
基于关联规则的隧道掘进中岩机信息感知互馈数据挖掘方法研究
2021-09-17 01:10:38乔金丽徐源浩刘建琴胡建帮
隧道建设(中英文) 2021年8期
乔金丽,徐源浩,刘建琴,胡建帮
(1.河北工业大学土木与交通学院,天津 300401; 2. 天津大学机械工程学院,天津 300072)
0 引言
掘进机在服役过程中对岩体条件敏感,岩体信息不明确将直接影响智能掘进决策,造成操作参数不合理、预警不及时等问题,因此,必须保证掘进过程中的安全与效率[1-2]。为了研究掘进机掘进过程中各因素之间的相互作用影响,近年来,越来越多的人工智能技术手段开始应用于岩土工程领域。Boubou等[3]利用神经网络对地表沉降进行预测;朱北斗等[4]利用BP神经网络对掘进参数进行训练,建立了地层识别模型; Liu等[5]同样利用神经网络建立了岩体特征预测模型; 田睿等[6]利用改进的深度神经网络对岩爆烈度等级进行预测; 张天瑞等[7]通过数据挖掘技术对掘进机运行中出现的故障加以诊断,提高了诊断速度; Khamesi等[8]将最近邻聚类与梯度下降、粒子群(PSO)、帝国主义竞争(ICA)3种算法结合模糊系统反智能推测土层类别; Zhou 等[9]建立粒子群算法与支持向量机的混合模型,对TBM掘进能耗进行预测,用于帮助确定TBM的性能和效率;Yagiz等[10-12]利用粒子群、灰狼算法等基于隧洞地质条件来预测TBM的掘进速度; Masoud等[13]则用基因规划表达在Yagiz的基础上进一步做出了TBM掘进速度的拟合公式。
以上工作大都是揭示定量关系,且由于神经网络等是黑箱操作,未能清楚地表达各项因素之间的因果关系。在数据挖掘方面,关联规则可以实现直观定性描述,已经成功地应用于揭示各种领域中的因果关系[14-15]。本文基于数据挖掘理念,对数据进行K-means聚类分析与预处理,应用关联算法,建立数据挖掘模型,得到多条关联规则,关联规则可直观显示各因素在不同类别下的相互影响作用,建立明确的因果导向。为掘进机提供先导判据,与决策树预测结果进行比对,综合现场岩体参数结果等多源信息,进行岩机的交互式耦合预测,以期实现在静态预测基础上的掘进过程动态分析。
1 关联规则挖掘算法
1.1 关联规则原理
关联规则分析是为了从数据集中找出各项之间的关联关系。Apriori算法[16]是一种最有影响的挖掘布尔关联规则频繁项集的算法,其核心思想是通过连接产生候选项与其支持度,然后通过剪枝生成频繁项集。
频繁项集是指支持度大于或等于给定的最小支持度阈值的事项集。关联规则参数之间的关联度可以用支持度和置信度2个指标来表示,同时使用提升度作为鉴定强关联规则是否有效的标准。支持度、置信度与提升度的表达式分别如式(1)、式(2)、式(3)所示。
Support(A→B)=P(A∪B)=count(A∪B)/D。
(1)
Confidence(A→B)=P(B│A)。
(2)
Lift(A→B)=P(B│A)/P(B)=
Confidence(A→B)/P(B)。
(3)
式(1)—(3)中:D为数据集;A、B为事项集。
