
机器学习在变压器故障诊断中的应用
2021-09-21 08:21马洪斌杨蕾娜
河北电力技术 2021年4期
马洪斌,杨 飞,杨蕾娜,张 冉
(国网山东省电力公司枣庄供电公司,山东 枣庄 277000)
变压器作为电力系统的重要组成部分,其运行状态决定了整个系统的安全稳定。一旦变压器发生故障,将带来巨大的经济损失。因此,变压器故障的有效诊断对保证变压器的安全可靠运行具有非常重要的意义。随着机器学习的兴起,越来越多的研究人员将机器学习应用到变压器故障诊断中,取得较好的效果。文献[1]提出了基于加权K近邻算法的变压器故障诊断,根据待分类样本在特征空间中K个最近邻样本中的多数样本的类别进行分类,因此具有直观、无需先验统计知识、无师学习等特点。文献[2]提出了基于油中溶解气体的支持向量机变压器故障诊断,有效解决了传统学习方法的“维数灾难”和“过学习”等问题。文献[3]提出了基于知识粗糙度的多变量决策树在变压器故障诊断系统中的应用,有效地简化了决策树,减少诊断信息的冗余性,诊断效率高,结果易于理解。
1 机器学习方法
机器学习通过对外部环境的信息和知识进行加工改造,使其成为有效的信息内容,学习是机器学习的核心,包括对信息的采集、接受监督和指导,同时还包括对学习的推理以及修改学习系统的知识库。
机器学习具有目的性、结构性、有效性和开放性。机器学习可以了解学习的内容,学习的行为具有一定的目的性。结构性中,可以系统地将知识的结构和组织形式进行修改和完善。针对有效性,机器学习系统学习的知识能够适应实践的需要,不断改善机器学习系统。开放性表现在机器学习能够与外部环境进行信息的交互和自身的进化。
1.1 支持向量机
支持向量机(Support Vector Machine,SVM)是在统计学习理论的基础上发展出的一种模式识别方法,是一种全局最优求解算法而不是求得局部极小值,该方法“以结构风险最小化原则”,根据实际需求对子集中的判别函数以及函数子集进行恰当选择。既可以保障学习的效果不会存在异常的状况,又可以保障样本的误差,且其独立测试集的测试误差仍然较小,具有很好的泛化能力。SVM具有坚定的理论基础,在人脸识别、文本自动分类等众多领域获得广泛的应用[4]。
1.2 vote集成学习
集成学习方法主要是由个体的学习器进行组合生成,通过对样本数据集的学习可以获得多个分类器,这些分类器具有多样性和准确性。根据个体的学习器之间是否是同一类型的学习算法,又可以将分类器分为“同质”和“异质”。对于个体的学习器的合并,是按照某种策略将个体学习器对新样本分类的预测结果综合考虑,从而得到一个最终的预测结果,见图1。集成策略主要有“平均值法”和“多数投票法”等[5]。
