
基于卷积神经网络的CT弦图学习与身体部位识别*
2021-09-10 02:34:42陈诗琳李淑龙马建华
中山大学学报(自然科学版)(中英文) 2021年4期
陈诗琳,李淑龙,马建华
南方医科大学生物医学工程学院/广东省医学图像处理重点实验室,广东广州 510515
基于医学影像的身体部位识别(BPR,Bodypart Recognition)旨在准确定医学影像所属身体部位(例如,头部、胸部或腹部等),是许多医学影像分析算法的预处理步骤[1-2]。近几十年来,学者们研发了大量医学影像分析算法以辅助医生进行临床诊断和治疗决策[3-4],例如,病灶检测算法[5]、器官分割算法[6]等。不同的医学影像分析算法通常需要结合不同解剖结构的先验知识(例如,器官形状)进行设计[7-8]。因此,在执行特定的医学影像分析算法之前,首先需要识别医学影像中包含的身体部位信息以获取先验知识。此外,给定具体的身体部位信息可以减小分类、分割等医学影像分析算法的搜索范围,从而提高算法的速度以及鲁棒性[9]。再者,放射科医生希望在阅片前能针对特定部位减少冗余信息以加快阅片速度。因此,能自动筛选感兴趣部位的身体部位识别算法尤为重要。然而,目前身体部位识别仍是一项艰巨且值得研究的任务[10-11]。
医学影像种类良多,其中包括计算机断层扫描(CT,Computed Tomography)[12]、磁共振成像(MRI,Magnetic Resonance Imaging)[13]以及正电子发射断层扫描计算机断层扫描(PET-CT,Positron Emission To⁃mography-Computed Tomography)等。由于自身优势,CT 相对其他医学影像技术有更为广泛的临床应用。一般而言,CT图像的DICOM 头文件中含有身体部位信息[14]。对于非全身CT扫描,学者们可以通过对DI⁃COM 头文件进行文本检索来实现身体部位识别(例如,胸部CT和腹部CT等)。然而,DICOM 头文件中的身体部位信息存在大约15%的错误,从而限制了使用文本检索身体部位的准确性[15]。此外,DICOM 信息的多语言特性也使得基于文本检索身体部位的研究难以进行[16]。对于全身CT扫描(例如,PET-CT),由于其DICOM 头文件缺少身体部位的信息,学者们无法基于文本检索进行身体部位识别。为了避免基于文本检索方法的问题,越来越多的学者转而研究基于CT 图像进行身体部位识别的算法。与基于文本检索的身体部位识别算法相比,基于CT图像的身体部位识别算法可以有效利用CT图像内部的解剖信息,进而获取更高的身体部位识别精度[17]。
基于CT 图像的身体部位识别研究本质上是一个多分类问题。在过去十几年中,学者们已经提出了许多基于CT 图像的身体部位识别方法。例如,田野等[18]基于CT 图像使用AdaBoost 方法进行身体部位分类识别。Park 等[19]提出一种使用小波变换域中的能量信息来确定身体部位的算法。Hong 等[20]建立了一个全局参考系去识别身体各部位。该方法从识别头部开始,确定头部的边界框后,进而使用不同的算法逐一定位其他身体部位,包括颈部、胸部、腹部和骨盆。