
改进的SSD算法及其在目标检测中的应用
2021-09-15 11:20李孟洲李浩方马军强
计算机应用与软件 2021年9期
张 震 李孟洲 李浩方 马军强
(郑州大学电气工程学院 河南 郑州 450001)
0 引 言
随着互联网储存大量的数据,计算机拥有强大的运算能力以及国内外在深度学习取得多方面的突破,目标检测也应运而生。Girshick等[1]在2014年提出R-CNN促使深度学习在目标检测领域飞速发展,紧接着SPP-Net(Spatial Pyramid Pooling Networks)、Fast-R-CNN[2]、Faster-R-CNN[3]、YOLO[4-5]、YOLO2、SSD[6]、DSSD[7]等也进一步促进了目标检测的发展。目前,目标检测已应用于多个领域,也成为当前的研究热点。
近年来,深度学习在目标检测衍生出来的主流算法大致分为两类。一类是基于R-CNN展开的各种算法,主要包括Fast-R-CNN、Faster-R-CNN、Mask-R-CNN、RFCN[8];另一类则为YOLO、YOLO2、SSD等。其中第一类会先进行区域选取(region proposals),再对所选区域进行分类(classification)。第二类则是直接将产生的proposal同时进行了regression+classification。因此,第二类相比于第一类在速度方面更占优势,但是精确度(Precision)和召回率(Recall)皆有所下降。
Fast-R-CNN是在SPP-Net基础上进行了改进,并将它嫁接到VGG16上所形成的网络,将SPP改成RoI Layer pooling层,通过Softmax Classifer和Bounding-Box Regressors联合训练的方式来更新所有参数,实现了整个网络端到端的训练;Faster-R-CNN与Fast-R-CNN最大的区别是融合了一种新的网络RPN(Region Proposal Network)来替代之前的search selective;Mask-R-CNN主要是对Faster-R-CNN的输出进行了改进,增添了一个新的输出object mask;RFCN与Faster-R-CNN的网络结构不同之处在于不再以VGG16作为基础网络,而以ResNet为基础网络。YOLO使用了全新的训练方式筛选候选框—采用整图的方式来训练模型,并且可以一次性预测多个Box的类别和位置;YOLO2在YOLO的基础上去掉了网络与类别的预测绑定在一起,也使用了anchor box模式,更多地使用了卷积来代替全连接网络,并增加了BN算法,同时提升了网络的入口分辨率,去掉最后的池化层,保证有更好的分辨率;SSD则是在YOLO的基础上融合了RPN,与以上各种算法相比,综合性能优异,但是小目标检测与识别效果低一直都是SSD难以摆脱的缺点,文献[7,9-11]也证实了这一点。