在建立关联模型前需要设定好最小支持度和置信度,只有支持度和置信度不小于最小值,且提升度大于1的结果才被选为推荐的强关联规则。
关联规则模型的建立流程如下:
1)对于给定的最小支持度阈值,遍历数据集D,剔除小于该阈值的项集,得到1项频繁项集L1。
2)由频繁项集L1自身连接产生2项候选集D1;同样对比阈值,保留满足条件的2项频繁项集L2。
3)由频繁项集L2自身连接产生3项候选集D2;同样对比阈值,保留满足条件的3项频繁项集L3。
4)循环2)、3)步,每一步增加1项,直到得到最大频繁项集Lk。
1.2 关联规则实例演示
以某一商场的简单交易清单为例(如表1所示),假定只存在4种商品,分别为商品0、1、2、3。所探索的是商品组合被一起购买的概率,其组合类型如图1所示。

表1 某商场的简单交易清单

图1 商品的组合类型
图1显示了商品之间所有可能的组合,从上往下第1个集合是Ø,表示不包含任何物品的空集,商品集合之间的连线表明2个或者更多集合可以组合形成1个更大的集合。
使用集合的支持度来度量其出现的频率。设定最小支持度为60%,商品0、1、2、3的支持度分别为4/5、4/5、4/5、2/5,则商品3明显不符合,因此1项频繁集为商品0、1、2。
如果1个项集是非频繁的,那么它的所有超集也是非频繁的。因此,所有含有商品3的超集都是不频繁的,只余下{0,1}、{0,2}、{1,2}、{0,1,2},其支持度分别为3/5、3/5、3/5、2/5,因此{0,1,2}为非频繁项,只存在2项频繁集。
置信度计算: 对于2项频繁集,设定最小置信度为70%,有关联规则{0}→{1}、{0}→{2}、{1}→{2},其置信度分别为3/4、3/4、3/4,都满足最小置信度要求,对于关联规则{0}→{1}可以说购买商品0的人有很大可能购买商品1,其他关联规则同样如此。
2 影响因素的数据K-means聚类预处理
2.1 试验数据
研究中,关联模型所采用的数据来自于一个硬岩隧道开挖项目(皇后区3号输水隧道,第2阶段)编制的数据库[10]。此数据库包括岩石单轴抗压强度(UCS)、巴西抗拉强度(BTS)、用于量化岩石脆韧性的峰斜指数(PSI)、岩体连续性方向的α角、薄弱面间距(DPW)、掘进速度(ROP)、岩石破碎等级及岩石类型,共计153例。其中,峰斜指数是施加在试样上的最大载荷(kN)与相应位移(mm)的比值。岩石共有5种类型,编号设置为1—5,分别是: 花岗质(长英质)片麻岩和正片麻岩,占比29.4%; 正片麻岩,占比20.3%; 片麻岩、角闪岩和片岩,占比39.8%; 块状石榴石角闪岩和较大的岩墙,占比9.1%; 流纹英安岩脉岩,占比1.3%。岩石破碎等级与薄弱面间距除极少数环有不同外基本相同,将破碎等级与薄弱面间距合并为1项,共分为3种不同类型,间距小于0.4 m为一类,大于1.6 m 为一类,0.4~16 m为一类。
数据库中UCS、BTS、PSI与α参数曲线、掘进速度曲线分别如图2和图3所示,可以看到巴西抗拉强度与峰斜指数的变化较为平缓,另外3个参数的变化则非常明显。所有数据是在整条隧道的不同环随机选取的,保证了数据的随机性与代表性。表2示出各个参数的最大值、最小值、平均值、标准差与偏差值。标准差越小,说明数据值与平均值的偏差就越小;偏差值可以用标准差/平均值的比值来表示,抗拉强度的偏差值最小,说明BTS的变化最小。