Criminisi 等[21]利用回归森林进行解剖部位检测和定位。这些传统分类识别算法大多是先提取预定义的特征,然后使用特定的分类器进行分类。有时这些传统算法还与特征选择方法结合使用[22-23]。然而,这些方法中采用的预定义特征(也称为人工特征,Handcrafted feature)通常难以完全反映CT 图像内部解剖信息[22],这极大地限制了身体部位识别准确率的进一步提高。
近年来,具有强大端到端学习能力的深度学习(DL,Deep Learning)技术,特别是卷积神经网络技术(CNN,Convolutional Neural Network)被广泛用于CT 图像分析任务以及身体部位识别研究中,取得了一定的成功[24]。例如,Roth 等[25]提出一种基于CNN 针对医学图像人体解剖识别的特定分类方法。他们将2D 轴向CT 图像作为CNN 分类器的输入来识别身体的5 个部分(颈部、肺部、肝脏、骨盆以及腿部),其准确率高达94.1%。Yan 等[26]提出了一种用于图像分类的多阶段深度学习框架,并将其应用于身体部位识别任务。Zhang 等[27]利用3D CT 图像的空间信息作为监督源进行身体部位识别研究。这些基于CNN的身体部位识别方法通常是在CT 图像域中构建,而不考虑CT 图像的生成机制。实际上,CT 图像是通过特定的重建算法以及一系列重建步骤从CT 弦图(CT Sinogram)重建生成,其重建过程势必会导致一些原始数据信息的丢失。虽然,专家难以从CT 弦图数据中定义有效的人工特征进行图像分析和疾病诊断,但基于CT 弦图的医学影像分析任务在科学和实践上仍具有可行性,并且具有自主学习能力的深度学习技术使这种可行性得以实现。具体而言,使用端到端训练的CNN 框架可以分析和解释CT弦图,从而进行身体部位识别。最近,越来越多的研究人员试图跳过重建步骤利用深度学习直接对CT 弦图进行分析,以获得更好的医学任务性能[28-29]。Lee等[30]基于深度学习对CT 弦图数据进行身体部位识别并验证了该方法的有效性。然而,该研究的实验数据量较小且只局限于同一种CT扫描设备所收集的增强CT数据。实际上影响身体部位识别性能的因素有很多,例如增强与非增强CT扫描、不同CT扫描设备、正常与病变CT图像等。因此,针对更广泛数据类型的身体部位识别方法仍有待进一步研究。
考虑到上述影响因素,本研究提出利用深度学习对更广泛的CT数据类型进行CT弦图学习,并用于身体部位识别。具体而言,本文方法以CT弦图作为CNN分类器的输入,从而构造基于CNN的五分类器(称为Sino-Net),对5 个身体部位(头部、颈部、胸部、上腹部以及骨盆)进行识别。为了评估本文提出方法的有效性,3 种常见的CNN 结构(残差网络(ResNet)[31]、密集连接网络(DenseNet)[32]以及Inception网络[33])将被改进从而分别构建3种CNN 模型,并使用1个公开数据集(DeepLesion)[34]和3个来自不同医疗机构的临床数据集来进行实验验证。这些数据集包含了正常和带有病变的CT 数据、增强和非增强的CT数据以及来自于不同扫描设备的CT数据,以尽可能多地考虑更广泛的影响因素。实验结果表明,基于CNN 的CT 弦图学习可以达到与基于CT 图像进行身体部位识别相似的性能,甚至优于基于CT 图像识别的结果。