目前,针对SSD对小目标识别率低的问题提出了FSSD(Feature fusion Single Shot multibox Detector)、DSSD(Deconvolutional Single Shot Detector)、R-SSD等。文献[12-13]提出的FSSD,是一种SSD+FPN思想的结合,重新构造出一组新的特征金字塔,相比于传统的SSD在小目标检测与识别上具有更高的精确度;文献[7]中DSSD是将SSD的基础网络由VGG16改为ResNet,并引入反卷积层用于传递信息,虽然也提高了识别小目标的准确率,但是降低了识别速度,实时性变差;文献[14]提出的R-SSD则是通过增加不同层feature map的联系以及feature map的个数来提高检测小目标的识别率。本文则提出轻量级网络融合+层级特征融合的方法来解决SSD对小目标识别率低的问题。
1 SSD目标检测
SSD是Liu等[6]提出的一种目标检测算法,它在YOLO的基础上融合了RPN的思想,在不同的卷积层所输出的不同尺度的卷积结果(Feature Map)上面画格子,在多种尺度的格子上提取目标中心点。虽然改善了算法中每个网络预测的物体个数是指定的,容易造成遗漏(如指定检测2个,但是实际有3个)和算法对物体尺度相对比较敏感,对尺度变化较大的物体泛化能力较差的缺点,但是,仍然存在着容易漏检小目标、重复检出多个边界框的问题。
1.1 传统SSD的模型结构
SSD使用的是一种基于VGG 16改进的模型结构,其使用了Conv4_3、Conv_7(FC7)、Conv6_2、Conv7_2、Conv8_2、Conv9_2六个不同特征图来检测不同尺度的目标,低层主要用于预测小目标,而高层则用来预测大目标,能够直接预测目标的位置和类别,同时也能够大大提高检测精度,SSD算法的网络结构如图1所示。
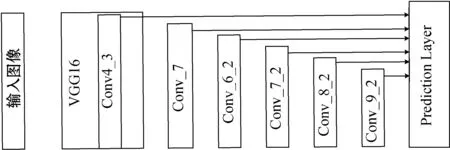
图1 SSD算法的网络结构
1.2 传统SSD的损失函数
SSD的损失函数包含用于分类的log loss 和用于回归的smooth L1,即:
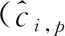
1.3 传统SSD的缺点及改进
传统SSD算法采用六个不同特征图来检测不同尺度的目标,其低层次的定位效果好但分类精度低,由于六个不同特征图相互独立,造成传统SSD算法对小目标的检测效果一般。针对以上问题,本文提出轻量级网络融合+层级特征融合的方法来改进传统SSD算法,其主要针对金字塔结构中的特征层进行融合以及对空洞卷积层输出的结果依次进行求和,并将后边所有输出的求和与第一个输出连接(Concatenate)起来,然后输出结果。
2 改进的SSD算法
