
基于半监督学习的AES 算法功耗分析*
2021-09-14 07:35王相宾王永娟高光普袁庆军
密码学报 2021年4期
王相宾, 王永娟, 赵 远, 高光普, 袁庆军
1. 战略支援部队信息工程大学, 郑州450001
2. 河南省网络密码重点实验室, 郑州450001
1 引言
密码设备在金融、国防、及网络安全领域都有着十分广泛的应用. 运行环境的封闭,使得硬件实现的密码算法通常比软件实现的密码算法具有更好的安全性. 侧信道分析[1]是一种分析密码算法物理实现安全性的方法, 较为常见的侧信道分析方法主要有计时分析、功耗分析、电磁攻击、故障攻击、缓存攻击等[2].功耗分析又称为能量分析, 实施简单且分析效果良好, 主要通过分析采集自密码设备在运行过程中所泄露出的能量消耗信息, 来对加密过程中所使用的密钥进行还原.
基于机器学习的功耗分析方法是该研究领域的主要方向之一. 经典的功耗分析方法需要假设设备噪声符合高斯分布, 而基于机器学习的功耗攻击则可以放宽这一假设, 因而其适用性更强. 但是, 当前大部分在功耗分析中应用到的机器学习方法是有监督学习方法[3–9], 这些方法往往要求攻击者能够完全控制目标密码设备, 同时需要大量已标记的能量迹训练模型. 本文考虑在有已完成分析的密码设备的条件下, 对与之相似的设备进行攻击的情况. 在该场景下, 原有的密码设备可以提供足够的有标记能量迹, 而新的分析对象设备可以采集到大量的无标记能量迹. 这种情况更符合半监督学习方法的应用条件, 因此考虑使用半监督学习的方法进行建模类的功耗分析.
2013 年, Lerman 等人首次将半监督学习算法应用到功耗分析中[8], 分析了在某些实际场景下, 基于半监督学习的功耗攻击相较于使用有监督学习方法的优势. 2017 年, Liu 等使用协同学习方法完成了对AES 算法的功耗攻击[10], 可在使用少量有标记能量迹的条件下进行密钥恢复. 文献[11] 使用朴素贝叶斯分类和径向基核函数的支持向量机作为分类器, 采用自学习方法进行功耗分析研究. 文章从分类数目、样本数量等多个角度分析了半监督学习对于功耗攻击效果的提升, 并指出分类数目越少, 恢复密钥的成功率越高.
然而, 目前关于半监督学习在功耗攻击中的应用相关研究较少. 本文将半监督学习算法 Tri-Training[12]应用到功耗分析中, 并在算法中增加阈值判断操作, 以减小训练过程中特别是在初始分类器较弱时引入噪声所带来的影响. 实验对在8051 单片机上运行的标准AES-128 算法进行攻击. 在使用50 条已标记能量迹的条件下, 对单字节密钥汉明重量预测准确率可以达到53.28% (随机猜测的准确率为11.1%); 在使用100 条有标记能量迹时, 准确率可达到80.81%, 在使用相同数目有标记能量迹的条件下,较使用有监督学习方法的攻击取得了更好的分析效果.
文章安排如下: 第2 节介绍进行分析所需的相关知识; 第3 节介绍实验及分析结果; 第4 节对文章进行总结, 并对下一步工作进行展望.
2 预备知识
2.1 功耗分析的基本原理
密码设备在运行过程中所产生的能量消耗具有数据依赖性, 功耗分析的主要原理是根据密码设备的能量消耗, 利用其与所运行算法中间值的关系来获取中间值, 而中间值与密钥直接相关, 进而获取密钥. 通常情况下, 攻击者仅仅需要对算法第一轮或最后一轮进行分析即可完成攻击.
目前, 功耗分析根据攻击条件的不同, 可分为建模攻击和非建模攻击. 建模攻击要求攻击者能够完全控制一台与目标设备相同或相似的密码设备, 可以测量足够的能量消耗曲线来提取特征并进行建模. 这一类的攻击方法主要有经典模板攻击, 以及使用支持向量机、随机森林等机器学习方法, 和使用多层感知机、卷积神经网络等深度学习方法的攻击方法. 非建模攻击不需要控制一台相关的目标设备, 攻击的条件相对宽松, 但是其在攻击阶段的效率是要逊于建模类攻击的, 这是由于没有对于能量泄露特征的提前刻画. 这一类主要的攻击方法有简单功耗分析、差分功耗分析、相关碰撞攻击等.
