
基于LightGBM的南太平洋长鳍金枪鱼渔场预报模型研究
2021-09-22 07:12王德兴袁红春陈冠奇吴若有
水产科学 2021年5期
宫 鹏,王德兴,袁红春,陈冠奇,吴若有
( 上海海洋大学 信息学院,上海 201306 )
长鳍金枪鱼(Thunnusalalunga)是一种温带大洋性鱼类,主要分布于太平洋、大西洋和印度洋。在太平洋远洋渔业中,金枪鱼因其高经济效益及丰富的资源量位居捕捞量首位,其中长鳍金枪鱼占每年渔获量的1/3,并且近年来产量还在日益增加。目前,长鳍金枪鱼已经成为我国在南太平洋延绳钓渔业中的主要目标鱼种之一[1]。因此,提高长鳍金枪鱼渔场预报的准确率成为渔业研究的热点。
根据长鳍金枪鱼的生活习性,目前对其渔场的预报主要是结合海洋环境因子来进行。杨嘉樑等[2]采用分位数回归方法分析各水层以及整个水体各个环境因子与长鳍金枪鱼渔获率的关系,得到了长鳍金枪鱼栖息地综合指数(IHI)分布较高的海域。魏联等[3]采用BP神经网络方法对西北太平洋柔鱼(Ommastrephesbartramii)渔场进行预报,以海洋环境因子作为输入因子,得到了拟合残差最小的最优预报模型。陈雪忠等[4]采用一种随机森林模型,以海洋环境因子作为预测变量进行长鳍金枪鱼的渔场预报,在高单位捕捞努力量渔获量渔区达到了最佳精度,但是随机森林得出的预测结果无法解释其具体原因,还需使用其他方法配合来分析渔场分布的具体情况。范永超等[5]使用一元非线性回归方法对南太平洋长鳍金枪鱼中心渔场进行预测,预报准确率接近70%。
海洋环境因子是进行渔场预报的重要指标,但是日益增加的渔业数据规模,使得大量的环境信息更为复杂多变,变量间的关系难以描述[6]。轻度量化梯度促进机(LightGBM)模型[7]针对这种复杂的数据,提出了两种解决方法:梯度单边采样(GOSS)和独立特征合并(EFB),大大降低了处理样本数据的时间复杂度。针对可能影响渔场预报准确率的海洋环境因子和现有的观察数据,笔者选取了3个环境因子:海表温度(SST)、叶绿素a质量浓度(Chl-a)和海面高度(SSH)及3个时空因子:月份、经度和纬度,旨在利用LightGBM模型建立南太平洋长鳍金枪鱼渔场预报模型。
1 材料与方法
