
用于车辆重识别的基于细节感知的判别特征学习模型*
2021-09-10 02:33:36邱铭凯李熙莹
中山大学学报(自然科学版)(中英文) 2021年4期
邱铭凯,李熙莹
中山大学智能工程学院/广东省智能交通系统重点实验室/视频图像智能分析与应用技术公安部重点实验室,广东广州 510006
车辆重识别的一个重要应用就是重构车辆轨迹。通过车辆重识别,可以实现连续时间内同一车辆在不同摄像头下的关联,实现基于道路监控视频的车辆轨迹重构。利用车辆重识别重构的车辆轨迹,结合车辆驾驶员信息,可以实现用户乘客出行规律分析,进一步实现乘客出行预测及出行引导。另外,在公安刑侦方面,车辆重识别可以用于车辆跟踪、被盗车辆检索以及车辆套牌验证等场景。因此,车辆重识别在智能交通系统中具有重要的研究意义。如何在视频大数据中基于计算机视觉技术,自动实现车辆重识别,是智能交通系统发展中一个亟需解决的问题。
车辆重识别在实际研究中的一大挑战就是对外观相似的不同车辆进行区分。在实际场景中,道路上存在多辆车属于同一款式的情况,而在同一摄像头下拍摄到的不同车辆,由于款式和颜色相同,外观相似度高,难以区分。由于相似外观的不同车辆之间的差异主要集中于车窗装饰物等局部区域,提升算法对于局部细节差异的捕获能力成为研究的关键。
现有的车辆重识别研究主要利用深度学习技术,通过设计相应的训练任务及改进网络结构来指导网络提取到具有辨识度的特征。为了加快网络训练,使得网络训练过程更加稳定,Liu 等[1]设计了一个Couple Cluster Loss 以改进三元组损失;考虑类内差异,Bai 等[2]提出了一个Group-Sensi⁃tive-Triplet Embedding 方法,将同一车辆的不同图片按照属性差异划分为多个组,同一组内的图片被认为是具有相同的属性,然后在损失函数中考虑组间的差异,以及不同车辆之间的差异,达到特征差异化的目的;考虑多视角下车辆的重识别,Chu 等[3]和Zhou 等[4]研究利用对抗生成网络来通过单视角图片生成车辆的多视角融合特征;考虑车辆关键部位特征提取,Khorramshahi 等[5]和Guo等[6]通过车辆关键部位定位以及关键点检测,利用注意力机制来提取具有辨识度的特征。这些方法的实验结果表明,添加限制性更强的损失函数以及有选择性的引入额外的特征可以提高算法的鲁棒性以及增强算法的识别效果。
卷积神经网络提取的特征可以根据深度被分为三个部分:浅层、中层及深层特征。其中,浅层特征对浅层视觉信息进行表达,包括边缘、角以及圆等;中层特征对图片物体的各个部分进行表达;深层特征得到关于图片整体的语义信息表达[7-8]。因此,利用网络的中层特征将会有助于网络对于车辆局部区域的细节特征的提取,提高网络对于车辆细节差异的辨识能力。