基于机器学习的功耗分析方法属于建模类攻击, 攻击过程主要分为两个阶段: 第一阶段为模型训练阶段, 攻击者使用有标记的能量迹进行训练, 获得训练模型; 第二阶段为攻击阶段, 在该阶段使用模型对密钥未知的能量迹进行判别, 进而恢复密钥. 而在此之前, 通常还需要对数据进行预处理. 预处理过程主要包括能量迹对齐和泄露数据提取. 比较关键的是泄露数据提取, 其方法主要有特征点提取和数据降维. 下面给出基于机器学习的功耗分析流程, 如图1 所示.
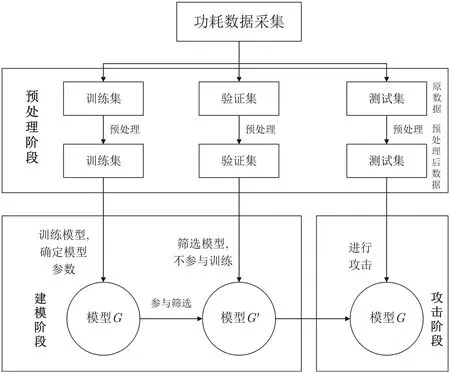
图1 基于机器学习的功耗分析流程Figure 1 Process of machine learning-based power analysis
2.2 半监督学习和Tri-TrainingT 算法介绍
机器学习按照学习任务类型可以分为有监督学习、无监督学习和半监督学习. 伴随着数据采集和数据存储的进步, 通过软件、硬件获得大量无标记数据相对容易, 而给这些无标记数据做分类标签却花费很大.因此在实际的样本集中, 无标记样本的数量远远大于有标记的样本数量. 在进行模型训练过程中, 如果只利用少量的有类标的数据样本, 即有监督学习, 那么会因为数据量太少, 使得模型的泛化能力不足, 同时造成了大量无标记样本的浪费; 如果只使用大量无类标的样本, 即无监督学习, 则会忽略己有标记样本的价值.
半监督学习是将有监督学习和无监督学习结合的一类机器学习方法, 其目的是希望学习器能够自发地利用无标记样本中的信息来提高其性能, 并且不依赖于外界的信息交互. 这里主要考虑的是半监督分类方法, 主要包括生成式方法、基于图的方法、基于判别的方法和基于分歧的方法[13]. 其中典型的基于分歧的方法有协同学习等, 经典的协同学习算法Co-Training 要求数据具有两个充分冗余且满足条件独立性的视图. 其中充分是指每个视图都包含能够产生最好的分类器的信息, 对于其中任意一个视图而言, 另一个视图是冗余的. 同时, 对于分类标签而言这两个视图是条件独立的[14]. 而实际中的数据往往不能满足充分视图的条件, 且大多数现实任务的数据为单视图数据, 即只有一个属性集. 为解决以上问题, Zhou 和Li提出了Tri-Training 算法, 该算法与Co-Training 算法同样是基于分歧的半监督学习方法. 该算法不再需要数据具有充分冗余视图, 且该方法是一种单视图学习, 其核心思想是用隐式估计样本标记置信度的方法选取合适的未标记样本. Tri-Training 算法使用三个分类器进行训练, 不再是挑选一个分类器来使用, 而是使用集成学习中经常用到的投票法, 将三个分类器组成一个集成, 来实现对未标记样本的分类. 其主要流程如下[12];
(1) 使用有放回均匀采样的方法从有标记数据集里抽取三个子数据集. 利用三个子数据集训练三个有差异的基分类器;
(2) 对于其中一个分类器i, 另外两个分类器预测所有未标注数据集, 挑选出其中预测结果相同的样本, 作为新的有标签数据, 加入到分类器i的训练集中;
(3) 为三个分类器分别执行步骤(2), 并利用三个扩增的数据集更新分类器;
(4) 重复执行(2) 和(3), 直到模型收敛.
其中需要注意的是, 在给未标记数据加上伪标记时, 可能多数分类器得到结果是错误的, 此时对于少数分类器而言, 其得到是有噪音的标记样本. 针对这种情况, Zhou 证明了引入噪音所带来的负面影响可以使用大量未标记样本正确标记所带来的正面影响所抵消, 即在一定条件下累积的标记噪声可以通过大量未标记数据进行补偿. 为进一步提高算法生成分类器的精确度, 本文在将Tri-Training 算法应用到功耗分析时加入阈值判断操作, 可以进一步减小噪声的引入, 以提高分类器的性能(以下称之为Tri-TrainingT算法), 出算法流程如图2 所示.
