
基于瑞芯微平台的Yolov4 tiny改进和加速
2021-09-16 04:44张利红吴柔莞蔡敬菊
科学与信息化 2021年23期
张利红 吴柔莞 蔡敬菊
1.中国科学院光电技术研究所 四川 成都 610209;2.中国科学院大学电子电气与通信工程学院 北京 100049
引言
随着物联网、5G应用的发展,终端的目标检测算法落地需求不断增强。自2012年以来,以AlexNet[1]网络为代表的深度学习算法成为研究主流;2013年Girshick提出基于区域卷积网络的RCNN框架获得更好的特征提取能力[2],随后在RCNN框架上诞生了SPPNet[3]、Faster-RCNN[4];近两年Joseph Redmon[5-7]等人提出的YOLO系列算法解决了不同尺度的目标检测问题,基本上保证检测的实时性。但基于深度学习的目标检测算法参数量过大和网络结构复杂,受限于终端设备的硬件资源无法直接运行未经优化的模型[8-10]。为了尽量减小在嵌入式平台上实际应用中的功耗和性能开销,嵌入式系统上部署目标检测算法需要从核心算法和硬件开发平台两方面进行选取。
在硬件平台方面,长期以来国外厂商在芯片的研发应用上占据优势,国内嵌入式设备的开发环境尚不完备。当前科研常用设备也多为ARM的big.LITTLE系列,Xilinx的FPGA或NVIDIA的Jetson TX1、TX2系列。为发展自主可控的技术平台,在国产嵌入式平台进行深度学习算法的部署落地也成为重要的课题[11-12]。rk3399pro是瑞芯微电子开发的专门针对AI终端推理的国产芯片,采用大小核处理器内嵌NPU神经网络处理器的方案换取高性能、低功耗和高扩展性,兼具高速总线PCIE和超强的视频编解码能力。以上特点使其适用于目标检测领域,2020年6月山东大学的丁月[13]利用Yolov3 tiny在640*480的图像中实现30帧/秒的检测速度。
近年学者在算法方面主要提出两种方案:一是从算法结构进行改进,采用可分离卷积、分组卷积等方式降低参数量和计算成本。这类方案以谷歌提出的MobileNet[14]、斯坦福提出的SqueezeNet[15]为代表。二是对已有模型进行剪枝压缩剔除对检测效果影响较小的参数结构,比如8位定点量化、模型蒸馏等。两者衍生的大量改进的轻量化神经网络部署到终端设备上的检测精度已基本达到标准,但如何针对特定平台的进行算法改进,以更少的资源占用率实现检测速度和精度的平衡尚未被系统研究[16-19]。