1.1 数据来源与处理
本研究海域为南太平洋,经、纬度范围为W 135°~E 110°,S 5°~S 40°,渔业数据为中西太平洋渔业委员会(WCPFC)(http:∥www.wcpfc.int)提供的2000—2015年的南太平洋延绳钓数据。数据包括年份、月份、经度、纬度和捕获量,其中时间分辨率为月,空间分辨率为5°×5°。海表温度和叶绿素a质量浓度数据来源于美国国家海洋和大气管理局(NOAA)环境数据库(http:∥www.noaa.gov)。海面高度数据来源于哥白尼海洋环境监测服务中心(CMEMS)(http:∥marine.copernicus.eu),该数据集中包含的数据空间分辨率为1°×1°,对其进行网格化处理,变成与渔业数据统一的5°×5°空间分辨率,便于后续计算单位捕捞努力量渔获量。
单位捕捞努力量渔获量(CPUE)作为渔业资源评估中的重要指标[8],在一个渔区(5°×5°)内的计算公式如下:
(1)
式中,i为经度,j为纬度,CPUE(i,j)表示(i,j)渔区内每1000钩的渔获尾数,Ffish(i,j)表示(i,j)渔区内长鳍金枪鱼总渔获尾数,Fhook(i,j)表示(i,j)渔区内投放的的延绳钓钓钩总数。
三分位数是统计学研究中最常用的方法之一[9],笔者也采用三分位数对渔区进行划分[4]。由于金枪鱼的生存习性导致在不同月份的单位捕捞努力量渔获量出现显著的差异,因此以整年的单位捕捞努力量渔获量进行渔区划分并不合适,而是以月为单位,以33.3%和66.7%分位点为界将每月单位捕捞努力量渔获量划分为高、中、低三类。
1.2 预测变量的选择
已有的研究结果显示,海表温度对长鳍金枪鱼渔场分布的影响极为重要。樊伟等[10]对单位捕捞努力量渔获量分布和海表温度等数据进行分析,结果表明,高单位捕捞努力量渔获量渔区主要分布在海表温度为16~22 ℃以及25~30 ℃之间的区域。闫敏等[11]通过对南太平洋长鳍金枪鱼渔场附近的叶绿素a质量浓度进行分析,结果表明,渔场最适叶绿素a质量浓度为0.02~0.08 mg/m3。范江涛[12]总结了各个月份单位捕捞努力量渔获量与海面高度的关系。由于长鳍金枪鱼的生活习性,渔场单位捕捞努力量渔获量呈现明显的季节性变化。综合考虑上述因素,本研究选取了3个环境因子:海表温度、叶绿素a质量浓度和海面高度及3个时空因子:月份、经度和纬度作为预测变量。
