化结构使得整体结构更为简洁,在保证精度的同时加快了收敛速度。
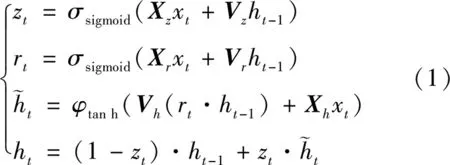
式中:zt、rt、xt—当前时刻更新门、重置门及输入状态;
ht-1与ht—隐含层输出状态;
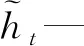
σsigmoid与φtan h—GRU激活函数;
Xz、Xr、Xh、Vz、Vr、Vh—权重矩阵。
SVR在处理样本数据时,需要根据样本数据的情况进行分类讨论从而得到最终结果。针对能源系统的负荷预测情况,由于训练集中的数据呈现非线性特征,故数据需要被映射至高维空间中,并求解对应的回归估计函数。
回归估计函数g(x)如式(2)所示:
g(x)=θ·φ(x)+P
(2)
相关最优化问题表示如下:
(3)
(4)
式中:θ—权值;
b—偏置;
τ—不敏感损失函数;
C—惩罚系数;

由于核函数可将线性不可分的数据映射至高维空间,使其线性可分,因此选取合适的核函数对提升模型预测精度具有重要意义。RBF核函数(radial basis function,RBF)泛化能力出色,受控参数少,故选取此种核函数映射样本数据。
LightGBM是已有梯度提升决策树 (gradient boosting decision tree,GBDT)的一种高效实现,是最新的一类梯度提升算法。LightGBM算法在已有梯度提升算法的基础上做出改进,其训练效率与准确率更高、占用内存更低,适用于大样本高维度数据。
LightGBM中主要包含单边梯度采样(gradient-based one-side sampling,GOSS)与互斥特征绑定(exclusive feature bundling,EFB)两种算法。GOSS在那些具有小梯度特征的样本上实行随机采样,保留部分小梯度样本a个,而梯度较大的b个样本则全部保留。在实际处理中,为减小直接去除小梯度样本对数据集本身分布的影响,计算信息增益时在小梯度数据的基础上扩至(1-a)/b倍,这样可保证小梯度样本参与到训练过程中,减少对数据集本身的影响。EFB则致力于采用特征捆绑的方式来减少特征。对于某些互斥特征可直接进行捆绑,而对于某些不满足完全互斥的特征,引入冲突比例这一参考变量,在冲突比例较小时对相应特征采取合并。通过以上两种方法的处理,数据量与特征量均得以减少,整体训练速度大大加快。
在决策树生长策略上,已有的算法多采取按层生长的方式,而LightGBM则采取了按叶子生长的策略,并附加深度限制。已有算法在采取按层分裂时,对同一层的叶子不加以区分,这一过程产生的无效搜索与分裂不可避免。按叶子生长的策略则解决了这一问题,分裂时选取分裂增益最大的叶子进行分裂。在相同的分裂次数下,按叶子生长的策略精度相较按层分裂的策略精度更高,然而这种按叶子生长的策略在处理实际问题时,容易长成较深的梯度树,产生过拟合的情况。在控制分裂时,引入最大深度限制,防止出现过深决策树的情况。生长策略对比如图4所示。
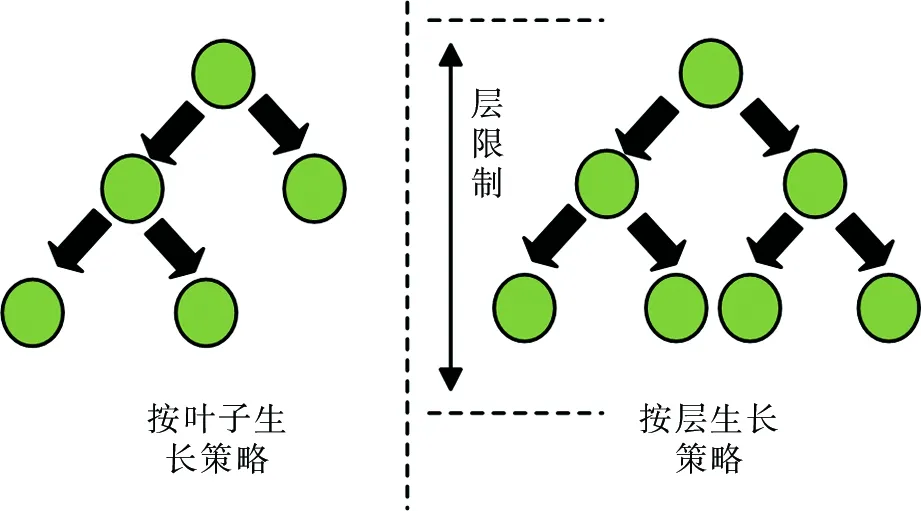
图4 生长策略对比
