
新能源乘用车辆应用场景识别方法研究
2021-09-10 07:22:44王同根
交通科技与管理 2021年19期
关键词:聚类分析
王同根

摘 要:本文通过研究新能源车辆出行特征,从出行强度、时空轨迹角度,挖掘车辆行为特征差异,构建表征车辆属性的指标维度,提出无监督学习中的聚类分析法,识别新能源车辆的应用场景,采用上海市新能源车辆数据进行验证,证明提出方法的准确性。
关键词:新能源车;出行强度;时空轨迹;聚类分析
0 引言
随着充电技术不断成熟,相关政策鼓励,新能源动力车辆得到了广泛推广。2020年,中国新能源汽车销量达到136.7万辆[1]。同时,新能源车辆用户行为研究逐步成为热点,包括出行行为、充电行为,涉及用户分类研究,常见地将用户根据行驶里程分为长里程、短里程用户[2,3],缺少用户使用场景深入研究,以及大规模数据实践案例。然而,新能源用户场景识别划分,不仅有助于推动新能源车辆推广应用,而且能有效支撑政府对于网约车辆监管,具有很强的必要性。
本文提出一种基于无监督聚类法的车辆应用场景识别方法,通过挖掘时空行为特征差异,构建衡量车辆属性的指标维度。采用K-MEANS算法对车辆进行聚类分析,综合手肘法和轮廓系数,法判断最优分类数,根据每类结果指标特征,确定车辆具体应用场景,即私家通勤、兼职网约、专职网约车辆。最后,采用上海市新能源汽车出行数据,识别车辆应用场景,通过与互联网平台注册数据相互校验,验证算法的精度和有效性。
1 数据介绍及预处理
研究数据来源于上海市新能源汽车公共数据采集与监测平台,分析样本为乘用车辆10万辆,其中,已有网约标签车辆1 000辆。数据信息包括采集时间、经纬度、累计里程等字段,采集频率为10 s~30 s。
数据预处理步骤分为数据清洗、车辆次行切割、车辆日出行数据处理。数据清洗中,去除里程数据丢失严重的车辆,过滤经纬度、时间跳变的记录;以30 min间隔,将原始数据进行切分,形成车辆次出行时空轨迹,即时间、经纬度序列;以日为单位,处理车辆每日出行特征,包括日出行时间、日出行里程。
2 行为特征分析
