
基于空洞卷积的人体实例分割算法
2021-09-10 07:22王冲赵志刚潘振宽于晓康
青岛大学学报(自然科学版) 2021年2期
王冲 赵志刚 潘振宽 于晓康







摘要:针对人体实例分割任务中存在着姿态多样和背景复杂的问题,提出了一种高精度的实例分割算法。利用Mask R-CNN算法特征融合过程中的细节信息,改善人体分割任务中边缘分割不精确的问题,提高人体分割精度。改进了特征金字塔的特征融合过程,将原有自顶向下的路径改为自底向上,以保留浅层特征图中更多的空间位置信息,并且在特征融合过程中加入多尺度空洞卷积,在增大特征图感受野同时保持分辨率不变,可以避免降采样过程中特征丢失;使用COCO数据集和网络平台,建立新的人体图像数据集。最后将本算法与Mask R-CNN算法做对比,在IoU分别为0.7、0.8和0.9时,准确率提高了0.26,0.41和0.59。实验结果表明,算法在新的人体图像数据集可以得到更精确的结果。
关键词:实例分割;空洞卷积;多尺度特征融合
中图分类号:TP391
文献标志码:A
收稿日期:2020-10-19
通信作者:
于晓康,男,博士,副教授,主要研究方向为计算机几何,计算机图形学,计算机视觉等。E-mail: xyu_qdu@163.com
实例分割实际是目标检测和语义分割的结合。相对于目标检测,实例分割可精确到物体边缘;相对于语义分割,实例分割可以分割出每个独立个体。实例分割算法是从图像中用目标检测方法框出不同实例,然后在不同实例区域内进行逐像素预测的分割方法。目前目标检测领域的深度学习方法主要有两类:双阶段的目标检测算法和单阶段的目标检测算法。双阶段的目标检测算法要先生成一系列的候选框,再进行分类。如RCNN[1]通过选择性搜索產生候选框,再通过SVM对区域进行分类;Fast R-CNN[2]通过选择性搜索算法产生候选框,对候选框进行ROI pooling操作统一特征图大小,最后通过softmax进行分类;Faster R-CNN[3]用区域候选网络(Region Proposal Network,RPN)代替选择性搜索算法,在生成候选框时效率更高。单阶段的目标检测算法无需生成候选框,只要一个阶段就可以完成检测。输入一张图片,直接输出目标检测的结果,如YOLOV1[4],YOLOV2[5]等。随着深度学习的日趋成,越来越多基于深度学习的语义分割框架被提出。Long等[6]提出了全卷积网络(FCN)是对图像进行像素级分割的代表,是神经网络做语义分割的开山之作。FCN可以接受任意尺寸的输入图像,采用反卷积对最后一个卷积层的feature map进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测,同时保留了原始输入图像中的空间信息,最后在上采样的特征图上进行逐像素分类。Chen等[7]提出了DeepLabV2网络模型,引入了空洞卷积,扩大感受野的同时降低了计算量,通过使用多尺度特征提取,得到全局和局部特征的语义信息。Dai等[8]提出的金字塔场景解析网络(PSPNet)引入充分的上下文信息和不同感受野下的全局信息,并在ResNet的中间层加入辅助损失,该模型也取得比较理想的结果。基于目标检测的实例分割,是目标检测和语义分割的合并。