1 试验材料和仿真
1.1 公开数据集(DeepLesion)
本文采用公开数据集(DeepLesion)来训练和五折交叉验证本文提出的方法,即使用CNN 分类器对CT 弦图进行学习,从而识别5 个身体部位。DeepLesion 数据集由美国国立卫生研究院临床中心(NIHCC)创建,是目前世界上最大的CT 影像数据集。该数据集由4 427 名患者的CT 图像组成,涵盖了大多数人体解剖结构[34]。该数据集数据类型广泛,其中包含了增强和非增强CT图像以及正常和带有病灶的CT图像。根据医学解剖对身体部位的划分,我们从该数据集中选择了34 416 张身体躯干部位图像,其图像大小均为512×512。这些图像均由2 名放射科医生手动标记分类,划分为5 个最常见的身体部位:头部、颈部、胸部、上腹部和骨盆,数据分布如表1所示。

表1 DeepLesion数据集中5个身体部位的数量分布Table1 Distribution of five bodyparts in the DeepLesion dataset
1.2 临床数据集
本文使用的3个临床数据集仅用于独立测试以评估所提出方法的性能。(a)胸部数据集:该数据集在美国德克萨斯大学西南医学中心(UTSW)收集,由100例早期(IA 和IB)非小细胞肺癌(NSCLC)患者组成。共包括579 张胸部CT 图像,其图像大小为512×512,使用通用电气(GE)CT 扫描设备扫描。(b)上腹部数据集:该数据集由2010 年1 月至2019 年5 月在南方医科大学附属珠江医院肝胆外科二科就诊的135 例胰腺疾病患者组成。共包括1 537 张上腹部CT 图像,其图像大小为512×512,使用飞利浦(Philips)CT 扫描设备扫描。(c)骨盆数据集:该数据集在美国德克萨斯西南医学中心收集,由15 例IB-IVA 子宫颈癌患者组成。共包括836 张骨盆CT 图像,其图像大小为512×512,使用通用电气(GE)CT 扫描设备扫描。
1.3 数据仿真
由于真实CT弦图为各厂商的商业机密,难以获取。因此,本研究通过数据仿真的方式对CT图像进行仿真从而获得弦图数据。此仿真方法已广泛应用于需要用到CT弦图数据的研究[35]。本研究采用西门子公司Somatom Definition AS+CT 扫描仪的成像几何来模拟弦图,其成像几何参数具体为:X 射线射源到旋转中心的距离595 mm;X 射线源到探测器的距离1 085.6 mm;重建尺寸512×512;体素尺寸0.664 0 mm;探测器数量736;2个相邻探测器之间的间距1.094 7 mm。本研究对上述1个公开数据集和3个临床数据集进行前向拉东变换(Radon transform),在具有泊松(Poisson)噪声和零均值高斯分布随机值的噪声水平下生成CT弦图[36],可由如下公式所示

2 方 法
2.1 方法概述
