
基于组合优化的Kriging参数估计算法
2021-09-15 02:36王红
计算机与现代化 2021年9期
王 红
(大连东软信息学院计算机学院,辽宁 大连 116023)
0 引 言
数学模型是理解复杂系统的结构、功能,并对系统行为进行设计、优化和控制的重要工具[1-2]。实际生产中的很多数学模型包含了大量的参数,由于实验条件及经费的限制,很多参数不能从实验中直接获取,因此必须依靠优化方法根据已有的实验数据对这些参数进行估计来获得。当模型具有强非线性以及sloppiness属性(即模型的行为只由少数几个刚性参数的组合便可决定)时[3],参数估计过程中的大部分迭代过程都发生在目标函数的平原区域,参数的更新可能把参数推向其取值范围的边界值,此时耗费大量的优化时间但目标函数值的变化却很不明显[4]。当模型以常微分方程组(ODEs)形式描述时,由于模型响应与待估参数之间的关系无法以显示函数的形式表达,所以需要使用数值积分计算,而优化过程中频繁的积分运算会消耗大量的计算时间[5],特别是当常微分方程组具有刚性(stiff)特征时,求解时间可能会占据优化总时间的95%[6]。
为了减少优化过程中进行积分计算所耗费的时间,可以通过一定数目的训练样本构建待估参数和目标函数之间的近似关系,即所谓的代理模型[7]。这样在参数估计的优化过程中,用这些代理模型函数替代原有的目标函数进行迭代优化,就不再需要计算数值积分过程,从而大大地节省了优化时间。也就是说,基于代理模型进行参数估计的常规思路是分为2个阶段:1)代理模型构建;2)基于代理模型进行参数估计。
但仅依赖初始训练样本构建的代理模型很难达到预期精度要求。因此,需要依据加点准则借助优化算法查找增加新的样例点,通过新增样例点更新模型以提高代理模型精度[8-9]。如果采用的加点准则能充分考虑目标函数局部与全局的平衡关系,则用于精化代理模型的新增样例点有可能就是目标函数的全局最优解。也就是说,在增加新样例点精化代理模型的过程中同步完成了参数的优化过程,即将前面的2个阶段合成了一个阶段。