1.3 LightGBM渔场预报模型的建立
LightGBM属于自适应提升(Boosting)模型[13]的一种,是对梯度下降树(GBDT)的高效实现。随着科学技术的发展,渔业数据和海洋环境数据规模变得更加巨大,传统的自适应提升模型(如XGBoost[14], pGBRT[15]等)在效率上已经逐渐不能满足需求,导致这种情况的最主要原因是传统算法的实现需要遍历所有的样本数据,这个操作使得时间成本变得非常高。LightGBM针对数据的复杂性问题提出了两种算法:梯度单边采样算法和独立特征合并算法。
1.3.1 梯度单边采样算法
传统的自适应提升算法使用所有的样本点来计算梯度,但是根据文献[7],梯度大的样本点在信息增益的计算中往往起着最主要的作用,也就是说这类样本点会贡献更多的信息增益,因此为保证信息增益评估的精度,梯度单边采样算法在进行下采样时保留梯度大的样本点,对于小梯度样本点进行随机采样。梯度单边采样算法步骤如下:
(1)降序排列所有的样本点;
(2)按比例选取靠前的样本生成一个大梯度样本点集合;
(3)对第(2)步后剩下的样本按比例进行随机采样,生成一个小梯度样本点集合;
(4)将两个集合合并成一个样本集合;
(5)为小梯度样本引入一个常量乘数;
(6)使用上述得到的样本,学习一个新的弱学习器;
(7)重复(1)~(6)步骤直到达到规定的迭代次数或者收敛为止。
这样梯度单边采样算法在不改变数据分布的情况下大大提高了模型的学习速率。
1.3.2 独立特征合并算法
在渔场预报中,渔业数据和海洋环境数据往往有着特征量多且特征空间稀疏的特点,尤其是在稀疏的特征空间中,存在着大量互斥的特征(例如one-hot),LightGBM使用直方图(Histogram)算法对互斥特征进行合并,其基本思想是先将连续的特征值离散化成M个整数,并构建一个宽度为M的直方图(图1),根据直方图的离散值遍历数据,寻找决策树最优的分割点。相较于XGBoost模型的排序算法,直方图算法极大降低了时间复杂度,并且由于决策树属于弱模型,这种模糊的分割方法往往能达到更好的效果。
