
基于计算机视觉的运动动作无标记识别技术研究进展
2021-09-20 09:15:22岑炫震顾耀东
上海体育学院学报 2021年9期
孙 冬,宋 杨,2,岑炫震,2,盛 博,顾耀东
(1.宁波大学体育学院,浙江宁波315211;2.塞格德大学工程学院,匈牙利塞格德6700;3.上海大学机电工程与自动化学院,上海200444)
当前,动作捕捉系统(Motion Capture System,MoCap)及相关技术已广泛应用于运动科学、生物力学以及康复医学等领域[1-6]。例如,可穿戴的惯性传感测量元件(Inertial Measurement Unit,IMU)包含了加速度计、陀螺仪和磁强计传感器等组件,可以进行三轴测量,基于人体运动的分层结构,分别量化加速度、角速度和运动方向[7]。由于轻便、无线和便于操作等特性,其已被成功应用于足球、游泳、高山滑雪、跑步等项目的动作识别[8-11]。然而,在竞技比赛中,实验控制条件的受限以及禁止在体表粘贴标记点和佩戴传感器的要求提示上述动作捕捉技术存在劣势[12]。
近年来,基于计算机视觉的无标记动作捕捉技术使得复杂环境下的人体动作识别(human activity recognition)成为可能。通过摄像设备进行无标记动作捕捉,远程获取比赛中的运动学信息,依托计算机视觉的机器学习(machine learning)算法,将检测到的人体活动表示为与特定动作相对应的波信号特征并提取到计算机终端,进而同步完成视频的自动分析、信息的自动提取以及快速反馈[13-17]。基于计算机视觉图像的动作分析首先需要预测或估计目标在图像序列中的位置和方向,通过识别连续图像中具有相同或相近特征的目标,进而实现对位移参数的实时追踪和获取[18]。在当前实际应用中,通常将人体结构简化为由无摩擦的转动关节连接而成的一系列刚体,便于机器的识别与追踪[19],然而事实上人体运动十分复杂,并且由于肌肉、肌腱等软组织的存在,并不能以简单的刚体模型进行描述。因此,精准跟踪和量化动态的人体姿态成为当前计算机视觉、机器学习以及运动科学等领域专家所面临的难点之一[20-22]。
此外,传统的机器学习算法对原始运动学数据的处理能力有限,无法有效地对不连续、有噪声以及存在缺失值的高维数据进行训练[23-24],并且总是需要对原始数据进行预处理,包括卡尔曼滤波(Kalman Filter)、傅里叶快速变换(Fast Fourier Transform,FFT)以及包括主成分分析(Principal Component Analysis,PCA)和 向 量 编 码 技 术(vector coding techniques)的降维等一系列步骤[23,25-28]。值得注意的是,与实验室环境下的三维动作捕捉分析相比,基于比赛现场的计算机视觉运动分析系统鲁棒性、准确性以及有效性的平衡依赖于算法的改良和硬件的优化[29]。近年来,结合深度学习(deep learning)算法进行人体姿态自动识别引起计算机视觉等领域专家学者的广泛关注[30]。
深度学习是机器学习的一个重要分支,其特点是具有更深层次的神经网络模型架构,其理念来源于人脑的生物神经网络[31]。该算法大多使用人工标记的图像数据来训练神经网络,随后将图像或视频输入经过训练后的网络,从而进行人体姿态、关节中心和骨骼位置的估计和识别[32]。与基于红、绿、蓝三原色(Red-Green-Blue,RGB)深度图像的微软Kinect摄像机相比,深度学习算法对摄像机与待测目标之间的距离及视频记录采样频率等约束较少[33-34]。当前,以深度学习为基础的方法已实现从二维RGB图像自动估计人体关节中心,并输出图像中的二维坐标[35]。同时,通过使用多台摄像机联动,同步多视角摄像机图像中的人体二维关节位置,并结合深度学习算法能够实现三维空间内对人体关节中心点和关键骨性标记点的定位[36]。基于人体三维姿态识别的深度学习计算机视觉研究正尝试使用一种算法进行姿势位置的估计和追踪,并且已有研究[37-38]探索了基于单目摄像机的三维人体姿态识别。