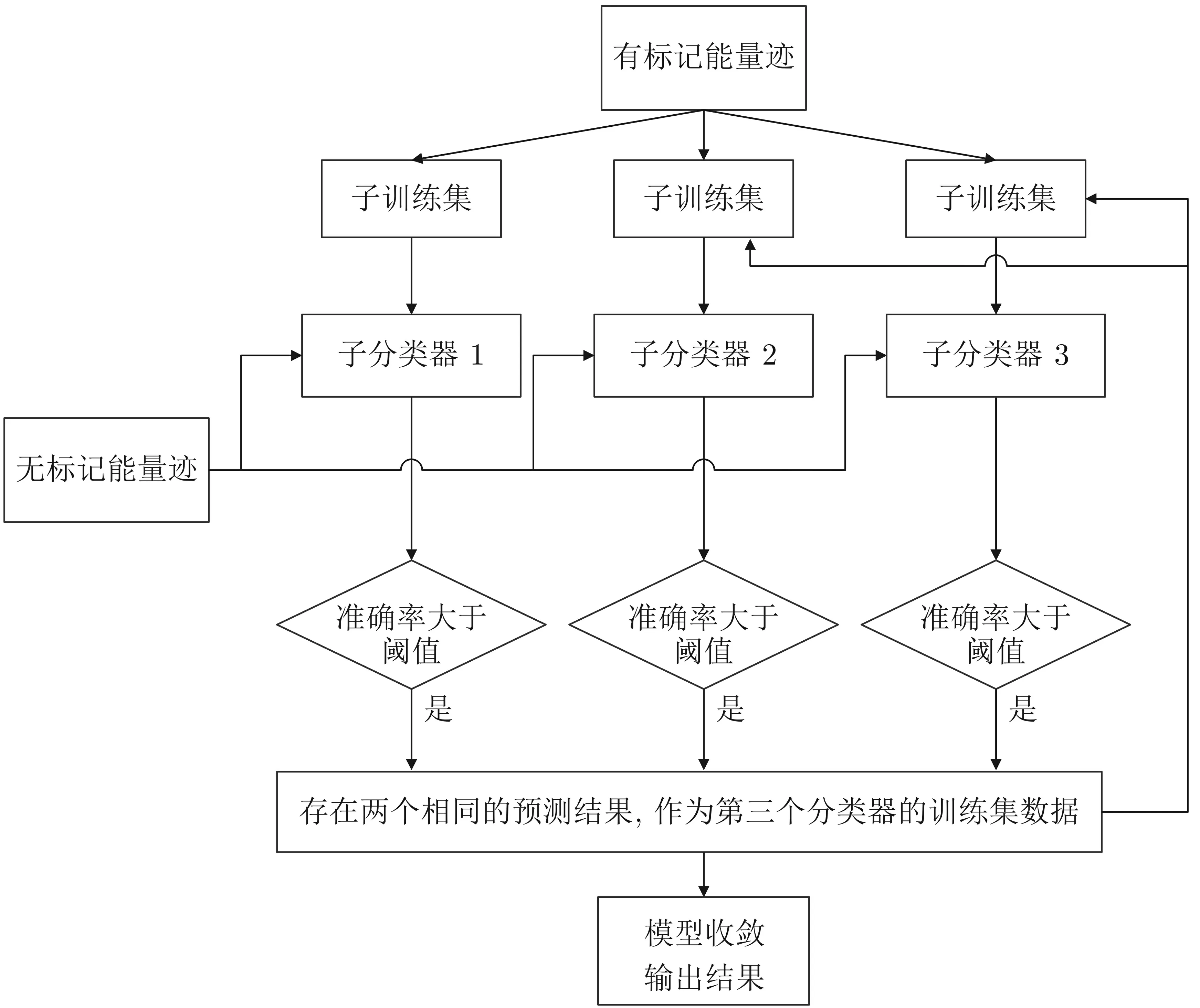
图2 Tri-TrainingT 算法流程Figure 2 Process of Tri-TrainingT
2.3 AES 算法及目标数据集
高级加密标准AES 属于分组密码算法,有三种最常见的实现方案,分别为AES-128、AES-192、AES-256, 分组长度均为128 bit, 其区别在于所使用的密钥长度不同, 分别为128 bit、192 bit 和256 bit, 加密的轮数也不同, 分别为10 轮、12 轮和14 轮.