本文提出改进的SSD算法整体网络结构如图2所示,首先对Conv4_3、Conv_7、Conv6_2、Conv7_2、Conv8_2(简记为ConvY_Y)这五个特征层进行卷积操作(由于Conv9_2特征层尺寸很小,包含较多的语义信息,故不需对其进行卷积操作)[15]。为了免去特征融合后再进行特征降维的操作,要求进行卷积操作后生成的Conv4_3_0、Conv_7_0、Conv6_2_0、Conv7_2_0、Conv8_2_0(简记为ConvY_Y_0)的特征维数不能超过原始的特征维数[15]。然后将Conv4_3和Conv4_3_0、Conv_7和Conv_7_0、Conv6_2和Conv6_2_0、Conv7_2和Conv7_2_0、Conv8_2和Conv8_2_0这五对分别进行融合,依次得到Conv4_3_1、Conv_7_1、Conv6_2_1、Conv7_2_1、Conv8_2_1并与Conv9_2形成新的金字塔特征层[15]。之后对Conv_7_1、Conv6_2_1、Conv7_2_1、Conv8_2_1、Conv9_2(简记为ConvY_Y_1)五个新特征层的空洞卷积层进行特征融合,依次得到Conv_7_2、Conv6_2_2、Conv7_2_2、Conv8_2_2、Conv9_2_2(简记为ConvY_Y_2),与Conv4_3_1形成最终的金字塔特征层[16]。
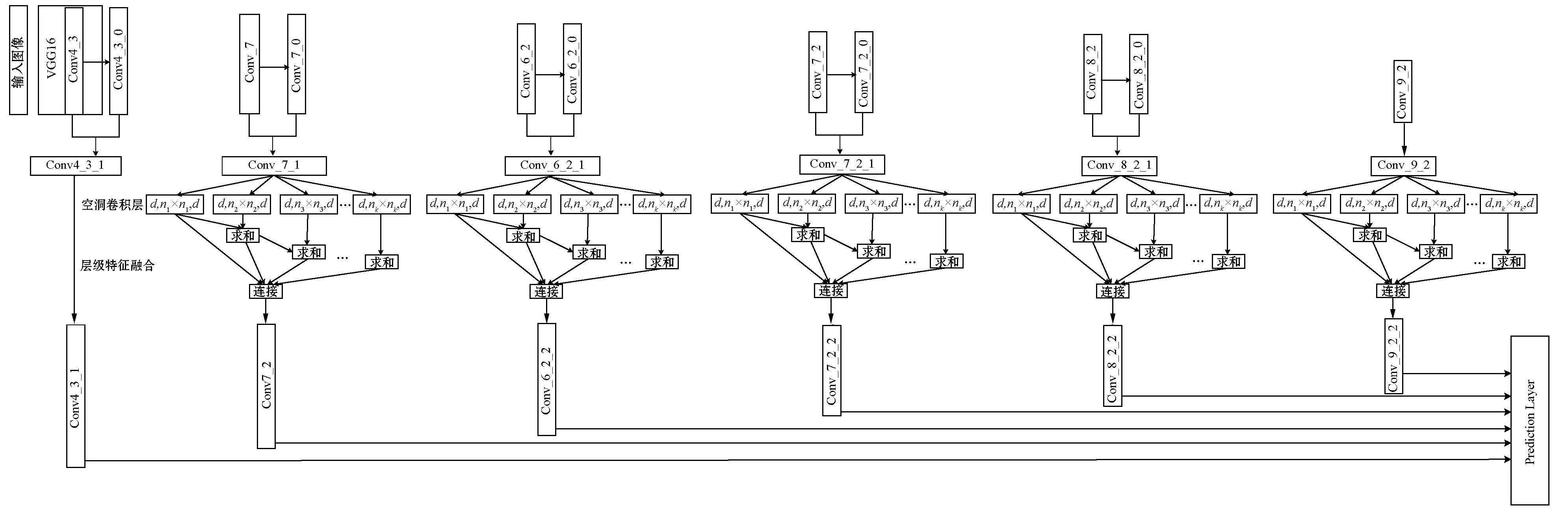
图2 改进SSD算法的网络结构
ConvY_Y_0相比于ConvY_Y具有更强的语义信息和更大的卷积特征尺度。此外,由于本文提出的卷积不改变补边的特征尺寸,因此原特征图的边缘信息得到更好的保留。
本文基于层级特征融合的思想,对ConvY_Y_1的空洞卷积层输出结果依次进行求和,并将后边所有输出的求和与第一个输出连接(Concatenate)起来,得到ConvY_Y_2,然后与Conv4_3_1形成最终的金字塔特征层[15]。此方法与别的通过使用小的扩张参数来增加学习参数的一般方法相比,不仅操作更为简单,而且解决了增加卷积结构复杂性的问题。
本文最终形成的金字塔特征层相比于传统SSD算法的金字塔特征层增强了特征层的语义信息,并引入层级特征融合使得数据更加连续,最终达到改善SSD算法对小物体识别率低的问题。由于生成的特征层相比于最初的特征层,特征维数没有升高,特征图的边缘特征没有损失,因此在特征融合时高层特征不仅不用调整尺寸,而且不用进行降维操作,相比于传统的特征融合操作,本文采用的特征融合方法更具有优势。
2.1 轻量级网络融合策略
特征连接以及特征对应元素相加[7,10-12,17]是目前进行特征增强最流行的两种特征融合方式,本文基于特征连接设计了一种轻量级网络融合策略对传统SSD算法的金字塔特征层进行特征增强。因为ConvY_Y_0不仅特征尺寸与ConvY_Y相同,而且前者的特征维数不高于后者,故可直接进行融合。
在进行特征融合时,如果x为输入特征,f(x)为对x卷积操作,y为卷积后的特征,则y=f(x),若令(x,y)为特征x和特征y首尾相连的操作,则相应的特征进行首尾相连的操作可表示为Fconcat=(x,y),Fconcat为特征x和特征y首尾相连后得到的特征[15]。