基于上述研究现状,本文通过系统回顾国内外基于计算机视觉的无标记动作捕捉技术,包括图像识别技术、机器学习算法以及深度学习算法在运动动作识别领域的应用现状,揭示无标记动作捕捉在运动检测和特征动作识别领域的潜在应用,如可实现日常训练比赛中运动员动作的无干扰识别与快速反馈,为教练员训练决策提供参考。
1 研究方法
1.1 文献检索策略
为确保纳入文献的全面性,本文的文献筛选过程依据系统评价和meta分析的PRISMA(Preferred Reporting Items for Systematic Reviews and Meta-Analysis)声明[39],对Web of Science、PubMed、Scopus、Google Scholar、IEEE Xplore、中国知网(CNKI)6个数据库进行文献检索。检索时间为2000年1月1日—2020年6月30日。检索中英文关键词运用“AND/OR”布尔运算符进行组合连接。英文检索词包括:(Sports OR Exercise OR Movement OR Motion OR Athlete OR Player OR Match OR Competition OR Game OR Training)AND(Movement OR Motor OR Action OR Skill)AND(Vision OR Computer Vision OR Machine Vision OR Camera OR Video OR Footage OR Motion)AND(Capture OR Recognition OR Detection OR Classification)。中文检索词包括:(运动OR运动员OR球员OR比赛OR竞赛OR训练)AND(运动动作OR移动OR行动OR技能)AND(视觉OR计算机视觉OR机器视觉OR摄像机OR视频OR镜头OR动作)AND(捕捉OR识别OR检测OR分类)。依据以上检索关键词依次对文献的标题、摘要进行筛选,随后提取文献全文进行评估。同时为避免遗漏,对检索文献的参考文献进行二次溯源检测。文献检索流程如图1所示。
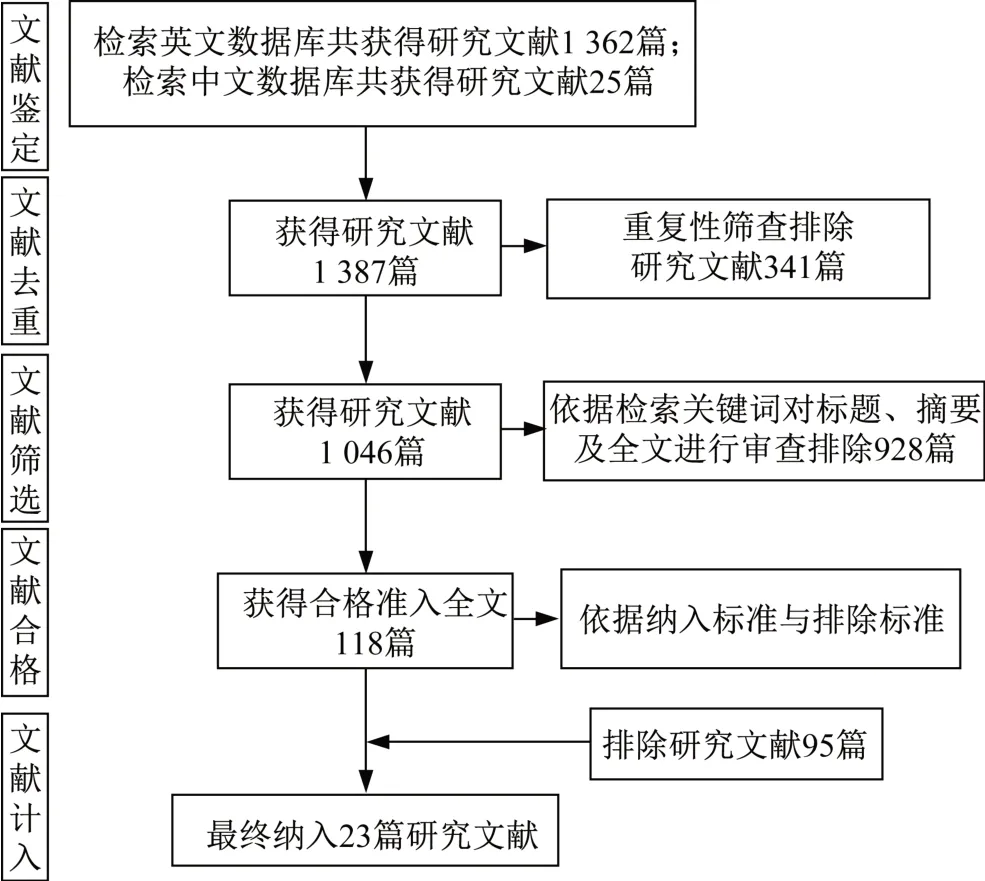
图1 文献检索流程Figure 1 Flow diagram of the study selection process
1.2 纳入/排除文献标准
纳入文献标准:①研究文献是公开发表的中文或英文论文;②研究聚焦具体的体育运动或动作,有计算机视觉输入作为模型训练数据库;③机器学习算法,数据处理过程定义清晰;④动作识别过程为半自动或全自动化。排除文献标准:①综述类论文;②研究不涉及具体的运动动作,或与临床或康复应用相关;③研究关注点为运动器材而非运动员本身;④数据处理过程和机器学习识别模型定义不明确。
1.3 研究信息筛选与提取
首先由2名作者分别对纳入文献的关键信息进行提取,使用Microsoft Excel 2016收集整理关键信息,不一致的信息由第3名作者综合评估判断。纳入文献关键信息包括第一作者、发表年份、运动类型/目标动作、样本量、受试者性别、运动员等级、摄像机数量、摄像机规格、采集频率、图像特征提取技术、动作识别技术、动作识别质量评估方法、图像数据训练与验证、动作识别精度表现14个指标。通过前期文献研究结果,发现受试者即采集对象的年龄对机器学习模型的识别精度几乎无影响,因此未将受试者年龄因素纳入考虑范围。动作识别技术包括将视频数据集转换为便于识别的预处理过程,以及将目标运动或动作进行分割的处理阶段(包括特征识别和提取技术,以及所采用的机器学习算法等)。
2 研究结果
2.1 文献筛选结果
本文共检索到研究文献1 387篇,其中,通过Web of Science、PubMed、Scopus、Google Scholar、IEEE Xplore 5个英文数据库检索获得文献1 362篇,通过中国知网(CNKI)中文数据库检索获得文献25篇。统一导入文献管理软件Mendeley(2020)去重后得到1 046篇文献,由2名作者通过关键词、标题、摘要、全文进行独立审查,结合前文制定的纳入与排除标准进一步筛选剔除,最终纳入23篇文献,如图1所示。