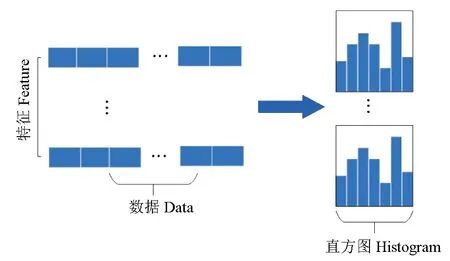
图1 直方图算法Fig.1 Histogram algorithm
1.4 模型精度检验
渔场预报精度是由模型的预报结果和真实的渔场情况对比得到的,根据文献[16],假设南太平洋长鳍金枪鱼渔场的实际渔区集合为C1,非渔区集合为C2,渔场预报模型预测得到的渔区集合为C1′,非渔区集合为C2′,则渔场预报精准率(Rp)如下:
(2)
同时使用召回率(Rr)和F1_Score作为模型评估的参考标准,具体计算如下:
(3)
(4)
1.5 试验设计
1.5.1 试验环境
本试验电脑的显卡为NVIDIA GTX 1060,CPU型号为Intel Core i7-7700HQ,操作系统为Windows 10,同时搭建了基于Python 3.6的scikit-learn机器学习库。
1.5.2 试验过程
试验过程见图2,试验数据为2000—2015年南太平洋环境数据和长鳍金枪鱼的延绳钓数据,其中2000—2014年的9860条数据按照数量比4∶1划分为训练集和验证集,2015年的数据作为测试集。
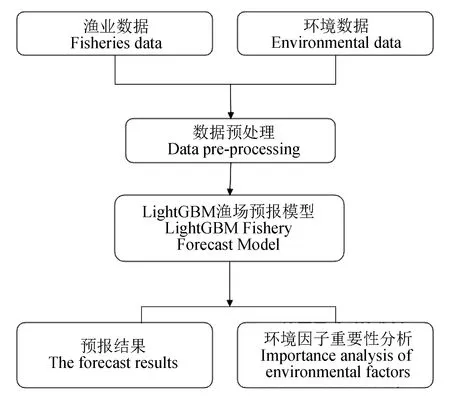
图2 试验过程Fig.2 The experimental procedure
对数据集进行预处理,将每月单位捕捞努力量渔获量按照三分位点划分为0、1、2三类,分别对应高、中、低产区,将处理好的数据输入到LightGBM模型。为加快模型的收敛速度,先设置一个较大的学习率Plearning=0.1,初始迭代次数ne=100,由于LightGBM模型使用的是带深度限制的Leaf-wise叶子生长策略,为了防止过拟合,叶子节点数nleaves应当小于2d,其中d为树的深度,同时使用早停策略中断迭代,设置early_stopping_rounds=5。在对参数进行初始设定后,调用sklearn中的GridSearchCV。
函数对参数组合进行网格搜索,并使用交叉验证的方式来减少偶然性。在运行多个参数组合后,得到了最优参数,部分参数组合见表1。
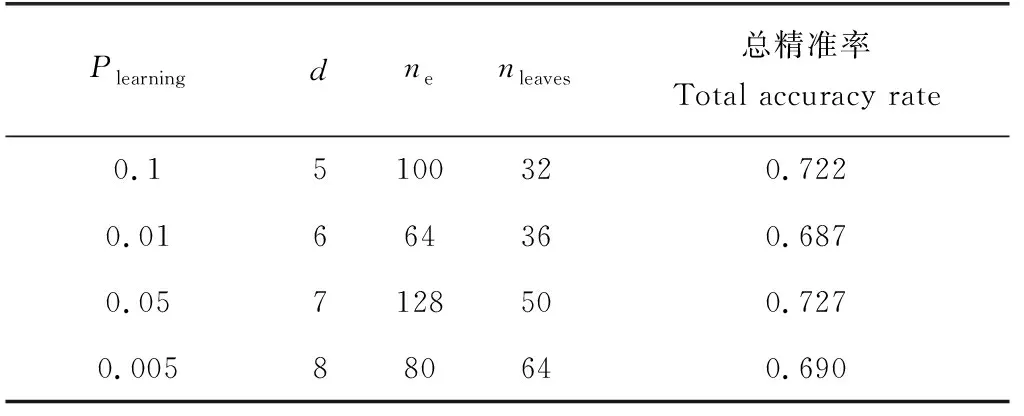