在所有的代理模型中,Kriging代理可以等价于任何阶的多项式函数,因此非常适用于求解具有多个极值的非线性函数插值问题[10]。本文基于Kriging代理模型估计ODEs类型函数的参数,以解决ODEs积分时间长的问题,同时组合Adam及SGD with momentum这2个算法的优势,搜索新样例点更新代理模型,以提高最优查找速度及收敛时间。
本文主要工作:
1)介绍Kriging代理模型的一般构成及影响模型优化结果的3个重要因素即初始样例集合、加点准则及新增样例点的优化算法。
2)介绍混合Adam&SGD的优化算法。
3)介绍将混合Adam&SGD的优化算法和Kriging代理模型结合的具体过程。
4)在计算结果部分首先介绍验证本文算法的算例血管中性粒细胞模型,然后给出了本文提出的优化算法对该模型中参数进行估计的结果,并将该结果和其他优化算法进行比较。
5)总结概括了本文的算法及下一步的工作方向。
1 算 法
1.1 Kriging代理模型
Kriging代理模型[11]是基于回归分析技术提出的,整个函数由代表全局趋势函数和表征局部特点函数2个部分构成,其中FT(x)βf为全局趋势函数,Z(x)为局部特征函数。全局趋势可以用常数或低阶多项式表示,而局部特征函数Z(x)是一个动态随机过程,服从式(2)所示的高斯分布。
f(x)=FT(x)βf+Z(x),x∈Rm
(1)
(2)
式(1)中,F(x)是不同取样点x所对应的目标值所构成的集合,βf是和F(x)对应的因子向量。式(2)中,R是相关函数,根据式(2)所示,在样例集合S=[x1,x2,…,xn]及对应的目标值集合F=[f1,f2,…,fn]已知的情况下,任给数据点xnew,根据已构建的代理模型,可知该点的目标预测值为式(3):
fp=CF
(3)
其中,C是权重系数,代表样例集合中每个点对新点xnew的贡献度。根据Kriging的估计具有无偏性及最优性2个特征,可推导出期望为0时,预测值和真实值之间的差平方和最小。据此可将式(3)细化为式(4),其中σ2是预测值与真实值之间的方差估计。