本文分析的数据集采集自8051 单片机, 是一种标准AES-128 算法的ECB 软件实现, 所采集的曲线为AES 加密运算过程中第一轮的能量泄露波形. 实验分两次在不同时间段共采集了20 000 条能量波形,每次采集10 000 条. 由于环境噪声、电压波动等因素的影响, 两次采集的波形是存在一定差别的, 用以模拟从两台相似的设备上采集能量波形. 每条波形含有4000 个采样点, 使用相同的密钥对随机生成的明文进行加密. 分析时根据实际需要, 将能量迹分为有标签和无标签的训练集以及测试集.
3 基于Tri-TrainingT 的AES 功耗分析
在仅能够获取少量已标记样本和大量未标记样本的条件下, 利用Tri-TrainingT算法对从密码设备中采集到的能量迹进行训练, 以此作为训练集, 以设备加密算法运行过程中, 明文和密钥运算后的函数值(称为中间值) 作为样本的类别标记, 采用汉明重量模型来进行对标准AES-128 算法的攻击. 攻击的主要流程如图3 所示.

图3 攻击主要流程Figure 3 Main attack process
3.1 特征点提取
特征点是指从包含较多能量消耗信息的能量迹中抽取的有价值的点, 可以视为能量迹的信息泄露分析. 由于能量迹中不仅仅包括与密钥操作有关的能量消耗信息, 因此特征点提取是数据预处理阶段的重要步骤, 其主要的作用有两方面: 一是提取特征点可以过滤掉能量迹中部分不相关的特征, 减少噪声的引入;二是可以降低样本向量的维度, 便于计算和存储, 提高攻击阶段的效率. 特征点提取的常用方法有差分和(sum of difference)、T检验、ρ检验和相关系数法等[15], 本文所使用的是相关系数法.

使用上述方法对采集到的能量泄露波形进行分析, 结果如图4 所示, 其中横坐标为采样点, 纵坐标为相关系数, 可以看到最大泄露点为第373 个点. 进行分析实验时, 提取第370 个到第440 个点, 以及第500个到580 个点, 共150 个点作为特征点进行分析.
