
CRCLA的杂凑算法优先级决策映射方法
2021-09-16 01:53章宇雷徐金甫
计算机工程与设计 2021年9期
章宇雷,李 伟,徐金甫,陈 韬
(信息工程大学 信息安全重点实验室,河南 郑州 450000)
0 引 言
近年来,国内外针对杂凑算法硬件实现的研究较多,但绝大多数文献仅仅是针对专用集成电路硬件结构进行设计的,在灵活性上具有局限性,难以适应多种算法实时切换的需求。粗粒度可重构密码逻辑阵列(coarse-grained reconfigurable cipher logical array,CRCLA)是一种基于数据流的高效运算结构[2],兼顾了灵活性和处理速度的需求,能够通过配置实现多种算法的实时重构。
目前,国内外针对算法映射到CRCLA上的研究,主要集中在分组密码算法上,如文献[2-5]。然而国内外还没有针对杂凑算法映射问题的专项研究,相较于其它类型算法,杂凑算法在运算中具有其不同的特征,在映射的方法上会有一定的区别。同时,在映射过程中,对于某一具体操作的映射,往往存在着多种候选映射方案,最佳映射方案的选取必定会影响后续操作的映射,且决定了整个映射结果的优劣,需要结合杂凑算法的映射特征设定相应的决策机制来选取最佳映射方案。
本文分析了杂凑算法的基本特征,结合可重构阵列的硬件结构,采用空间展开操作并行的映射手段,针对在具体映射过程中某一操作的多种候选映射方案提出了一种优先级决策机制,从而总结出杂凑算法高能效映射方法,并选取了几种典型的杂凑算法进行实验。
1 杂凑密码算法处理特征
杂凑密码算法是将任意长度消息编码的数字序列按照一定的规则进行填充后按固定长度分成一些消息块,经过消息扩展后的消息块经过压缩变换后输出固定长度的杂凑值。杂凑算法处理流程如图1所示。

图1 杂凑算法处理流程
通过对多种典型的杂凑算法的运算过程进行分析,杂凑算法具有以下几个特征:
特征1:不同算法涉及的运算操作均较为简单,大部分运算操作在阵列上仅需计算单元中的一个算子单元即可实现,因此在映射时可以将部分操作进行合并,减少映射资源。
特征2:消息扩展部分轮间数据依赖强烈但有固定规律,由计算过程可以发现,从某一轮开始,该轮输出数据依赖于之前轮的输出数据,但具有固定性。在映射中,需要注意每一轮数据的存储以方便后续的运算,因此数据的存储方式是一个需要考虑的问题。
特征3:消息扩展模块与压缩部分的关联数据呈单向流动,且两部分可同步进行,映射时存在并行执行的可能性,从而可以减少算法的执行周期,提高算法的吞吐率。
特征4:压缩部分轮内数据依赖强烈但无轮间数据依赖,压缩部分的轮运算每轮输出只与前一轮的数据存在依赖关系,轮运算内部数据仅与当前轮相关,不存在轮间数据依赖关系。因此在映射时,相关计算PE的跨度不要过大,减少不必要的互连资源。