人体实例分割,则是人体目标检测与人体语义分割的结合。He等[9]提出了Mask R-CNN算法,以ResNet-101[10]为底层网络,使用金字塔结构融合多尺度特征,构建特征金字塔网络[11-12](Feature Pyramid Networks,FPN),在Faster R-CNN的基础上添加了一个掩码分支,在分割精度上得到了很好的效果。虽然Mask R-CNN在分割精度方面得到很大的提升,但是相对于人体实例分割方面仍然存在着问题,Mask R-CNN中使用的FPN是自顶向下的多特征尺寸融合,即由深层特征到浅层特征的融合,虽然更好地将语义信息融合至浅层网络,但在人体实例分割中存在着姿态和背景复杂的问题,因此浅层的空间位置信息更为重要。针对上述问题,本文在Mask R-CNN算法的基础上,用新的人体图像数据集进行网络训练和评估,为了提高检测准确率,将FPN原有自顶向下路径改为自底向上,以便更好利用浅层网络的空间位置信息。在改进后的FPN网络中加入空洞卷积,扩大感受野,保留大量的语义信息,进一步优化分割结果。
1 方法
本文基于Mask R-CNN算法,针对其中的特征金字塔结构做出改进,鉴于浅层特征图具有更多的空间位置和细节信息,将传统特征金字塔中的自顶向下特征融合结构改为自底向上,将浅层特征图逐层融入到深层特征图中,这样可以将细节信息更好地保存下来。由于ResNet网络中第一层输出的特征图分辨率过大,增加运算成本,本模型从第二层开始构建新的金字塔特征。图像的实例分割是一种像素级分割,要对图像中每一个像素点进行类别判断,因此每个像素的判别与分割结果有很大关系。但是,人体图象分割时不能只考虑像素本身,还要考虑目标的整体性,所以分割时要结合全局语义信息。因此,本文提出使用空洞卷积:空洞卷积是向普通卷积引入了一个新参数——dilation_rate,即空洞率,用来保证在特征图尺寸不变的基础上扩大感受野。空洞率不同时,感受野也会不同,为了得到不同尺度的感受野,实验设置了三种不同的空洞率,确保获取多尺度特征信息。本文设置的空洞率参数分别为1,2,3。如图1所示。
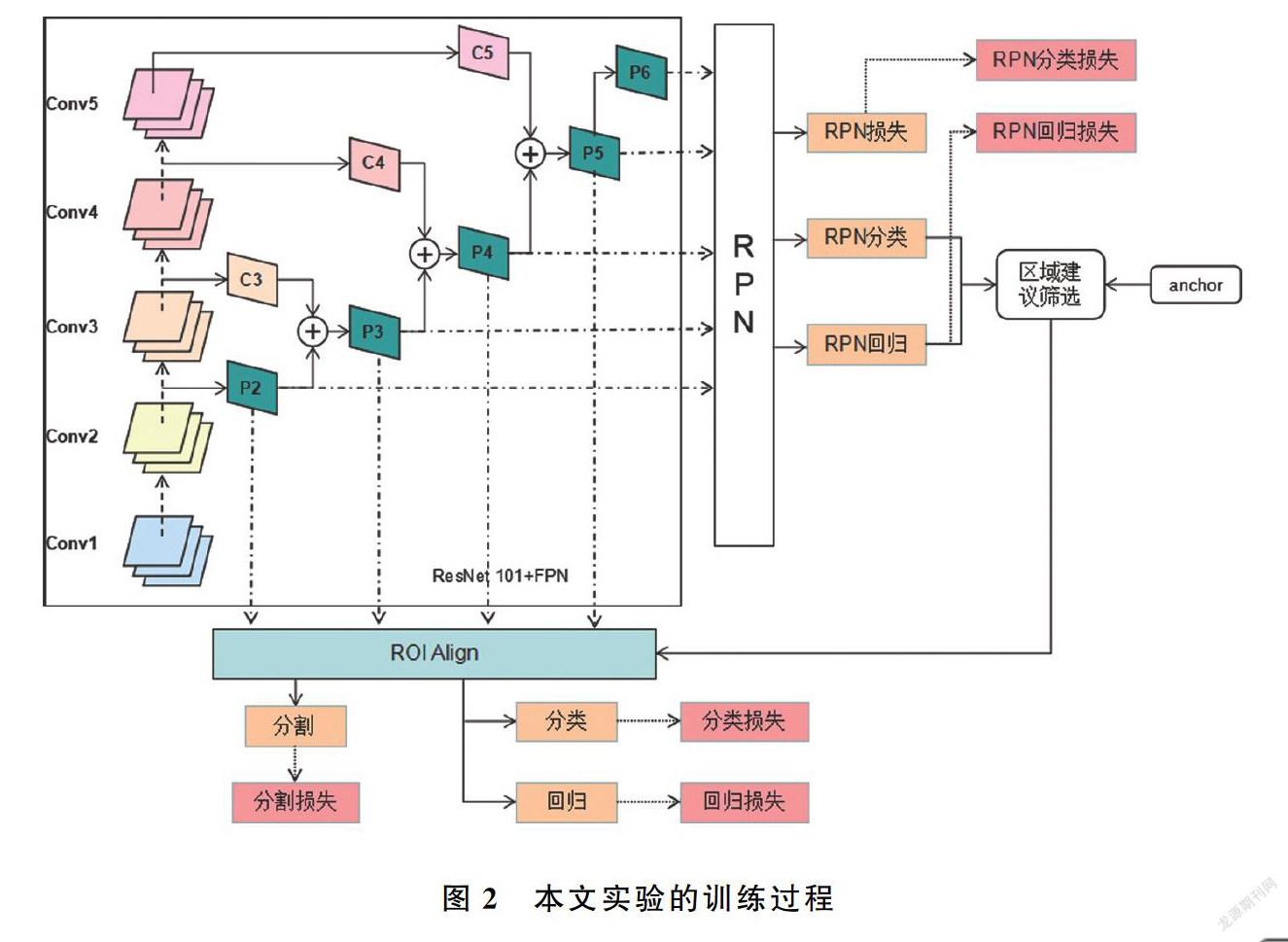
本文提出的网络结构在训练过程和推理过程有以下不同:训练过程要计算RPN损失和网络损失更新网络参数,而推理过程不需要计算损失函数;在训练过程中分类、回归和掩码分割是并行计算的,推理过程中,分类/回归和掩码分割是串行计算的。图2和图3分别为训练过程和推理过程的网络结构。
(1)训练过程。以Resnet101为底层网络,将原版的FPN网络中自顶向下路径改为自底向上,并在FPN的P2~P5层加入空洞卷积构建了高分辨率的特征融合网络。特征融合后,特征金字塔网络生成的各层特征进入RPN。另外对RPN生成的每个锚框进行二分类判断前景和背景,给出该锚框的前景得分并对其进行位置回归。为了减少计算量以及精确检测结果需要对锚框进行筛选,选择适合的锚框进行检测。随后对筛选出来的锚框进行RoIAlign,将锚框映射回特征图,再由映射回特征图的锚框得到固定大小的特征区域,随后对每个特征区域进行分类、回归和掩码分割,并与真实值作比较,分别计算损失。最后依据整体损失,调整参数,在不断训练中最小化损失函数。损失函数为
L=Lcls+Lbox+Lmask(1)