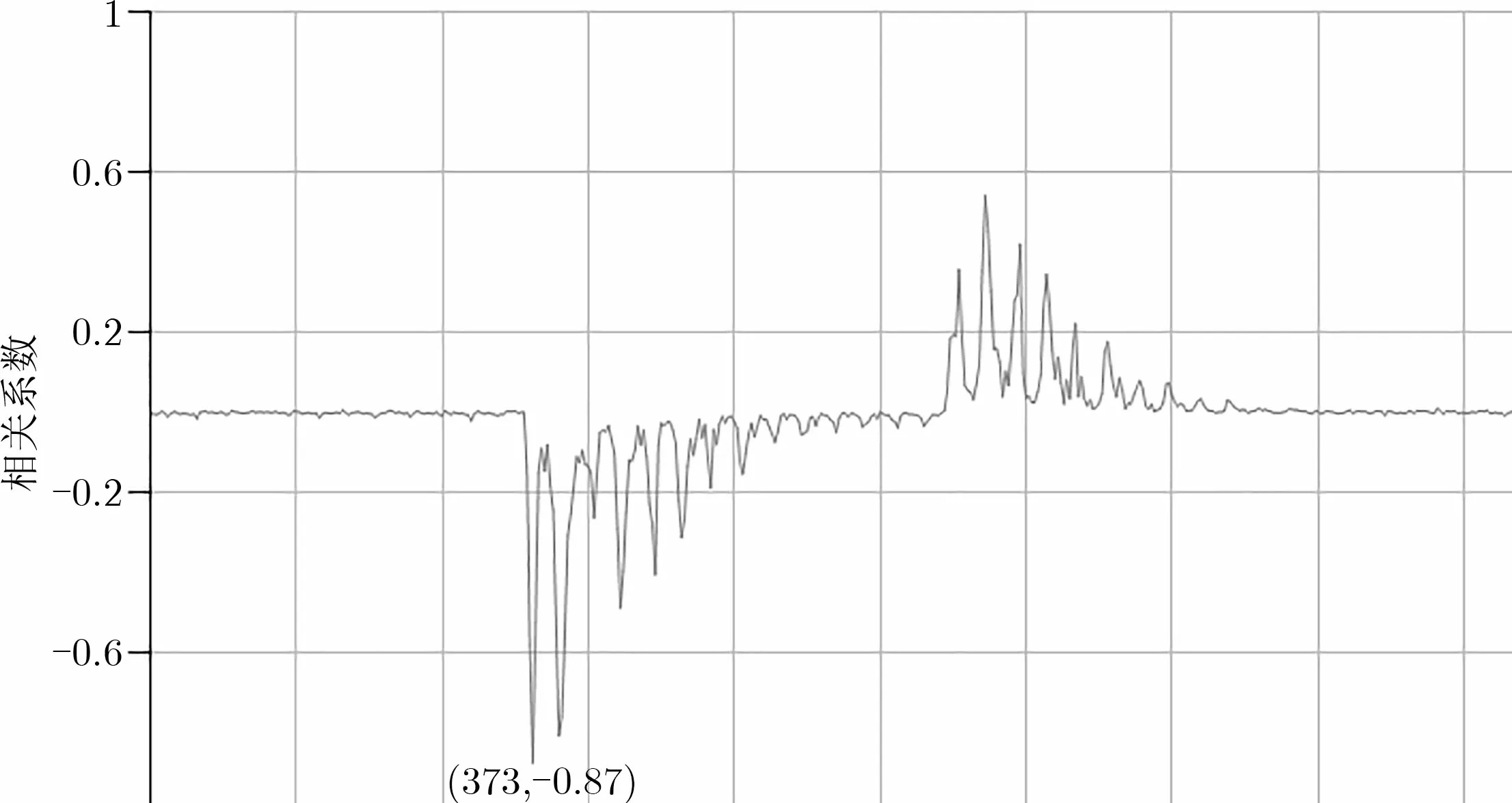
图4 特征点泄露分析Figure 4 Feature point leak analysis
3.2 实验及分析
3.2.1 实验条件
实验使用采集自8051 单片机上AES-128 算法加密过程的20 000 条能量泄露波形作为样本, 采集分两次完成, 每次采集10 000 条. 将两次采集到的数据集分别记为A, B. 实验过程中从数据集A 中分别随机抽取50、60、70、80、90、100 条能量迹作为已标记样本集, 从数据集B 中随机抽取5000 条能量迹作为未标记的样本集, 再从剩余的5000 条能量迹中随机抽取2000 条作为测试集, 并利用相关系数法提取150 个特征点. 实验中分别使用0.75、0.8、0.85、0.9、0.95 作为置信度阈值, 以对比不同阈值对准确率的影响.
实验对照采用使用径向基核函数和线性核函数的支持向量机(support vector machine,SVM)和Tri-Training 算法作为参照. 其中Tri-Training 算法的基分类器均为线性核函数的支持向量机. Tri-TrainingT算法的三个分类器均为线性核函数支持向量机. 需要注意的是, 支持向量机是一个二分类的分类器, 因此在使用时采用“一对一” 的方式构建多分类器, 即在每两个类别之间建立一个支持向量机分类器, 对于k分类问题, 构建出的多分类器需要k(k −1)/2 个支持向量机. 实验时, 各个算法在每组已标记样本上独立运行15 次, 以15 次结果的平均值作为最终结果.
3.2.2 实验结果
实验以AES-128 算法第一轮的第一字节为例进行分析, 采用了汉明重量模型, 将256 种可能的S 盒输出中间值映射到0 到8, 共9 类汉明重量上. 在测试集上的准确率代表单条能量迹恢复该字节密钥汉明重量的概率, 可以此作为分类效果优劣的评价标准. 在得到汉明重量模型分类结果后, 可进一步采用穷举、密钥概率优势分析等方法进一步完成密钥恢复. 各个算法在每组样本上的运行平均准确率如表1 所示.