图2 数据库中UCS、BTS、PSI与α参数曲线图

图3 掘进速度曲线图

表2 各项参数统计
2.2 聚类处理
使用K-means聚类方法对数据库中的各项参数进行聚类分析,指定数据划分为3类,随机选取样本集中3个对象作为初始聚集中心,针对所有对象,计算其与3个聚集中心点的距离,然后将该对象归为距离最小的聚集中心代表的簇。1次计算归类结束之后,针对每个簇类,重新计算聚集中心,然后针对剩余对象,重新寻找距离最近的聚集中心。如此循环,直到前后2次迭代的簇类没有变化。
各项参数的聚集结果见表3,按照高、中、低对聚类结果用0、1、2进行标注。由表3可知,高抗压强度为170.3~199.7 MPa,中抗压强度为144.8~169 MPa,低抗压强度为118.3~143.4 MPa,超过一半的岩体属于低抗压类; 高抗拉强度为9.8~11.4 MPa,中抗拉强度为8.6~9.6 MPa,低抗拉强度为6.7~8.4 MPa,接近一半的岩体为高抗拉强度; 高峰斜指数为52~58 kN/mm,中峰斜指数为35~46 kN/mm,低峰斜指数为25~34 kN/mm,64.1%的岩体属于低峰斜指数;α高角度为57°~89°,中角度为31°~56°,低角度为2°~30°,α的分布较为平均,各聚类结果基本接近1/3。掘进机的掘进速度则呈现中间大的分布,高掘进速度为2.39~3.07 m/h,中掘进速度为1.93~2.37 m/h,低掘进速度为1.27~1.91 m/h。

表3 各项参数的聚类结果
3 隧道岩机数据挖掘模型
3.1 基于关联规则的隧道岩机数据挖掘
在本模型中,设置最小支持度为5%,最小置信度为80%,由于当全部数据用于分析时,前置条件和后置结果存在相互支持的现象,所以指定掘进机的掘进速度这一参数作为后置结果,对数据库选取的7个参数进行数据挖掘,共生成符合预先设定阈值条件的有效关联规则20条,如表4所示。
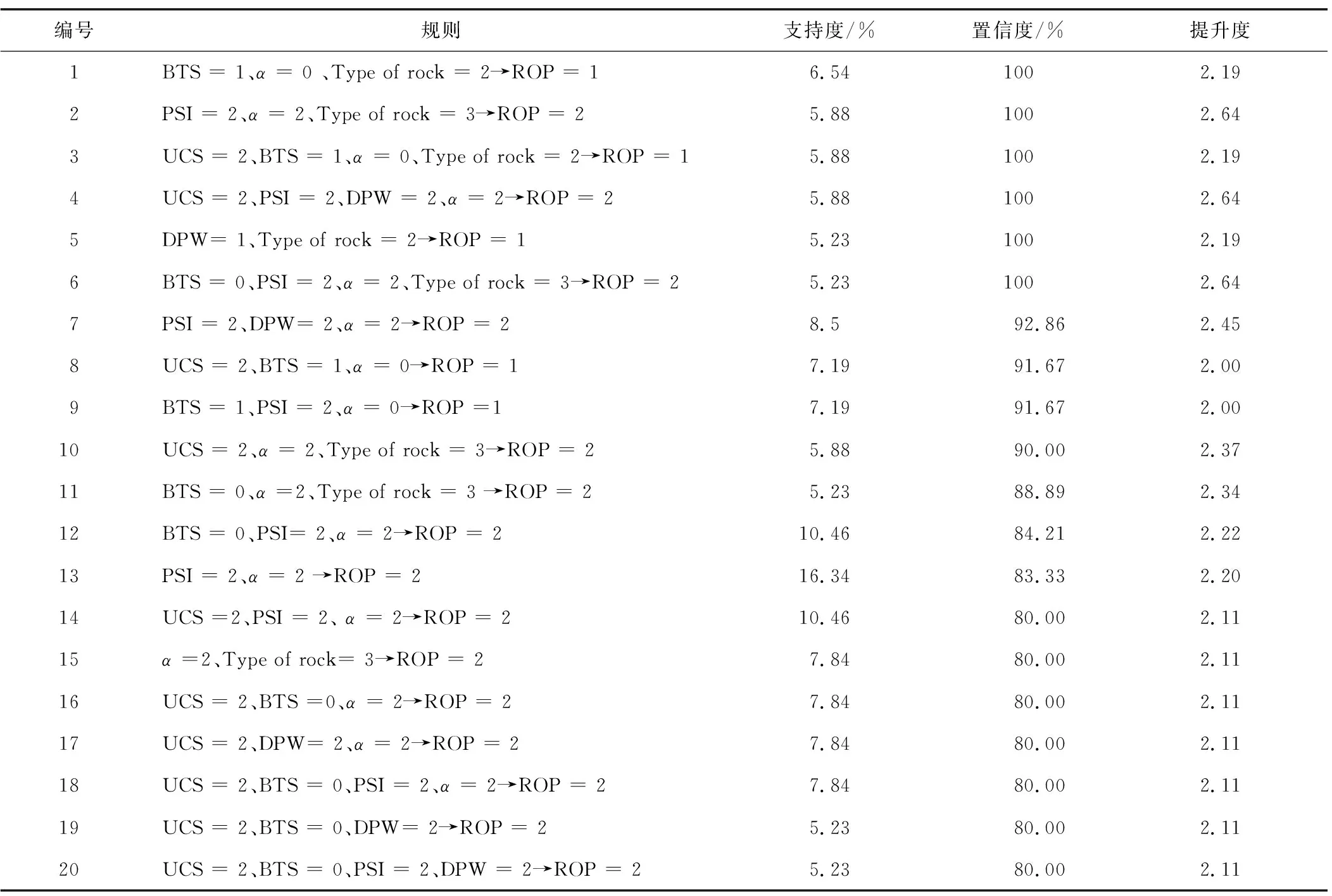
表4 掘进机掘进关联规则结果
表4中的每一条关联规则都代表着一条因果关系。例如,关联规则1揭示了抗拉强度(MPa)在[8.6,9.6]、α(°)在[57,89]、岩石类型为正片麻岩时,掘进速度(m/h)位于低速掘进区[1.27,1.91]的置信度为100%。换言之,基于强相关特性,所有4个参数值会同时出现。
基于关联规则整理出的20条规则,可以看到,有6条规则置信度为100%,4条规则不低于90%,剩余规则置信度则全部低于90%;而在掘进速度方面,所得出的结果要么是处于低掘进区间,要么处于中掘进区间,没有高掘进区间。导致这一结果可能的原因,一方面在于采用的数据集中高区间本身所占比例就远远小于中低区间,没有足够的样本数量;另一方面高区间掘进速度实际出现的情况偏少。
从规则1与规则3中可以看到,在增加了一项因素之后,其他条件不变的情况下,所得到的结果并没有发生变化;但这不能说明UCS的影响是可以忽略不计的,如规则10与规则11所示,存在UCS条件的规则,比存在BTS条件的规则置信度高。