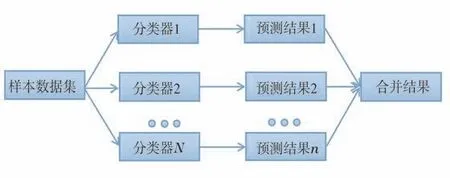
图1 集成学习
2 变压器故障特性
2.1 变压器油及固体绝缘产生气体机理
对于大型电力变压器,目前几乎都是用油来绝缘和散热,电力变压器油与油中的固体有机绝缘材料在运行电压下因电、热、氧化和局部电弧等多种因素作用会逐渐老化、裂解,产生少量的甲烷、乙烯、乙烷、乙炔等低分子烃类,以及一氧化碳、二氧化碳和氢气等气体,并多数溶解在油中。油中溶解气体的组分和含量在一定程度上反映出电力变压器绝缘老化或故障的程度,可以作为反映电力设备异常的特征量。通过对运行中的电力变压器定期分析溶解于油中的气体组分、含量和产气速率,能够及早发现电力变压器内部存在的潜伏性故障[6]。
2.2 变压器典型故障分析
变压器内部故障主要为过热式和异常放电式,其中过热式主要包括低温过热(<300℃),中温过热(300~700℃)和高温过热(>700℃),异常放电式主要包括低能量放电和高能量放电。
根据试验和变压器故障处理案例分析,油浸式变压器发生故障时产生的气体成分见表1。
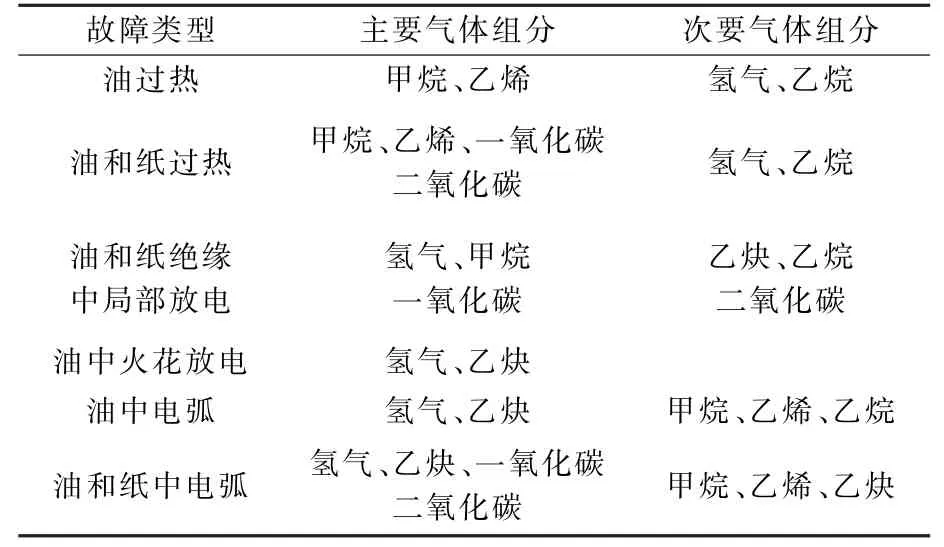
表1 油浸式变压器不同故障类型时产生的气体组分
通过分析,将变压器的故障类型分为中低温过热、高温过热、低能量放电和高能量放电。本文将变压器的4种故障类型与正常情况,共5种状态类型作为识别结果进行模式识别。
3 基于机器学习的变压器故障诊断
将机器学习与变压器故障诊断相结合,提出了故障诊断流程,见图2。
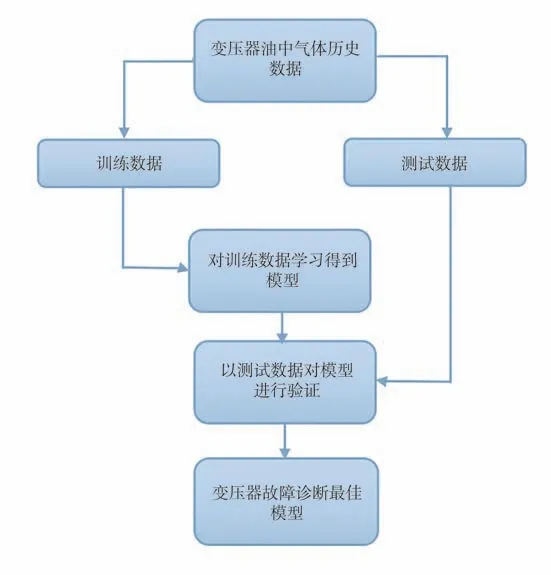
图2 基于机器学习的变压器故障诊断流程
对采集得到的变压器油中气体数据115组,分成训练数据(75组)和测试数据(40组),通过对训练数据进行学习得到故障诊断模型,以测试数据对得到的模型进行验证,判断模型的准确率。同时采用vote集成学习进一步对各个分类器进行组合,提升故障识别的准确率。
将甲烷、乙烯、乙烷、乙炔、氢气作为特征向量进行变压器故障模式识别,考虑到分类问题主要是针对数值型结构,气体组分为数值型不需转换,因此将变压器的状态正常、中低温过热、高温过热、低能量放电和高能量放电由字符型转换为数值型,分别标注为0、1、2、3、4,训练数据和测试数据见表2-3。
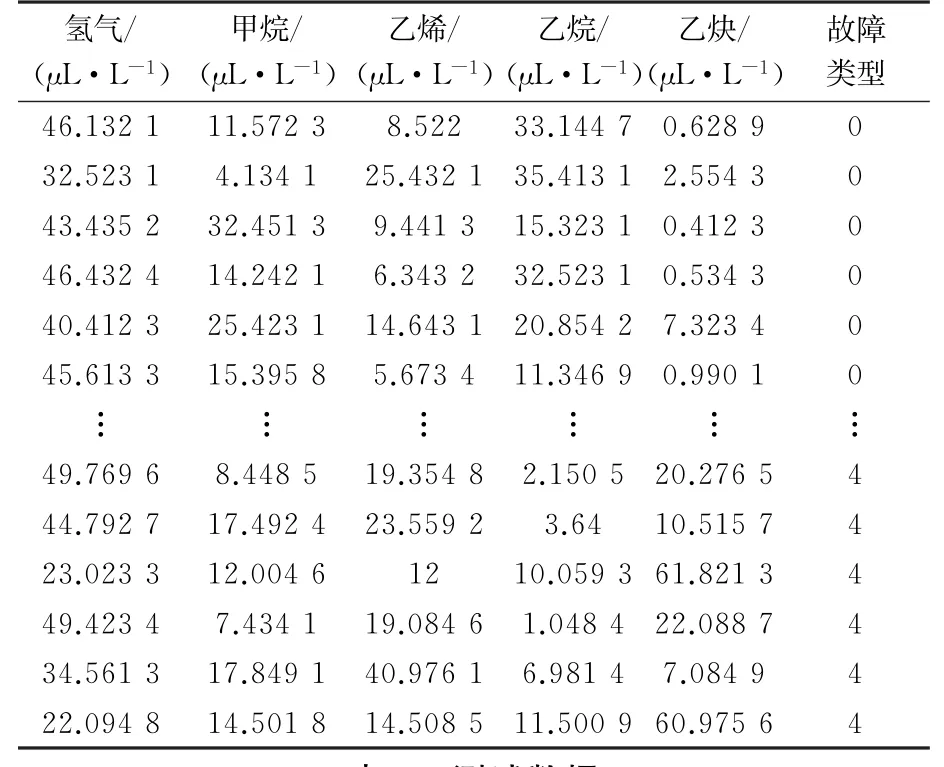
表2 训练数据