2.2 纳入文献实验设计
本文纳入研究文献均为基于计算机视觉的无标记动作捕捉技术,结合机器(深度)学习算法对多种运动项目及相关动作进行的识别和应用。在纳入的23篇文献中,涉及网球运动的有3项[40-42]、篮球运动的有3项[43-45]、体操运动的有2项[46-47]、拳击运动的有2项[48-49]、冰球运动的有2项[50-51]、高尔夫运动的有1项[52]、足球运动的有1项[53]、跳水运动的有1项[54]、排球运动的有1项[55]、空手道运动的有1项[56],1项研究同时包含游泳和网球运动[57],1项研究同时包含高尔夫和棒球运动[58],1项研究涉及步行、反向跳、掷球等基础动作[12],1项研究同时包含自行车和单板滑雪运动[59],1项研究涉及多种竞技运动组合,其数据集包含110万个经过标记的视频以及400余种不同的运动动作[60]。纳入研究多以职业运动员为研究对象(n=17),有16项研究报告了选取的运动员性别,其中14项研究[12,42-45,47-50,52-53,56,58-59]的受试者仅为男性,1项研究[46]的受试者为女性,1项研究[41]同时包含男性和女性受试者。目前,无标记动作捕捉前处理环节较为主流的方法是针对目标运动特征进行分类处理,例如将网球运动分类为发球、正手击球和反手击球3类[40-42],将游泳运动按照泳姿分为蛙泳、仰泳、蝶泳和自由泳4类[57,61]。基于深度学习算法的语义描述模型,能够实现对运动员训练动作、技术水平及疲劳程度的分类和预测,例如对体操鞍马旋转动作的分类等[47]。
2.3 计算机视觉图像获取途径
本文选取的23项研究包含了多种不同的实验设计及计算机视觉图像获取方式,如表1所示。传统的基于反光标记追踪的红外三维动作捕捉与基于计算机视觉的无标记动作捕捉流程如图2所示。有16项研究[12,40-44,46,50,52-54,56-59,61]的计算机视觉图像采集依靠主流的RGB摄像机进行,3项研究[47-49]采用深度摄像头对竞技运动场的三维图像进行深度感知和获取,此外还有4项研究[45,51,55,60]的摄像头类型未给出。从摄像头数量以及设置的角度看,10项研究[43-44,46-49,52,54,56,58]采用单目镜头完成全部图像的采集和获取,其中3项使用深度摄像头的研究[47-49]均使用单目镜头。1项研究[53]采用了16个环绕足球场的RGB摄像头,以“鸟瞰(bird'seyeview)”视角对全场运动图像进行采集。此外,共有11项研究[12,43,46,48-49,52-53,56-59]报道了摄像机的采集频率,从25帧/s到210帧/s不等。O′Conaire等[42]使用1个俯视镜头及8个围绕网球场边线的镜头对运动员的发球、正手击球和反手击球动作进行识别,但由于障碍遮挡等因素,仅有2个摄像头捕捉的图像可用于最终的动作识别分析。
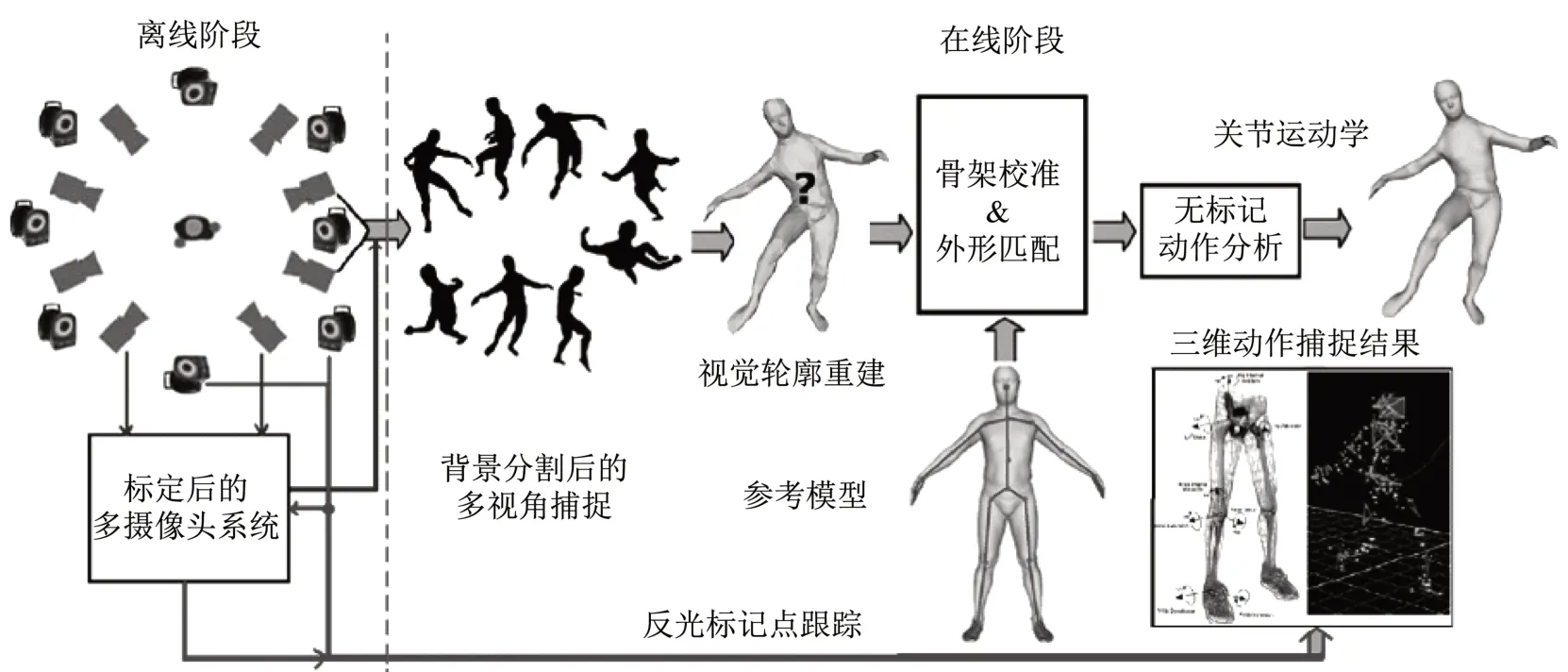
图2 无标记计算机视觉轮廓动作捕捉与反光标记红外三维动作捕捉流程[62]Figure2 Themarkerlesscomputer vision motion captureand themarker-based infrared three-dimensional motion capture
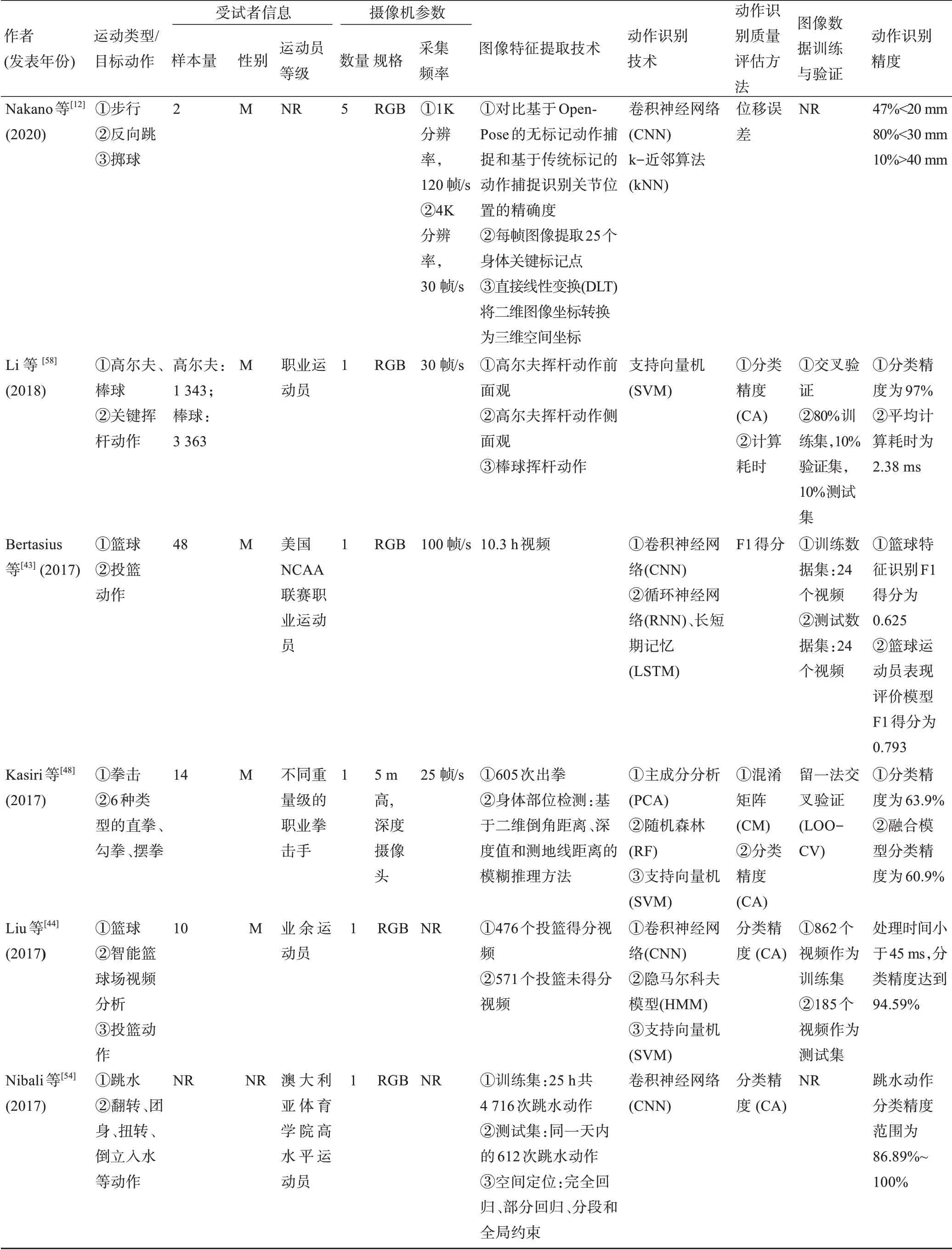
表1 基于计算机视觉的无标记动作捕捉相关研究关键信息提取(N=23)Table 1 Extraction of key information related to studies on vision-based markerless motion capture studies(N=23)
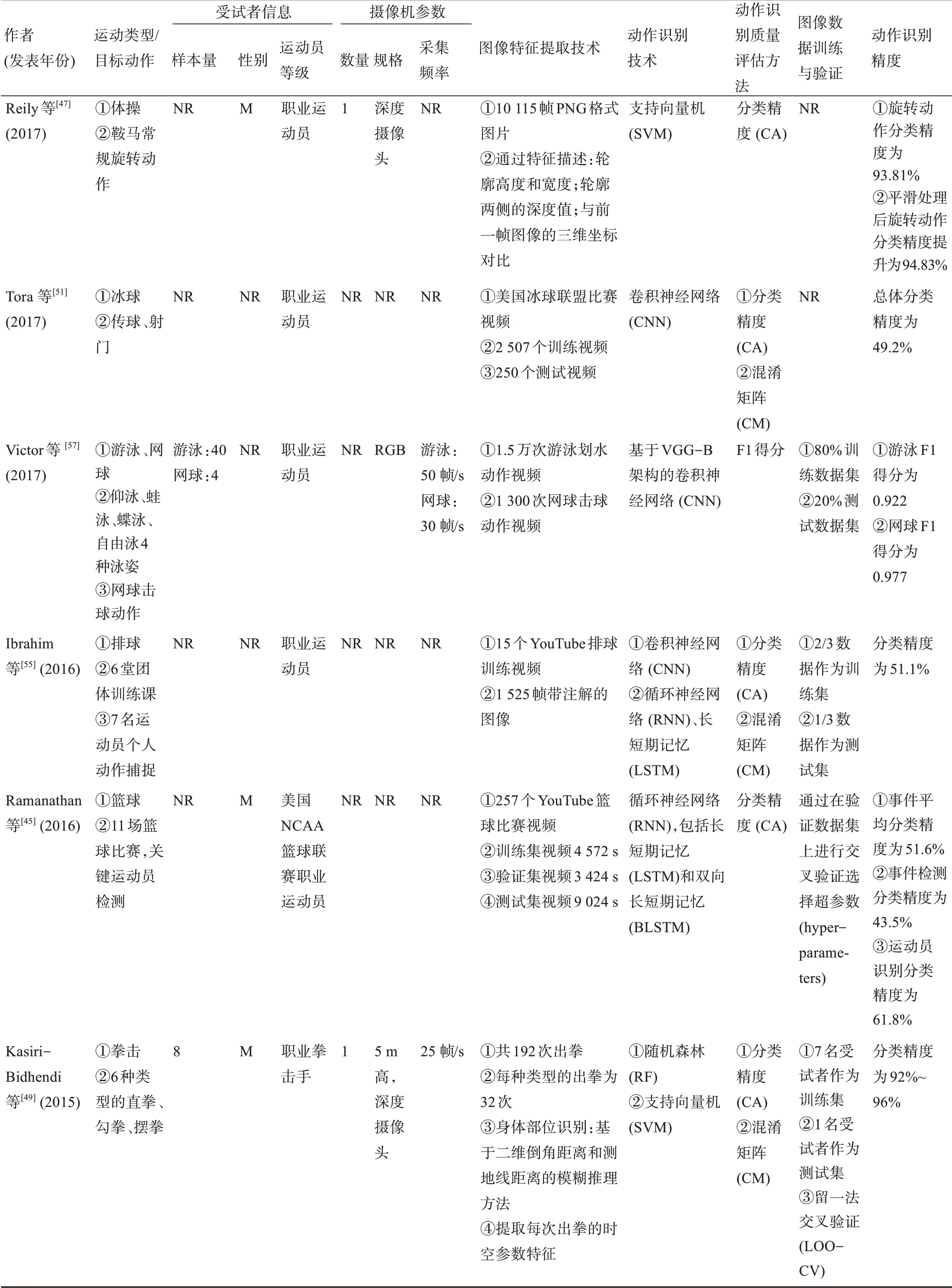
续表1