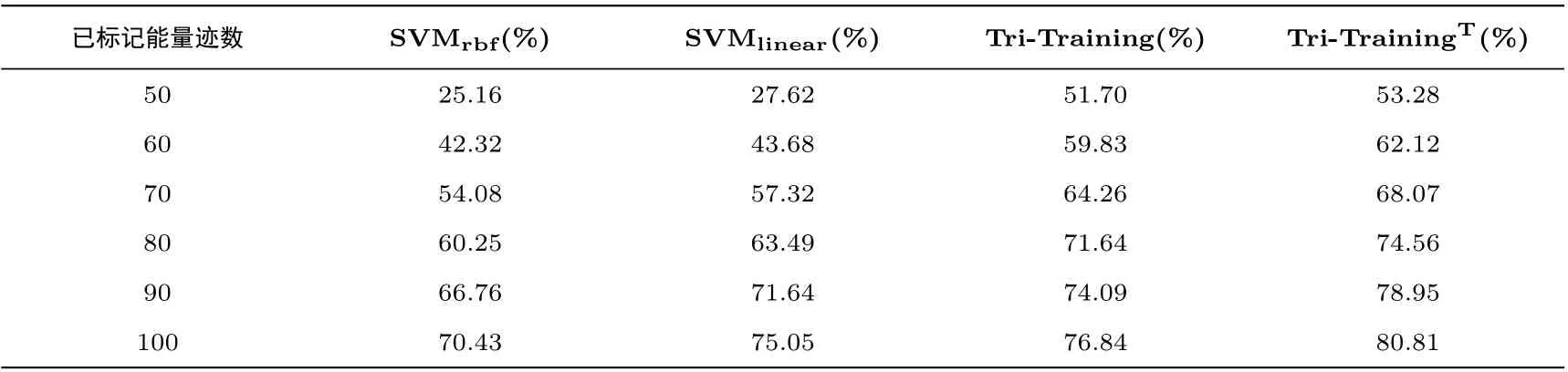
表1 各类算法的分析准确率Table 1 Analysis accuracy of each algorithm
实验得到的Tri-TrainingT、Tri-Training 和SVM 算法分析准确率变化趋势如图5 所示.
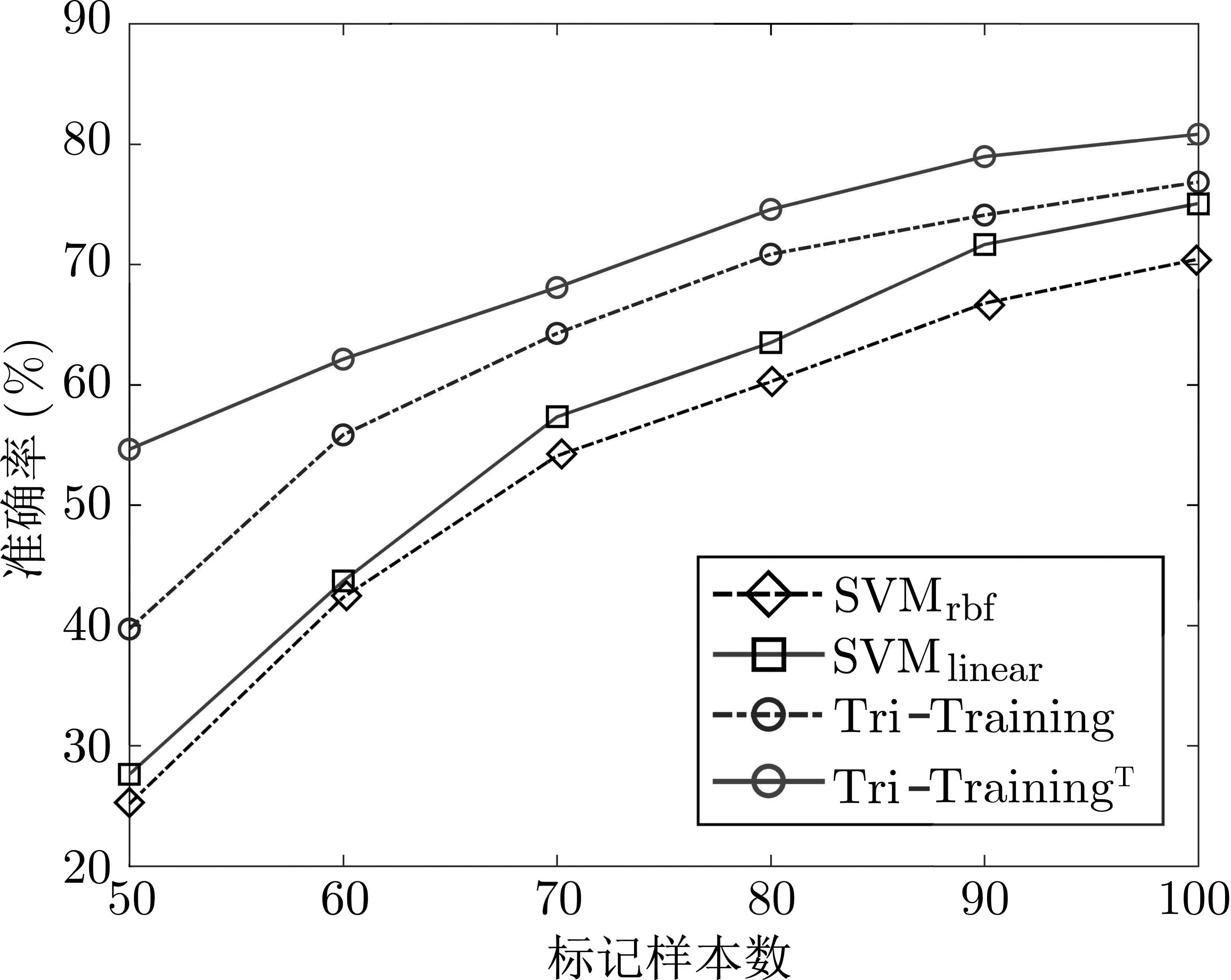
图5 各算法准确率变化趋势Figure 5 Variation trend of correct rate of each algorithm
表3 给出了使用线性核函数作为基分类器的Tri-TrainingT算法15 次独立运行的准确率结果, 所使用的有标记能量迹数量为100 条, 阈值设定为0.8. 可以看出, 算法单次运行得到的准确率是较为稳定的.根据以上实验结果可以得到以下结论;
(1) 在已标记能量迹较少的条件下, 使用半监督学习算法的攻击效果是优于使用有监督算法的攻击效果的. 二者的差距会随着标记样本数量的增加而逐渐减小. 这说明在已标记能量迹较少的情况下, 半监督学习算法可以利用未标记能量迹中的信息提升分类器的准确度. 