综上所述,杂凑密码算法的基本特征对算法的映射方式进行了一定的约束,本文将依据杂凑算法的基本特征提出杂凑算法的高能效映射方法。
2 CRCLA基本结构及模型
CRCLA采用了数据流加配置流驱动的方式,通过配置信息来配置阵列内部计算单元以及互连结构,从而实现不同种类的密码运算操作。
2.1 CRCLA硬件结构
CRCLA整体上由输入输出FIFO、接口控制器、阵列控制器、配置控制单元、共享存储单元(shared store unit,SSU)和运算系统组成,其结构如图2所示。

图2 CRCLA整体结构
其中,输入输出FIFO负责数据的缓存以及与外部数据的交互,输入FIFO用来存储输入的配置信息以及数据,输出FIFO用来存储经过阵列计算后得到的输出数据;配置控制单元由1个配置解析器和4个配置页面组成,4个配置页面之间可以通过控制进行切换,可实现阵列的实时重构,配置解析器用来解析配置信息,将配置信息送至对应的部件;阵列控制器可通过配置信息的配置,负责产生阵列内部所需要的控制信号,以保证算法的正常执行;计算系统由64个计算单元(process element,PE)和基于2D-Mesh的互连结构组成。
PE由可重构密码块(reconfigurable cryptography block,RCB)及互连单元组成,RCB承担主要的计算任务,内部包含着能实现多种运算的运算部件,且可通过内部互连实现数据互通,能够实现复杂的密码运算。RCB内部还包含寄存器单元,便于实现数据的暂存以及控制数据路径的延时,可以适应不同算法的需求。由于部分密码算法存在大位宽计算需求,同一行多个PE能够级联,以实现64 bit、128 bit的运算。
2.2 问题描述
为方便问题描述,需要将杂凑算法到可重构阵列上的映射抽象成数学模型,结合国内外提出的阵列结构,本小节抽象出通用阵列数据流模型,对算法映射问题给出以下定义。
定义1 粗粒度可重构阵列的硬件资源图(coarse-grained reconfigurable array resource graph,CRAG)可表示为:给定一个由N×N个PE构成的CRCLA,包含共享存储单元等资源,其硬件资源图可表示为CRAG={PE,Con,M},其中,PE为阵列中所有计算单元PEi,j的集合,i,j分别表示PE位于第i行,第j列,1≤i≤N, 1≤j≤N;Con表示互连资源的集合;M表示存储资源的集合。
定义2 可重构阵列的计算单元资源的集合可表示为:PE={OU1,OU2,…OUn},其中OU表示PE内部包含的算子单元,如算术类单元、逻辑类单元、置换类单元等各类密码运算单元。
定义3 可重构阵列的互连资源的集合可表示为:Con={ConPE,ConPES},其中,ConPE表示PE之间的互连,ConPES表示PE与共享存储单元之间的互连。