从车辆出行强度、时空轨迹方面,挖掘样本车辆、网约车辆使用特征差异性,提出表征车辆应用场景属性的多维度指标,作为聚类分析模型输入。
2.1 出行强度特征
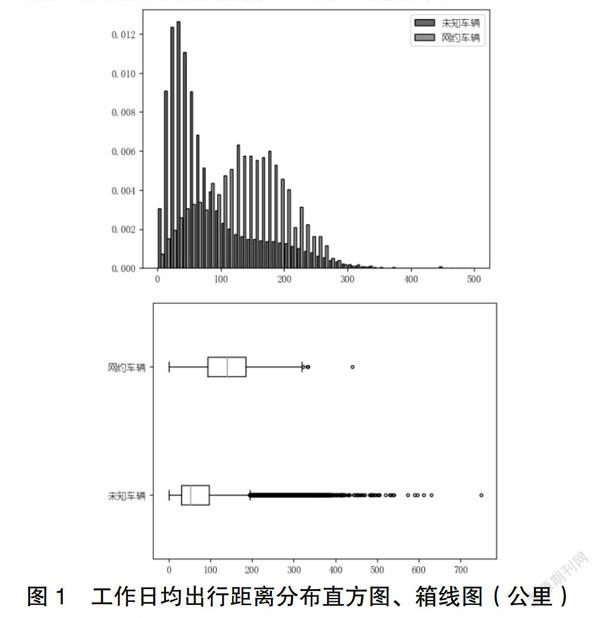
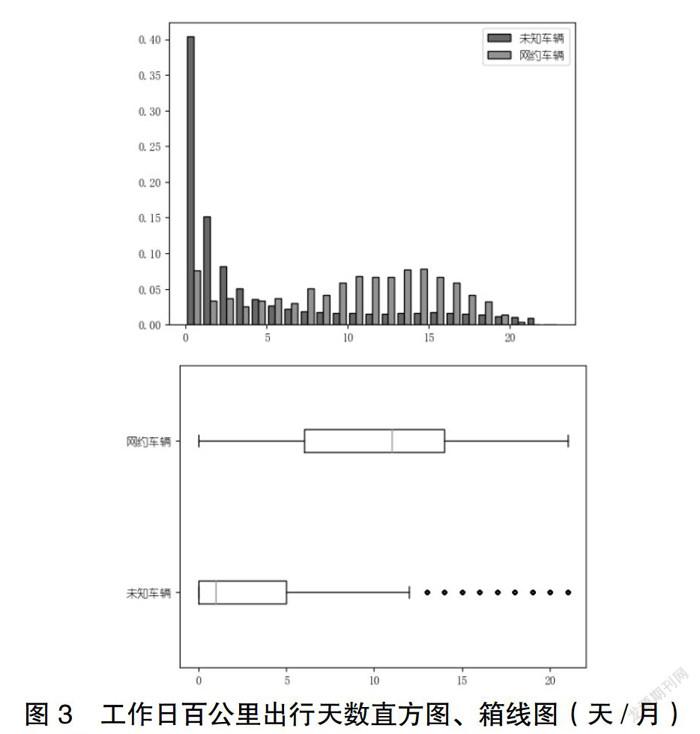
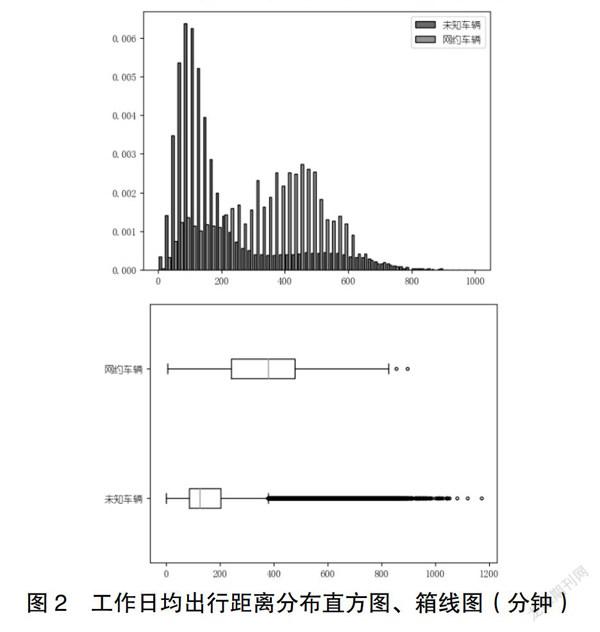
出行强度是衡量车辆应用场景最直观特征,常用的评价指标,如行驶里程、时长、次数。相比周末、节假日不确定性影响,工作日出行特征趋于稳定,选择工作日时间指标值;由于数据源特点,提取载客次行为有难度,不同场景车辆日出行次数差异不大;为减少极端、随机日出行的影响,考虑反映月出行强度的指标。基于此,选择工作日均出行时间、工作日均出行距离以及每月工作日百公里天数,作为出行强度特征指标。
图1~3为出行强度指标统计分布的直方图和箱线图,从图中看出,相比网约车辆,未知车辆数值区间跨度更大,中位数数值明显较低,四分位箱体更窄,异常值集中在较大值一侧,分布呈现右偏态,而网约分布则呈现标准正态分布。反映未知車辆样本混合了私家、网约以及兼职等不同场景的车辆,且出行强度较低的样本分布更为集中。
2.2 轨迹相似度特征
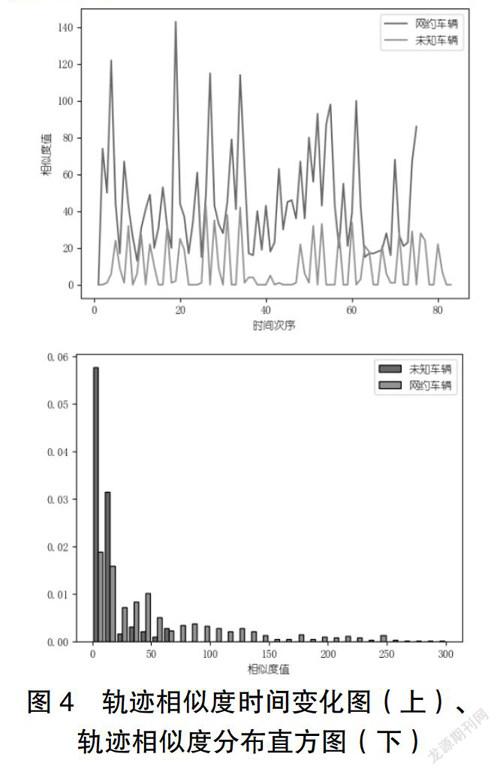
轨迹作为一种重要的时空对象数据类型和信息源,通过提取轨迹数据中的相似性与异常特征,并有助于发现其中有意义的模式。目前,时空轨迹的应用范围涵盖了人类行为、交通物流等。本文选取轨迹相似度特征,作为衡量车辆应用场景另一维度,相比出行强度,侧重描述车辆出行路径的规律性:私家通勤车辆轨迹相对稳定,一段时间内具有较高的相似性;网约车辆出行随机性较强,轨迹之间的关联度较低;兼职车辆轨迹特征处于两者之间。
考虑车辆轨迹长度灵活性,采用动态时间归整(DTW)算法计算轨迹之间的相似度值[4]。同时,为了衡量一段时间内的轨迹特征,以车辆所有轨迹间相似度的均值,作为轨迹相似度特征的指标。