其中,Lcls和Lbox分别表示类别损失函数和边框回归函数,其计算方式与Faster R-CNN中的Lcls和Lbox计算方式相同。Lmask是分割分支的损失,mask分支会输出k×m×m的特征图,其中k表示输出的维度,每个维度表示一个类别,m×m表示特征图大小。Lmask采用平均二值交叉熵函数,只计算对应类别维度的mask损失。
(2)推理过程。推理过程与训练网络有所区别,以Resnet-101为主干网络,将原版FPN中自顶向下路径改为自底而上,且加入空洞卷积,提出新的特征融合结构。在融合网络深浅层特征后,RPN网络对每个生成的锚框进行二分类,判断其为前景或者背景,以前景得分筛选出合适的锚框,进行RoIAlign操作,再对每个特征区域进行分类、回归和掩码分割。
2 实验
本次实验数据集为人体图像数据集,数据集中的图片在COCO数据集选取或者从网络下载得到。本次实验数据集加上背景类共有两类,其中训练集图像2 000张,验证图像200张,测试图像500张。每张图片中最少有一个人体实例。通过labelme制作相应的掩码标签,并标记真实类别。深度卷积网络需要大量数据进行训练,为了防止过拟合问题的出现,得到更好性能的网络模型,在训练阶段使用数据增强技术对数据进行了扩充,对图片进行随机旋转。对原始图片进行旋转,图片对应的掩码也会做相应的旋转。图4所示为旋转后的图片及其对应的掩码。
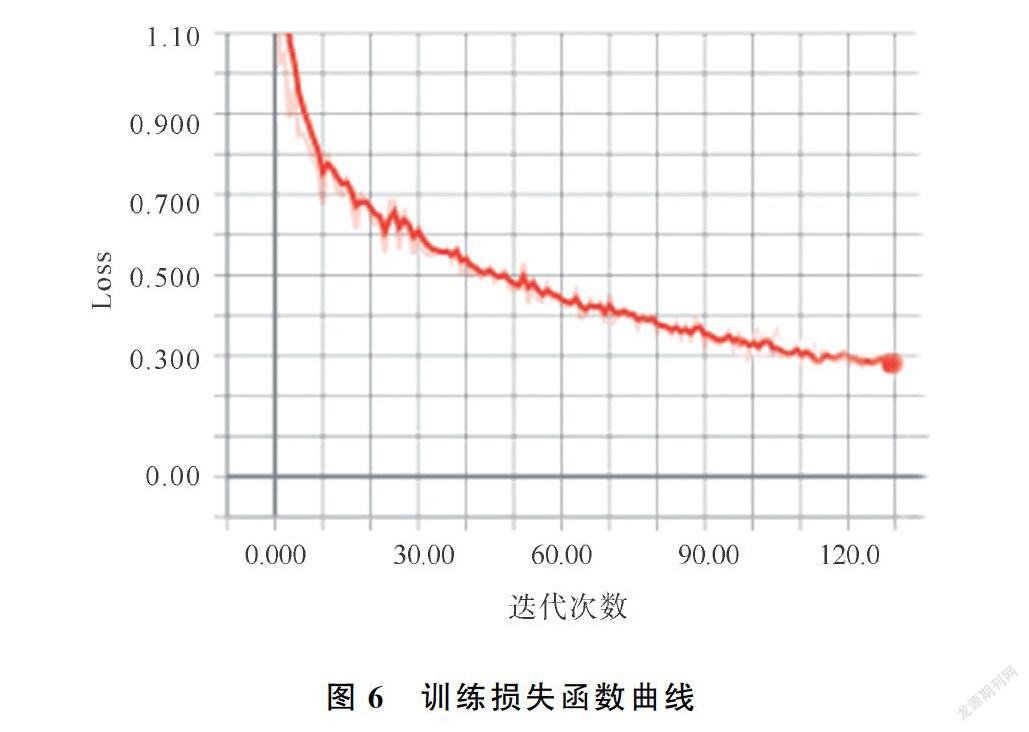
在训练阶段,将原图、真实框、labelme标记的真实掩码标签和真实类别输入网络。使用Resnet101作为主干网络,得到C1到C5不同尺度的特征图,依次对C2到C5层的特征图进行降采样并与其上一层经过降维之后的特征图进行融合,得到特征图P2到P5,尺寸大小分别为[256,256,256],[128,128,256],[64,64,256],[32,32,256]。在特征融合过程中使用不同尺度的空洞卷积以得到不同感受野的特征信息,为了消除特征图相加造成的特征混乱,使用3×3卷积对P2到P5层特征图进行卷积操作,得到的特征图作为后续RPN和全连接层的输入。根据各个特征层的大小得到多个面积和长宽比不同的边界框,这些边界框称为锚框。训练阶段,将每个锚框视为一个训练样本,生成的锚框信息包括前/背景得分和偏移量。通过RPN网络输出全部锚框的信息,用于训练RPN损失,训练时,对前景得分进行排序,保留前景得分最高的6 000个锚框,为了确保不会出现过于重复的推荐区域,修正调整得到候选框,通过非极大值抑制操作保留2 000个候选框。与目标框的交并比(Intersection over Union,IoU)不小于0.5的候選框记为正样本,否则记为负样本。从2 000个候选框中选取200个进行后续训练,其中33%为正样本。根据正样本与真实框的重叠率,确定参与训练的候选框的对应标签,用于掩码分支的训练,在其类别掩码上计算损失函数。其中IoU的计算如图5所示。在测试阶段,骨干网络同样采用Resnet101和改进之后的FPN对图像进行特征提取和融合,进行RPN操作后,对其输出的前景得分进行排序,再通过非极大值抑制保留1 000个候选框,对这1 000个候选框进行ROIAlign操作,将其映射成固定大小相应的特征区域,最后对候选框分类,回归和Mask生成。