为了提升算法对于局部细节差异的捕获能力,本文提出了一个基于细节感知的判别特征学习网络模型。模型以InceptionV3[9]网络为基础结构,设计了一个指导式的局部特征提取流程。在网络结构中,将基础网络划分为浅层、中层和深层三层,对中层网络设计基于注意力机制的局部特征提取模块;结合局部限制及混合采样策略指导局部特征提取。最后,将网络提取的局部特征及全局特征组合作为车辆的联合特征,计算不同车辆之间特征的欧式距离作为相似度衡量。模型在公开数据集VehicleID[1]及VeRi[10]上都可以取得领先于现有算法的水平。
1 基于细节感知的判别特征学习模型
本文设计的基于细节感知的判别特征学习模型,如图1 所示。在网络结构设计中,以Incep⁃tionV3 作为基础骨干网络,引入局部特征提取模块,以局部特征及基础骨干网络提取到的全局特征作为车辆的联合提取特征;在模型训练中,设计多任务联合训练,以不同的损失函数指导特征的生成;为了优化模型的训练,在图片输入部分,模型设计了有效的混合采样策略。对于局部特征的生成提取,算法以局部特征提取模块为基础,结合局部限制及混合采样策略,组成了一个完整的指导式局部特征提取流程。
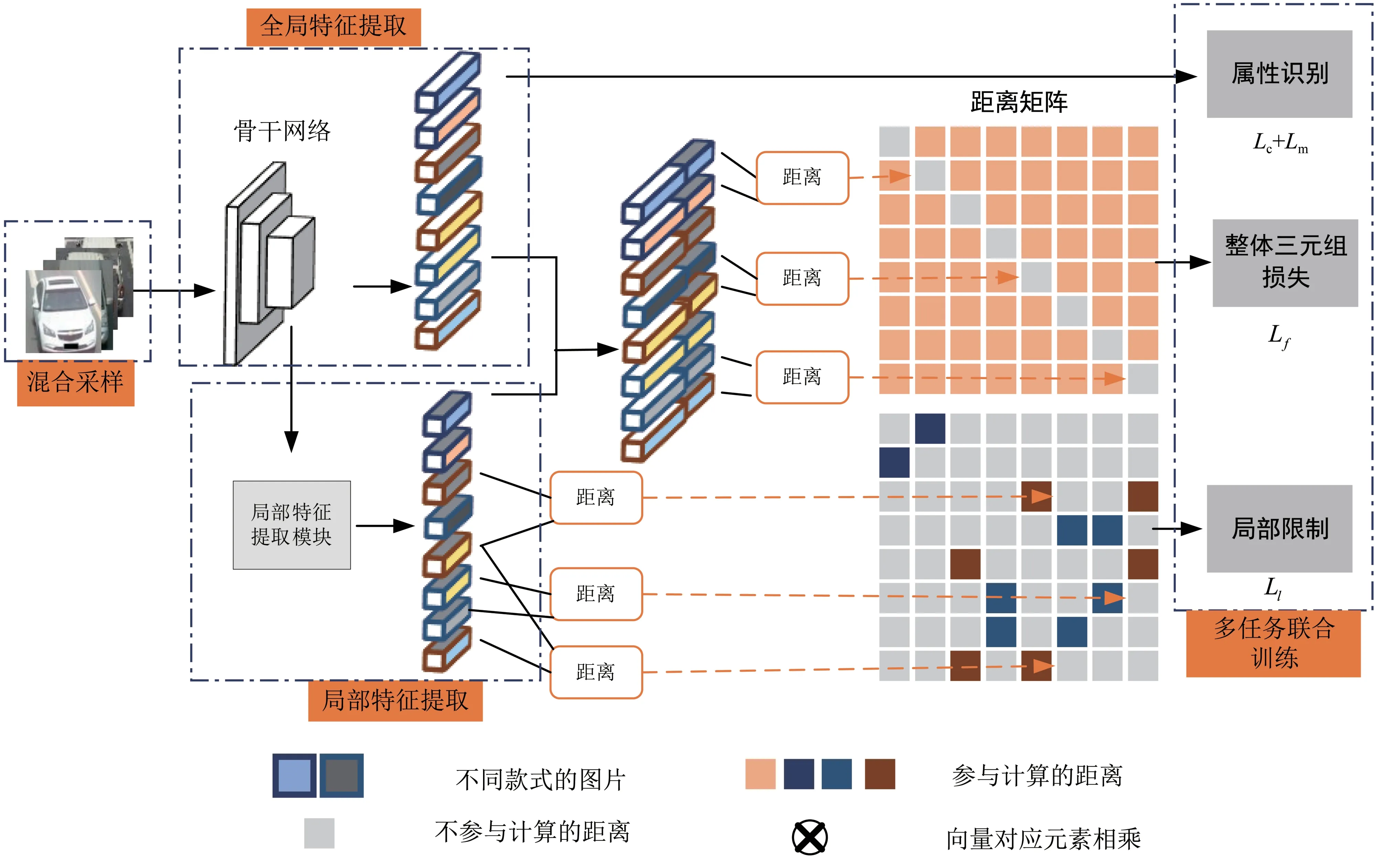
图1 基于细节感知的判别特征学习模型Fig.1 Detail-aware discriminative feature learning model
1.1 全局特征提取
判别特征学习模型中的基础骨干网络负责车辆全局特征的提取。在车辆重识别算法中,普遍使用VGG16[11],Inception[9]以及ResNet[12]等经典网络作为基础骨干网络。其中,InceptionV3 网络的基本结构如表1 所示,因为Inception 模块的存在,InceptionV3 可以更好的适用于多尺度特征的提取,所以在本研究中使用InceptionV3 作为基础骨干网络。

表1 InceptionV3 网络结构表Table 1 Network architecture of InceptionV3
Inception 模块如图2 所示。Inception 模块设计为先进行多尺寸的卷积、池化并行运算后,将输出并联。一方面能够增加网络的宽度,另一方面增加了网络对于尺度的适应性,从而使得Inception网络可以更好地适用于多尺度特征提取。
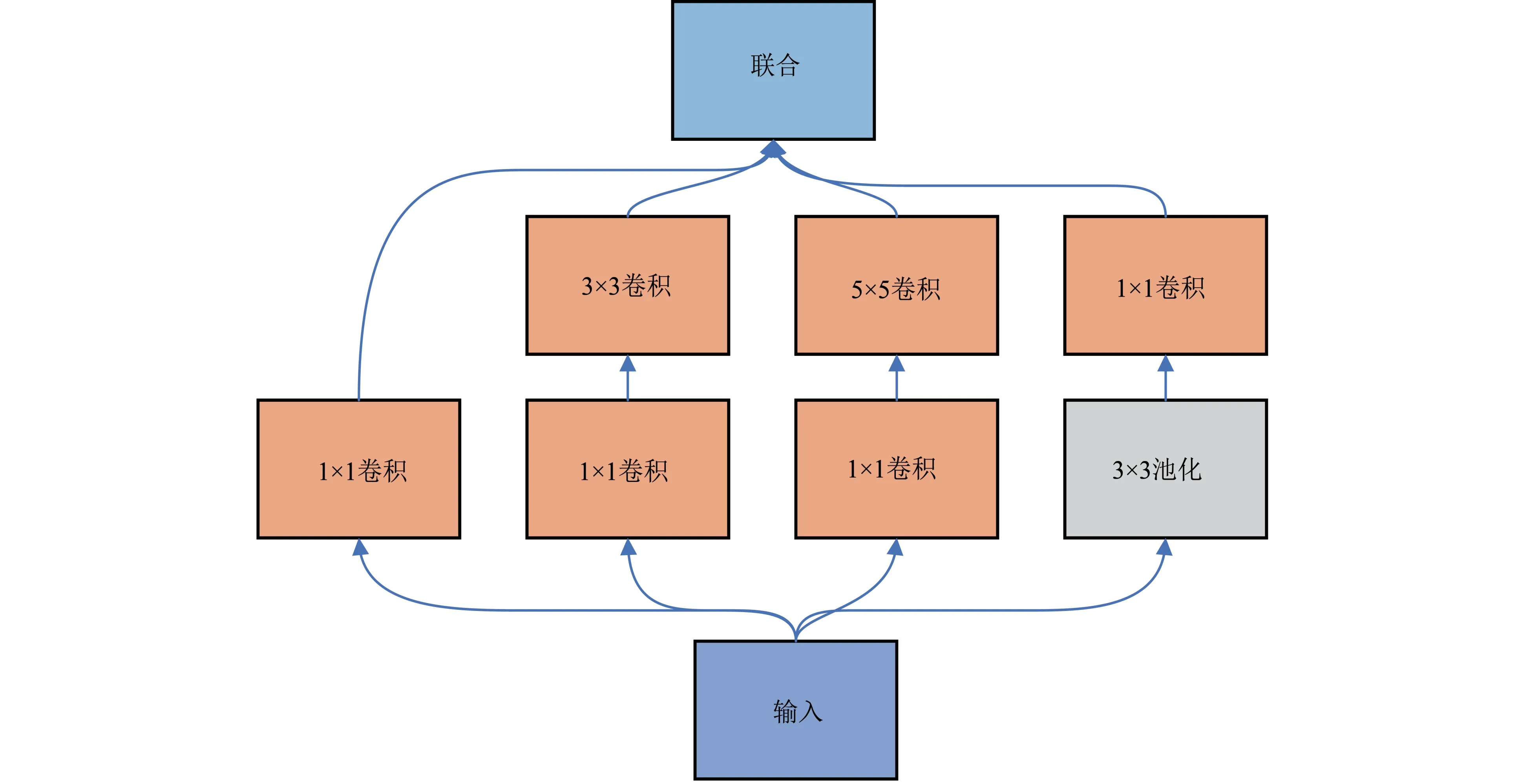
图2 Inception 模块Fig.2 Inception Module
这里使用Inception 网络会更有利于对车辆局部区域特征的捕捉。对输入图片,经过Incep⁃tionV3 网络提取,可以得到大小为1×2 048 的表示车辆全局特征的向量。
1.2 局部特征提取