定义4 可重构阵列的存储资源的集合可表示为:M={Rs,SSU},其中Rs为阵列中的寄存器单元Rsi,j的集合,i,j分别表示Rs位于第i行,第j列,1≤i≤N, 1≤j≤N;SSU表示共享存储单元。
定义5 一个杂凑算法的集合可表示为:Ha={op,L,SData},其中,op表示杂凑算法包含的一系列运算操作,L表示各个操作之间的连接关系,SData表示杂凑算法运算过程中需要寄存的数据。
定义6 杂凑算法到可重构阵列上的映射:给定一个杂凑算法的集合Ha={op,L,SData}和一个可重构阵列的硬件资源图CRAG={PE,Con,M},Ha到CRAG上的映射可表示为在满足资源约束的条件下,完成op→PE,L→Con,SData→M的绑定。
3 杂凑算法高能效映射方法
本节首先进行杂凑算法的映射分析,为提高映射能效,确定总体采用的映射手段后,针对映射过程中某一具体操作的多种候选映射方案提出了基于优先级的决策机制,并对映射方法进行了描述。
3.1 杂凑算法映射分析
对于杂凑算法的填充部分,其操作是将数据“1”添加到消息末尾,再添加k个“0”,需要满足以下条件
1+l+k=448 mod 512或1+l+k=896 mod 512
(1)
式中:l表示填充后的总长度,mod为模运算。由于填充部分运算的特殊性,通过对现有的阵列结构进行研究发现,其计算单元无法满足填充部分运算的需求,因此,仅针对经过填充后的一个消息块的消息扩展、迭代压缩的映射进行研究。通过对比多种杂凑算法的研究分析,其主要参数数据见表1。
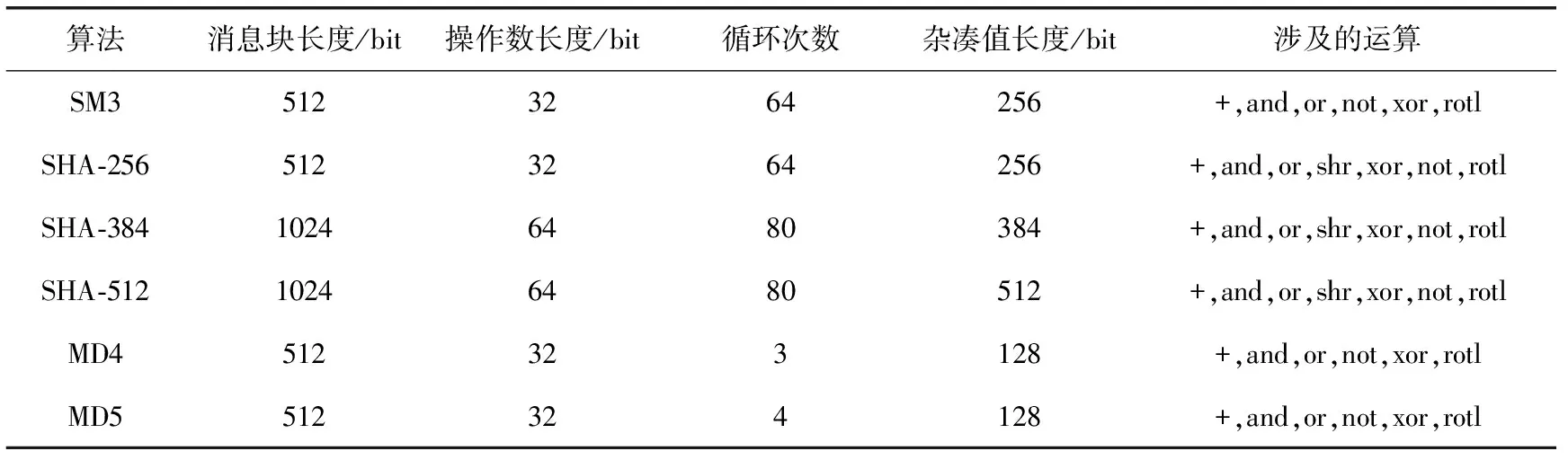
表1 多种杂凑算法主要参数对比
不难看出,不同种类的杂凑算法不同之处在于数据位宽、操作数长度,循环次数以及最后输出的杂凑值。其算法流程以及涉及的运算几乎是一致的。
CRCLA阵列结构的输入数据位宽为32 bit,在阵列内部同一行多个PE之间可以通过级联来实现大位宽处理。上述列表中所涉及到的运算通过配置RCB即可完全实现,并且能够满足多个操作并行的处理。
对于杂凑密码算法,衡量其性能的指标主要通过吞吐率来体现,假设L为处理数据位宽,N为杂凑运算过程所需时钟周期数,F为时钟频率,则杂凑算法的吞吐率可以表示如式(2)所示
(2)
式(2)中可以看出,要提高杂凑算法的吞吐率,主要可以通过增大数据处理位宽,增大时钟频率,以及降低运算过程所需时钟周期数来实现。由于大多数文献中评价杂凑算法的处理性能通常以吞吐率作为评价指标,而可重构阵列可采用堆叠可重构单元的方式来提高吞吐率[3],因此仅考虑吞吐率指标是不够客观的,需要同时考虑算法运行的功耗。其功耗取决于具体的映射方案,以及消耗的资源总数来确定。
3.2 空间展开操作并行
