
四川盆地区域性暴雨过程相似度指标及其与灾情的关系研究
2021-09-16 09:35王春学张顺谦陈文秀
气象与环境科学 2021年5期
周 斌,王春学,张顺谦,邓 彪,陈文秀,孙 蕊
(四川省气候中心/高原与盆地暴雨旱涝灾害四川省重点实验室,成都 610072)
引 言
暴雨洪涝是四川盆地发生频率最高、危害最重的气象灾害之一,其中区域性暴雨过程降水强度大、持续时间长、影响范围广,往往引发山洪、泥石流、滑坡等次生灾害,造成较大的人员伤亡和经济损失[1-5]。2013年四川盆地出现6次区域性暴雨过程,其中6月29-7月1日的过程造成449.2万人受灾,死亡13人,失踪5人;农作物受灾面积197千公顷;直接经济损失37亿元[6-7]。2014年出现5次区域性暴雨过程,其中9月17-18日的过程造成379.3万人受灾,6人死亡,12人失踪;农作物受灾面积93.6千公顷;直接经济损失57.5亿元[8]。2018-2019年虽然没有出现特大型的区域性暴雨过程,但是一般型区域性暴雨过程更加频繁,其中2018年出现8次,2019年出现6次,对社会生产生活造成很大的影响[9]。
王春学等[10]制定了四川盆地区域性暴雨过程的识别方法,完善了区域性暴雨过程的监测评价业务,但是灾情评估方面的相关技术和方法还比较欠缺。根据灾情评估时效性,开展灾前和灾中评估业务主要有两种方法:一种是基于承灾体易损性的评估,该方法主要通过致灾过程的模拟仿真计算,需要相对全面的承灾体数据和承灾体与致灾因子相互作用的机理模型支持,对模型和数据的要求都较高,目前要实现业务化难度还比较大[11]。另一种方法是基于历史灾情统计资料的评估方法,该方法主要是探究致灾因子强度和承灾体损失率之间的关系,进而对未来灾害造成的可能损失进行评估,这种方法快速简便,对承灾体的数据精度要求不高,比较容易实现业务化[11]。以往这方面的研究主要集中在利用概率密度函数、灰色关联度等方法,而这类方法往往计算相对复杂,并且默认以往的所有灾害过程发生在相同的下垫面,当下垫面人口、经济、防灾减灾能力等方面的空间差异很大时,评估效果就不够理想[12-18]。由于四川盆地内的地理、农业、社会、经济等方面的差距较大[19],所以在对四川盆地区域性暴雨过程的灾情进行关联分析时,区域暴雨过程与历史灾情案例发生的区域要有一定的空间相似性。利用相似分析方法评估四川盆地区域性暴雨过程的灾情是一个比较理想的方法,而过程相似方法在台风[20-21]、干旱[22-24]等灾害影响评估方面已经有相关研究,在区域性暴雨灾害评估方面的相关研究还比较少。