表1 参数列表Tab.1 The parameter list
在不同参数组合下,LightGBM模型均取得较好的结果,其中第3组为网格搜索后所得到的最优组合。为验证模型的有效性,笔者使用朴素贝叶斯、XGBoost算法和BP神经网络在相同的数据集和试验环境下做了同样的试验,并与LightGBM模型作对比。
2 结果与分析
2.1 不同模型的预测结果与分析
LightGBM模型在精准率、召回率和F1_Score上相较于其他模型均取得了较好的效果(表2),而且因为使用了直方图算法,时间复杂度仅为O(#M),其中M为特征值离散后的整数数量,相较于XGBoost的时间复杂度O(#data),获得了极大的提升,XGBoost在分裂特征时,通过遍历所有分割点来获得最优分割点,虽然能够很精确地找到最优分割点,但是在空间和时间的花销上产生了极大的损耗。
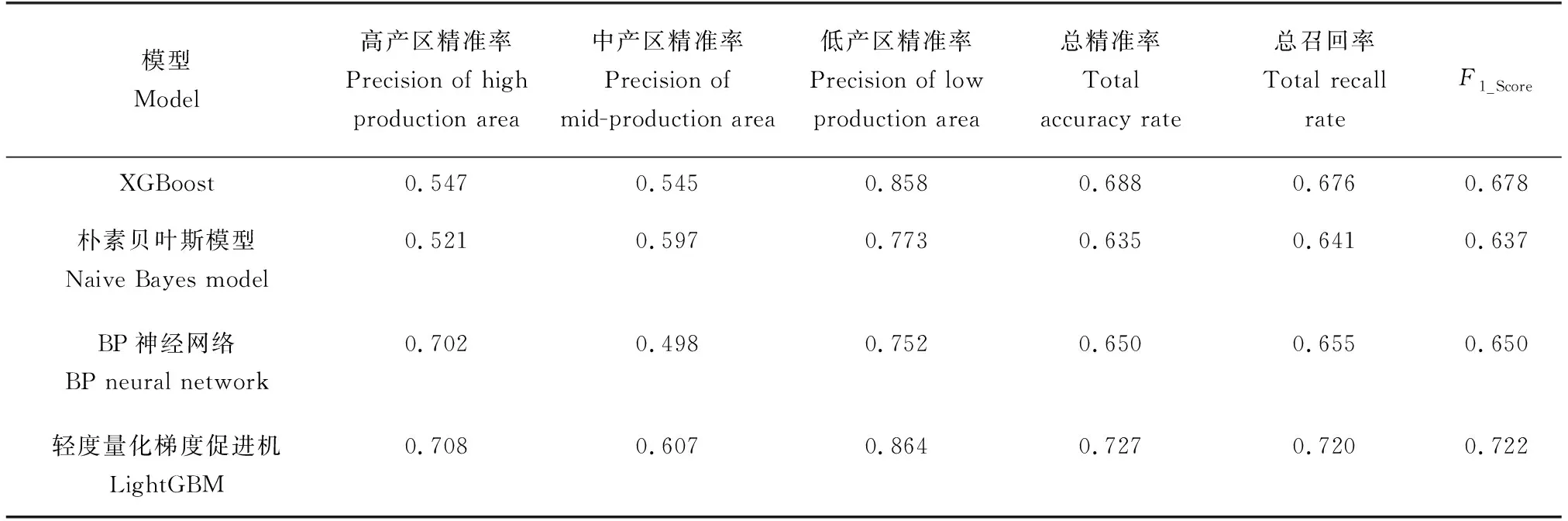
表2 不同模型试验结果对比Tab.2 The comparison of results in different model tests
朴素贝叶斯模型以数学理论为基础,通过先验概率,计算出某一对象所属的类别,即后验概率,计算过程中不考虑海洋环境因子和时空因子之间的相关性,虽然减少了计算开销,但是由于每个输入
因子都是独立的,因此无法获得输入因子的重要性指标。LightGBM模型通过调用sklearn中的feature_importances_方法对决策树分裂过程中每个节点的分裂增益进行统计,得到每个特征的重要性指标,能够对渔场的形成原理做出准确的解释,为捕捞业提供理论基础。BP神经网络作为一种“黑盒模型”[17],虽然实现简单,但是其权重具有无法解释性,无法分析环境因子和时空因子对渔场形成的贡献关系。
2.2 输入因子重要性分析