1.2.1 局部特征选择车辆局部特征的提取分为网络划分、中层网络特征提取两步。为了对基础网络结构InceptionV3 进行划分,在网络划分阶段,参考文献[13],首先按照图3 所示的基础算法训练,训练完成后,对InceptionV3 各层网络学习到的特征进行了可视化。
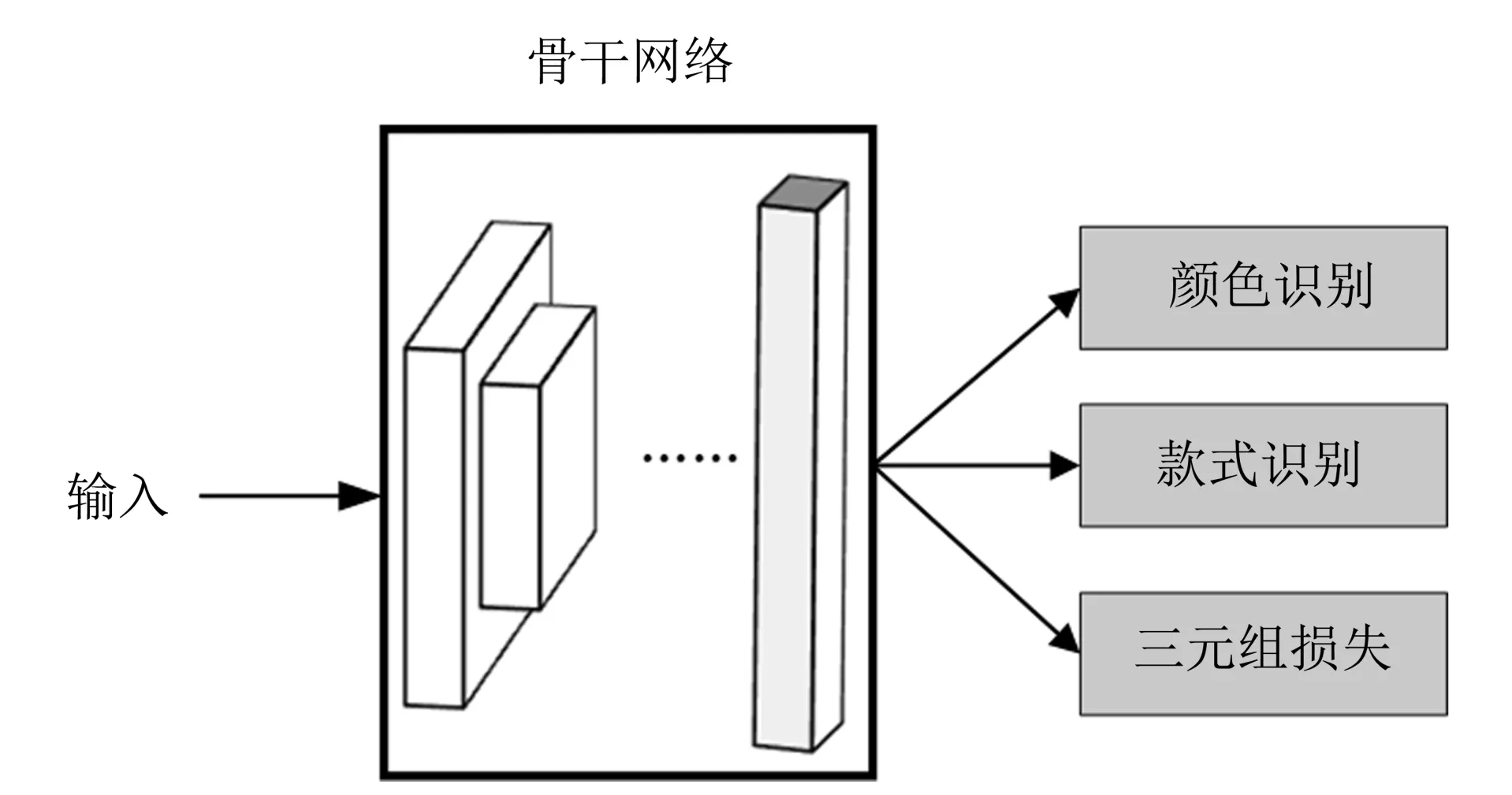
图3 车辆重识别基础算法Fig.3 Baseline algorithm for vehicle re-identification
网络每一层的部分特征图的可视化结果如图4所示。可以看到,对于InceptionV3 网络,给定输入图片,Conv1 到Conv5 这5 层学习到的是颜色、边缘、线段等特征;Mixed5 及Mixed6 学习到的大部分是车辆的局部区域,包括车辆栅格、车顶、车窗、车灯等。Mixed7 学习到的则是偏全局性的特征。因此,将Mixed5 以及Mixed6 两个Inception模块划分为中层网络。

图4 InceptionV3 网络各层特征可视化结果Fig.4 Feature visualization results of InceptionV3
基于前面的假设,网络的中层特征有助于网络对于车辆局部区域特征的提取,所以中间层Mixed5以及Mixed6被用于提取车辆的局部特征。
1.2.2 基于注意力机制的局部特征提取模块在实际场景中区分不同车辆时,车辆的各个区域具有不同的辨识度。高辨识度区域主要集中于车灯、车辆栅格、车标以及车辆挡风玻璃等区域。因此,对局部特征进行提取、比对的过程中,应该考虑不同局部区域特征的辨识度,增强具有高辨识度的特征,抑制低辨识度特征的干扰。
基于上面的描述,在局部特征提取模块的设计中,我们引入注意力机制,根据区域的重要性实现网络自学习并自动分配不同的权重,得到带注意力机制的局部特征提取模块,模块结构如图5中所示。
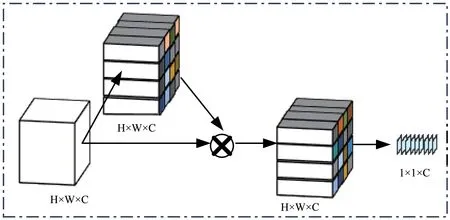
图5 局部特征提取模块Fig.5 Local feature extraction module
对于大小为H×W×C 的中间层特征图,添加一个卷积核大小为3×3、步长为1×1 的卷积层,得到一个与原始特征图同样大小的注意力特征图。在这里,使用Sigmoid 函数作为激活函数,从而保证得到的特征图中的数值大小位于(0,1)区间内。得到的注意力特征图与原始特征图相乘后进行全局池化,即可得到最终的局部特征向量。
1.3 多任务联合训练
输入车辆图片,模型提取得到两部分特征:全局特征以及局部特征。针对全局特征、局部特征以及两者组合的联合特征,分别设计了不同任务及相应的损失函数,以指导特征的生成。
对于全局特征,设计了车辆的属性识别任务,分别对车辆的颜色以及款式进行识别。颜色及款式识别属于多分类问题,使用softmax 交叉熵函数作为损失函数:
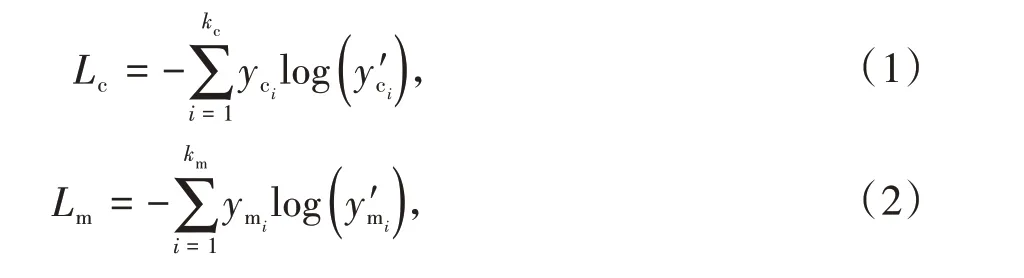
其中下标c 和m 分别表示颜色及款式。对于颜色识别,kc表示车辆颜色种类的数目,是网络输出的对于车辆属于第i种颜色的概率的预测值。yci为0 或1,表示车辆颜色的真实值,定义为

对于款式识别,km,ymi,y′mi的含义与ym,yci,y′ci类似。对于车辆的联合特征,在算法中设计了整体三元组损失函数。
对于车辆的联合特征,在算法中设计了整体三元组损失函数。从训练集中随机选择一张图片作为anchor,记为xa;再随机选择一张与xa属于同一车辆、但是不同的图片作为正样本(positive),记为xp;同时,选择一张与xa属于不同车辆的图片作为负样本(negative),记为xn。这样,就组成一个训练三元组[xa,xp,xn],输入网络后可得到三元组的特征表达[Gf(xa),Gf(xp),Gf(xn)]。整体三元组损失函数为
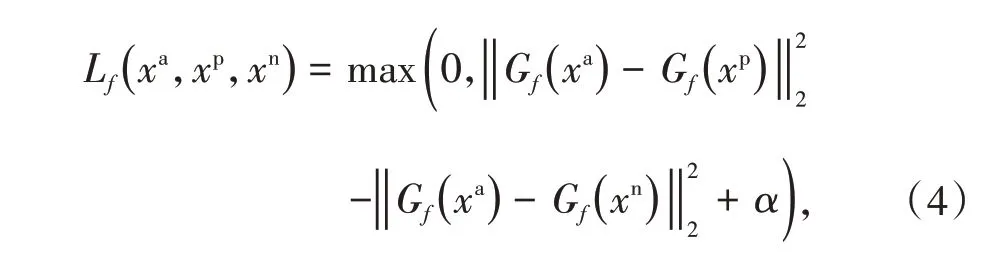
其中α是预设值的阈值。

1.4 混合采样策略
根据局部限制中对于三元组样本构造的要求,在网络输入中,不同于一般算法的直接随机抽取M张图片作为输入,本算法中设计了混合采样策略,如图6所示。
图6中,车辆优先策略属于一种先随机选择车辆,再随机选择图片的二次随机过程。车辆优先策略以车辆为基本单位,先对车辆进行随机采样,选择K1辆车后,分别对每辆车的所有图片进行随机选取,选取P1张图片,则一个批次训练的总图片数目为K1×P1。车辆优先策略的优点是可以保证训练集中每一张图片都可以找到属于相同车辆的其他图片,从而能够组成有效的三元组,有效地加速网络训练,保证网络收敛。
图6的款式优先策略在车辆优先的基础上,加入了对款式随机选择的过程,属于一种三次随机过程。与车辆优先策略不同,款式优先策略以款式为基本单位,先随机选取C个款式,对每一个款式随机选取K2辆车,对每一辆车再随机选取P2张图片,则一批次的训练图片总数为C×K2×P2。款式优先策略的意义在于:因设计了一个局部限制三元组损失函数,对于给定的anchorxam,只有与anchor属于相同款式不同车辆的图片才被确定为负样本。如果仅采用车辆优先策略,则在同一批次训练中,存在两辆及以上车辆属于同一款式的概率极低,即使用车辆优先策略不利于局部限制三元组损失函数的收敛,而款式优先策略则可以很好的解决这一问题。
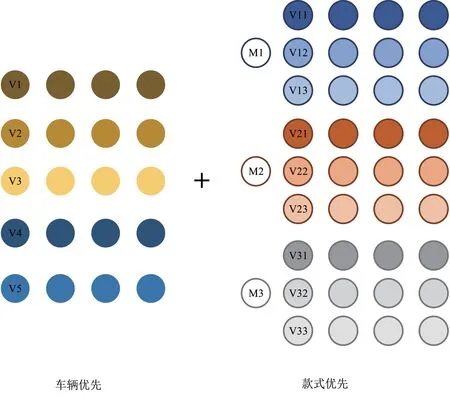
图6 混合采样策略Fig.6 Mixed sampling strategy
款式优先策略可以满足需求,但是在本算法中,使用的是车辆优先策略结合款式优先策略的混合采样策略,使用混合采样策略的意义会在实验部分进行阐述。
2 实验验证
2.1 实验设置