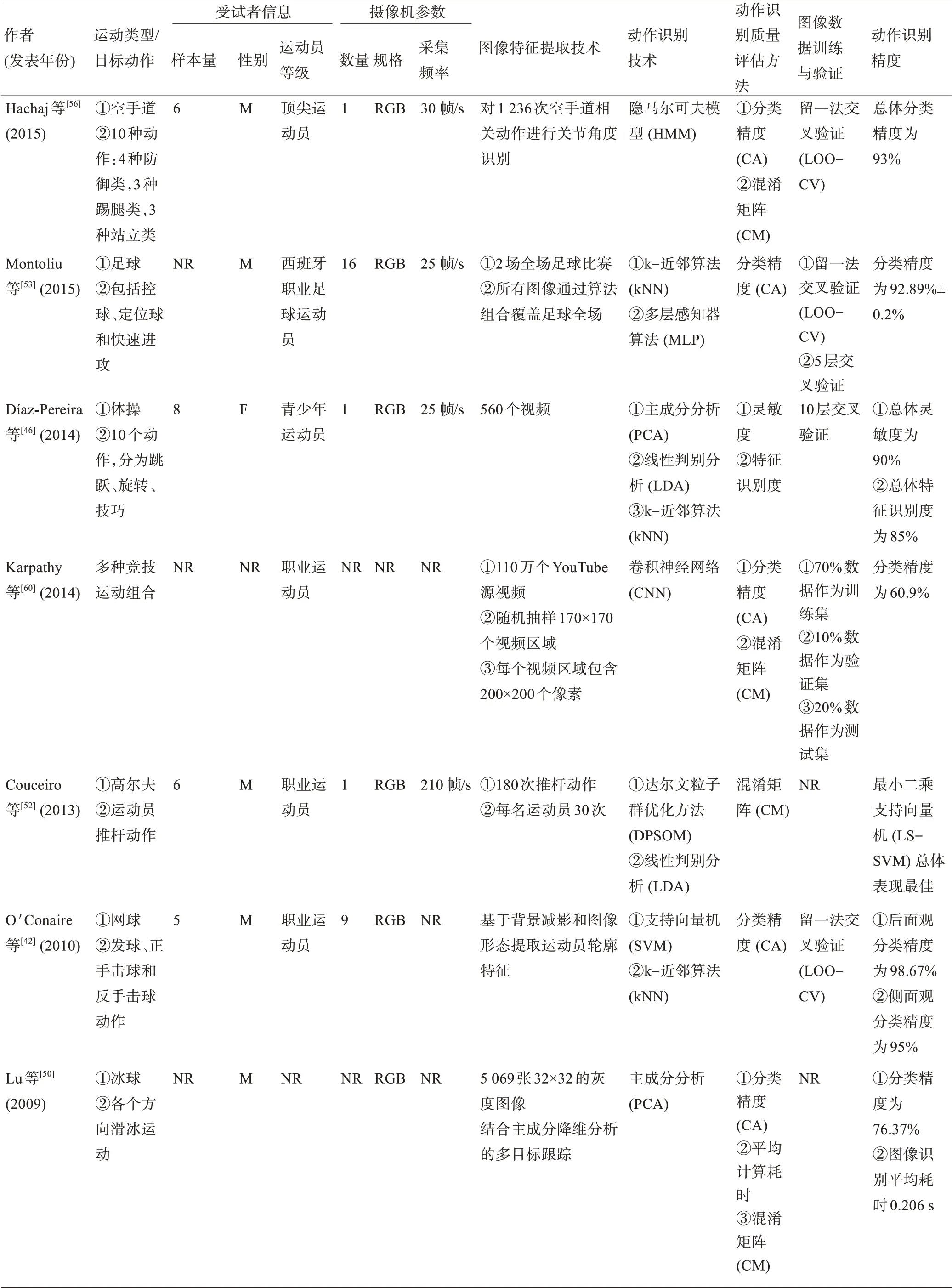
续表1
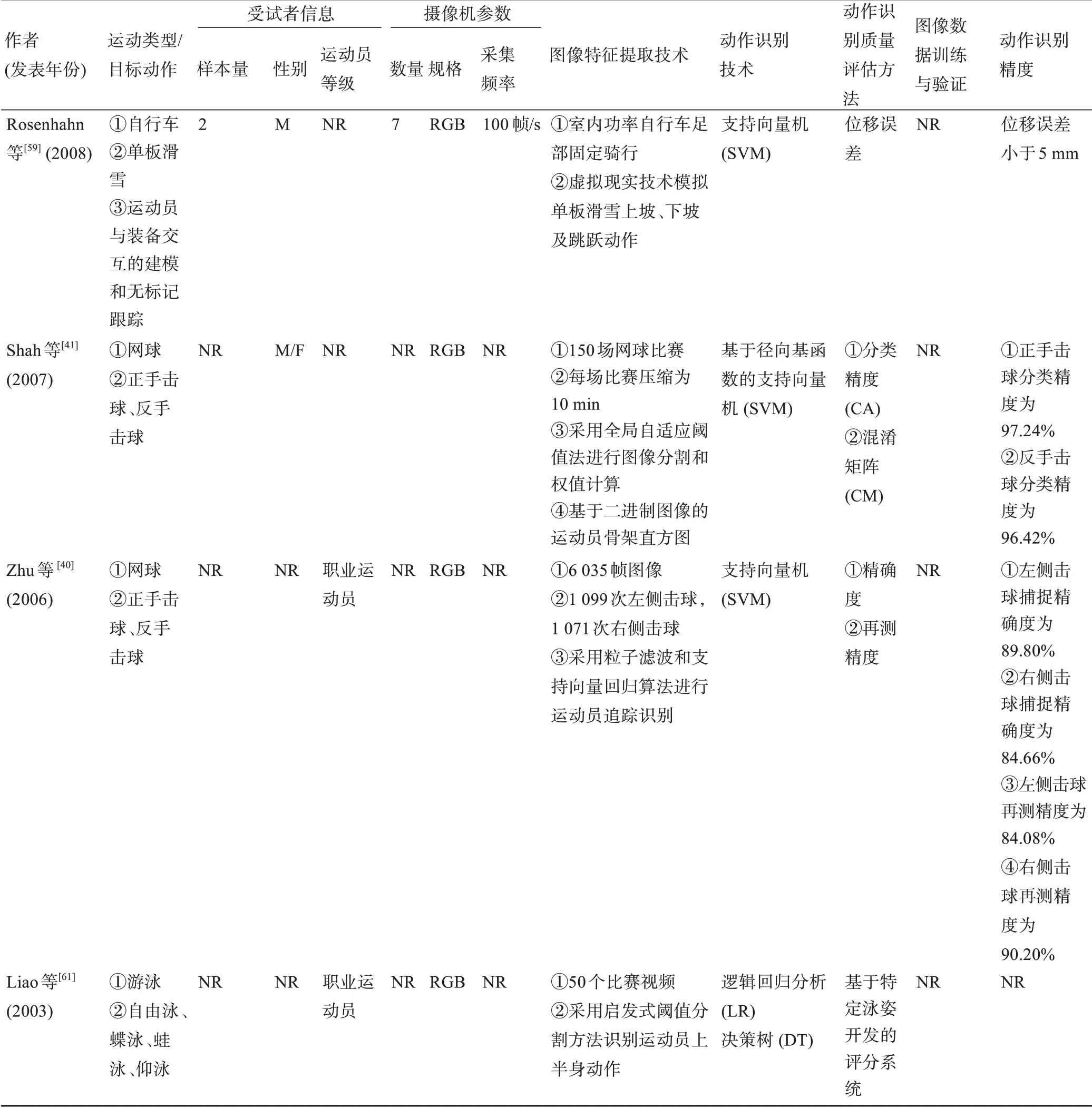
续表1
2.4 图像特征提取与动作识别技术
基于机器学习和深度学习算法的计算机视觉捕捉图像特征提取是本文涉及的23项研究采用的主流方法,主要体现在二维图像的转换以及输入图像数据的分割等处理步骤。纳入研究均报道了图像特征提取采用的关键算法和技术,其中单纯使用机器学习算法的研究[40-42,46-50,52-53,56,58-59,61]有14项,仅借助深度学习算法的研究[43,45,51,54-55,57,60]有7项,同时结合机器学习和深度学习算法的研究[12,44]有2项。
纳入文献中共有9项研究[40-42,44,47-49,58-59]采用支持向量机(Support Vector Machine,SVM)相关算法,其中:2006—2008、2012、2015、2018年各1项,2017年3项,共占所有研究的39%;2009、2013、2014、2017年共有4项研究[46,48,50,52]采用基于机器学习的降维算法,其中包括主成分分析和线性判别分析(Linear Discriminant Analysis,LDA);2010、2014、2015、2019年共有4项研究[12,42,46,53]采 用k-近 邻 算 法(k-Nearest Neighbour,kNN);2015和2017年共有2项研究[44,56]采用隐马尔科夫模型(Hidden Markov Model,HMM)相关算法,另有2项研究[48-49]采用随机森林(Random Forest,RF)算法;2003年有2项研究,其中1项采用逻辑回归分析算法(Logistic Regression,LR)相关算法[61],另外1项采用决策树(Decision Tree,DT)算法[61];2015年有1项研究[53]采用多层感知(Multilayer Perceptron,MLP)算法,2013年有1项研究[52]采用达尔文粒子群优化方法(Darwinian Particle Swarm Optimization Method,DPSOM)。在所有使用深度学习相关算法的研究中,采用卷积神经网络(Convolutional Neural Network,CNN)相关算法的研究[12,43-44,51,54-55,57,60]有8项,其中仅2017年就有5项,另外3项研究分别发表于2014、2016、2019年;此外,2015、2016、2017年有3项研究[43,45,55]采 用 了 循 环 神 经 网 络(Recurrent Neural Network,RNN)相关算法。
2.5 动作识别质量评估与精度表现
如表1所示,基于计算机视觉的动作识别质量评估方法大部分采用定量评估,其中采用分类精度方法(Classification Accuracy,CA)进 行 评 估 的 研究[41-42,44-45,47-51,53,55-56,58,60]有14项,占所有研究的65%。从识别精度表现角度评估,分类精度值越接近100%,说明动作识别精度越高。纳入研究的分类精度范围为49.2%~100%,其中分类精度值范围小于80%的研究[45,48,50-51,55,60]有6项,分类精度值范围在90%~100%的研究[41-42,44,47,49,53,56,58]有8项,有1项研究[54]的分类精度值范围在80%~100%。采用混淆矩阵(Confusion Matrix,CM)对模型动作识别结果进行可视化的研究[41,48-52,55-56,60]有9项。有2项研究[43,57]采用F1得分来判断动作识别算法的精确度,研究的目标运动为篮球,以及游泳和网球。2项研究[12,59]采用位移误差评估识别精度,其中:1项研究的动作识别位移误差小于5 mm;另1项研究基于OpenPose开源人体姿态估计算法的无标记动作捕捉,80%的位移误差在30 mm以下,但有10%的位移误差在40 mm以上,识别精度较为局限。