本文提出算法的总流程图如图1 所示。首先,对DeepLesion 数据集及3 个临床数据集根据1.3 节所提及的数据仿真方法进行处理,以获得CT弦图数据。其次,将DeepLesion数据集仿真得到的CT弦图数据集采用五折交叉验证法训练CNN 分类器,从而识别5 个身体部位,该网络结构被称为Sino-Net。具体而言,以CT 弦图作为Sino-Net 的输入,Sino-Net 会对CT 弦图进行自主特征学习,在Sino-Net 的最后一层将输出一个五维向量(y1,y2,…,y5),然后利用Softmax函数可计算出5个身体部位的预测概率pi(i= 1,2,…,5),计算公式如下

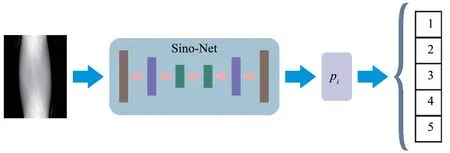
图1 提出方法的总流程图Fig.1 Illustration of the proposed method
实验使用一个具有24 GB 内存容量的NVIDIA Tesla P40 图形处理器(GPU)的PyTorch 工具包进行实验。参数动量(Momentum)可加速学习过程,根据实践经验,我们将其设置为0.9。批大小(Batch Size)为150,对所有网络进行了300个周期的训练,学习率为10-5。
2.2 CNN模型结构
为了验证Sino-Net 对广泛数据类型的CT 弦图的学习能力和对身体部位的识别性能,本文对3 种最常用的CNN结构进行修改,从而执行本文的实验。
2.2.1 基于ResNet修改的CNN结构残差网络(ResNet)于2015 年被首次提出,它在ImageNet 大规模视觉识别挑战赛(ILSVRC)中获得了图像分类的优胜。残差网络易于优化,并且其内部跳跃连接(Short⁃cut)结构可以缓解由于神经网络深度增加而导致的梯度消失问题。因此,本文首先基于残差网络的跳跃连接构建了CNN 模型,此模型被称为Res-BPR,如图2 所示。它由8 个卷积(Convolution)层,4 个最大池(Max-pooling)层和1 个全连接(FC,Fully Connected)层组成。其中,卷积核大小为3×3,共有64 个卷积核,激活函数为线性整流函数(ReLU,Rectified Linear Unit),最大池化大小为2×2。除前两个卷积层外,剩余卷积层之后都添加了批归一化(BN,Batch Normalization)操作。

图2 Res-BPR,它由8个卷积层、4个最大池化层和1个全连接层组成Fig.2 Res-BPR,which consists of eight convolution layers,four max-pooling layers and one FC layer