本文将建立一个四川盆地区域性暴雨过程相似度指标,并探索利用该指标开展灾害影响评估,以期建立一套快速准确的灾情评估方法,提高四川盆地区域性暴雨过程监测评价业务能力,为气象防灾减灾决策服务提供科技支撑。
1 资料和方法
1.1 资 料
本文使用了1961-2018年四川盆地104个县级气象站逐日降水量资料,以及从四川省气候中心搜集整理的四川盆地区域性暴雨过程灾情资料中提取了1991-2018年的灾情较完整(包括受灾人口、农作物受灾面积和直接经济损失)的23次暴雨过程灾情资料。
1.2 方 法
王春学等[10]提出了集中暴雨站点的概念,并制定了综合强度指数。如果A站的24 h雨量R24≥50 mm,并且距离该站最近的10个站中,有3个及以上站点的R24≥50 mm,则A站为一个集中暴雨站点。如果集中暴雨站点数N≥15,则该日为一个区域性暴雨日。
降水量为
Ipre=(P1+P2+…+Pj)/nj=1,…,n
(1)
式(1)中,n为集中暴雨站数最多日的集中暴雨站数,Pj为其中第j个观测站点在本次区域性暴雨过程中的总降水量。
降水强度为
Ipin=(max(P241)+max(P242)+…+max(P24j))/nj=1,…,n
(2)
式(2)中,max()为取最大值函数,P24j为第j个观测站点在区域性暴雨过程中最大的24 h观测降水量。
降水范围为
Icov=n/N
(3)
式(3)中,N为总观测站点总数。
持续时间为
Idat=m
(4)
式(4)中,m为区域性暴雨过程开始日期到结束日期的持续天数(单位:d)
综合强度评价指标为
I=(Ipre+Ipin+Icov+Idat)/4
(5)
公式(5)中各单项指标需要先进行标准化处理。
2 结果分析
2.1 区域性暴雨过程相似度指标构建
如果2次区域性暴雨过程发生在不同的区域,即使强度、时间等指标均相似,其造成的影响也可能相差甚远。所以评价2次区域性暴雨过程相似与否的首要指标应该是区域重合率,其次是降水量和降水日数。综合考虑利用这3项指标构造相似度指数,各单项指标的定义如下。
重合率项:
C=2×A1+2/(A1+A2)
(6)
A1为过程1的集中暴雨站点数,A2为过程2的集中暴雨站点数,A1+2为2次过程重合的集中暴雨站点数。
降水量项:
R=2×R1+2/(R1+R2)
(7)
R1为过程1的集中暴雨站点总降水量,R2为过程2的集中暴雨站点总降水量,R1+2为2次过程重合集中暴雨站点的总降水量。
降水日数项:
D=|D1-D2|/(D1+D2)
(8)
D1为过程1的持续天数,D2为过程2的持续天数。