通过3.1节对杂凑算法的映射分析,其主要运算过程体现在消息扩展和迭代压缩中的循环部分。首先,对消息扩展模块和迭代压缩模块进行分别讨论。在一组消息经过消息扩展后将各消息块分成若干个操作数(不超过16个),再将这些操作数通过一些基本的运算生成下一个操作数后并更新。阵列中存在着通用的共享存储单元SSU,若将划分后的这些数据都存入SSU,将会大大加剧从SSU到PE的互连资源的压力,极有可能造成互连资源不足导致映射失败的情况,且不方便后续的数据更新及运算。阵列中每个PE中都包含寄存器单元,因此,将初始化的若干个数据通过移位的方式传送至每个PE的寄存器单元中,通过PE之间的互连网络来实现移位,每当生成一个新的数据后,通过配置打开寄存器的使能信号,实现移位的功能,来达到数据上的更新。以16个32位操作数为例,深色箭头表示PE内部寄存器内的数据的走向,每个PE承担着不同的计算任务,如图3所示。
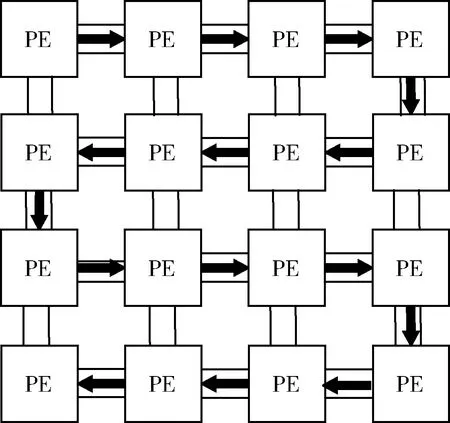
图3 移位寄存器的构成
而对于迭代压缩模块,每一轮的运算实质上也是对各个数据进行密码运算并更替,每一轮输出数据仅与上一轮相关,因此,只需考虑在映射时,哪一些操作可以合并映射在同一个PE上以及布局布线,减少阵列中的资源消耗。
在同时考虑两个模块的映射时,采取空间展开并行操作的方式,在其资源充足的前提下,将CRCLA阵列在空间上划分成两块,上半部分映射消息扩展模块,下半部分映射迭代压缩模块。上下两部分存在着从消息扩展部分到压缩迭代部分数据的单向流动,通过对控制上的配置,当消息扩展模块生成数据后,送入迭代压缩模块进行运算,实现两个模块的并行映射与执行,这样既能充分利用可重构阵列的资源,又能减少运算周期,有效提高算法的吞吐率。当阵列规模较小时,则采用多重配置页面的模式进行映射。
3.3 优先级决策机制
在制定了总体的映射方案后,再对映射过程中某一具体操作的映射进行分析。
在映射过程中,一个杂凑算法的某个操作往往会存在多种映射方案,如寄存器的选取、互连资源的走向、运算PE的选取等等。
定义7 候选映射方案:针对杂凑算法映射中的某一具体操作及与其相关的操作数和连接关系,存在多种组合方式Map={Mapk∶op→PEi,j,L→Con,SData→Mi,j,k=1,2,…n},能满足当前映射的需求,则Mapk称为一种候选映射方案。
某个操作的多个候选映射方案的选取往往会直接影响后续操作的映射方案的选取以及整个映射方案的优劣,因此,需要建立一套适配于杂凑算法映射的决策机制,来从多种映射方案中选取最佳方案,使得其在各个方面都较优。本文从存储资源开销、PE内部占用率开销、互连资源开销、配置信息量、延时开销5个方面进行讨论并确定其优先级。
存储资源开销。在杂凑算法映射到阵列的过程中,由以上分析可知,对阵列内部的寄存器需求较高,若某个映射操作上占用过多的寄存器资源,极有可能导致后续的映射操作难度加大。