2.2.2 基于DenseNet修改的CNN结构密集连接卷积网络(DenseNet)于2017 年被首次提出。自此之后,DenseNet 被广泛用于各种图像分析任务中并取得了上佳的效果。DenseNet 具有较强的泛化能力,它的成功得益于它内部的密集连接块(DB,Dense Block)结构,该结构能减轻网络训练过程中出现的过拟合问题。鉴于密集连接块的优点,本文构建了CNN 网络结构Dense-BPR,如图3 所示。它由1 个卷积层,4 个密集连接块,3 个过渡层(TL,Transition Layer),1 个平均池(Avg-pooling)层和1 个全连接层组成。其中卷积核大小为3×3,共有64 个卷积核。每个密集连接块由不同数量的密集层(DL,Dense Layer)组成,4个密集连接块的密集层数量依次为3、6、12以及8。每个密集层由两个卷积层组成,两个卷积层的卷积核大小分别为1×1 和3×3,卷积核数量分别为128 和32。过渡层位于两个相邻的密集连接块之间,它的作用是改变通道大小,使得前一个密集连接块输出的特征图大小能与后一个密集连接块的输入相匹配。过渡层由1 个卷积层和1 个平均池层组成。其中,卷积核大小为1×1,卷积数量为128,平均池化大小为2×2。

图3 Dense-BPR,它由1个卷积层、4个密集连接卷积块、3个过渡层、1个平均池化层和1个全连接层组成。2个相邻的密集连接块由过渡层连接Fig.3 Dense-BPR,which consists of one convolution layer,four Dense Blocks,three transition layers(TLs),one average-pooling layer,and one FC layer. Two adjoining Dense Blocks are connected by a TL
2.2.3 基于Inception网络修改的CNN结构自GoogLeNet于2014年在ILSVRC 中获得第一名以来,Incep⁃tion 模块引起了学者们的广泛关注。Inception 模块使用多个小卷积核代替大卷积核,从而提高了参数的利用率并加快了网络的计算速度。如图4 所示,Inception 模块也被用来构建用于身体部位识别的网络结构,称为Incept-BPR。该网络结构由3 个相同的Inception 模块、1 个卷积层和1 个全连接层组成。每个Incep⁃tion模块由2个不同的卷积层、1个最大池化层以及“四条分支”组成。其中,2个卷积层的卷积核大小为3×3,卷积核数量分别为16 和32。最大池层紧接其后,最大池化大小为2×2。4 条分支中的3 条分支为卷积层,卷积核大小分别为3×3、5×5 以及1×1。剩余1 条分支为平均池层,池化大小为2×2。由于1×1 卷积核运算可以限制通道数并降低计算成本,因此在卷积核大小为5×5、3×3 的卷积层前和平均池层后额外添加了卷积核大小为1×1的卷积层。

图4 Incept-BPR,它由3个Inception模块、1个卷积层和1个全连接层组成Fig.4 Incept-BPR,which consists of three Inception modules,one convolution layer and one FC layer
2.3 实验设置