而在已标记能量迹足够多的情况下, 半监督学习算法的分析效果优势就不够明显. 在有100 条有能量迹时, 使用Tri-TrainingT算法较使用径向基核函数的SVM 算法准确率可提升约14.7%.
(2) 对比同样采用线性核函数支持向量机作为基分类器的Tri-TrainingT算法和Tri-Training 算法,当已标记能量迹数量相同时, 前者的分析准确率更高, 说明Tri-TrainingT算法采用的阈值判断操作可以减小噪声带来的干扰, 能够更充分地利用未标记样本中的信息, 使得模型的分类效果更好. 实验的结果相较于文献[11] 中, 使用100 条有标记能量迹对AES-128 算法能量迹进行9 分类建模训练后得到的准确率有了明显提升(文献[11] 中对应的准确率为59.04%), Tri-TrainingT算法在功耗攻击中确有一定的应用效果.
(3) 对比Tri-TrainingT算法和Tri-Training 算法的效果, 可以看出在有50 条有标记能量迹时二者的准确率相差最大, 随着有标记能量迹数量的增加, 二者的差距逐渐减小. 说明阈值判断在有标记能量迹较少时的效果最为明显, 随着有标记能量迹数量增加阈值的影响逐渐减弱, 之后可进一步研究阈值选取与样本数目之前的关系.