图4分别为典型车辆轨迹相似度时间变化图、轨迹相似度数值分布直方图,从轨迹相似度时间变化和分布情况,网约车辆相似度值区间大、极值高,且轨迹波动性较大;相比之下,未知车辆具有明显的周期性,且轨迹相似度集中在低值区域。从轨迹相似度角度判断,未知车辆是私家通勤车辆可能性较高。
3 方法描述
在车辆行为特征研究基础上,采用无监督学习K-MEANS聚类方法,对特征相近车辆进行聚类分析,根据每类的特征值情况,进一步判断每类车辆应用场景。
3.1 分类最优K值确定
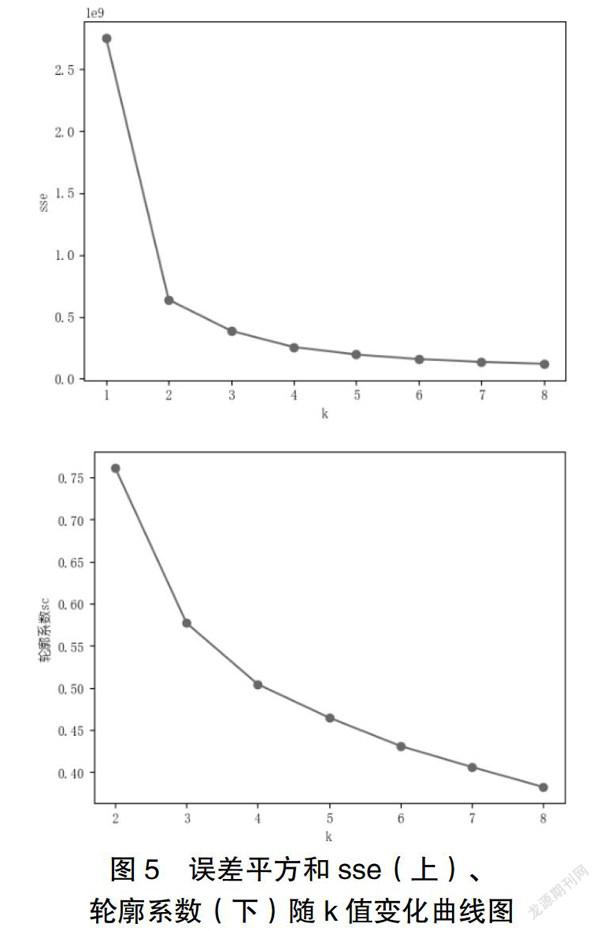
K-MEANS算法关键需预先确定分类k值,最优k值对应车辆场景类别。本文综合手肘法和轮廓系数法[5],判断k值。
(1)手肘法,随着聚类数k的增大,样本划分更加精细,每个簇的聚合程度逐渐提高,误差平方和sse逐渐变小。当k小于真实聚类数,sse下降幅度很大,当k到达真实聚类数,sse的下降幅度会骤减。
(2)轮廓系数法,选择轮廓系数较大所对应的k值。当样本i轮廓系数接近1,说明样本i聚类合理,接近-1,则说明样本i更应该分类到另外的簇。
图5为误差平方和、轮廓系数随着k值变化的曲线图。根据手肘法,k>3误差平方和值降幅明显放缓,k最优值为3;根据轮廓系数法,k最优取值为2、3。综合考虑,车辆场景聚类为3类,即私家通勤、兼职网约、专职网约。
3.2 K-MEANS聚类算法步骤
K-MEANS是一个迭代型算法[6],在确定最优分类k值为3的基础上,具体算法步骤:
(1)准备车辆特征向量数据集,其中,代表车辆集合,分别代表日均出行里程、日均出行时间、百公里天数、轨迹相似度四个特征值向量;
(2)随机初始化3个数据点,作为3组类别中心点;
(3)计算每个数据点到中心点的距离,选择距离最短的,将车辆划分到该类别,最终得到3个类别的车辆集合,,;
(4)对于每个类别,重新计算其中心点,其中,,;
(5)重复步骤(3)、(4),直到每一类中心在每次迭代后变化不大为止,得到3组车辆集合,即车辆应用场景聚类结果。
4 结果和分析
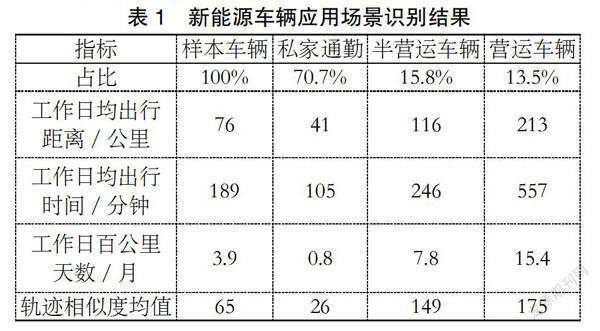