fp=σ2-λT(FTC-f)
(4)
通用Kriging的优化算法流程如图1所示。在图1所示的流程里,对最终优化结果起到影响作用的因素包括3个:
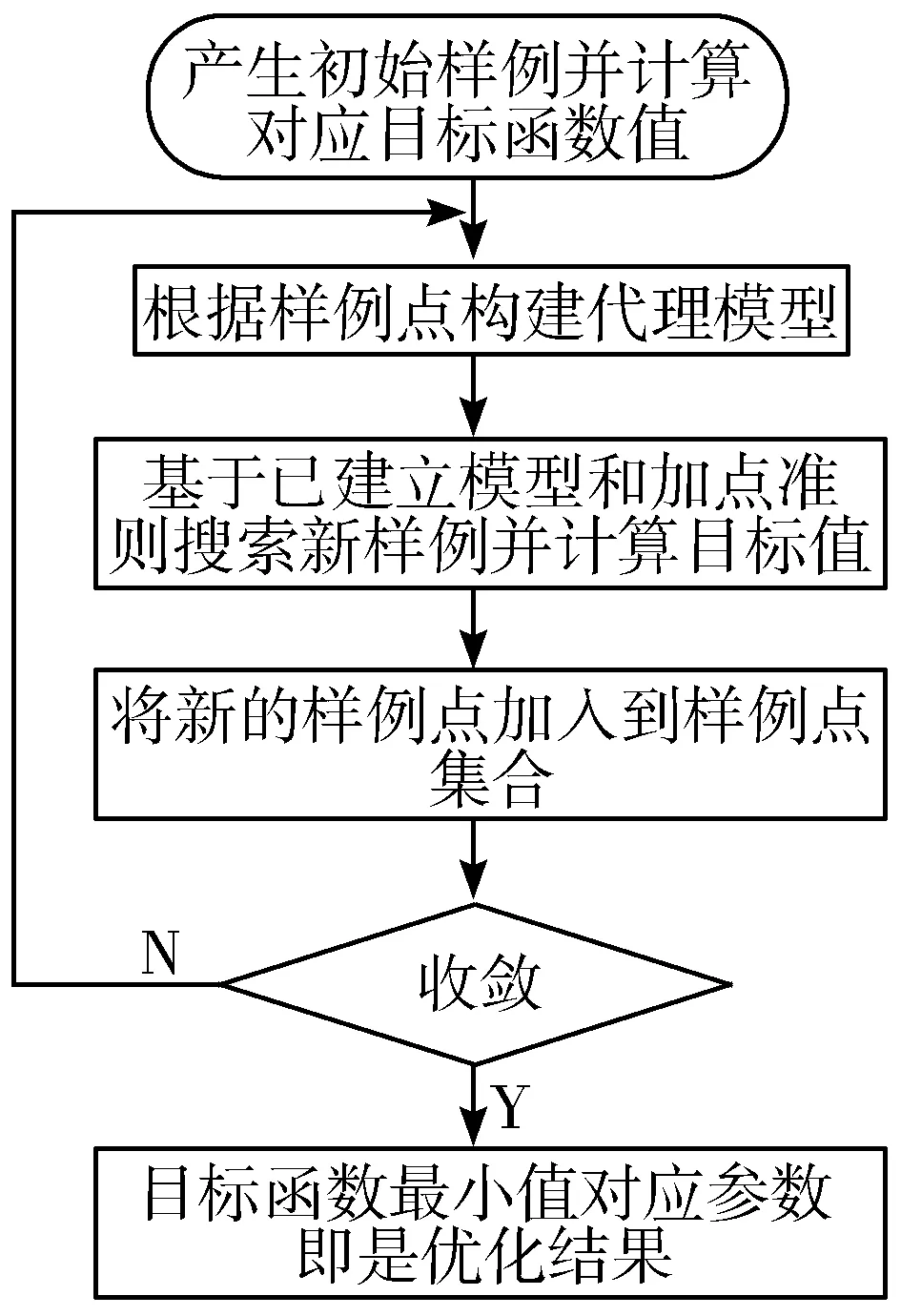
图1 常用Kriging优化算法流程
1)构建初始代理模型的样例点集。其中初始样例点集合的好坏不仅决定了模型的优劣还直接影响了后续模型寻找最优值的优化速度,因此要求初始集合点应该能提供足够多的信息量,即在对参数空间没有任何先验知识的前提下尽量均匀取样。
2)加点准则。加点准则是选择新样例点的基本标准,该标准就是优化算法的目标函数。作为一种基于高斯过程的代理模型,Kriging代理可以在优化过程中确定模型的不确定性,因此能预知在参数空间的哪些区域增加新的样例点可以提高构建模型的精度。常见的加点准则有可能提高加点准则(PI)[12]、期望提高(EI)[13]和广义期望提高(GEI)[14]等。
3)新增数据点的优化算法。新增数据点的优化算法是基于Kriging代理模型优化中讨论最少的议题,针对非线性问题,通常可以采用已经存在的任何优化算法。
1.2 混合Adam&SGD的优化算法
所谓参数估计就是借助于某种优化算法,通过最小化目标函数找到一组参数值p,以和实验数据最好地拟合。以常微分方程组形式呈现的参数估计问题可以表示为:
(5)
其中,x代表ODEs,p是待估计参数,f是ODEs右侧函数。xei(tj)代表tj时刻实验值,xi(tj,p)代表tj时刻计算值,N是样例点数目,n是ODEs的数目,PU和pL代表参数取值范围的上下限。由于f的非线性特性,因此x很难有解析解。
机器学习也是一种代理模型,其中一系列的优化算法各具特色。动态梯度下降法(SGD)[15]是其中最简单的优化算法,又称小批量梯度下降法。通过计算目标函数对已有参数的梯度方向,并将其作为参数更新下降的最快移动方向,公式表示为:
(6)