3 讨论
随着计算机技术、图像识别处理技术以及人工智能等相关算法的发展进步,全自动、实时、无标记的动作捕捉应是未来运动科学领域进行动作识别和动作技术分析的主流方式。相比于传统的实验室运动学测量分析,无标记动作捕捉技术的优势[15]:一方面能够摆脱场地等限制因素,降低测试前准备工作量;另一方面能够大大提升动作捕捉的效率,做到实时反馈甚至超前预判,为教练员的训练决策和运动员场上动作技术改进提供依据。目前,基于计算机视觉的无标记动作捕捉在竞技体育和运动科学领域的应用较少,相关识别技术、算法有待进一步开发,同时系统的鲁棒性、准确性、灵敏性也需要进一步验证。传统的基于红外摄像机的三维动作捕捉系统仅需要识别粘贴在受试者体表骨性标志的反光点,随后基于追踪的标记点三维坐标构建人体骨架模型。然而,在无标记动作捕捉领域,就需要借助相关的机器学习算法识别人体动作,构建人体运动学模型,完成连续图像中的运动学参数获取[17]。基于计算机视觉的无标记动作捕捉系统主要由4个组成部分:①摄像机系统;②人体图像识别模型构建;③图像特征提取;④机器学习识别算法的应用。在以上4个部分中,图像参数的捕捉和获取是离线(off-line)处理部分,图像特征提取、识别模型构建以及算法应用是在线(on-line)处理部分,机器学习识别算法的优化通常需要大量的图像数据训练以提升识别效果。下文结合计算机视觉无标记动作捕捉系统的4个组成部分以及动作捕捉精度进行具体分析,并提出当前无标记动作捕捉技术的局限性和未来研究方向。
3.1 运动图像捕捉及模型构建
本文纳入的研究多数采用单目RGB摄像机配置。与多个摄像机相比,单个摄像机输出的数据可以最大限度地减少需要处理的数据量,降低计算工作量。然而,由于遮挡和视角变化,单摄像机在细节特征捕捉以及多个体参与的团队竞赛中存在局限性,但多摄像机配置会增加处理时间和模型计算的复杂程度[63]。因此,需要对计算量和运动捕捉的精度进行有效平衡,使摄像头的放置位置和数量适应运动目标的生物力学特征及捕捉环境。本文纳入的研究大多是基于运动现场的实时动作捕捉,即需要快速反馈,因此使用便携式的单目RGB摄像头易于在动态环境中捕捉运动图像,节省校准和标定耗时。当前,用于图像捕捉的摄像机主要包含2种类型:①传统的识别图像颜色、亮度等特征的RGB摄像机;②能够识别图像中每个像素点到摄像头距离的深度摄像机[64]。相比于传统摄像机,深度摄像机受光线、阴影、反射和复杂背景的影响较小。可以同时获取图像颜色和深度值的RGB-D传感相机系统通过光线传输时间(Time of Fight,ToF)技术,采用红外线作为光源,记录光源强度信息以及光线从光源到图像中像素点的时间,能够对人体全身的三维姿态进行有效估计。目前该技术已应用在微软Kinect人机交互系统,能够感知三维环境中的人体姿态[65]。当前已有研究比较基于ToF技术的深度相机和基于反光标记的动作捕捉系统识别人体下蹲动作的运动学参数,但需要注意的是,深度相机较低的采集频率(通常为30帧/s以下)和对自然光线高度的敏感性以及多深度传感器之间的干扰可能会限制其在运动科学中的应用[64]。
无标记动作捕捉建立的人体模型与基于反光标记三维动作捕捉建立的人体骨架模型类似,均是由骨骼以及相邻骨骼组成的关节构成,通常采用骨骼长度、关节相对位移以及关节角度等指标量化模型特征[66]。基于无标记动作捕捉的人体模型构建通常需要识别图像中人体的轮廓和体积特征,再通过进一步的算法提取人体模型中的关节运动轨迹等运动学参数[67]。早期研究通常采用简化的圆柱几何形状近似表示人体模型的轮廓和体积特征,该模型以人体骨架为基础,在已知四肢长度和人体姿态的前提下,可以通过空间三维高斯函数(Spatial 3D Gaussians)排列简化的立体几何形态,将体积参数赋予骨架模型,从而生成人体模型轮廓[68]。这种识别模型仍然有其应用的场景,原因是该模型仅需要提取相对简单的图像特征,实现对人体位置快速和近实时拟合,但缺点是拟合精度有限,难以在精确定量的运动分析中应用[69]。