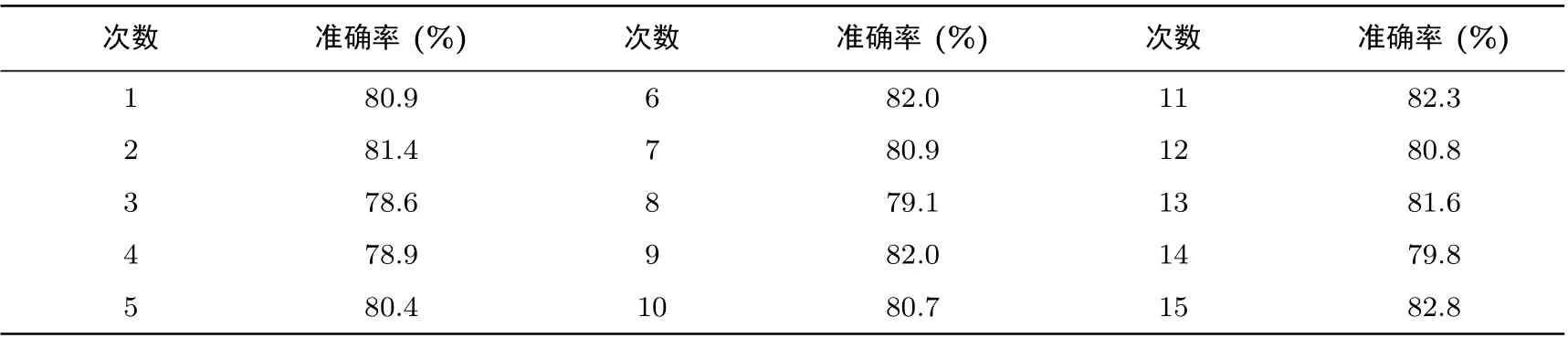
表2 Tri-TrainingT 算法使用100 条有标记能量迹准确率结果Table 2 Accuracy of Tri-TrainingT using 100 labled power traces
表3 给出了使用线性核函数作为基分类器的Tri-TrainingT算法在使用100 条有标记能量迹时, 不同阈值对应的准确率结果. 结果表明当阈值T= 0.8 时可以达到最好的分类效果, 而T= 0.75 时的分析效果最差.

表3 不同阈值的准确率结果Table 3 Accuracy results for different thresholds
为进一步检验建模的效果, 下面进行密钥恢复实验. 由之前的分析可以得到单条能量迹Ti对应S盒输出值vi的汉明重量等于W的概率, 记为pi. 此时对应的S 盒输出值共有C(W,8) 种情况, 由ki=S−1⊕m可以计算出对应的密钥值,m为明文, 进而得到猜测密钥的集合. 在实际的分析过程中, 通过不断增加能量迹条数来寻找具有概率优势的猜测密钥.
本文的实验中, 以密钥的第一字节为例, 使用100 条有标记能量迹和5000 条无标记能量迹训练得到的模型进行分析. 在计算过程, 为避免出现指数增长过快的情况出现, 需要对概率值取自然对数. 随着能量迹数量增加, 当能量迹条数达到62 条时, 各猜测密钥的概率优势如图6 所示.
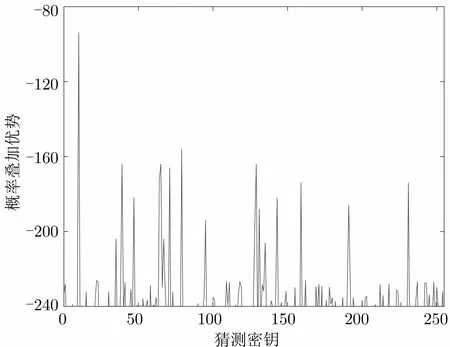
图6 恢复密钥第1 字节Figure 6 Recover first byte of key
从图中可以看出密钥字节0x11 的概率优势已足够大, 故猜测正确密钥的第一字节为0x11, 这与加密时实际所使用的密钥第1 字节相同. 同样, 可以使用相同的方法恢复剩余字节的密钥.
4 小结
本文将Tri-Training 算法应用到AES-128 的功耗分析中, 在拥有少量已标记样本和大量未标记样本的情况下, 得到了较使用有监督学习方法分析的更好的攻击效果. 同时在进行模型训练时引入了阈值判断操作, 可以进一步减小初始分类器较弱时引入噪声所带来的影响, 提高分类的准确度. 在之后的工作中可继续对其他加密算法的功耗数据进行分析, 改进分析方法, 提高其泛化能力. 同时, 在阈值选取的问题上,可以优化阈值选取策略, 针对训练过程中的具体情况调整阈值, 进一步探究选取的样本数量和阈值选取以及有标记能量迹和无标记能量迹数量之间的关系, 保持分类器之间训练样本的平衡.
猜你喜欢
北京航空航天大学学报(2022年7期)2022-08-06
电子产品世界(2022年4期)2022-04-21
故事作文·低年级(2022年2期)2022-02-23
故事作文·低年级(2022年1期)2022-02-03
计算机系统应用(2021年2期)2021-02-23
计算机应用与软件(2020年1期)2020-01-14
计算机测量与控制(2019年4期)2019-05-08
计算机与网络(2018年2期)2018-09-10
个人电脑(2016年12期)2017-02-13
微型计算机(2009年12期)2009-12-21