这里的α是尺度系数,决定了在最大下降方向上的步长。mt和Vt分别代表一阶动量和二阶动量,而gt是目标函数相对于参数的梯度。该增量通用公式适用于机器学习中的所有优化算法[16]。
对目标函数比较简单的优化问题,梯度下降法收敛效果比较好,而对于参数以千计算的优化问题来说,梯度下降法可能是唯一的选择[17]。但该方法在遇到V型搜索区域时,会在波谷两侧递增持续震荡,浪费大量的迭代时间,最后可能还会停留在一个局部最优点。针对SGD在峰谷震荡的情况,引入Nesterov提出的梯度加速法[18],通过修改梯度的计算公式为式(7),将未来即将走到的点梯度方向与历史累积动量相结合,以达到预看多一步的目的。
(7)
同时为提高下坡时的优化速度,可在梯度下降过程中加入惯性[19],此时一阶动量修改为式(8)所示,使得当前点的梯度下降方向由累积下降方向与当前下降方向共同决定。
mt=β1·mt-1+(1-β1)·gt
(8)
以上SGD及其变形都是针对原有算法中存在的问题,基于一阶动量提出的改进。为提高算法的收敛速度以及使其具有自适应的特点,Adam算法[2]在步长更新中引入二阶动量即梯度方差元素,修改如式(9):
(9)
该算法适用于处理大型数据及稀疏数据,但缺点是二阶动量Vt不是单调变化,因此最终可能不收敛,而且可能会错过全局最优解[20]。
考虑一阶动量和二阶动量的各自优势,Keskar等人[21]提出可以将二者组合,同时享有Adam优化速度快和SGD最终收敛的双重优点。本文利用该思路,将其作为寻找新增点的优化算法。算法流程如算法1所示。
算法1 本文寻找新增点的优化算法的流程
输入:设定优化过程所需初始参数
输出:待增加点集合
过程:
1.计算目标函数相对于各参数的梯度。
2.每循环10次按照特定规律减小学习率。
3.判断是否切换到SGD算法,否就跳转到步骤4,是就计算SGD学习率后,跳转到步骤5。
4.执行Adam算法,得到参数变化量。
5.执行SGD算法,得到参数变化量。
6.参数更新。
7.优化算法是否收敛,如收敛跳转到步骤8,否则跳转到步骤1。
8.得到待增加点集合。
其中算法Adam和SGD切换条件需满足式(10):