目前,三维统计形状模型(3D Statistical Shape Model)方法已被应用于人体建模,该方法通过识别图像中的关键点,结合形状对齐、相似变换(similarity transformation)、主成分分析降维处理等操作步骤,使用数量较少的二维参数拟合图像中的人体形态[70-71]。但由于统计形状模型方法聚焦的重点是人体模型的表层形态,对模型底层的骨架结构能否实现精确模拟还需要进一步验证。现阶段基于计算机视觉的无标记动作捕捉大多构建的是简化后的人体参数模型,识别的有效性和准确度在很大程度上取决于识别算法的质量[72-73]。
3.2 基于计算机视觉的图像特征
数字图像由二维数字网格排列而成,其中每个网格中的数字代表该网格的颜色与亮度,即像素。确定像素与物体之间的关系是计算机视觉的一项根本任务,如何提取图像中的人体运动特征是实现无标记动作捕捉的核心环节和技术难点,而基于标记点的动作捕捉不存在图像特征提取和识别的问题[74]。无标记动作捕捉的首要任务是确定图像的范围和捕捉目标的位置。传统的捕捉目标提取和图像背景分割通常采用色度差分法,该方法将图像背景预涂为特定颜色,要求被捕捉目标使用色差较大的对比色,即可将目标轮廓从图像中快速分割出来[63]。对于图像背景复杂,无法使用色度差分法的情况,则可以使用背景减除算法,但该方法较容易受到阴影、反射、遮挡、光线变化以及捕捉目标之间的相互影响。图像轮廓的模糊为特征识别增加了难度,仅通过轮廓特征无法提供被观察对象与摄像机的距离参数、相对位置以及朝向等信息,可以通过增加摄像机数量,使用更为复杂的图像轮廓特征识别算法降低处理过程的模糊性[75]。
在摄像机数量充足的前提下,可以通过不同角度的图像轮廓拟合,实现捕捉目标的三维形态转换,获得图像轮廓视觉外壳(visual hull)[76]。该方法对多台摄像机的观察目标进行三维轮廓重建,基于不同方向角度捕捉到的二维图像,结合每台摄像机捕捉的视锥区域交点,形成三维的图像轮廓视觉外壳[75]。捕捉目标三维建模精确度和复杂程度的提升会导致运算时长和算法复杂程度增加。需要注意的是,图像轮廓的三维重建不能解决所有的图像拟合问题,还需要结合额外的信息输入以识别图像轮廓的位置与身体各环节的对应关系[29]。捕捉目标的轮廓识别是无标记动作捕捉的重要组成部分,Liu等[77]基于1台RGB摄像机对篮球投篮动作进行图像轮廓解析,相较于基于标记点的动作捕捉,图像分类精度达到了94.59%,实现了较为精确的图像轮廓识别,并且可进行多目标跟踪。使用图像轮廓识别技术可以提高鲁棒性,降低识别目标模糊程度,减少摄像机的使用数量并简化无标记动作捕捉流程。随着深度学习算法的应用,图像识别过程将得到进一步简化,使用单机位进行被捕捉目标的三维动作识别成为可能[78]。
3.3 基于机器学习的识别算法
用于识别图像中人体姿态的机器学习算法可以分为生成式算法(generative algorithm)和判别式算法(discriminativealgorithm),统称为监督式学习[79]。监督式学习算法在基于计算机视觉的无标记动作识别领域占主导地位,训练数据集的生成首先需要对视频进行手动标记和注释等前处理过程,如果是由多摄像机跟踪的多目标运动,前处理难度会显著增加。例如,Victor等[57]对高达15 000个游泳和网球视频进行了手动标记,耗时较长,工作量较大。生成式算法对基于训练数据的学习进行预测,模型参数可以根据图像数据生成假设,随后对该假设进行评估,通过进一步的迭代优化,从而确定最佳的预测匹配[80-81]。生成式算法包括朴素贝叶斯算法(naive Bayes)、隐马尔可夫算法、k-近邻算法等[82]。判别式算法直接使用图像数据推断模型参数,避免了反复调整人体模型参数适应图像的过程,因此也被称为无模型算法。与生成式算法相比,判别式算法处理时间较短,对异常值判别的鲁棒性更高。常用的判别式算法包括逻辑回归、支持向量机、决策树、线性判别分析、神经网络(Neural Network,NN)等[83]。