整体实验设置如图5 所示,本文使用DeepLesion 数据集训练Sino-Net,并采用五折交叉验证法以验证该算法的有效性,3个临床数据集将进一步用来独立测试该算法的性能。此外,与CT 弦图相对应的CT 图像作为以上3个CNN 网络的输入,训练了相应的CNN 网络(称为Img-Net),将用来和Sino-Net进行比较,从而进一步验证Sino-Net 对身体部位识别的性能。Sino-Net 的结果还将与7种传统分类方法的结果进行比较。7种传统分类方法分别为:逻辑回归(LR,Logistic Regression)[37];线性判别分析(LDA,Linear Dis⁃criminant Analysis)[38];K 近邻(KNN,K-Nearest Neighbor)[39];分类和回归树(CART,Classification And Regression Tree)[40];随机森林(RF,Random Forest)[41];朴素贝叶斯(NB,Naive Bayesian)[42]以及支持向量机(SVM,Support Vector Machine)[43]。为了保证实验的公平性,采用同样数据划分的五折交叉验证法训练7 种传统分类方法。具体地,首先对每张CT 图像进行人工特征提取,共包括532 个手工特征,其中,7 个为形状特征,13 个为纹理特征,512 个为直方图特征。然后,将这些特征作为7 种传统分类器的输入,以获得最终的结果。
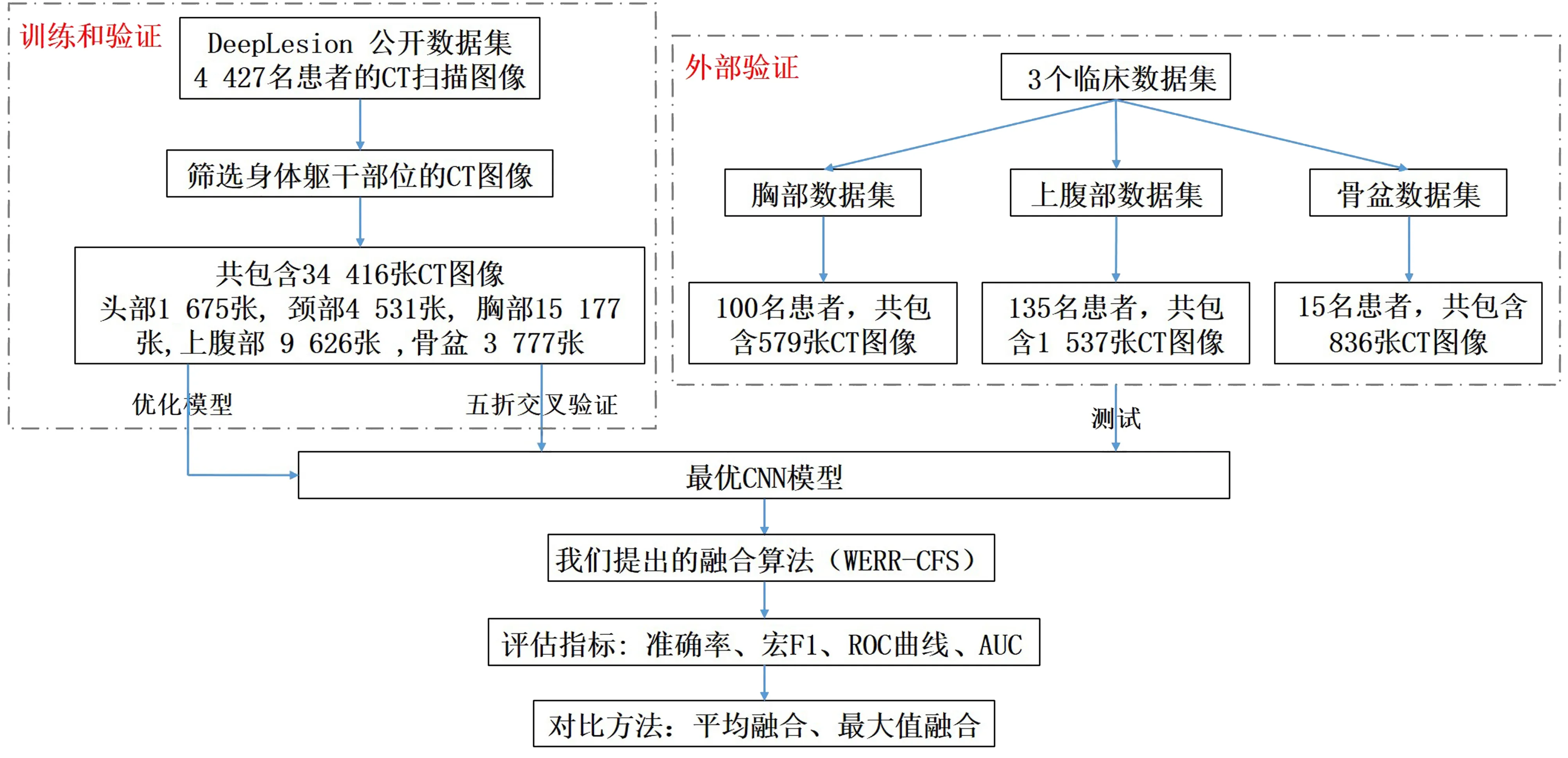
图5 实验设置总流程图Fig.5 Illustration of experiment setup
实验的评估准则包括准确率(Acc,Accuracy),宏F1(macro-F1),接收者操作特征曲线(Receiver Operating Characteristic Curve,ROC 曲线)[44],ROC 曲线下面积(Area Under Curve,AUC)[45]。用于身体部位识别的Acc计算公式

3 结 果
表2 总结了针对DeepLesion 数据集使用3 个CNN 分类器进行身体部位识别的准确率和宏F1 结果。由表2可以观察到基于3种常用CNN 改进的模型(Res-BPR、Dense-BPR、Incept-BPR),Sino-Net 的性能都比Img-Net 的性能更好。Sino-Net 的准确率和宏F1 在Dense-BPR 模型下取得最佳结果,分别为99.77%和99.76%。实验结果表明,基于CT 弦图进行身体部位识别具有可行性和有效性,并且与基于CT 图像的身体部位识别算法相比,结果均有所提高。

表2 3个CNN网络识别身体部位的准确率和宏F11)Table 2 The accuracy and macro-F1 of three CNN networks to recognize bodyparts %
表3 给出了针对DeepLesion 数据集,本文提出的方法(Sino-Net-Dense-BPR)和7 种传统分类方法的准确率比较结果。此实验用在3个Sino-Net模型中表现最好的Dense-BPR 模型来与7种传统分类方法进行比较。由表3 可以观察到,7 种传统方法中随机森林分类器获得最高的准确率(85.52%),远低于Sino-Net-Dense-BPR(99.77%)。图6 展示了本文提出的方法和7 种传统分类方法的ROC 曲线,可以看出,Si⁃no-Net-Dense-BPR 取得了最优的结果。综上结果表明,在身体部位识别算法研究中,本文提出方法在各方面都优于7种传统方法。