PE占用率开销。可重构处理单元PE是用来执行具体运算的功能单元,若在映射中导致一些PE上承担的计算任务明显比其它PE要多,而在后续的映射过程中由于互连资源的限制需要再次使用这部分PE,将会导致需要重构配置的次数增多,同时也会加大配置信息量。
互连资源开销。由于阵列内的互连资源是有限的,而面积和功耗导致了不可能保证任意两个PE之间的直接连接。由第2节可知,本文基于的阵列结构在互连上采用的是最为常规的2D-mesh结构,只能够保证一个PE可以同其相邻的PE进行直接连接。在配置当前操作时,必须要考虑使用的互连资源,否则后续的映射操作可能会存在互连资源冲突的情况,导致需要切换配置页面重构配置,这不仅大大加剧了映射的复杂度,并且也可能直接导致映射失败。
配置信息量。映射方案的配置信息量越少,数据注入输入FIFO占用的时钟周期越少,同时说明需要配置的结构单元越少,映射复杂度越低,效率越高。
延时开销。轮函数的循环部分为核心部分,其核心循环的延时开销将直接决定映射的性能优劣。
这5个方面如果单独考虑则过于片面,但是如果仅仅通过计算相加的方式来择优选取,由于各个开销在计算结果的单位上完全不同,且重要性不同,则不能客观反应出总的映射开销,选取的映射方案实质上并不一定就是最佳的。因此,本节设计了针对杂凑算法的决策机制,分析这5种开销的重要性程度,给出优先级排序,按照优先级从大到小的方式进行筛选得出最佳方案。
本文的目标瞄准点为杂凑算法的高能效映射,为了提高杂凑算法映射后的计算性能,将延时开销作为首要评判指标。其次,杂凑算法在映射过程中,需要用到大量的存储资源,而存储资源的分配不佳将会导致后续的操作存储资源分配难度大大加剧,且在一定程度上会影响到互连资源的消耗上,因此,将存储资源消耗作为决策机制中的第二评判指标。当决定互连时,若选取占用较多的互连资源的方案,将会导致后续的操作在互连上存在绕线过多,或占用过多PE作为路由PE的情况,甚至可能导致映射失败,因此将互连资源作为第三评判指标。考虑PE占用率是为了平衡各个PE的使用程度,以免出现某些PE操作过多某些PE操作过少的情况,因此将PE占用率作为第四评判指标。最后,在剩下的侯选映射方案中选取配置信息量最小的方案进行映射。据此,得出表2所示的决策机制伪代码。

表2 决策机制伪代码
3.4 杂凑算法高能效映射方法
通过以上分析,得到基于优先级决策机制的杂凑算法高能效映射方法描述如下,其流程如图4所示。

图4 杂凑算法高能效映射方法流程
步骤1对目标阵列硬件结构及其可用的资源总量进行分析,得到阵列资源图CRAG={PE,Con,M};
步骤2对需要映射的算法进行分析,得到算法中可映射加速的部分的集合Ha={op,L,SData};
步骤3依据阵列可用资源及待映射算法的复杂程度,判断是否可以采用空间展开操作并行的方式进行映射,如可行,将按照3.2节所述方案进行映射划分。如不可行,则采用多配置页面方式;