目前关于深度学习的目标检测算法主要分为以下两类:基于深度学习的双阶段检测算法和基于深度学习的单阶段检测算法。其中,Yolo系列[5-7]算法将候选区域生成阶段省略掉,直接将检测任务视为回归问题进行端到端的检测,检测速度和精度相对其他深度目标检测算法在终端设备上进行部署更占优势。Yolov4[20]算法在yolov3的基础上通过替换主干特征提取网络、Mosaic数据增强、更换激活、损失函数、标签平滑等方式,利用图形处理器(GPU)进行训练推理工作,取得了权重参数量和性能最佳平衡。但在部署至终端时,如果不针对应用平台进行改进,硬件推理仍会耗时过长。
本文选定Yolov4 tiny为模型结构基础,针对国产rk3399pro芯片架构特点对算法进行改进,并对算法在平台上的运行方式进行优化,提供了一种Yolov4 tiny算法在瑞芯微平台上实时目标检测的较优方案。
1 瑞芯微平台及Yolov4 tiny算法分析
1.1 瑞芯微RKNN工具链
瑞芯微提供的RKNN工具链可支持对深度学习算法的快速移植和应用开发。该工具链通过调用API(Application Programming Interface,应用程序接口)接口的方式对硬件寄存器、MAC(Multiply Accumulate,乘数累加器)等电路单元进行控制,省去复杂的底层芯片处理工作,支持将训练的caffe、Tensorflow等主流模型转换为RKNN模型,进而使瑞芯微平台能够加载推理。
瑞芯微RKNN工具链的应用开发流程如图1所示,主要分为模型训练、模型转换、模型推理三部分。通过主流的深度学习模型框架对目标检测算法进行训练,得到较好的MAP(Mean Average Precision,全类平均精度)和recall(召回率);导出模型的参数权重至RKNN Toolkit中转换为RKNN模型;通过调用API接口在瑞芯微平台上加载运行RKNN模型,对模型输出张量进行后处理输出目标检测类别和位置。
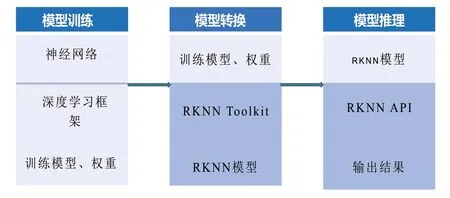
图1 瑞芯微平台开发应用流程图
1.2 Yolov4 tiny算法
Yolov4 tiny算法是Yolov4目标检测算法的精简版,它采用CSPDarkNet53-tiny作为主干特征提取网络提取图像的浅层特征,跨层利用FPN结构作为颈部进行低层和高层特征的特征融合与加强,对输出的两个特征层沿用yolov3检测头部进行分类与回归预测。图2是当输入为416×416的RGB图像时,Yolov4 tiny的特征结构,将输入的图像均分为N×N个网格,若检测目标的中心坐标在某个网格中,则该网格对应完成对此目标的检测,输出B个边界框的模型预测中心坐标、宽高和置信度预测值。在模型训练类别为C类时,Yolov4 tiny输出N×N(5×B+C)大小的张量。