借助sklearn中的feature_importances_方法,得到了海洋环境因子和时空因子等输入因子对南太平洋长鳍金枪鱼渔场预报的重要性(图3)。由图3可见,海面高度是影响长鳍金枪鱼渔场分布的主要因素,其次依次为叶绿素a质量浓度、经度、海面温度、月份和纬度,根据文献[18],海面高度与海流密切相关,是一种反映流场的特征指标,因此海面高度是影响渔场分布的重要环境因子。目前许多研究表明,海面温度对于金枪鱼这种大洋性鱼类的影响至关重要[19-20],在XGBoost模型中以同样的输入因子计算特征重要性(图4),海面温度处于首位,其变化通常与海流边界和锋面相关,海面温度通过影响长鳍金枪鱼的生长、觅食以及洄游对渔场分布和变动有着直接的联系。在实际研究中,海面高度和海面温度息息相关,两者共同作用下充分指示了南太平洋长鳍金枪鱼渔场的分布和变动。
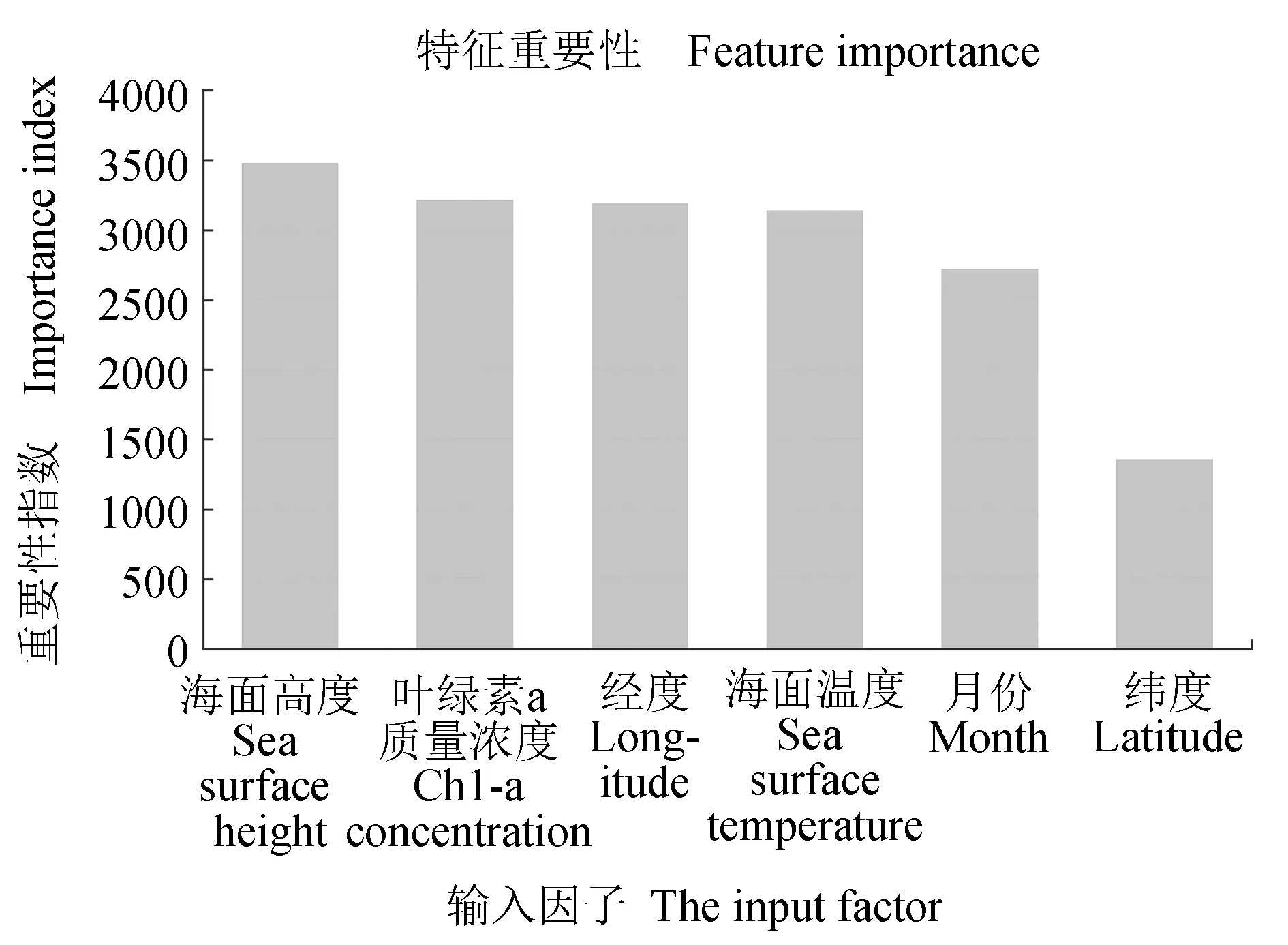
图3 LightGBM模型输入因子重要性Fig.3 The input factor importance in LightGBM model
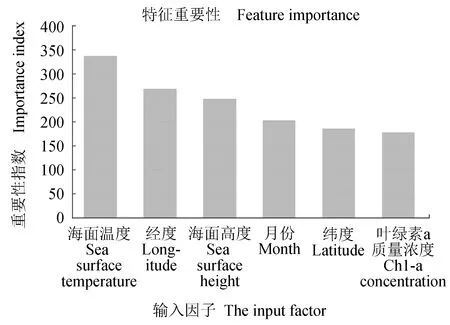
图4 XGBoost模型输入因子重要性Fig.4 The input factor importance in XGBoost Model
3 讨 论
3.1 单位捕捞努力量渔获量与环境因子的关系
本研究结果表明,海面温度和海面高度是影响渔场分布的重要因子,文献[10-11,19-20]也得到了相同的研究结果,两者共同作用下对金枪鱼种群分布起到了关键性作用,根据以往研究,南太平洋长
鳍金枪鱼渔场最适温度为16~22 ℃以及25~30 ℃[9,21],最适高度受季节影响,在不同月份呈现波动,但主要分布在0.8 m左右[11]。除了这两种关键因子外,叶绿素a质量浓度对渔场分布的影响同样至关重要[22],其原理主要是通过控制浮游生物数量的变化来影响金枪鱼种群数量和渔场变动[22]。研究表明,单位捕捞努力量渔获量高产区多分布在叶绿素a质量浓度0.02~0.08 mg/m3的海域中[11]。从渔场的形成机制来看,渔场分布主要受海流流场的影响,而海面高度和温度正是一种反映流场的特征指标,间接证明了本研究结果的准确性。
3.2 中产区不确定性
对于渔场分类,笔者采用按月对单位捕捞努力量渔获量进行三分位划分,但是在实际的预测中,由于各种复杂因素的影响(政策、大尺度海洋事件、溶解氧[22]、洄游路线[23]等),处于高—中、中—低渔区边界的渔场可能会被误分类从而导致中产区预测精准率明显降低。