(10)
即Adam算法当前的学习率和平均学习率特别接近时,表示应该由Adam算法转化为SGD算法。转换之后SGD学习率采用式(11)计算,其中gt是梯度。
(11)
1.3 混合Adam&SGD优化算法的Kriging代理模型
使用混合Adam&SGD优化算法的Kriging代理模型流程如图2所示。
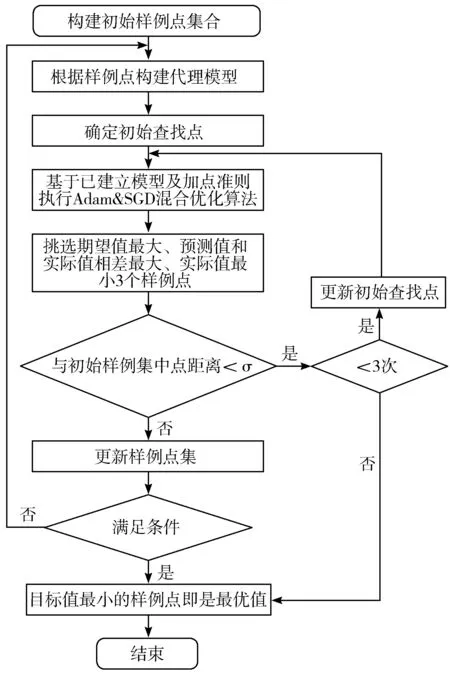
图2 混合Adam&SGD优化算法的Kriging流程

(12)
为提高建模速度,这里采用多点加点原则,每次增加3个点,即GEI值最大的点、实际值与预测值相差最大的点、目标函数值最小的点用来充实模型构建样例点集。
2 计算结果
2.1 算例介绍
本文使用血管中性粒细胞(PMN)[22]代谢模型作为检测算法有效性的算例。该模型使用13个常微分方程组表示细胞中的酶促反应动力学特征即米氏方程,该方程具体如式(13)和式(14):
(13)
其中,[S]是底物浓度,[Et]是酶的整个浓度,Kcat是酶的转换数,Km是米氏常数。而加入可逆抑制剂后式(13)可转化为式(14)。其中[I]是抑制剂的浓度,KI是抑制常数。
(14)
在13个方程中共含有41个参数。根据这些参数在酶促反应中承担的角色不同将其分为8个类别,不同类别的取值范围从跨越2个数量级到跨越6个数量级变化不等,具体信息如表1所示。
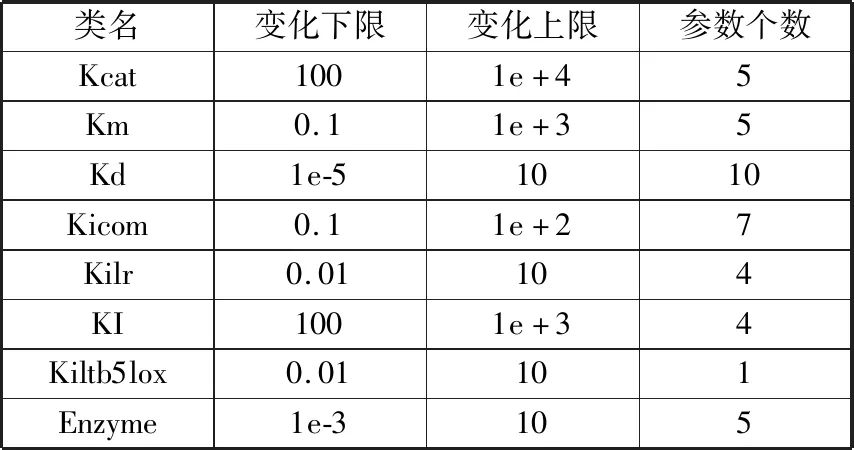
表1 待估计参数信息
因为这41个参数的值无法通过实验获取到,只能通过优化算法对其进行数值估计。本文使用基于混合Adam&SGD优化算法的Kriging代理模型对这8个类别中的41个参数值进行估计。
因为没有实验测量得到的参数真实数值作为比对,因此参数估计结果的优劣只能通过目标函数值的大小进行衡量,后续的结果说明就是基于这样的前提完成的。
2.2 计算条件设定及结果说明
初始样例采用确定性均匀分布与随机性均匀分布相结合方式来生成,考虑PMN模型中有的参数变化跨越几个指数级别,因此取对数后均匀取样。抽取4组样例,样例信息如表2所示。