算法使用在ImageNet[14]数据集上预训练好的模型进行参数的初始化。对于网络的基础设置,使用Adam 优化器作为参数优化器,使用默认的参数设置(ϵ= 10-3,β1= 0.9,β2= 0.999)。初始学习率设置为0.000 1,批大小(batch-size)设置为128,学习率衰减设置为每5 个epoch 乘以系数0.9,训练100 个epoch。对于算法中的各个参数,在整体三元组损失函数以及局部限制三元组损失函数中,设置α=β= 1.0;在混合采样策略中,设置C=K2=P1=P2= 4,K1= 16,即款式优先策略与车辆优先策略采样数目相同,各采样64 张图片。
2.2 数据集及评价标准
在测试中,给定查询集,对于查询集中每一张图片,在候选集中进行匹配。为了评价查询集在候选集中的匹配效果,本研究使用3个指标作为评价标准:rank1 准确率,rank5 准确率以及mAP(mean average precision)。为了对算法的有效性进行验证,本研究使用车辆重识别公开数据集Vehi⁃cleID[1]与VeRi[10]作为实验数据集。
VehicleID 数据集采集自中国城市道路上监控摄像头于白天拍摄到的视频。总共包含26 267 辆车共221 763 张图片,每张图片根据车牌号都标注有相应的ID,其中共78 957 张图片标注有款式及颜色信息,共228个款式,7种颜色。
VehicleID 数据集中提供了三种不同大小的测试集。其中,Test800 测试集包含800 张查询图片,6 532 张候选图片;Test1600 测试集包含1 600 张查询图片,11 395 张候选图片;Test2400 测试集包含2 400 张查询图片,17 638 张候选图片。后续试验会在三个不同测试集上进行,根据VehicleID 数据集的设置,使用rank1 及rank5 准确率作为算法在VehicleID数据集上的性能评价指标。
VeRi 数据集采集自中国福建省福州市永泰县一条道路上的道路监控摄像头拍摄到的视频,总共包含776辆车共49 357张图片。VeRi数据集中所有车辆都标注有颜色及车型信息,共9种车型,10种颜色。数据集中还提供了每一图片拍摄的位置信息及时间信息。
VeRi数据集中,其中500辆车共37 778张图片作为训练集,剩余200辆车共11 579张图片作为测试集。测试集中,划分1 678 张图片作为查询集合,剩余9 901张图片作为候选集合。根据VeRi数据集的设置,使用rank1准确率,rank5准确率以及mAP作为算法在VeRi数据集上的性能评价指标。
2.3 消融分析
本文提出的算法包含了局部特征提取、局部限制、采样策略等各个组件。为了对各个部分选择最有效的设计方式,以及明确各个部分对于算法效果的影响,我们对算法进行了消融分析,从而得到各个部分对于基础算法的提升效果。本部分实验以VehicleID 数据集的Test800,Test1600 和Test2400测试集进行测试。