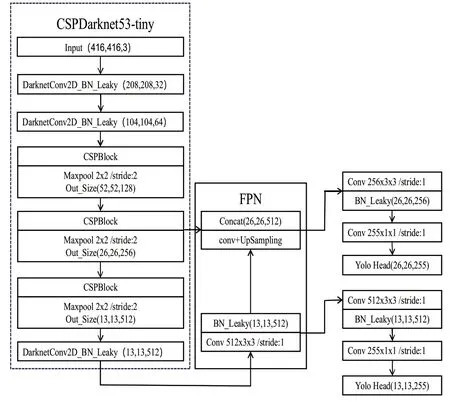
图2 Yolov4 tiny网络结构
相对于Yolov4而言,精简版的Yolov4的参数量缩小为十分之一;但在前期开发测试中发现 Yolov4 tiny直接部署到瑞芯微平台上的速度仅在3~4帧/秒,难以满足实时性需求需要进行改进。
2 基于rk3399pro的算法优化
Yolov4 tiny参数较多、神经网络算子占用硬件资源较大,在实际应用场景下的检测实时性无法被满足。本文结合瑞芯微平台的rk3399pro芯片资源和算法结构特征,从以下方面对Yolov4 tiny算法进行优化。
2.1 数据集处理及先验框聚类
KITTI数据集[21]是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。原始数据集部分类别在图片中像素过小、标注模糊不清,需要对原有的类别标签进行处理,将不需要的类别标签舍弃。在将其归一化为416×416大小时,为避免检测目标的长宽比发生畸变,即图片产生拉伸形变,采用背景填充的方式对训练和测试的图片进行压缩。
Yolov4 tiny原模型中的先验框由coco数据集训练而来,对于应用在自动驾驶场景的数据集而言并不具有普适性。
K-means是一个迭代型的算法距离公式定义为:

其中,A-聚类框大小;B-样本库大小;C-聚类中心;IOU表示A、B交互比。
对标签处理后的KITTI数据集使用K-means算法对目标标注框进行聚类,分析聚类结果后将占比最大的Anchor值作为检测目标先验框类别,Anchor与标注框的平均IOU为67.47%。使用聚类后的标注框进行训练,重复训练5次平均检测精度有了0.56%的提升,如表1所示。
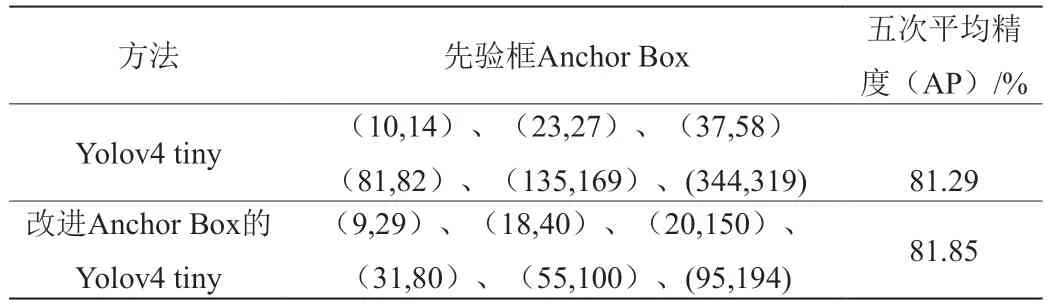
表1 不同anchor box性能对比
2.2 卷积通道数及激活函数改进
深度目标检测算法中的卷积层主要由大量的矩阵乘加运算实现,导致终端推理耗时过多。rk3399pro中有可用于乘加运算加速的专用NPU:支持8bit/16bit运算,运算性能最高可达3Tops,功耗不到GPU所需要的1%。利用NPU对卷积层进行并行计算加速,分析NPU中固定MAC结构特点,在程序编译芯片进行加速运算时,采用3×3的卷积核更有利于实现最高的MAC利用率。基于此,将卷积输出通道数均改为3的倍数。