表3 测试数据
分别采用支持向量机、逻辑回归、最近邻分类、贝叶斯分类、决策树和随机森林对训练数据进行学习,得到故障诊断模型。利用测试数据对各个故障诊断模型进行模型验证,得到各个模型的识别结果见图3-8,蓝色圆圈表示的是实际的故障类型,红色圆圈表示的是预测的故障类型。
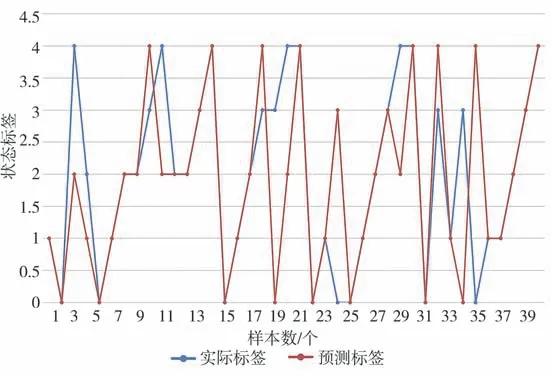
图3 决策树分类结果

图4 支持向量机分类结果
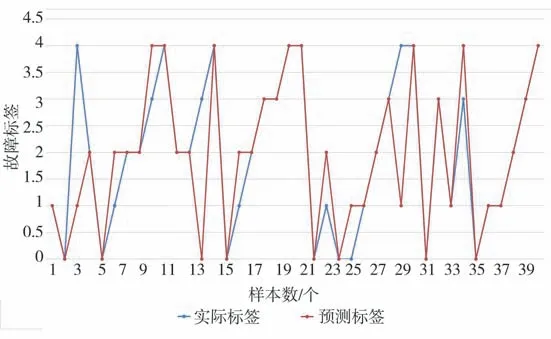
图5 最近邻分类结果
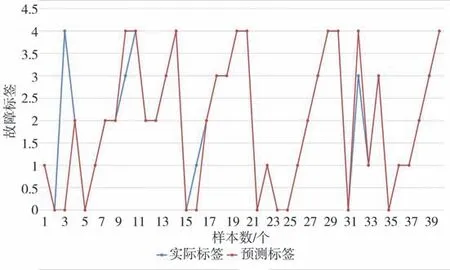
图6 随机森林分类结果
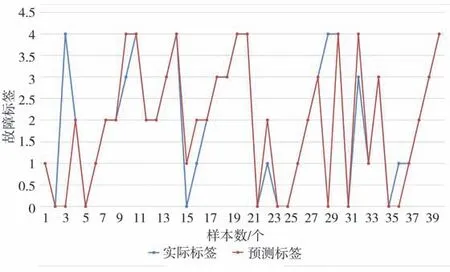
图7 逻辑回归分类结果
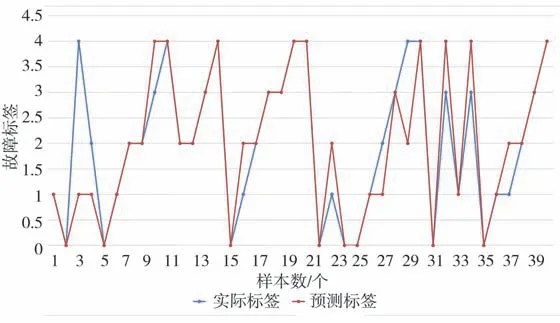
图8 贝叶斯分类结果
由40组测试数据对以上6个分类器的识别验证结果,可以得到各分类器的识别准确率,同时得到各分类器对每一种故障的识别准确率如表4-5所示。