步骤4依据阵列中计算单元的结构对算法中可以合并的操作进行操作合并,得到新的算法操作集合Ha`;
步骤5按照算法操作的优先级对算法中的每个操作进行映射,判断该操作是否存在候选映射方案,若存在,则跳至步骤6;若不存在,则跳至步骤7;
步骤6计算各个候选映射方案的5个开销值,按照3.3节所述映射决策机制进行决策,得到最佳映射方案;
步骤7更新硬件资源映射图,并判断是否存在未映射的操作,若存在,则重复步骤5~步骤7;若不存在,则映射结束,依据硬件资源映射图得到阵列数据流配置信息。
4 实验验证与分析
本节首先通过SM3映射示例来展示整个映射流程及映射结果,然后对决策机制进行实验对比。
4.1 算法映射示例
以SM3算法为例,遵照以上映射流程进行映射。对运算操作进行合并后映射到PE中,选取RAM单元用来存储算法中涉及到的IV等常量。依据所需算子数量,将SM3的消息扩展和迭代压缩部分分别映射到阵列上,得到图5所示的阵列数据路径映射图。
如图5所示,将SM3的消息扩展部分映射在阵列的上半部分,SM3的操作位宽为32位,移位寄存器的构成部分为16个操作数,选取左上部分16个PE通过PE内部寄存器以及互连构成移位寄存器。此外考虑到该部分涉及到的运算为移位、异或等操作,可以操作合并至同一个PE当中,减少资源消耗。

图5 SM3阵列映射图
阵列图的下半部分用来映射压缩模块。压缩模块运算相对于消息扩展模块较为复杂,需要更为精确的划分运算操作,在映射前期,更需要对同一操作的多种候选映射方案准确利用好映射决策机制。算法中压缩模块的布尔运算取决于当前操作的轮数,因此需要两个配置页面来完成整个运算,图中下半部分的深色PE即为映射布尔运算的PE。
在将数据注入阵列移位寄存器的过程中,仅需在第5个时钟周期就可将Wj和W′j通过配置送入迭代压缩部分,实现操作上的并行,大大减少了算法运行的周期。经过优化后的方案相比典型的映射方案减少了11个时钟周期,提高了算法的吞吐率。
4.2 对决策机制的实验对比
本文提出了一种针对杂凑算法映射的决策机制,基于存储资源开销、PE占用率开销、互连资源开销、配置信息量、延时开销5种开销按照影响程度排列优先级,如果一个操作存在多种映射方案时,决策机制将依据优先级筛选出最佳映射方案。
本文以课题组设计的阵列结构进行实验,由于大部分文献所实现的可重构阵列结构无源码支持,且相关文献中列举的映射算法均为分组密码算法,而课题组设计的阵列结构基本符合2.2节中所提到的阵列数据流模型,因此可以作为典型阵列硬件结构进行实验,其实验结果能够具有一定的参考价值。
实验基于课题组前期设计的55 nm工艺下流片的粗粒度可重构密码逻辑阵列芯片,其基本硬件结构如图2所示。选取了SM3、SHA-256、SHA-384、SHA-512、MD4、MD5等多种典型杂凑算法在阵列芯片上进行实测分析,通过构建Xilinx AX7020开发板与阵列芯片的数据交互,并将数据通过串口助手打印至PC端,得到的吞吐率及功耗测试结果见表3、表4。