卷积运算只是将输入图像特征与卷积核做乘加操作,如果不引入激活函数将无法解决线性不可分问题,造成模型的特征拟合能力不足。除了考量非饱和性、参数少、单调性等要求,还要在终端设备构造实现激活函数时计算量少、函数简单尤为重要。
ReLU函数[22-23]的数学表达式如公式(2)所示:
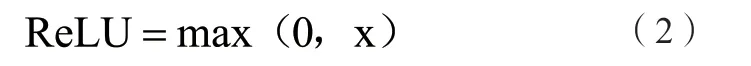
相较于sigmod函数与tanh函数,它的优点在于输入为正数时,不存在梯度饱和;又由于将矩阵内所有负值都设为零,训练传播速度极快。Leaky Relu函数是ReLU的变体,将函数输出负值给予了一个小坡度;虽然这能减少静默神经元的出现,但同时会引入更多的计算量拖延设备检测时间。基于此,将Yolov4 tiny激活函数由Leaky Relu替换为ReLU函数。
NPU会对卷积层、ReLU及MAX Pooling层进行融合,融合示意图如图3所示,使其在硬件加速时被优化融合为一个整体的op (operators,神经网络计算的基本单元) 算子,进而减少计算带宽。
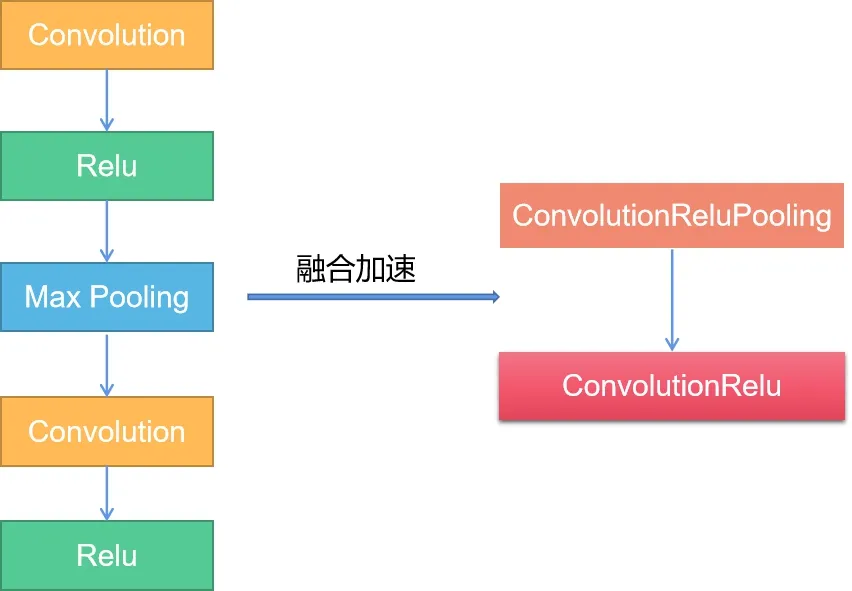
图3 NPU融合op算子加速示意图
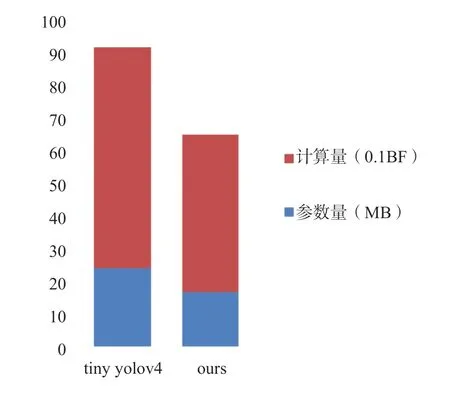
图4 改进前后特征提取网络复杂度对比
改进的模型在KITTI数据集上的map下降了2.29%变为79.56%,但参数计算量下降使得在GPU上的运行速度从169帧/秒提升为225帧/秒。改进后的模型部署到rk3399pro上单核检测速度也仅每秒6帧左右,仍需要对算法运行方式进行优化。
3 终端设备环境搭建与算法运行优化
文中模型训练均采用GPU:RTX 2060 SUPER,CPU:i5-10400,内存16G;python:3.6;CUDA10.1,cuDNN7.6.5,opencv:3.4.5;终端设备:瑞芯微rk3399pro。为防止单次模型训练中存在的误差,文中数据均是经过5次平均后的结果。
3.1 终端设备环境搭建
在rk3399pro中调用运行Yolov4 tiny需要操作系统同应用软件配合。操作系统需移植debian系统、裁剪后的ARM-linux内核,安装NPU支持的固件版本、深度学习网络需要的开发环境和库文件。应用软件方面需建立和PC间的交叉编译环境,安装Opencv、Qt、Cmake-gui,使用minicom传输模型文件。