在基于生成式算法的无标记动作识别中,人体的姿势形态是通过将人体模型与从图像中提取的信息进行匹配确定的。例如,对于一组给定的模型参数(身体形状、骨骼长度、关节角度等),首先可以生成对应的模型预测参数,随后将预测参数与图像提取特征进行比较,从而计算单个“误差值”,该“误差值”可以表示假设值与观测值的差异程度[84]。有研究[75,85]将预测得到的三维网格投影到二维图像中,调整网格与捕捉目标轮廓重叠程度最大化,通过迭代最近点算法(Iterative Closest Point,ICP)可以实现图像视觉外壳与捕捉目标各顶点的匹配度对比。生成式算法的关键是对算法函数的准确定义,从而将特定假设与图像信息进行比对,如果算法函数失准,则无法实现最优模型参数的匹配,导致运动约束降低和出现异常值的概率增加[86]。构建针对较高图像噪声和较低模型配置的高鲁棒性算法函数较为困难,一方面由于生成式算法需要对模型参数进行合理可靠的初始推测,另一方面被捕捉目标需要在开始阶段以特定的姿势进行初始标定[87]。在没有人为干预的情况下,由于遮挡、图像噪声或其他因素导致的精度下降,算法函数是无法进行自我纠正和还原的。前期已有研究[88]尝试改进相关算法函数,或通过结合生成式算法和判别式算法来解决这一难点。当前,无标记动作识别主要通过机器学习算法实现,但该文纳入的9项研究采用了深度学习算法,其中基于卷积神经网络(CNN)算法的总体计算用时最短,在相同硬件条件下的计算量更少,因此被其中的8项研究所采用。作为判别式算法的主要组成部分,深度学习将随着硬件设施的提升、数据量的扩大而得到越来越多的应用[31,89]。
3.4 无标记动作捕捉精度
无标记动作捕捉的精度表现可以通过可视化的模型预测结果与真实测量结果之间的比较进行量化,其中分类精度是最常使用的量化方法,其次是混淆矩阵。上述方法能够较为清晰地呈现模型预测结果与实测结果之间的差异,从而呈现模型预测精度。后续测量包括模型灵敏度、精确度和再测精度,测量结果越接近1.0表明模型预测精度越高,效果越好[17]。F1得分(F1-Score)也称F测量,是推导模型预测精度和灵敏度之间平衡性能的重要指标,可以对人体运动识别表现进行深入分析。具体的模型精度预测方法和算法的使用需要根据数据类型,传统的误差率或错误率统计方法一般使用默认的决策阈值,因此并不适用基于复杂的训练数据集开发的模型[90-91]。分类模型评估方法还包括接收者操作特征曲线(Receiver Operating Characteristic Curve,ROC),曲线下的包络面积是ROC的重要特征,面积越接近1表示模型识别能力越强[92]。每种研究方法都有其特定的参数设置、特征向量和模型训练算法,因此,评估不同研究方法的合理性和有效性是较为复杂的。Wolpert[93]在1996年提出的“无免费午餐定理(No-Free-Lunch theorems)”,即NFL定理是机器学习及搜索优化算法的重要理论基石,该定理指出,不存在单一的或通用的机器学习算法去解决和优化所有的识别问题。因此,建议针对某一特定问题和数据集采用组合方法,输入任务的先验假设(prior assumption)来适应模型输入和相关参数,以提高模型预测的整体成功率[94]。
本文纳入的大多数研究是基于运动场的实时无标记动作捕捉和运动员特定动作参数获取的,包括执行动作的数量、类型和强度等特征统计,可以应用于运动负荷监控、运动员个性化动作技术分析、自动化打分评估系统开发和团体球类运动的传球投篮动作质量评估等领域[47,95]。对于足球、橄榄球等室外运动,由于动作本身的复杂性和环境干扰,个体化模型的一致性和跟踪精度是当前面临的主要挑战。例如,足球射门和传球动作的分类精度在封闭的实验室环境要高于室外足球场环境[96]。摄像机摆放位置和视频分辨率对无标记动作捕捉精度同样有较大影响。Corazza等[75]使用高分辨率摄像机并调整摄像机位置后,关节中心点位移误差从调整前的(79±12)mm降低至(15±10)mm。现有研究[45,51,55]显示,基于计算机视觉的深度学习算法在篮球、排球和冰球等团体球类项目中具有较为稳定的捕捉精度表现,预测模型的计算效率、结果精度和复杂程度之间的平衡也是需要考虑的重要因素。