表4 不同分类器的模式识别结果
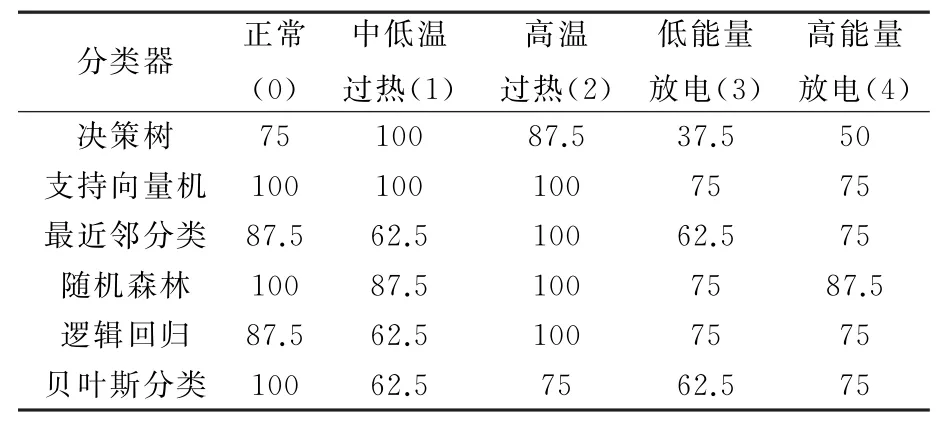
表5 不同分类器对不同故障的识别结果 %
将决策树、支持向量机和随机森林作为基分类器采用vote集成学习形成新的集合分类器,采用多数投票法的方式输出故障识别结果见图9和表6-7。

图9 vote集成学习识别结果

表6 vote集成学习故障识别结果

表7 vote集成学习对各故障类型识别结果 %
vote集成学习相对于单一的分类器,将同质分类器和异质分类器进行合并,其故障识别准确率得到提升,故障识别准确率为92.5%。
4 应用效果
通过实际现场中油色谱在线监测装置采集的5种特征气体进行变压器故障诊断,诊断结果见表8。

表8 220 kV主变压器故障诊断结果
第1组变压器的预测结果为中低温过热,通过实际的现场红外测温检测,发现主变压器本体下方连接处存在过热现场。第2组变压器的预测结果为低能量放电,通过对现场的变压器进行巡视检查,发现裸引线对套管导电管之间有放电的痕迹。
5 结论
基于机器学习搭建变压器故障诊断模型对变压器的故障类型进行识别,故障准确率由原来气体分析IEC三比值法的80%提高至90%,通过vote集成学习进一步组合单一分类器形成新的故障分类器,故障识别的准确率进一步提高为92.5%。采用机器学习方法对变压器进行故障诊断相比于传统的油中气体分析可以实现实时、随地的故障诊断,不需要进行现场油样采集和油化试验,大大提高了工作效率,减少了劳动时间。在实际变压器故障诊断中,具有实用性和可靠性,同时具有广泛的推广应用价值和实际意义。但目前只是通过简单的机器学习对故障进行诊断,存在一定的局限性,下一步将继续优化模型,增加训练数据量,增强模型的学习能力和适应能力,进一步提高故障识别的准确率。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
一重技术(2021年5期)2022-01-18
计算机系统应用(2021年2期)2021-02-23
电子技术与软件工程(2019年18期)2019-11-18
科学与财富(2018年30期)2018-12-28
电子制作(2018年10期)2018-08-04
电子技术与软件工程(2017年14期)2017-09-08
北京航空航天大学学报(2016年6期)2016-11-16
计算机应用(2016年9期)2016-11-01
体育科技(2016年2期)2016-02-28