3.3 预报模型的可行性
本研究基于LightGBM模型提出了一种南太平洋长鳍金枪鱼渔场预报方法,并利用2000—2014年渔业数据和时空数据训练得到的模型对2015年的长鳍金枪鱼渔场分布进行预测。预测结果见图5,预测的渔场位置与真实渔场位置存在少量误差,相较于其他模型,预报结果准确率与可信度较高。但是由于笔者所选取的环境因子多为海洋表层因子,无法从垂直空间上对金枪鱼渔场分布进行描述[24],在后续的工作中,需要获得更多的时空因子和环境因子来补充渔场环境信息,进一步提高渔场预报准确率。另外,利用LightGBM模型,可以得到不同输入因子的重要性指标,在以后的工作中可以依据重要性指标,对环境因子进行预处理以提高渔场预报精度。
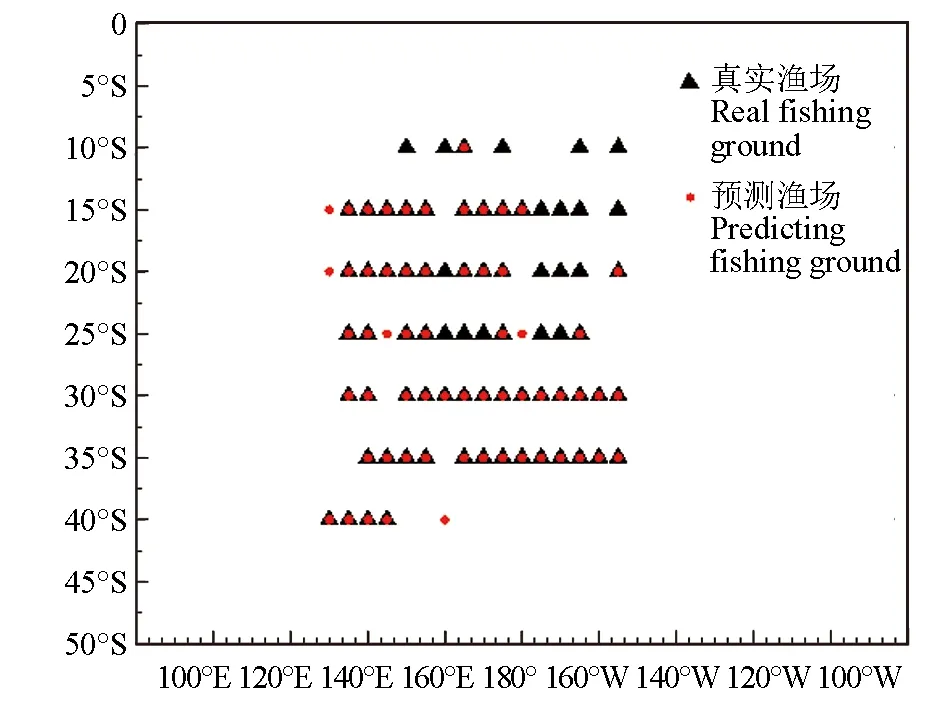
图5 渔场预测结果Fig.5 Fishing ground forecast results
4 结 论
笔者针对传统的渔情预报方法无法对环境因子重要性进行分析的缺陷,提出一种基于LightGBM模型的南太平洋长鳍金枪鱼渔场预报方法,并利用2015年的数据进行预报测试。测试结果表明,预测的渔场与真实渔场具体位置较为一致,相较于其他模型,预报结果准确率与可信度较高。同时结合XGBoost模型的预测结果,对各个输入因子间的重要性进行了分析,在随后的试验中,可以根据重要性指标进行参数的优化以及输入因子的替换等,进一步提高模型的性能和实用性。
猜你喜欢
大自然探索(2022年2期)2022-04-09
军事文摘(2021年22期)2022-01-18
阅读与作文(小学高年级版)(2021年8期)2021-09-12
大自然探索(2021年12期)2021-02-07
华人时刊(2018年17期)2018-11-19
电脑知识与技术(2018年20期)2018-11-15
金山(2018年8期)2018-11-09
数学学习与研究(2018年7期)2018-05-16
山东青年(2017年11期)2018-03-29
红蜻蜓(2017年11期)2018-03-09