考虑到算法差异度越大,数据结构及数据空间多样性越显著,各类模型可取长补短,提升预测性能,通过采用Pearson相关系数这一指标衡量各基学习器的误差关联度:
(5)
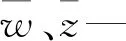
针对模型做出性能评价时,采用多种评价指标可有效反馈模型的波动状况及预测结果的好坏,因此,负荷预测模型常采用均方根误差(root mean square error,RMSE)这一评价指标反馈模型波动情况,采用平均相对误差(mean absolute percentage error,MAPE)这一评价指标来反馈模型预测的好坏。RMSE及MAPE表示形式为
(6)
(7)
式中:zi—某一时刻的实际值;
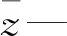
选取ARIMA模型作为对照,比较传统负荷预测模型与本文模型差异,如式(8)所示:
(8)
式中:p—自回归项数;
d—移动平均项数;
q—化为平稳时间序列需进行差分次数。
3 算例仿真
选取欧洲ENTSO提供的2017年1月至2018年12月间瑞士电力负荷数据及对应时刻天气数据作为训练数据,在此基础上训练并评价该模型。对应时刻天气数据源自Dark Sky网站。数据采样间隔以小时作为最小单位。依照具体平闰年的变动,每年数据采样点个数会有所不同。模型预测时段介于2019年1月至12月,预测目标为未来1 h电力负荷变化情况。本模型选取历史负荷信息、天气数据中的温湿度数据、时间数据作为输入。其中历史负荷信息涵盖前8 h历史负荷数据,时间数据按照对应月、日、小时、星期做出提取,分别作为特征输入。历史负荷数据中易被孤立的异常数据被剔除,视为缺失数据。所有的缺失数据依照默认方法填充。为使各类特征贡献分散稀疏,减少数据相互影响,采用独热编码对月、日、小时、星期等特征作离散化处理。
超参数设置及调优是模型性能提升及其重要的一环,针对不同的基学习器,本模型采用不同的调参方法寻找超参数最优组合:例如基学习器3可在网格搜索基础上结合交叉验证调参,基学习器4则可直接调用贝叶斯优化库对参数做出调整。
本文各类学习器超参数设置如下:
1)基学习器1 K值设为6;
2)基学习器2隐藏层设为2层,对应神经元数目分别为30,10;
3)基学习器3选取RBF核函数将负荷数据映射至高维空间,其系数初始值设为10-4,惩罚系数设为100;
4)基学习器4学习率设为0.1,树的数目设为500,叶子数目设为32,叶子节点最小数据量设为150,最小分裂增益阈值设为1,样本采样比例设为0.8,列采样比例设为0.8。
为寻求基学习器最优组合,需要就本文智能算法预测误差关联程度展开分析,其结果如图5所示。

图5 本文算法预测误差关联程度
由图5可知,由于各算法学习能力突出,难以避免在学习过程中引入训练数据本身存在的固有误差,故基学习器模型整体预测误差相关度较高,因此,在选择算法时应尽可能避免选取同源算法,例如在已选取GRU算法的情况下,尽可能避免选择LSTM算法,选取的4种算法训练机理差异显著,满足算法多样性要求,可在此基础上构建集成学习方案。