特征元素首尾相连的特征融合如图3所示,将卷积生成的ConvY_Y_0的特征维数统一设置为128维,低于ConvY_Y特征层的特征维数,然后将ConvY_Y与ConvY_Y_0直接串联得到ConvY_Y_1,将这种特征融合称为轻量级网络融合[15]。

图3 特征元素首尾相连的特征融合
2.2 层级特征融合策略
引入空洞卷积层可以增大卷积核感受野并保证层及特征信息不丢失,但是使用空洞卷积层会使卷积核操作数据不连续以及不能较好地识别小目标[16]。空洞卷积层结构表示为输入通道、感受野、输出通道,其中空洞卷积核的有效感受野为nk×nk,nk=2k-1(n-1)+1;k=1,2,…,K层级特征融合则是将空洞卷积层输出的结果依次进行求和,并将后边所有输出的求和与第一个输出连接(Concatenate)起来,然后输出结果,可以解决上述空洞卷积层存在的问题[16]。此方法与别的通过使用小的扩张参数来增加学习参数的一般方法相比,不仅操作更为简单,而且解决了增加卷积结构复杂性的问题,图4表示为层级特征融合结构[16],其中:左边的d表示输入通道;右边的d表示输出通道。

图4 层级特征融合结构
2.3 网络训练策略
因为本文算法对应的金字塔特征层与传统的SSD算法相差较多,所以不适合直接在已经训练好的SSD算法模型上进行相应的修改。本文算法同样以在ImageNet上训练好的VGG16网络作为基础框架,在训练本文算法时所采用的损失函数、对数据扩张的决策、挖掘决策困难样本,以及提取每个特征层对应Box的长宽比率与传统SSD算法相同。同时,训练本文算法的学习率与传统的SSD算法的学习率相同,IOU值设置为0.5。
3 实 验
本文算法主要针对于改进传统SSD算法对小目标识别率低的问题,为了验证本文算法的可行性,将其与传统SSD算法在PASCAL-VOC2007小目标数据集上对mAP、每秒传输帧数进行对比。本文所采用的操作系统为Ubuntu14.04 ,在TensorFlow平台上完成算法的训练与测试工作,所使用的GPU型号为GTX1080 Ti 。由于设备原因,本文算法采取单GPU训练,参数Batch size为16,相比于传统SSD算法小了一半。
3.1 实验步骤
本文算法首先以在ImageNet上训练好的VGG16网络作为基础框架,然后在PASCAL-VOC2007的训练集和验证集上训练本文算法,最后在PASCAL-VOC2007测试集上测试本文算法对小目标检测的有效性。将本文算法的测试结果与传统SSD算法的测试结果进行比较,得出本文算法可以提高对小目标的检测精度。
3.2 PASCAL-VOC2007数据集的测试结果