终端设备系统环境就绪后,将目标检测算法模型按照RKNN模型移植的步骤创建RKNN对象,启动设备载入RKNN模型,调用接口初始化RKNN SDK开发环境对输入的图像预处理后进行推理计算,对模型输出张量后处理得出检测目标和类别。
3.2 模型量化
rk3399pro支持的模型量化方法有非对称量化(asymmetric_quantized-u8)、动态定点量化(dynamic_fixed_point-8)和dynamic_fixed_point-16)三种。前两种量化方式属于计算公式不同的8位量化,但对大部分网络而言非对称unit8量化对网络精度损失最小[24]。
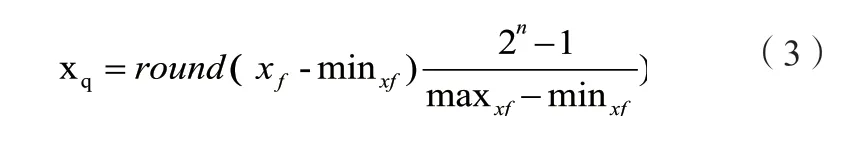
上述公式(3)中,xf代表float32类型数据,n表示量化数据的bit,xq表示最终量化值。
当对8位定点的精度损失过大时,也可利用NPU中的300Gops int16的计算单元对dynamic_fixed_point-16量化而来的卷积层进行加速。
对模型采用不同的量化方式可以发现,不同量化方式转换后的模型大小如图5所示,使用8位定点量化的模型大小将减至原模型的1/4。将FP32的浮点数张量转化为uint8张量,有助于减少内存带宽和存储空间,并进一步提高系统吞吐量降低系统延时。
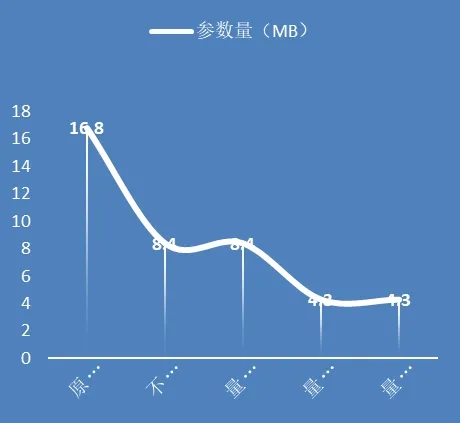
图5 Our yolov4 tiny模型不同量化参数比较
3.3 CPU-GPU-NPU多线程协同计算
rk3399pro采用big.LITTLE大小核CPU架构,拥有双核A72加四核A53,四核GPU Mail-T860。本文采用CPU-GPU-NPU多线程协同计算方案优化算法运行速度,即:①图像获取与预处理;②数据推理;③数据后处理与显示。以上三种分支结构中计算复杂度最高的就是数据推理,数据推理中的卷积计算占到整个目标检测系统90%的计算量,应交由NPU工作;其余两个分支结构都与图像处理相关,交由GPU实现。而CPU则负责系统调度,协调各个预算单元降低GPU功耗和NPU负载。在开发测试过程中发现,NPU专注推理加速时整个模型推理过程耗时将极小,而图像预处理和后处理时间较长。本文将利用两个大核分时复用NPU对GPU预处理的图像数据进行推理,随后小核调用GPU进行数据后处理和显示,如图6所示。
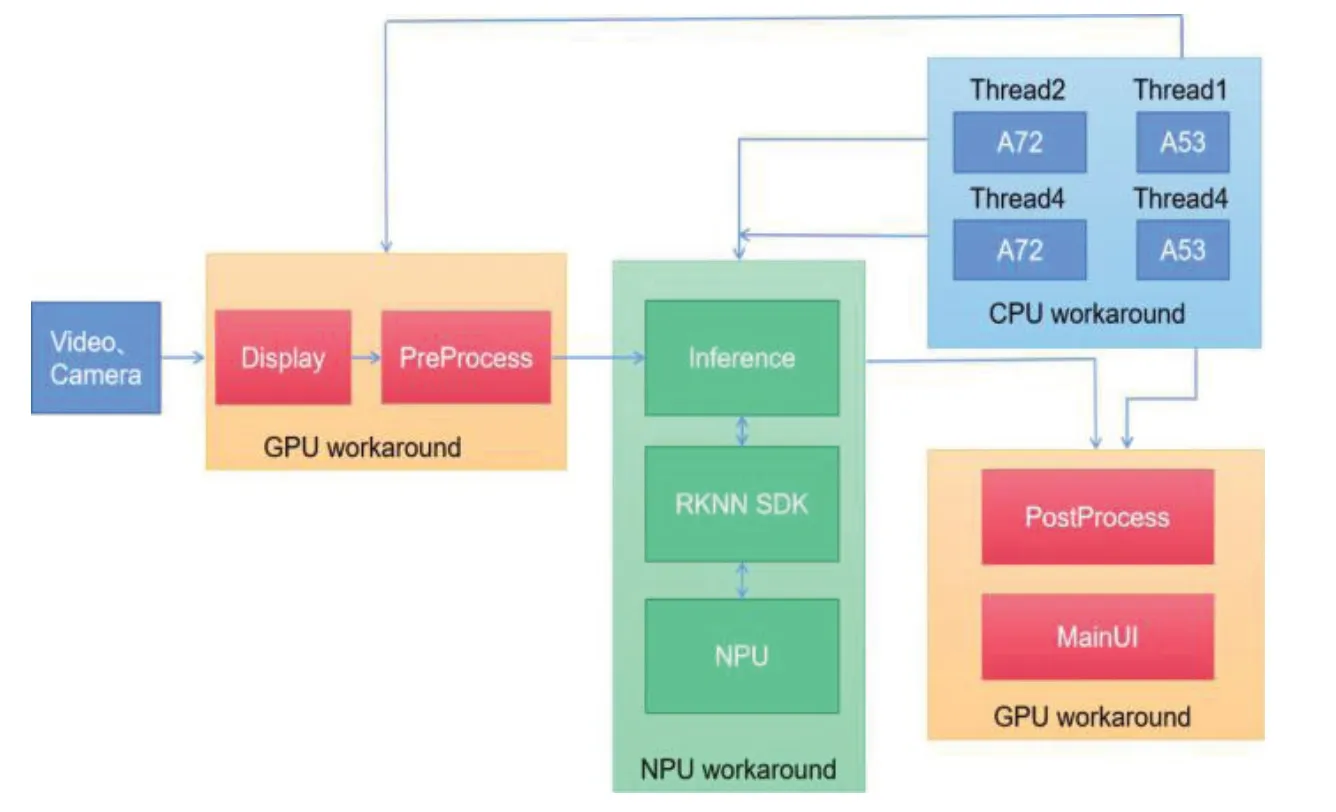