构造不同的相似度指标:SD1=C,SD2=C×R,SD3=C×(1-D),SD4=C×(R-D),并给出不同相似度指数与暴雨过程综合强度差值散点图(图1)。理论上如果相似度越高,则综合强度差值应该越小。由图1可以看到,单独使用重合率(图1a)和使用重合率加降水量(图1b)时,线性拟合的斜率均呈正值,即出现了相似度越高综合强度差值越大的情况,显然是不合理的。当使用重合率加降水日数(图1c)和使用3项指标(图1d)时,线性拟合的斜率均为负值,即表现出了重合率越高综合强度差异越小的对应关系,其中后者的规律性更强,并且通过了0.01的显著性检验,所以确定相似度指标计算公式为

图1 不同相似度指标与暴雨过程综合强度差值散点图
SD=C×(R-D)
(9)
上文分析中使用的是所有样本,如果两次过程发生在不同的位置或者重合率很低,那么二者的相似度一定很小,但是二者的暴雨综合强度差值则不一定很大,所以应该排除这些样本。利用重合率对原始样本进行筛选,结果见图2。从图2中可以看到,重合率从0到70%的变化过程中,拟合度随重合率的增加缓慢增大,当重合率超过70%后拟合率出现跳跃式增大。图3是在图1(d)的基础上选择了重合率大于70%的样本,可以看到相似度越高综合强度差值越小的规律更加明显,拟合方程相关系数达0.66,通过了0.001的显著性检验,即从侧面说明了相似度指标的合理性。

图2 拟合度和样本量随重合率的变化

图3 重合率超过70%的样本中相似度与综合强度差值散度图
2.2 相似度指标与灾情的关系
前文从理论上对相似度指标进行了设计和分析,表明包含3项指标的相似度指数最合理,但还需要进一步利用实际灾情资料对其进行检验。考虑到灾情资料的统一性和权威性,本文使用了1991年以来四川省民政厅、中国气象灾害大典(四川卷)和气象灾情直报系统上的23次区域性暴雨过程灾情统计结果,最终选择受灾人口、农作物受灾面积和直接经济损失3项灾情指标进行验证(表1)。
本研究共搜集到23次具有详细灾情记录的区域性暴雨过程。首先将这23次过程两两组合计算相似度,可以得到253组相似度样本,然后利用重合率进一步筛选,发现重合率超过40%的有34组,但涉及所有的灾情样本,所以这里仅研究这34组样本。两次区域性暴雨过程的相似度高,代表两次过程发生的位置、强度等均相似,所以其致灾能力也应该相当。进一步分析相似度与灾情损失差值的关系(图4)发现,受灾人口差值、农作物受灾面积差值和直接经济损失差值都与相似度成反比,即两次区域性暴雨过程的相似度越高,二者灾情损失越接近。从相似度与3种灾情差值的线性拟合来看,都通过了0.05显著性水平检验(R2=0.11),其中与受灾人口差值的拟合度最高。