从规则4、8、10、14及16、17、18可以近似得到低抗压强度与低的α角对于低掘进速度是非常必要的,这与通常认为的低抗压强度会使得破岩速度加快有所出入。但在破岩速度与掘进速度之外,还要考虑贯入度等其他因素,如α角较小,在掘进时岩体与掘进机偏向正对,从而导致掘进速度较低。这一推断与其他规则中高等程度的α角得到的是中等掘进速度相比较后可以进一步推论,α角在中等掘进区间可能有助于掘进速度的提高。
在岩石类型方面,出现的是第2种和第3种岩体,即正片麻岩与片麻岩、角闪岩和片岩,但考虑到出现岩体类型的规则仅有6条,说明岩体类型对掘进速度的影响偏小,是次要因素;纵观整个规则表,薄弱面间距大都表现为低间距区间,其与掘进速度呈现出正相关。
随着隧道掘进进度的不断推进,关联规则模型逐步建立,一方面在前期地质勘察的基础上,根据测点地质条件及应用模型给出的关联规则,推断掘进参数的选取范围; 另一方面通过正向地质勘探或超前地质预测对掌子面地质进行推定,然后对各项地质参数分类后由关联规则导出掘进参数范围。即先获取地质参数,再由当前模型参数聚类结果明确范围,最后根据符合的关联规则推断合适的掘进参数范围。随着掘进过程不断获取新数据,更新关联规则模型,使其更加完善。
3.2 基于决策树的隧道岩机数据挖掘
决策树模拟人通过条件判断将集合进行分割的过程,通常有3个步骤: 特征选择、决策树的生成、决策树的修剪。1颗决策树包含1个根节点、若干个内部节点及若干个叶子节点。根节点与内部节点的划分条件取决于当前数据集的最优划分属性,即通过该属性使划分出去的下一级节点的数据集尽可能纯净;叶子节点是决策树最终的决策结果,全部叶子节点数据集的合集是样本全集;整个决策树就是多条由根节点到叶子节点的判定测试序列组成。
决策树的直观表示见图4,A对应为根节点,包含了样本全集;B对应为内部节点;C、D、E为叶子节点;T表示符合当前划分条件,F表示不符合。
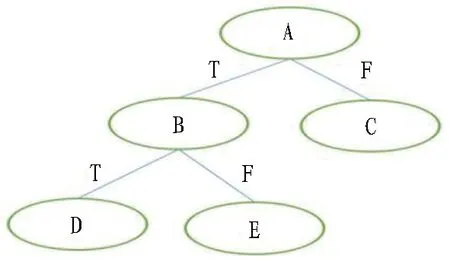
图4 决策树示意图
通过每一次决策的判定,在图4中包含的决策规则有3条: 决策1,A→B→D; 决策2, A→B→E; 决策3,A→C。
在决策树模型中,选取全数据集的80%作为训练集,20%为测试集。为充分发挥决策树本身对于最优特征选择的能力,只将掘进效率进行分类,其余参数保持原有数据。决策树运行结果见表5。

表5 决策树结果
决策树模型的决策链中特征可能出现不止一次,但从叶子节点进行倒推时,每个特征的区分区间必包含于上级节点中。以某一决策链为例,最后叶子节点全部数据集为24组低区间,整个决策链中α角出现过2次,DPW出现3次,由高至低α角分别为高于14°、高于57°,DPW分别为高于0.4 m、高于0.8 m、高于1.6 m。
3.3 决策树与关联规则的预测模型对比