PASCAL-VOC2007小目标数据集提供了20种类别的图片,表1为VOC2007具体的物体类别。为了检验本文算法在小目标识别上的性能,在PASCAL-VOC2007数据集中挑选了154幅具有代表性的图片来进行实验。其中154幅图片中涉及的物体类别有9种,包括aeroplane、bird、bottle、person、boat、dog、sofa、car、cat,对这154幅图片进行相应的处理后,共计有1 308个标注物体的groud truth。分别对其用传统的SSD算法、DSSD算法、DSOD算法、R-SSD算法,以及本文算法进行目标检测实验,传统的SSD算法与本文算法部分场景下的检测结果如图5所示,其中:数字1表示飞机;数字2和数字3表示鸟;右边的数字与精确度相关,数字越大,精确度越高。5种算法的检测结果如表2所示。
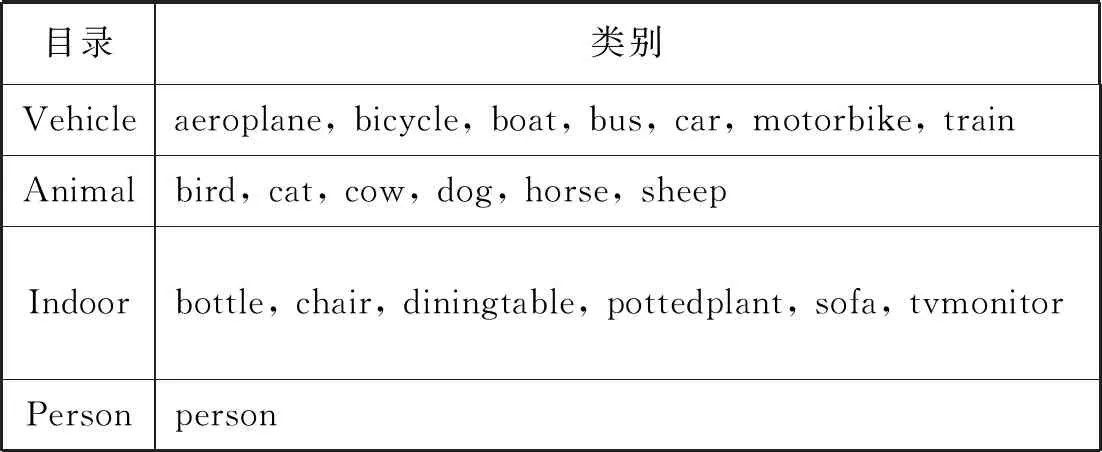
表1 VOC2007数据集的物体类别

图5 传统SSD与本文算法对小目标检测结果对比
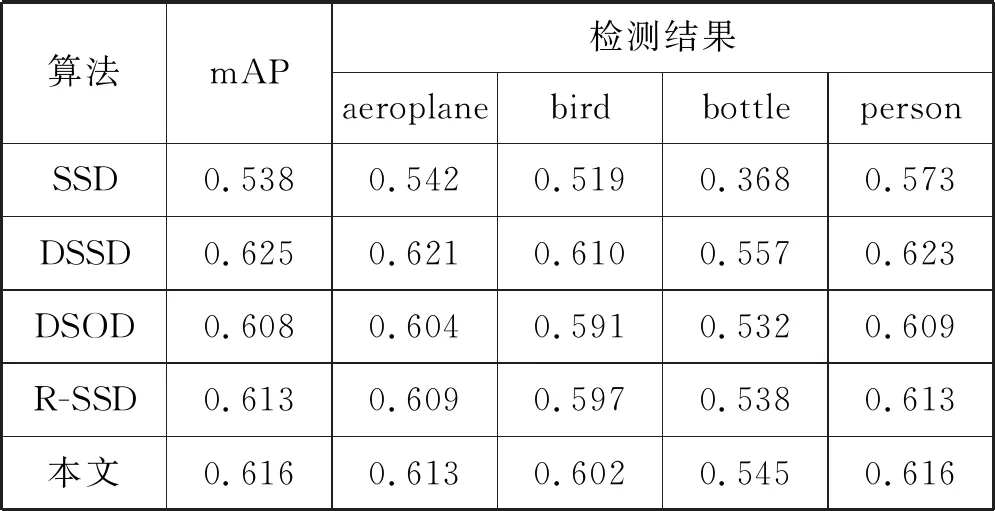
表2 VOC2007数据集9类物体检测结果

续表2
从图5可以看出本文算法对检测效果的改进,(a)和(c)为传统SSD算法的检测效果,可以得出其对近处物体以及较大的物体有较高的类别置信度,但是它的定位精确性需要进一步提高;(b)和(d)为本文算法的检测效果,可以看出不仅提高了对小目标的检测能力,而且对大目标的定位也更加精确。
从表2中可以得出本文算法对小尺寸物体(如bottle)的识别精度提升更大, mAP相比传统SSD算法提高了0.078,比DSOD算法提高了0.008,比R-SSD算法提高了0.003,但低于DSSD算法0.009,是因为DSSD以ResNet-101为基础网络,虽然比VGG16网络深、性能好,但是结构也更为复杂。从表3中也可看出DSSD牺牲了过多的检测速度。

表3 VOC2007测试集每秒传输帧数指标测试结果
由于本文算法在进行特征融合时既不用调整尺寸,又不用进行降维操作,故本文算法的检测速度可达81.5帧/s,远远高于Faster-R-CNN算法的7.0帧/s以及DSSD算法的9.5帧/s,且高于DSOD算法的17.4帧/s和R-SSD算法的16.6帧/s,相比较于传统SSD算法的85.0帧/s,仅仅损耗了3.5帧/s,具体每秒传输帧数指标测试结果可见表3。
4 结 语
本文提出轻量级网络融合+层级特征融合的方法通过修改金字塔特征层来改进传统SSD算法。在VOC2007的小目标数据集上对本文改进算法进行了测试,比传统SSD算法的mAP提高了0.078,并且每秒传输帧数几乎没有降低。未来的工作主要针对参数压缩、模型简化来展开,以提高算法的实时性。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
中国典型病例大全(2022年13期)2022-05-10
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
航天工业管理(2020年9期)2020-12-28
军事运筹与系统工程(2020年1期)2020-09-11
初中生世界·七年级(2019年5期)2019-06-22
廉政瞭望(2019年5期)2019-06-10