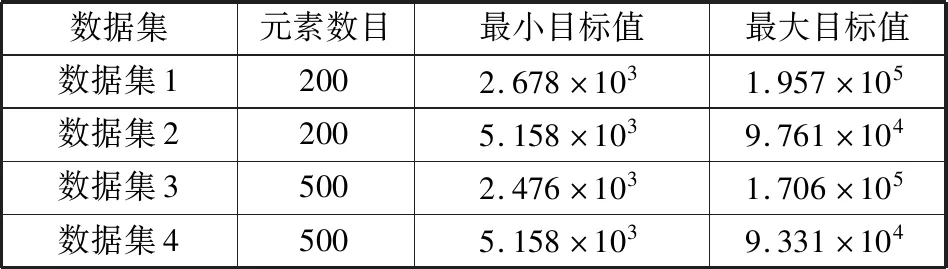
表2 4组样例信息说明
算法优化终止条件有3个:1)满足式(15);2)迭代次数≥30;3)连续3次无新样例点加入。其中终止条件中的第2个是为了体现资源受限的特征而设置的。
(15)
算法开发平台是Matlab2009b,CPU是Intel(R) Core(TM) 4.2 GHz。
因为PMN模型的高度非线性所以很难有解析解,在求解雅可比矩阵时需要使用数值形式计算多次积分,可能会增加积分时间。为节省计算时间,本文利用Broyden[23]提出的拟牛顿根发现法来估计雅可比矩阵。该方法最大的特点就是依赖前次矩阵值可以计算出本次矩阵值,具体如式(16):
(16)
其中,ΔOi是目标函数变化,Δpi是参数值变化。为避免累计误差,算法每5次迭代执行后重新计算该矩阵值。
为验证本文优化算法对Kriging代理模型的有效性,本文选择SSMGO(SS)[24]、Matlab工具箱自带的fmincon (FM)、SGD with Momentum(SM)[19]及Adam(AD)[2]这4种算法与本文算法进行比较。针对这5种算法,在4组集合上各执行3次。对每种算法的运行结果,挑选优化中目标函数最小的那组作比较,结果如表3所示(其中初值指初始目标值,终值指优化后目标值)。

表3 各优化算法结果比较
从表3给出的5种算法比较结果可以得到如下结论:
1)从最优解角度看:建模数据集中样例多的优化效果整体好于样例少的;初始数据集中的最小值对某些优化结果有一定影响,但并未看出直接影响关系。大部分情况下本文算法和SSMGO能得到相对好的优化效果。
2)从优化时间看:在同等条件下,数据集中样例数目越少,优化时间也相对短;对5种算法而言,相同数据集条件下,所用时间在同一数量级。本文算法和SSMGO算法所用时间略长于其他优化算法。
以表3中数据集4为例,给出本文算法估计出的41个参数结果值如表4所示。