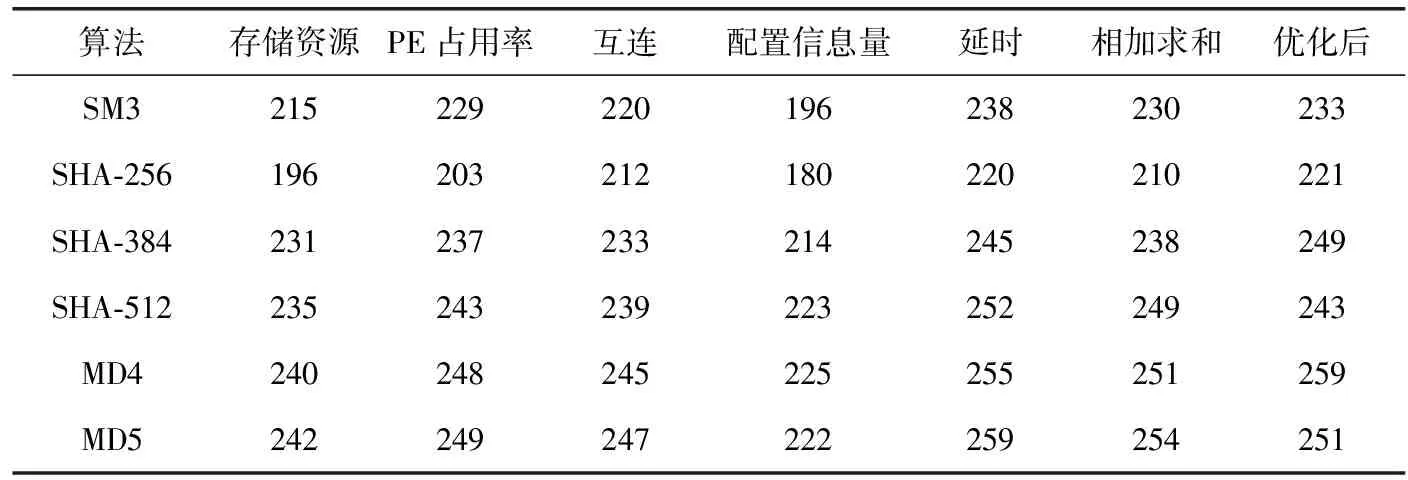
表3 不同决策方案得到的吞吐率/(Mb/s)

表4 不同决策方案得到的功耗/mW
表3分别对5种开销单独决策、直接相加决策、本文优化后的决策进行了多种杂凑算法的吞吐率测试,由表中所示数据可以看出,在吞吐率上以延时开销进行决策的吞吐率最佳,这是因为延时开销很大程度上决定了其算法的吞吐率,但本文优化后的结果也处于较优水平;表4分别对多种决策方案进行了多种杂凑算法的功耗测试,由表中所示数据可以看出,功耗上基本是以配置信息量决策最佳,但本文优化后的结果同时也处于较优水平;由于大多数文献中评价杂凑算法的处理性能通常以吞吐率作为评价指标,但对于阵列结构,仅考虑吞吐率及功耗指标是不够客观的,本文将能效比作为主要评价指标。
上述典型算法在7种决策方案上的能效比如图6所示。其中横坐标1~7分别表示基于存储资源开销、PE占用率开销、互连资源开销、配置信息量、延时开销,直接相加以及优化后,纵坐标表示能效值,其单位为Mbps/mW。从图中可以明显看出,本文提出的优化后的决策机制在能效提升上有着明显的优势,相较于其它不同决策机制的映射方法,本文提出的决策机制在能效上提升了约10%到20%。
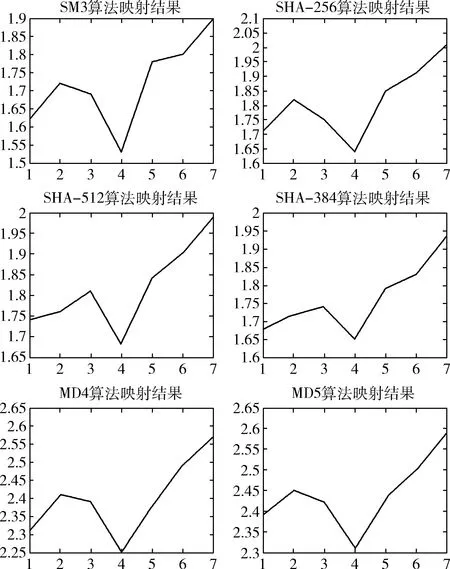
图6 典型杂凑算法映射结果
5 结束语
本文通过分析杂凑算法的基本特征,结合阵列数据流处理模型,采用空间展开操作并行手段,并针对某一具体操作的候选映射方案提出了一种优先级决策机制。以课题组设计的阵列结构作为实验平台,选取了几种典型的杂凑算法进行验证,数据表明,本文提出的映射方法在能效上具有一定的优势,能够满足典型杂凑算法的映射需求。由于本文仅针对杂凑算法的数据路径映射上进行分析,且未对阵列结构上进行改进,下一步将结合控制路径,以及修改部分阵列结构,进一步完善映射方法及提高杂凑算法映射的能效。
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19
有色金属设计(2022年4期)2022-02-04
摄影世界(2022年1期)2022-01-21
计算机应用(2020年5期)2020-06-07
印刷工业(2020年5期)2020-03-29
知识经济·中国直销(2018年12期)2018-12-29
商周刊(2017年6期)2017-08-22
流程工业(2017年4期)2017-06-21
自动化博览(2014年6期)2014-02-28
中国质量与标准导报(2013年8期)2013-03-11