首先,在局部特征提取模块设计中,考虑中间层以及池化方式对于算法的影响,我们将Incep⁃tionV3 网络的Mixed5 以及Mixed6 两个Inception 模块划分为中层网络。另外,利用中层网络特征图进行全局池化提取得到局部特征。在实验中,我们对不同模块分别进行全局均值池化以及全局最大值池化的对比。实验结果如表2 所示,其中Max,Ave 分别表示采用全局最大值池化及全局均值池化。
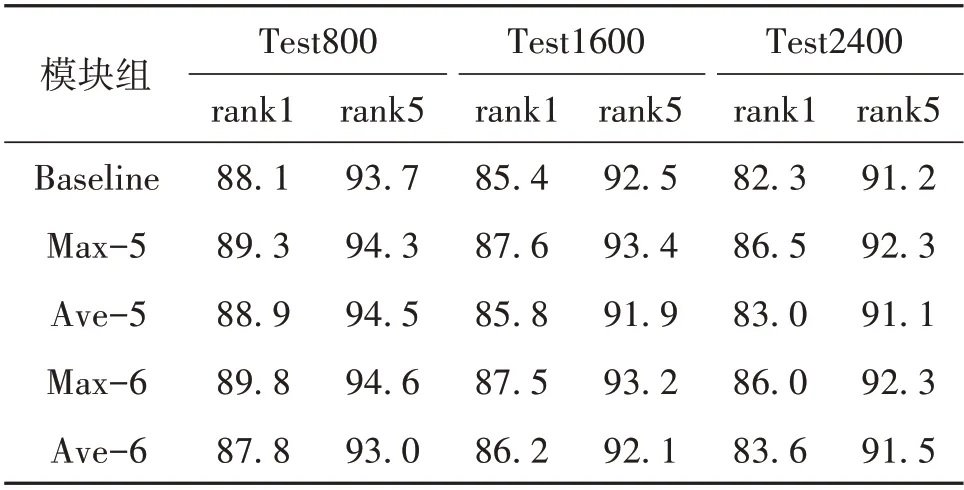
表2 不同中间层及池化方式组合的实验结果Table 2 Results of different combination of middle layers and pooling methods %
由表2可以看出,对于两个模块组,使用全局最大值池化进行特征提取在三个测试集上的表现都要优于使用全局均值池化。在使用全局最大值池化时,使用Mixed6 模块组在Test800 上的rank1准确率和rank5 准确率要优于Mixed5 模块组,但是在Test1600 和Test2400 两个较大的测试集上的rank1 和rank5 准确率则都要劣于Mixed5 模块组。考虑到Mixed6 模块组提取到的局部特征维度为768,远远大于Mixed5 模块组提取到的288 维特征向量,结合表格3的数据,在最终算法中将局部特征提取模块设计为利用全局最大值池化方式,对Mixed5模块组提取局部特征向量。
与Baseline 相比,加入局部特征向量,在不同的测试集上的rank1 和rank5 的准确率都有所提升。在Test800 测试集上,Max-5 的rank1 和rank5 准确率分别提高1.2%和0.6%,而在Test1600 测试集上,Max-5 的rank1 和rank5 准确率分别提高2.2%和0.9%;在Test2400 测试集上,Max-5 的rank1 和rank5 准确率分别提高4.2%和1.1%。可以看到,随着测试集的数量增大,加入局部特征向量对于准确率的提升越大。这是因为测试集的数量越大,则意味着存在外观相似的车辆数量越多,算法更大概率会因混淆而导致误判。而引入局部特征向量,则能够增强算法对于局部区域特征的辨识能力,从而能够更好的对易混车辆进行区分。所以,测试集数量越大,引入局部特征算法相比于原始算法的优势则越大。
其次,考虑引入注意力机制以及局部限制对于算法的影响。实验结果如表3 所示,其中att 表示注意力模块,LC 表示局部限制,最后的Max-5+att+LC则为最终的算法。
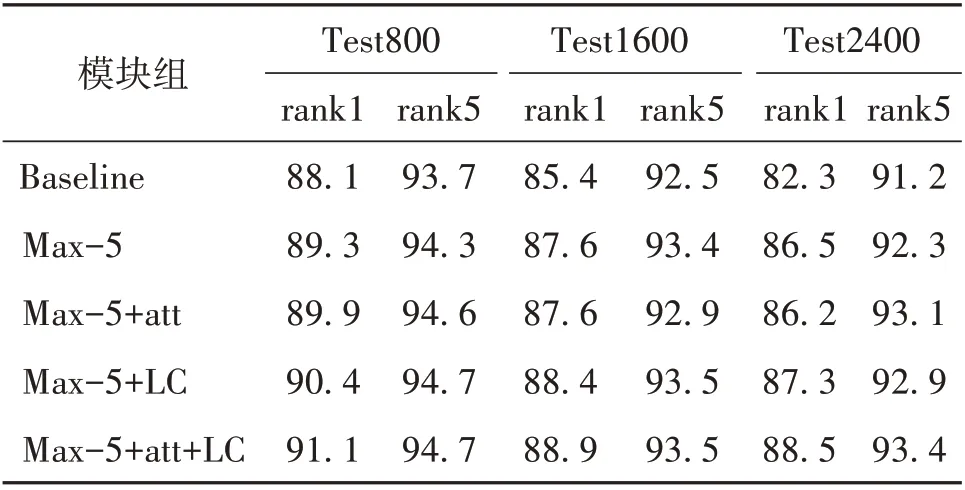
表3 组件消融分析结果Table 3 Ablation analysis results of components %