图6 CPU-GPU-NPU协同计算图
并在平台上进行验证不同的量化方式与是否使用线程在不同模型上的检测速度。
实验证明采用不同的优化方式在rk3399pro中的检测效果差距极大,检测结果如图7所示。本文使用8位定点量化后的Our yolov4 tiny模型在rk3399pro的理论推理性能达到80帧/s,比不量化的模型提升了12.7倍。在实际检测应用时,由于实验室摄像头最高只能输入每秒60帧的图像,使用python的多进程推理速度接近59帧/s,使用c接口的多线程推理速度接近60帧/s。

图7 不同优化方式检测效果对比
综上所述,本文提出的CPU-GPU-NPU多线程协同计算方案可以有效提升硬件加速效率减少数据传输耗时。
3.4 终端设备精度损失
rk3399pro等终端AI芯片为实现低功耗低成本的推理加速,MAC等电路单元会对神经网络结构进行优化。因此往往在GPU端训练的模型部署至终端设备时会存在精度和性能损失的问题。
验证精度损失的方法主要是对转换后的RKNN模型在开发板上进行推理后,打印出每层网络结构输出的tensor值,与在GPU端推理输出的tensor值进行比较欧式距离或余弦距离,进而判断模型转换的精度损失。但由于在终端设备部署的模型种类繁杂,实际检测中还要考量光线强弱、设备成像等因素,很难具体验证每个模型在实际检测中的精度损失。
在本文中,为将训练的模型具体的部署到rk3399pro平台实际使用;对采用不同量化方式的模型测试单纯在KITTI数据集上的map损失,实验数据可见表2。
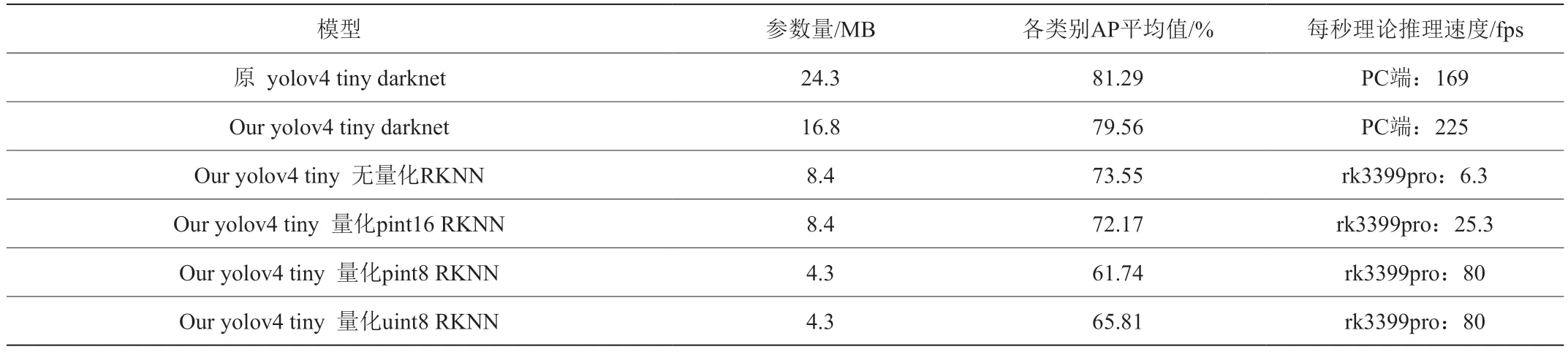
表2 不同模型性能对比
4 实验结果与分析
将经过改进后的模型与官方的Yolov4 tiny模型在rk3399pro端检测静态图像中的效果进行对比,可以发现在设置将经过改进后的模型与官方的Yolov4 tiny模型在rk3399pro端检测静态图像中的效果进行对比,可以发现在设置同样的目标检测阈值和NMS阈值时,本文训练的模型可以实现对目标更精确的定位,在真实道路场景中会遇到的遮挡和截断以及模糊不清等问题都能予以正确识别。
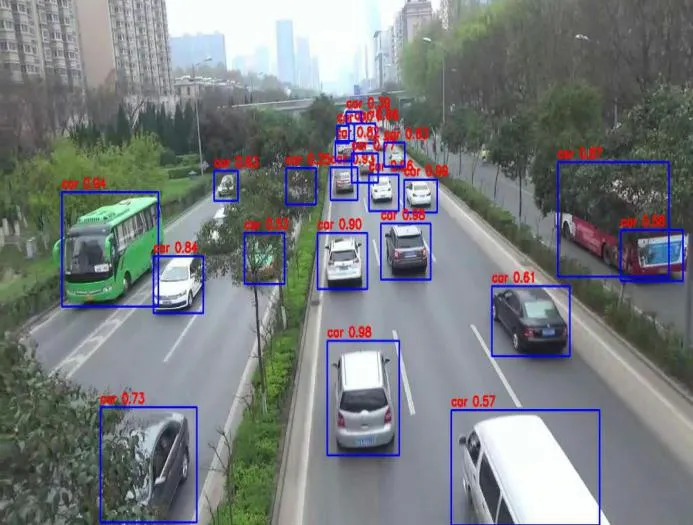
图8 原Yolov4 tiny模型在rk3399pro端检测结果图
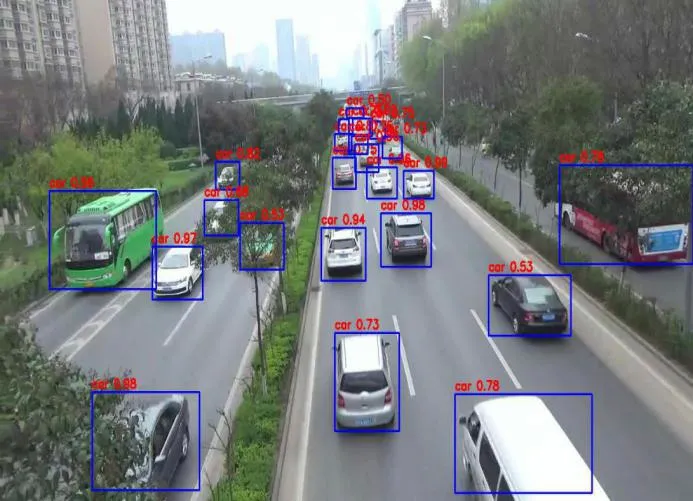
图9 Our yolov4 tiny模型在rk3399pro端检测结果图