3.5 研究局限与未来展望
在本文纳入的23项研究中,由于选取的模型参数和评估方法等差异,研究之间异质性较大,无法进行定量的荟萃分析。纳入研究的动作识别技术限定在机器学习以及深度学习算法领域,未考虑其他算法,例如线性判别函数分析等。此外,运动项目的不同以及运动场地大小的差异也可能是影响技术选择的重要因素,但由于纳入文献数量的限制及侧重点不同,本文并未对其进行进一步归纳分析。无标记动作捕捉系统的精确度和鲁棒性往往取决于研究领域和特定的采集环境,在不同领域的应用方式是不统一的。运动生物力学和康复医学等领域要求无标记运动分析系统具有高度精确性和较强适应性以检测运动过程中的细微变化[15]。基于上述部分应用场景对无标记动作捕捉系统的准确性和稳定性等方面需求,Elhayek等[78]提出将鲁棒性较高的判别分析方法与无轮廓运动学模型拟合方法相融合,以提升精度表现。当前,跑步运动的无标记动作捕捉可以实现步长、步频等时空参数的精确捕捉,并实现实时反馈[67]。三维关节角度等较为复杂的运动学参数需要对跟踪对象进行建模和在线捕捉采集,随后进行一定时间的离线处理,较难实现实时反馈。上述无标记动作捕捉过程,不需要对受试者、环境等进行特殊准备和标定等前处理,实现了训练实践和运动科学研究的同步,快速实时的反馈为教练员训练方案选取和运动员动作技术优化提供依据。但是,摄像机分辨率和捕捉精度需求的提升将导致视频存储和参数处理工作量大大增加,因此需要进行有效平衡,增加无标记动作捕捉的可操作性和实用价值。
4 结论与启示
(1)本文对机器学习、深度学习和相关算法技术在基于计算机视觉的无标记动作捕捉系统中的应用研究进行归纳综述,在动作技术识别和运动表现分析等领域,计算机视觉动作捕捉和相关模型、算法开发等已显示出良好的应用前景。其中支持向量机、主成分降维分析等传统机器学习算法仍是目前采用的主流动作识别技术。但随着卷积神经网络和循环神经网络等深度学习算法的开发与应用,在部分场景下的动作捕捉和识别效果要优于传统的机器学习方法。
(2)计算机视觉识别装置,包括常规的RGB摄像机和深度摄像机,其位置的摆放和设置、镜头分辨率、识别算法的选取以及数据存储处理等过程需要结合具体的运动场景(室内/室外/规模)、捕捉对象(单人/多人)和目标运动特点。室外运动和多目标运动项目容易受到捕捉环境、设备仪器和识别算法等的限制,因此,目前要实现对运动员动作的精确捕捉和实时反馈仍具有一定的挑战性。
(3)未来研究可以针对特定运动动作识别和运动表现评估,将传统的机器学习算法与深度学习识别算法进行对比,从而为动作识别技术和相关算法的选取与融合应用提供依据。计算机视觉图像可以与可穿戴无线惯性传感等装置配合使用,实现运动过程的多参数联合采集,提升无标记动作识别的效果、效率和鲁棒性。
作者贡献声明:
孙 冬:设计论文框架,撰写论文;
宋 杨:搜索资料,修改论文;
岑炫震:核实数据,修改论文;
盛 博:核实数据,修改论文;
顾耀东:设计选题,指导并修改论文。
猜你喜欢
电子制作(2018年11期)2018-08-04 03:25:38
小学生作文(低年级适用)(2018年3期)2018-04-17 00:58:35
中国公共安全(2017年8期)2017-10-13 08:12:17
少年博览·小学低年级(2017年4期)2017-06-09 16:22:28
作文评点报·低幼版(2017年7期)2017-03-11 20:49:41
中国公共安全(2017年11期)2017-02-06 05:27:47
办公自动化(2016年18期)2016-12-17 19:32:18
测绘科学与工程(2016年5期)2016-04-17 06:51:15
少儿科学周刊·少年版(2015年4期)2015-07-07 20:56:37
新闻前哨(2015年2期)2015-03-11 19:29:25