由表3可以看出,相比于原始的加入局部特征向量,单独引入注意力机制,在Test800 测试集的rank1 准确率提升0.9%;而在Test1600 和Test2400两个测试集上的rank1 和rank5 准确率则近似没有变化。另外,单独加入局部限制,在三个测试集上的准确率都要优于单独引入注意力机制。相比于原始的仅加入局部特征向量,在Test800 测试集的rank1 准确率提升1.1%,在Test1600 和Test2400上的rank1 准确率都提升了0.8%。而,同时引入注意力机制及局部限制,相比于原始的加入局部特征向量,在Test800 测试集上的rank1 和rank5 准确率分别提高1.8% 和0.4%,在Test1600 上的rank1 准确率提高1.3%,在Test2400 上的rank1 和rank5 准确率则分别提升2%和1.1%。可以看到,引入注意力机制和局部限制对算法在不同大小测试集上的rank1 准确率影响最大,而对于rank5 准确率的影响则较小。
在实验中,我们使用了款式优先结合车辆优先的混合采样策略。对混合采样策略和款式优先策略进行比较,实验结果如表4 所示。其中Mix 表示混合采样策略,MF表示款式优先策略。
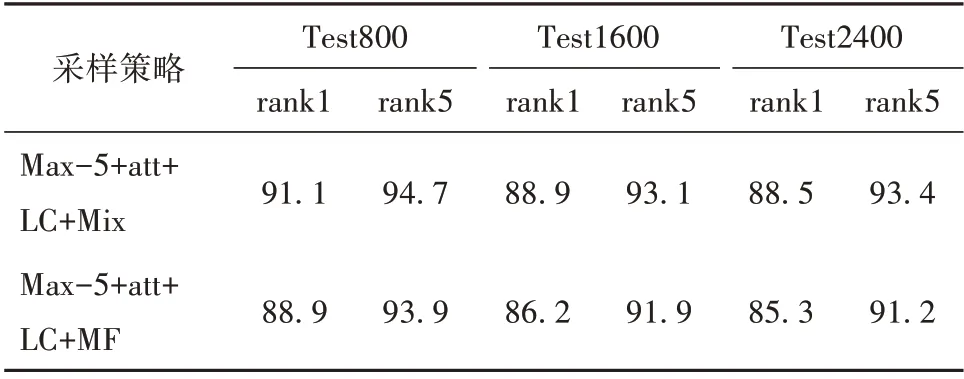
表4 不同采样策略的结果Table 4 Results of different sampling strategies %
可以看到,仅使用款式优先策略,相比于使用混合采样策略,在Test800 测试集的rank1 和rank5 准 确 率 分 别 下 降 了2.2% 和0.8%, 在Test1600 上的rank1 和rank5 准确率分别下降了2.7%和1.2%,在Test2400上的rank1和rank5准确率分别下降了3.2%和2.2%。出现准确率下降的原因为:如果单独采用款式优先策略,则对于每一车辆,在样本集中都存在与其相同款式但是不同ID 的车辆图片。由于在整体三元组损失的计算中,对于每一个anchor,都是选择与其距离最近的负样本,即外观最相似的不同车辆的图片。则由于款式相同的车辆之间外观最接近,对于每一个anchor,选择的都是与其相同款式但是不同ID的车辆图片进行训练,这也就意味着网络在训练的过程中没办法学习到不同款式车辆之间的差异。而采用款式优先结合车辆优先的混合策略,则一方面可以保证在样本集中存在可以满足局部限制三元组的样本对,另一方面可以保证网络可以学习到相同款式以及不同款式车辆之间的差异。
2.4 结果对比
将本研究的算法与现有的其他车辆重识别最新算法在VehicleID 及VeRi 数据集上进行对比。我们 选 择 的 对 比 算 法 包 括DRDL[1]、PROVID[10]、VAMI[3]、 JFSDL[15]、 ABLN[4]、 DHMVI[16]、TAMR[6]、AAVER[5]、EALN[17]。算法对比结果如表5-6所示。