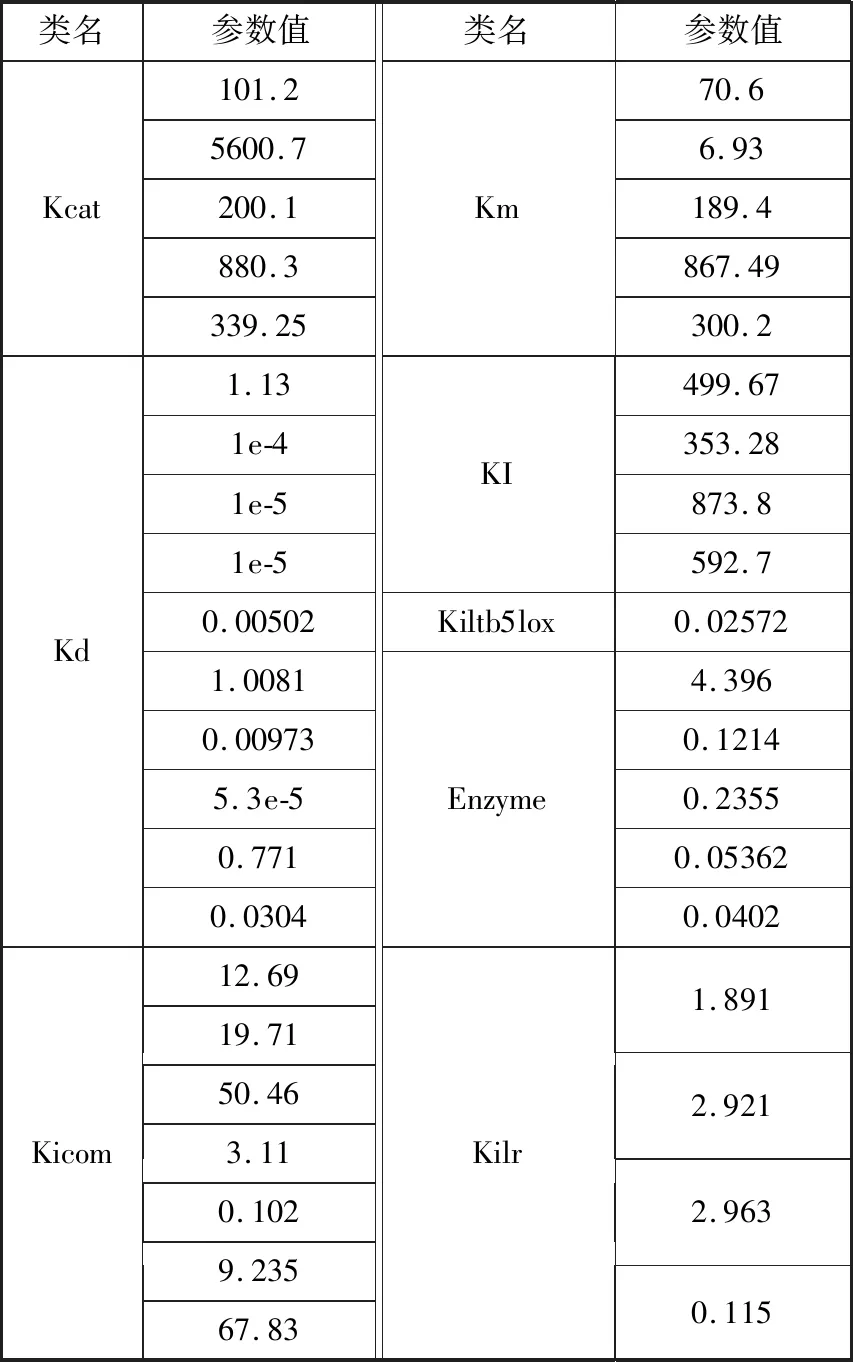
表4 数据集4的本文算法估计得到的参数值
以表3中数据集4为例,本文展示5种优化算法在优化过程中目标值的变化过程,如图3所示。
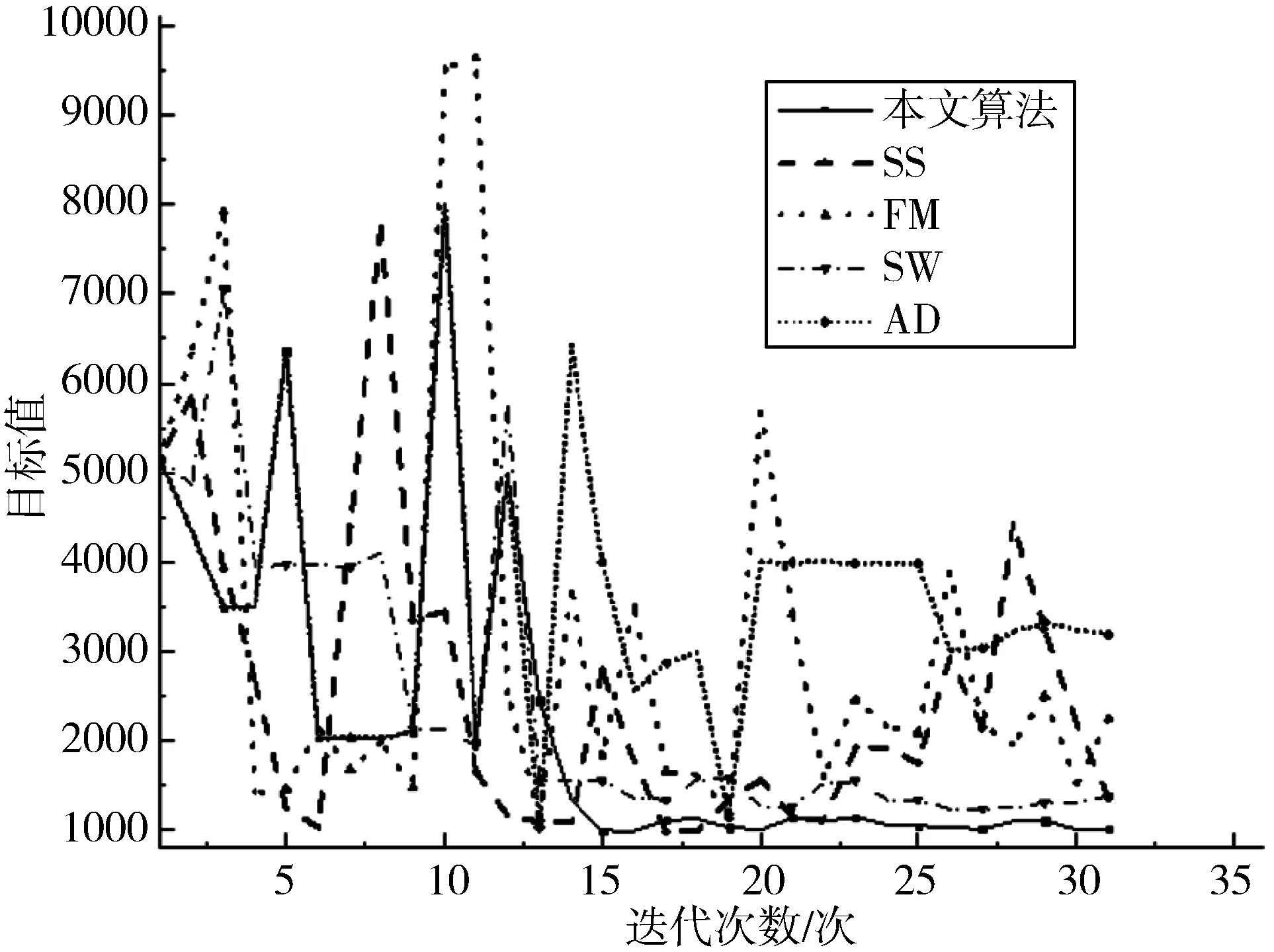
图3 数据集4优化过程所对应目标值变化过程
从图3的变化过程可见,本文算法和SW在规定的优化次数内有收敛趋势。所有5种优化算法中,FM和AD最先达到该算法的优化最小值,而SW后达到优化最小值。所有算法都有震荡过程,即目标值升高后有一个下降过程。
仍以数据集4为例,本文展现不同初始学习率对本文算法优化的影响,过程如图4所示。

图4 不同初始学习率对优化过程的影响
由图4可见2种初始学习率,在优化过程中均有抖动,但在后续均趋于平稳。低的初始学习率比高的初始学习率在优化过程中的下降过程要缓慢一些。
3 结束语
本文针对Kriging代理方法在解决非线性且具有sloppiness属性模型参数估计问题中的新增点查找算法进行改进,将Adam算法和带有动量的SGD算法的优势相结合,以期达到提高搜索质量以及最后收敛的双重目的。将该算法应用于PMN代谢模型,并与其他4种算法进行了比较。结果显示,在可比拟的时间内该算法能得到较好的优化效果。下一步的工作是探索学习率的修改规则以及进入局部最优的调整规则。
猜你喜欢
心理学探新(2022年1期)2022-06-07
哈尔滨工业大学学报(2022年5期)2022-04-19
北京航空航天大学学报(2020年10期)2020-11-14
广东教学报·教育综合(2020年15期)2020-03-23
趣味(数学)(2018年12期)2018-12-29
现代营销(创富信息版)(2018年8期)2018-09-08
统计与决策(2017年2期)2017-03-20
系统工程与电子技术(2016年2期)2016-04-16
社会心理科学(2015年6期)2015-02-07
中学教学参考·文综版(2014年1期)2014-03-11