为确定决策树预测模型的可靠性,使用测试集进行验证,但其在测试集中只有58.97%的正确率。决策结果分散大,说明其决策链对于样本量要求比较高;数据量少时,模型容易受到个别数据的影响发生波动,这是准确率低的主要原因之一。相较之下,关联规则是基于全体数据库建立的,每条规则在建立时首先进行了置信度评价,其得出的规则结论直观清晰,具有较高的可信度。当前研究着力于单一隧道的模型预测。在隧道开挖初期,数据采集器获得的数据量偏少,关联规则模型对数据的充分利用使其能在开挖初期仍能得到有效结论,对智能掘进具有一定的参考价值。
在隧道开挖初期,关联规则模型在一定岩体条件的地层进行隧道掘进时,可以预估掘进参数的大致范围,或者根据正常隧道掘进时的相关隧道参数,实现对其他地质特征的初步推测,有助于保证隧道施工的安全与效率。
4 结论与讨论
采用基于关联规则的数据挖掘手段,对岩体地质关键参数与掘进机工作参数之间的因果关系进行分析,有效地揭示地质参数与掘进参数之间的耦合关系,达到优化控制参数、指导掘进的目的。主要结论如下:
1)K-means聚类算法的应用将原始数据按照其临近程度分为高、中、低3组,并编号处理;分类编码后,确定了地质参数中的抗压强度、抗拉强度、峰斜指数、薄弱面间距、掘进速度、岩石连续性方向的α角、岩石类型等7个主要因素,为建立关联规则提供了支撑。
2)关联规则结果显示,岩体的抗拉强度、抗压强度及岩石连续性方向的α角是影响隧道掘进的重要因素,薄弱面间距的大小虽然也有一定影响,但在20条规则中出现次数明显少于其他因素。
3)在隧道开挖前,通过地质勘测初步确定了岩石的单轴抗压强度、巴西抗拉强度、峰斜指数、岩石连续性方向的α角、薄弱面间距等地质参数,结合本文所述关联规则可以得到相应的掘进参数范围,为智能掘进的实现提供理论参考依据。
4)多维关联规则挖掘方法分析多个参数之间的相关性,在原始数据集的基础上进行数据预处理、关联规则挖掘,对于多因素影响的相关性分析有着广泛的适用性;较之决策树结论更直观清晰,适用于开挖初期数据量较少时的模型建立;在实际的工程中,有助于隧道掘进中各参数的协调一致。
因此,针对掘进机和岩体参数复杂的隧道施工数据收集,引入数据挖掘是一种简单而较为成功的尝试,但规则简单粗放,各个簇的范围较大,最终结果限定在一定范围内,没有明确的参数值,参考意义大于决定意义;随着参数种类的丰富,隧道数据的积累,能够建立越来越完善的关联模型。而使用更多的数据挖掘手段,特别是建立多参数间的明确的模型,可以为隧道的智能化施工奠定基础。

猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
大众投资指南(2021年35期)2021-02-16 01:06:26
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
计算机应用(2018年5期)2018-07-25 07:41:26
电力与能源(2017年6期)2017-05-14 06:19:37
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
信息通信技术(2015年6期)2015-12-26 01:16:46
轴承(2015年2期)2015-07-25 03:51:04
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