本次实验使用的深度学习框架是keras,在图片输入的时候将图片缩放到1 024×1 024大小,为每个GPU 处理1张图片,锚框的大小设置为(32、64、128、256、512),每个尺寸对应生成宽高比分别为(0.5、1.0、2.0)的锚框,经过130次迭代,学习率为0.02,权重衰减为0.0001,动量为0.9。在Nvidia GeForce GTX 1080ti GPU上进行实验,图6是训练损失函数曲线,曲线总体呈下降趋势。
为了验证本文中提出模型的有效性,将本文的模型进行实例分割并与Mask R-CNN算法进行了对比,图7是Mask R-CNN模型与本文模型得到的实例分割对比图。图7(a)、(c)是本文算法的分割效果图,图7(b)、(d)是Mask R-CNN算法的分割效果图,其中第1,4,7列为实验结果原图,第2,3,5,6,8列为结果的细节图。通过图7的实例分割对比图来看,本文的模型的分割结果在边缘上与目标更加贴和,如图7第5列人体分割图中,Mask R-CNN算法得到的效果图有着明显缺失,本文模型则可以得到更为精准的分割效果。因为在特征融合过程中使用自底向上的结构可以保留更多的空间位置信息,且空洞卷积可以保持特征图尺寸不变,在一定程度上减少信息损失,提高分割的准确度。
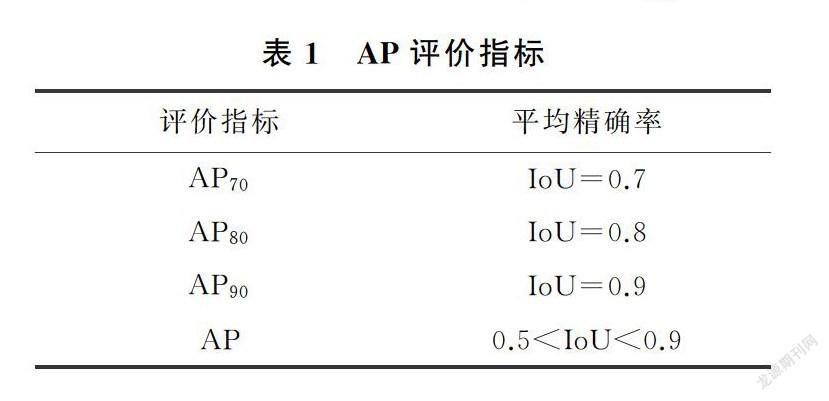
本文以Mask R-CNN算法为比较对象,在不同的IoU阈值下分别计算平均准确率(average precision,AP)来评价本文的性能,AP以召回率为横坐标,精确率为纵坐标,绘制精确率—召回率曲线,曲线下方的面积为AP
AP=∫10P(R)dR (2)
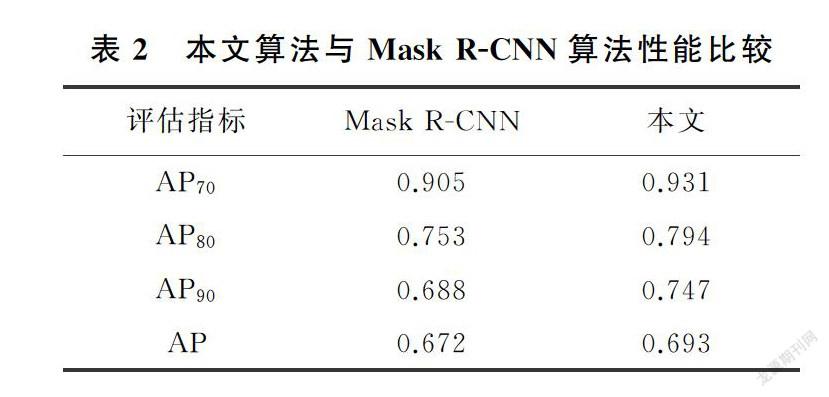
其中,P为精确率,R为召回率,P=TP/(TP+FP)、R=TP/(TP+FN),其中,TP表示被正确预测为正样本的数量,FP表示负样本被预测为正样本的数量,FN表示正样本被预测为负样本的数量。AP的评价指标如表1所示,计算结果如表2,可知,与Mask R-CNN算法相比,IoU=0.7,0.8和0.9时本算法准确率分别提高了0.26,0.41和0.59,实验数据验证了本文方法的有效性,自底向上的特征融合、多尺度空洞卷积的引入使得本文算法分割精度得到了提升,本文方法有着更高的精度。
3 结论
本文对Mask R-CNN算法进行部分修改做人体实例分割,将原有Mask R-CNN算法的FPN结构,加入空洞卷积进行特征融合。在新的人体数据集上进行对比试验,并对本文算法的性能加以分析,可知,通过使用自底向上的特征融合路径和加入空洞卷积,在一定程度上保留了更多的空间位置信息,扩大感受野,保持了全局特征的稳定性。通过对比实验结果,本文提出的算法改善了Mask R-CNN算法中的边缘分割失误的问题提升了平均精度。但本文仍存在着问题,细节分割的边界不精准,例如人的毛发,这是实例分割中的难点,也是未来研究的重点。
参考文献
[1]GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Columbus, 2014:580-587.