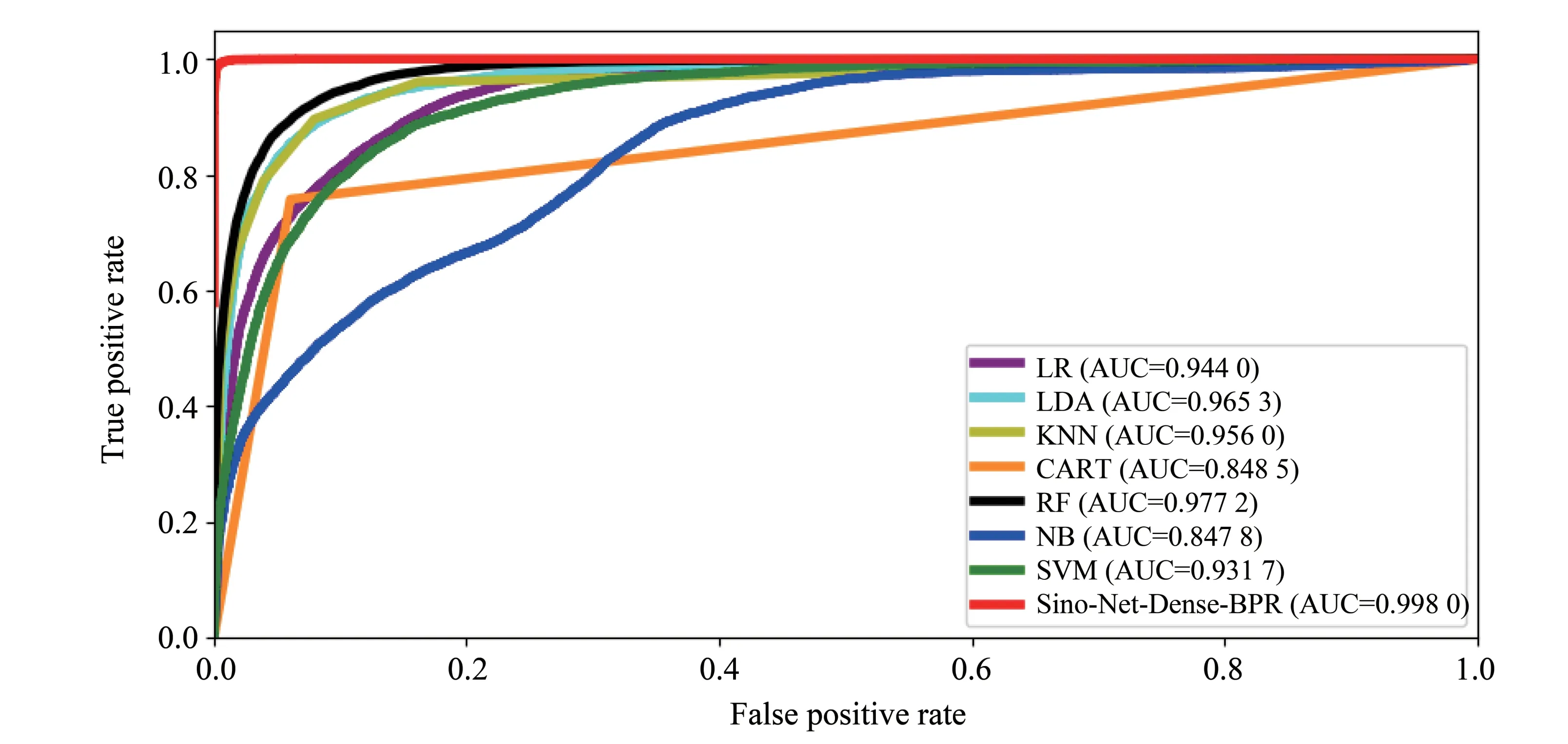
图6 7种传统分类方法和Sino-Net-Dense-BPR 的ROC曲线比较Fig.6 The comparison of ROC curve between seven traditional classification methods and the Sino-Net-Dense-BPR

表3 7种传统分类方法和Sino-Net-Dense-BPR 的准确率比较Table 3 The comparison of accuracy between seven traditional classification methods and the Sino-Net-Dense-BPR %
为了验证本文提出的方法的泛化能力,来自3个不同机构的临床数据集将用于外部验证,以独立测试本文提出方法的性能,结果展示在表4。由表4 可以观察到,Sino-Net 对3 个临床数据集的预测准确率结果都高于Img-Net的预测准确率结果,并且Sino-Net在3个数据集中都取得了上佳的结果。这些结果表明,对于来自不同CT扫描设备的数据本文提出的方法具有良好的泛化能力。

表4 3个临床数据集的准确率Table 4 The accuracy of three clinical datasets %
4 讨论和结论
本文使用基于CNN 的深度学习方法对广泛数据类型的CT弦图数据进行学习并应用于身体部位自动识别,通过改进3种常用CNN结构(ResNet、DenseNet和Inception网络)分别构建3个CNN五分类器,并采用公开数据集DeepLesion 和3 个临床数据分别进行模型训练、五折交叉验证和外部验证。实验结果表明,基于CT弦图的CNN分类器(Sino-Net)在身体部位识别任务中能达到和基于CT图像方法进行识别类似的效果,甚至优于基于CT图像识别的结果。这表明基于CT弦图的医学图像分析任务值得进一步探究,具有潜力。虽然本实验取得了不错的结果,但是本文只对临床CT扫描中5个最常见的身体部位进行分类识别,可能不足以用于临床实践。在将来的研究中,我们将进一步细分身体部位探究本文方法的性能。此外,由于身体部位过渡区域界限的不明确性[46],仍然存在着一些错分的情况,将来有必要进一步研究解决这个问题。
猜你喜欢
中国药学药品知识仓库(2022年8期)2022-05-09 13:54:24
中国临床医学影像杂志(2021年10期)2021-11-22 07:46:38
中国医学影像学杂志(2021年6期)2021-08-13 08:43:08
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