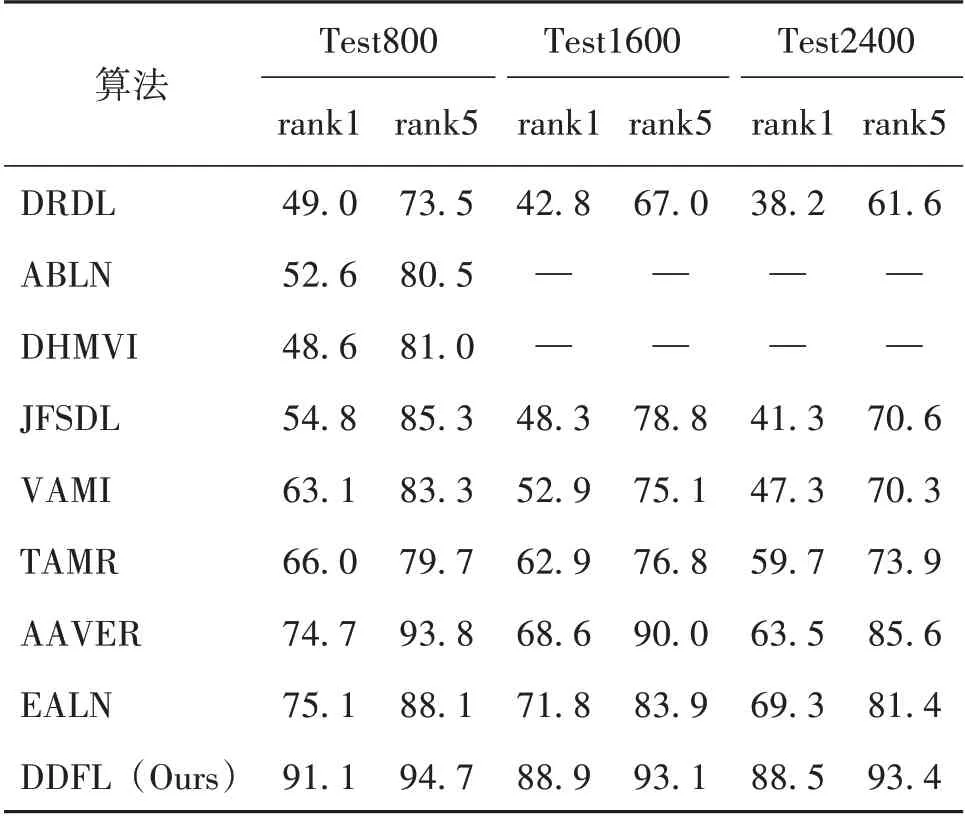
表5 算法在VehicleID数据集上的对比结果Table 5 Comparisons of our method with state-of-the-arts on VechileID dataset %
从表5-6 可以看出,在与其他算法的对比中,本研究所提出的算法模型在两个数据集中都可以取得最好的效果。在VehicleID 数据集中,相比于效果排在第二位的算法,本研究所提出的算法在Test800 测试集的rank1 和rank5 的准确率、分别提高16%和6.6%,在Test1600 和Test2400 两个测试集上的rank1 准确率分别提高17.1%和19.2%。在VeRi 数据集中,相比于效果排在第二位的算法,本研究所提出的算法的rank5 准确率和mAP 指标分别提高了1.6%和7.1%。
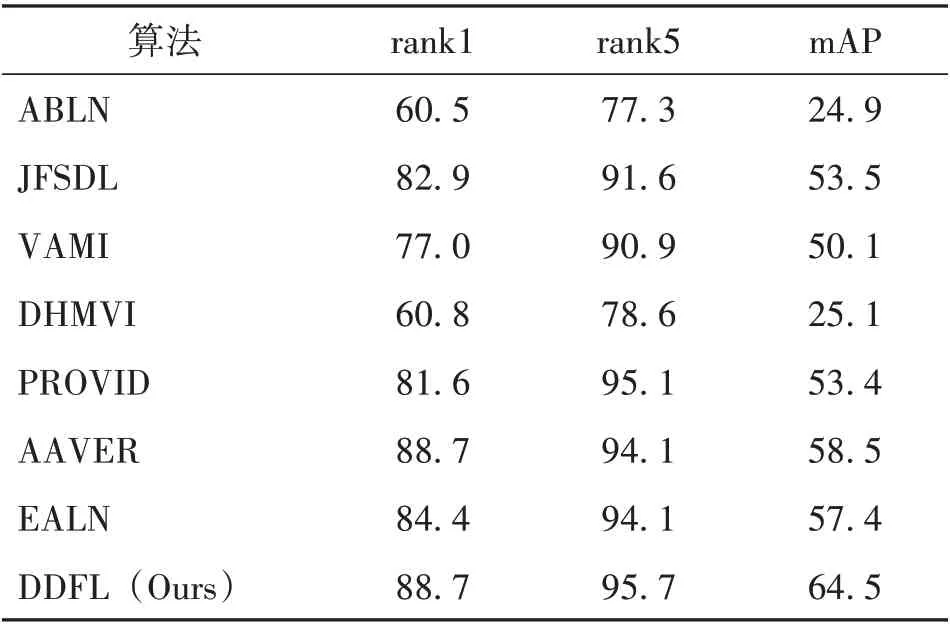
表6 算法在VeRi数据集上的对比结果Table 6 Comparisons of our method with state-of-the-arts on VeRi dataset %
3 结 论
本文设计了一个基于细节感知的判别特征学习模型。考虑深度网络可以根据表述的特征划分为浅层、中层和深层三类,其中中层特征对图片的局部区域特征进行表达,因此网络的中层特征会有利增强网络对于局部区域细节的辨识力。基于这一假设,模型以InceptionV3 网络为基础结构,设计了一个基于注意力机制的局部特征提取模块,结合局部限制及混合采样策略,指导局部特征提取生成。以提取的局部特征及基础网络生成的全局特征结合作为车辆的联合特征,通过计算车辆特征之间的绝对距离作为相似度度量。在公开数据集VehicleID 及VeRi 上的实验证明,所提的算法可以取得优于现有的车辆重识别算法的效果。
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2018年19期)2018-11-14 02:37:08
中国交通信息化(2018年5期)2018-08-21 03:37:40
小资CHIC!ELEGANCE(2018年17期)2018-06-15 01:29:02
自动化学报(2017年11期)2017-04-04 02:52:58
Coco薇(2015年5期)2016-03-29 22:40:10
噪声与振动控制(2015年4期)2015-01-01 07:08:21
oggi今日风采(2013年6期)2013-10-09 03:09:36