利用构建的算法,对上海市未知车辆的应用场景进行识别,结果如表1所示。私家通勤、兼职网约、全职网约车辆数占比分别为70.7%、15.8%、13.5%,工作日均出行距离分别为41、116、213公里,日均出行时间分别为105、246、557分钟,与相关调研的结论一致:私家通勤车辆以上下班为主,通勤距离通常小于50 km,专职车辆在使用上与巡游出租车相近,行驶距离通常大于200 km,而兼职车辆处于私家、专职之间,出行强度适中。在此基础上,进一步对1 300辆合规网约车辆进行聚类分析,网约场景的识别率达到83%,识别准确率较高。
参考文献:
[1]2020年汽车工业经济运行情况简析[R].上海省汽车行业协会,2020.
[2]上海市新能源汽车大数据研究报告2020[R].上海省汽车行业协会,2020.
[3]夏严.基于用户出行行为特性的插电式混合动力汽车全生命周期效能分析[D].东南大学,2019.
[4]龚玺.时空轨迹聚类方法研究进展[J].地理科学进展,2011(30):522-534.
[5]董炎焱.基于SSE的全局最优K-means算法[J].电子技术与软件工程,2018(11):196-197.
[6]秦嘉诚.基于K-means聚类算法优化方法的研究[J].信息技术,2019(1):66-70.
猜你喜欢
软件导刊(2016年11期)2016-12-22 21:36:40
科技创新导报(2016年21期)2016-12-17 13:19:49
对外经贸(2016年8期)2016-12-13 03:56:53
价值工程(2016年31期)2016-12-03 22:21:20
数学学习与研究(2016年19期)2016-11-22 11:38:21
商场现代化(2016年26期)2016-11-21 22:21:20
商情(2016年39期)2016-11-21 08:45:54
新媒体研究(2016年19期)2016-11-18 19:48:34
大经贸(2016年9期)2016-11-16 16:16:46
中国市场(2016年33期)2016-10-18 12:16:58