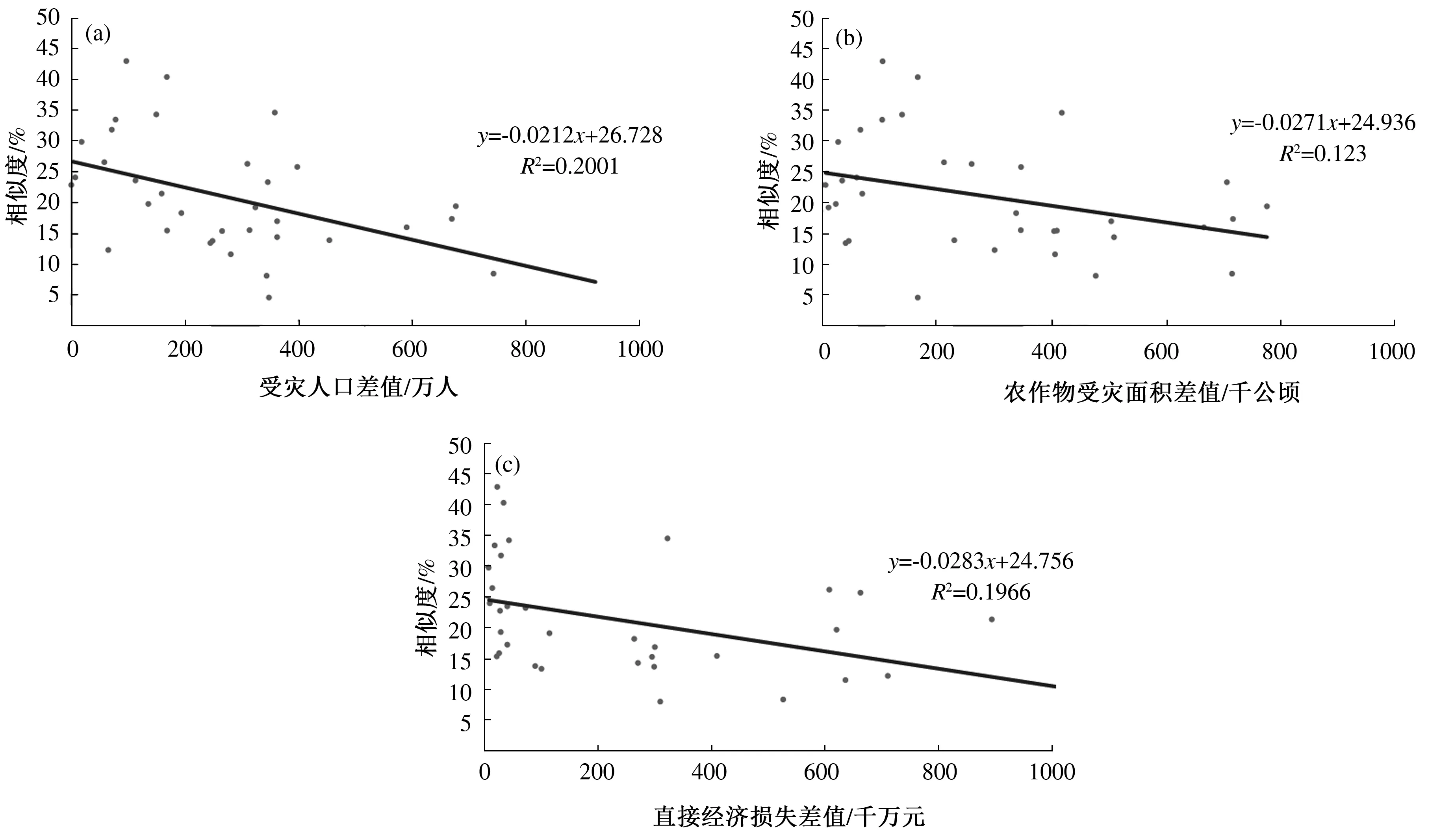
图4 重合率超过40%的34组样本中相似度与受灾人口差值(a)、农作物受灾面积差值(b)和直接经济损失差值(c)散点图
在有灾情资料的23次过程中,1999年8月9日和2017年8月7日两次过程的相似度最大,但是相似度也仅仅达到42%。从2次过程空间(图5)分布来看,第1次过程主要发生在四川盆地南部,中心区域降水量超过130 mm,第2次过程有两个降水区域,其中南部区域与第1次过程的范围基本吻合,但是强度偏弱。根据表1中的数据可知,两次过程受灾人口相差97.2万、农作物受灾面积相差52.4千公顷、直接经济损失相差12.4千万元,即两次区域暴雨过程各种灾情损失的量级基本一致,但是实际差值还是偏大,这与相似度偏低相对应。
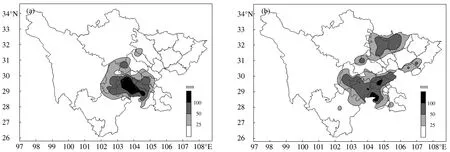
图5 1999年8月9日(a)和2017年8月7日(b)四川盆地区域性暴雨过程降水分布图
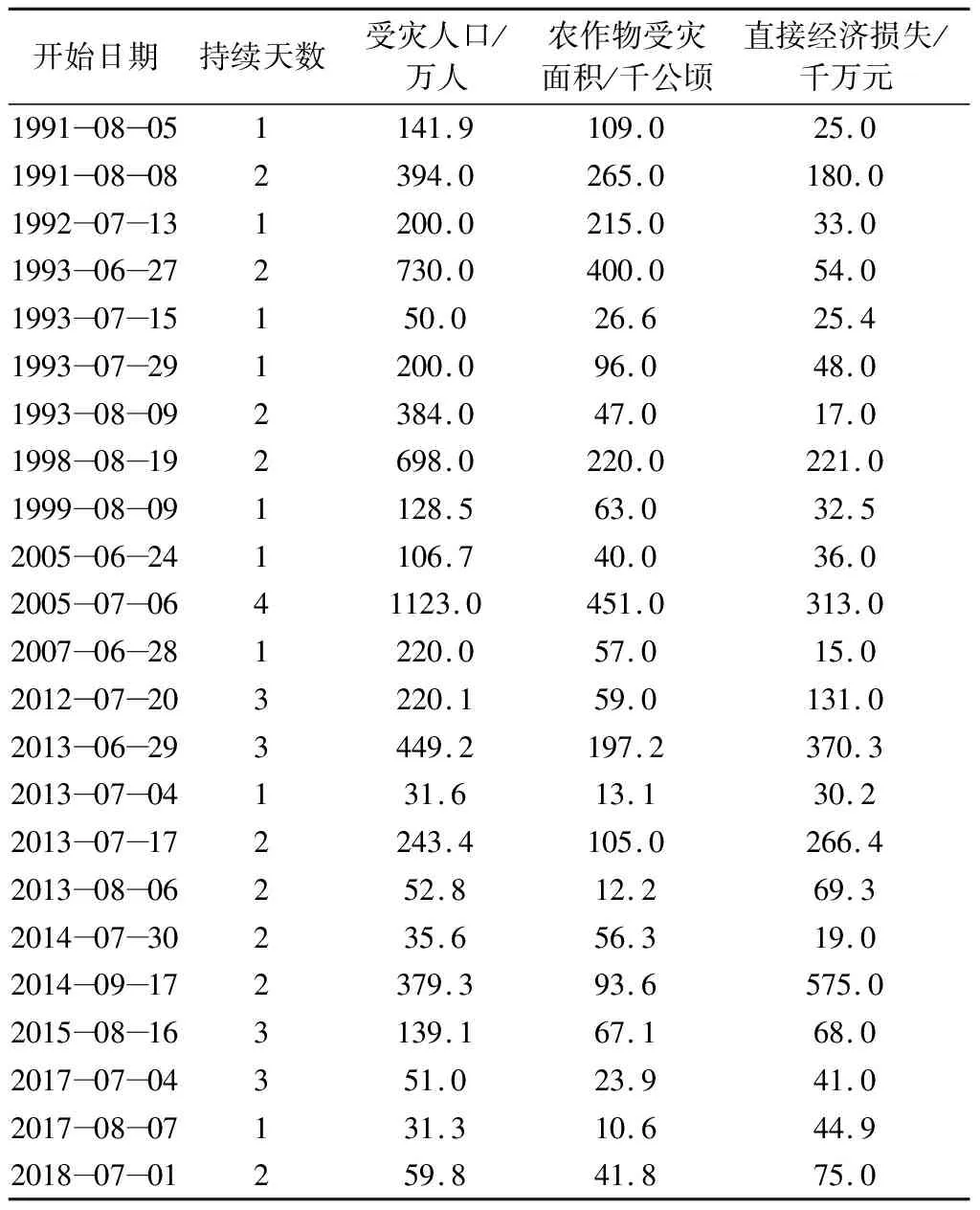
表1 四川盆地23次区域性暴雨过程灾情资料
2.3 相似度指标的应用
利用相似度指标可以快速地找到历史相似案例,可以开展区域性暴雨过程灾前、灾中预评估,或灾害发生后而灾情还没有统计时开展灾后影响评估。理论上相似度指标(SD)的最大值为100%。对某次区域性暴雨过程G1,如果可以找到相似度达到90%以上的历史过程G2,那么完全可以利用G2过程的灾害损失评估G1过程的灾损。由于目前搜集整理的历史区域性暴雨过程灾害资料比较少,相似度的高值在30%~40%,在有限的历史案例范围内利用最相似过程开展灾损评估还无法实现,所以本文将利用前3个相似过程的灾情与相似度乘积的累加值评估G1过程的灾害损失情况,具体公式为
S=A1×SD1+A2×SD2+A3×SD3
(10)
其中S为区域性暴雨过程G的评估灾损,A1、A2、A3分别表示与G前3个相似过程的灾损值,SD1、SD2、SD3分别表示与G前3个相似过程的相似度。
进一步比较评估灾损与实际灾损的差值,从受灾人口差值百分比来看(图6a),23次过程中有17次过程的差值百分比在±2倍之间,有15次过程在±1倍之间,总体来看受灾人口的评估较好。从农作物受灾面积差值百分比来看(图6b),23次过程中有19次过程的差值百分比在±2倍之间,有17次过程在±1倍之间,虽然个别过程差值超过8倍,但是总体来看农作物受灾面积的评估相对更稳定。从直接经济损失差值百分比来看(图6c),23次过程中有9次过程在±50%之间,有20次过程的差值百分比在±1倍之间,只3次过程的差值超过2倍,即直接经济损失的评估效果最好。