而在动态的视频检测中,对改进后模型在终端设备上的运行方式进行优化后,采用CPU-GPU-NPU多线程协同计算方案模型在摄像头采集的实时视频检测速度有了大幅提升,从单线程的15帧/秒提升至60帧/秒。

图10 Our yolov4 tiny模型在rk3399pro端单线程摄像头检测结果图

图11 Our yolov4 tiny模型在rk3399pro端多线程摄像头检测结果图
为了实现Yolov4 tiny模型在瑞芯微平台中部署应用,针对原模型存在的参数过多问题,采用修改网络和量化相结合的方式去除数据冗余,并验证不同的优化方式在设备上检测KITTI数据集的精确度。
实验证明:Yolov4 tiny模型经过非对称8位量化后虽然map精度从PC端的79.56%降至终端端的65.81%,但网络大小可从原始的16.8MB减少至4.3MB大小,理论模型推理速度从6.3fps/s提升至80fps/s;在瑞芯微平台上取得了理论检测速度和精度的较优平衡。
同时为了验证本文提出的算法改进和模型运行优化的方式具有一定普适性,在yolo系列的其他轻量化网络进行相同的实验。
数据结果如表3所示,证明以上改进方式在国产rk3399pro平台上部署轻量化目标检测算法提供了理论和技术支持。

表3 改进yolo系列轻量化模型前后检测效果对比
5 结束语
本文针对rk3399pro芯片结构特点对Yolov4 tiny 模型在卷积核通道数、激活函数等处进行改进;改进后的模型与原模型精度相近但检测速度大幅提升。同时搭建了交叉编译环境,将GPU端训练的模型通过工具链转换为RKNN模型;并探索了不同的量化方案、多核并行等优化方式对于代码运行的速度提升效果,优化方法在不同模型上的通用性等。研究可得,针对本文的目标检测算法,采用非对称8位量化、多线程并行、神经网络算子融合等方式可以大幅提升终端设备端的检测速度,实现鲁棒精确的检测效果。
本文针对Yolov4 tiny这一模型进行改进并实际应用在rk3399pro上,但对除了yolo系列之外的轻量化深度目标检测模型的通用改进方式并未做研究,日后将在这方面进行探索。
猜你喜欢
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
科技创新导报(2016年26期)2017-03-13
科技创新与应用(2016年34期)2016-12-23
电子技术与软件工程(2016年20期)2016-12-21
电子技术与软件工程(2016年20期)2016-12-21