[2]GIRSHICK R. Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision (ICCV). Santiago, 2015:1440-1448.
[3]REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]// 29th Annual Conference on Neural Information Processing Systems (NIPS), Montreal, 2015: 1137-1149.
[4]REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Seattle, 2016:779-788.
[5]REDMON J, FARHADI A. YOLO9000: Better, faster, stronger[C]//30th IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Honolulu, 2017:6517-6525.
[6]LONG J, SHELLHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Boston, 2015:3431-3440.
[7]CHEN L, PAPANDREOU G, KOKKINOS I, et al. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs[J]. IEEE transations on pattern analysis and machine intelligence, 2018,40(4):834-848.
[8]DAI J, HE K, SUN J. Pyramid scene parsing network[C]//30th IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu, 2017:6230-6239.
[9]HE K, GKIOXARI G, DOLLAR P, et al. Mask R-CNN[C]//16th IEEE International Conference on Computer Vision(ICCV). Venice, 2017:2980-2988.
[10] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Seattle 2016: 770-778.
[11] LIN T .Y, DOLLAR P, DIRSHICK R, et al. Feature pyramid networks for object detection[C]//30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, 2017:936-944.
[12] 于蘭兰,张志梅,刘堃,等.侯选框算法在车辆检测中的应用分析[J].青岛大学学报(自然科学版),2018,31(2):67-74.
Person Instance Segmentation Algorithm Based on Dilated Convolution
WANG Chong,ZHAO Zhi-gang,PAN Zhen-kuan,YU Xiao-kang
(College of Computer Science and Technology, Qingdao University, Qingdao 266071, China)
Abstract:
Aiming at the problem of multiple pose and complex background in person instance segmentation, a high-precision instance segmentation algorithm is proposed. By making use of the detailed information in the process of feature fusion of Mask R-CNN, the problem of inaccurat edge segmentation in person instance segmentation is improved, and the accuracy of person instance segmentation is improved. The feature fusion process of feature pyramid is improved. The original top-down path is changed to bottom-up path to retain more spatial details in the shallow feature map, and multi-scale dilated convolution is added in the feature fusion process to increase the receptive field of the feature map while keeping the resolution feature map unchanged, which can avoid information loss caused by down sampled. A new person image dataset is established from COCO dataset and network platform. Finally, compared with the Mask R-CNN, the proposed algorithm improves the accuracy by 0.26, 0.41 and 0.59 when the IOU is 0.7, 0.8 and 0.9 respectively. Experimental results show that algorithm can get more accurate person segmentation effect on the new person image dataset.
Keywords:
instance segmentation; dilated convolution; multi-scale feature fusion