为评估所建模型性能,选取SVR模型及ARIMA模型作为对照,与所构建的Blending集成学习模型进行对比分析。考虑到不同月份负荷特征差异较大,选取2019年2,5,8,10月分别绘制负荷预测曲线。由于各月时长不同,为便于结果进行纵向对比,各月仅绘制该月前25天负荷预测结果。仿真结果如图6所示。
由图6可知,各月负荷曲线总体趋势差异明显,2月负荷水平较高,而本文Blending集成学习模型预测效果明显优于基于统计学原理的ARIMA模型。相较于SVR这类单模型而言,Blending集成学习模型对负荷波动更敏感,与真实值曲线拟合程度较好。
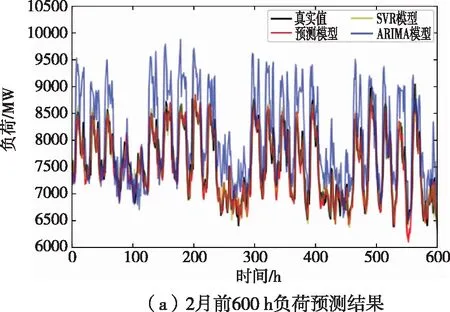

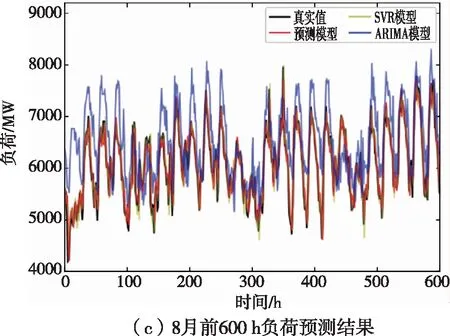

图6 2,5,8,10月前600 h负荷预测结果
采用RMSE、MAPE两类参数对模型误差加以评估,考虑到集成方式会对结果造成影响,设置一组基学习器仅集成LightGBM、SVR的对照模型。
由表1可知,本文所构建的模型精度更高,误差更小,优于单模型负荷预测方案。这是因为集成学习模型可有效整合各类算法的独特优势,单模型预测较差的部分可经多模型互补。模型误差也有所不同,提升基学习器多样性有助于提升精度。
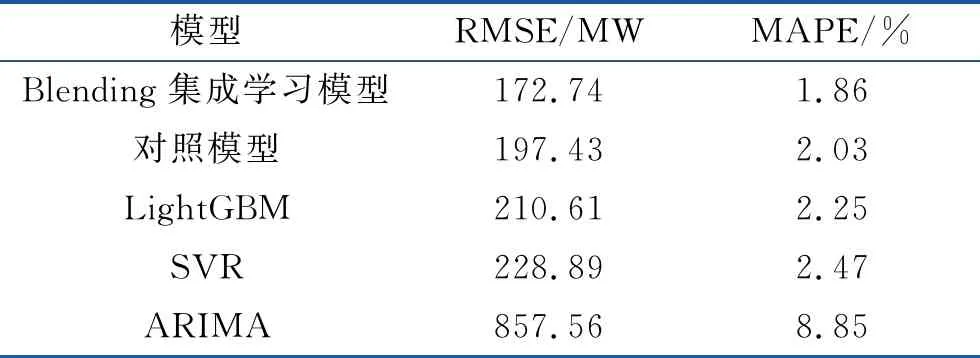
表1 模型误差对比
4 结 论
在已有结构设计的基础上,构建了基于能源节点的综合能源系统整体架构,并在已有负荷预测模型基础上,设计了基于Blending集成学习的IES负荷预测模型。该模型采用KNN,SVR,GRU,LightGBM 4种算法对基学习器加以训练,采用LightGBM这一算法训练元学习器。依照仿真结果,本文模型(RMSE=172.74 MW,MAPE=1.86%)预测效果明显优于ARIMA这一传统负荷预测模型(RMSE=857.56 MW,MAPE=8.85%)。
相较于LightGBM(RMSE=210.61 MW,MAPE=2.25%),SVR(RMSE=228.89 MW,MAPE=2.47%)等现有预测模型,Blending集成学习模型对负荷波动更为敏感,误差更小。通过设置基学习器仅集成LightGBM与SVR的对照模型(RMSE=197.43 MW,MAPE=2.03%),可知模型训练过程中提升基学习器的多样性与差异性有助于提升模型预测精度。
猜你喜欢
节能与环保(2022年7期)2022-11-09
纺织标准与质量(2022年2期)2022-07-12
煤气与热力(2022年4期)2022-05-23
长江大学学报(自科版)(2021年6期)2021-02-16
小学科学(2020年5期)2020-05-25
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
中学生数理化·七年级数学人教版(2016年6期)2016-05-14
山东青年(2016年2期)2016-02-28
燃气轮机技术(2014年4期)2014-04-16