图6 23次暴雨过程的评估灾情与实况灾情差值百分比
按照中国气象局发布的《气象灾情搜集上报调查和评估规定》[25],气象灾害可分为小灾、中灾、大灾和特大灾4种。而四川盆地区域性暴雨过程基本上都为中型以上等级,23次过程中有17次过程的气象灾害等级评估与实际相符,一致率达到74%,进一步说明该方法有一定的实际应用价值。
3 结 论
(1)通过对比分析,发现利用重合率项、降水量项和降水日数项3个因子构造的四川盆地区域性暴雨过程相似度指标最合理,重合率从0到70%的变化过程中,拟合度随重合率的增加缓慢增大,当重合率超过70%后拟合率出现跳跃式增大,通过了0.001的显著性水平检验。
(2)使用23次区域性暴雨过程的历史灾情资料对相似度指标进行检验,发现受灾人口差值、农作物受灾面积差值和直接经济损失差值都与相似度成反比,相似度与3种灾情差值的线性拟合都通过了0.05的显著性水平检验。其中1999年8月9日和2017年8月7日的区域性暴雨过程相似度为42%,是23次过程中相似度最大的两次过程,第1次过程主要发生在四川盆地南部,中心区域降水量超过130 mm,第2次过程有两个降水区域,其中南部区域与第1次过程的范围基本吻合,但是强度偏弱。两次过程受灾人口、农作物受灾面积和直接经济损失的量级基本一致。
(3)进一步利用相似度指标建立了灾损评估模型,并使用23次实况过程进行了应用检验。结果发现,有15次过程的受灾人口差值百分比在±1倍之间,17次过程的农作物受灾面积差值百分比在±1倍之间,20次过程的直接经济损失差值百分比在±1倍之间,评估效果均比较理想。另外,按照气象灾害评估分级标准,23次过程中有17次过程的气象灾害等级评估与实际相符,一致率达到74%。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
成都信息工程大学学报(2021年4期)2021-11-22
成都信息工程大学学报(2021年4期)2021-11-22
成都信息工程大学学报(2021年1期)2021-07-22
中国商界(2017年4期)2017-05-17
电子制作(2017年10期)2017-04-18
成才之路(2016年18期)2016-07-08
体育科技(2016年2期)2016-02-28
电气世界(2009年7期)2009-08-28
资本市场(2008年8期)2008-10-30
