
基于云计算和改进极限学习机的电网负荷预测
2021-09-09 05:21冯桂玲郑鹭洲蒋宏烨李思韬
科学技术与工程 2021年22期
冯桂玲, 郑鹭洲, 蒋宏烨, 李思韬
(国网福州供电公司, 福州 35009)
作为国家基础建设的核心支撑,电力系统在国民经济建设中发挥着极其重要的作用。近些年,随着云计算、大数据、5G等新型技术的广泛应用,智能电网精准管理与控制已成为国内外电力系统发展的主要方向之一[1-2]。在智能电网中,负荷预测精度对电力市场的电价配置、电能质量、安全运行至关重要[3],具有显著的经济效益。在特殊时期,可为电力检修、系统调度、降低发电成本以及提高电能质量提供重要指导。
随着电网信息化、智能化的飞速发展和电力需求因素的综合叠加,电力负荷数据规模一直在不断扩大。特别是随着智能电表的出现,实现了用户各类数据信息的实时上传,数据规模由GB级、TB级完成了向PB级的跨越,因此针对电力采集系统的优化完善机制应运而生[4],目前主流的智能电力数据采集平台采用分布式数据采集和存储,虽然在一定程度上提高了数据处理速度,但是面临海量数据下的电力负荷精准预测难题。
目前,电力负荷预测方法包括线性模型和非线性模型两大类。其中,在线性模型方法中,宏观指标方法利用电力弹性系数预测用电量;回归分析方法通过构建预测对象和关联因素(如地区生产总值、宏观经济状况、人口数量等)对应的模型方程,实现电力负荷估算[5];时间序列方法基于观测序列蕴含的随机特性,利用线性表达式拟合实际模型[6]。在非线性模型方法中,神经网络及其衍生方法通过自学习及自适应技术开展电力负荷影响因素深层次数据挖掘[7-8];模糊预测方法采用模糊理论来研究电力负荷变化趋势[9];支持向量机方法将训练数据集利用某一函数映射至高维线性特征空间,针对小样本数据量,取得较好的预测效果[10]。
近年来,电力负荷预测研究方向主要集中在基于机器学习的智能算法领域。张兰[11]利用量子粒子群算法优化Elman神经网络,建立量子粒子Elman预测模型,取得较好的预测结果。毛力等[12]针对传统模型存在过拟合问题,研究基于Hadoop平台的反向传播算法(BP)负荷预测方法,较好地解决了传统网络模型容易存在过拟合问题。徐龙秀等[13]对经典极限学习机预测算法进行优化改进,引入分布式思想[14]提升算法性能。孙海蓉等[15]研究了一种结合非线性递减权重平衡算法,实现电力负荷有效预测。吴润泽等[16]基于深度学习技术,通过提高算法的自适应感知能力获得比浅层网络更优的负荷预测结果。张新阳等[17]提出一种人工鱼群-反向传播(AFSA-BP)模型,采用人工鱼群算法(AFSA)对传统BP算法初始权值和阈值进行全局寻优以获得最优的网络参数。
然而上述方法的应用对象并非针对海量采集数据,无法满足智能电网电力云平台的计算需求。为了改善海量数据下的电力负荷预测效果,现在文献[18]基础上,提出一种结合云计算和改进极限学习机的电力负荷预测模型,对传统极限学习机使用添加扰动的粒子群优化算法进行改进,通过分布式计算进行精准建模和预测分析,并利用Hadoop平台对采集的用电负荷数据进行算法性能验证。实验结果表明,本研究方法相比文献[18]方法预测精度更高;相比传统泛化神经网络模型,运算速度更快,以期为海量数据环境下智能电网系统建设及管理运用提供一种新颖的解决思路。
1 云计算和Hadoop架构
云计算作为分布式计算的重要模式之一,首先将大型计算程序分解成若干个子程序,然后实施并行处理,最后将结果汇总后返给用户。
Hadoop是当前最流行的系统架构,由分布式文件系统(HDFS)和映射-归约(Map-Reduce)框架组成[19]。HDFS和Map-Reduce分别为海量数据提供存储及计算支撑,其主要功能模块为Map和Reduce,网络架构实现是指定一个Map函数,把一组键值对映射成一组新的键值对,然后通过Reduce函数进行并行处理。
Map-Reduce运行流程如图1所示,其中n为任务分片数,m为任务规约数,包括如下5部分内容。

图1 Map-Reduce运行流程
(1)输入(Input):读取分布式文件系统中输入的数据,对数据进行切割形成若干数据片,Map函数与数据片一一对应。
(2)分配(Map):把不同的数据片作为不同的键值对,按照Map函数设定的逻辑关系,对分配好的键值对进行处理,形成全新的中间键值对。
(3)转换(Shuffle):将中间键值节点由Map转至Reduce,并实施排序操作,合并所有等同的键值。
(4)规约(Reduce):规约形成结果。
(5)输出(Output):输出Reduce函数的处理结果,存储在分布式文件系统。
2 粒子群算法优化的极限学习机
2.1 极限学习机
极限学习机(extreme learning machine, ELM)是一种高效的单隐层前馈神经网络计算模型[20],利用最小二乘法求解输出层权值矩阵,输出全局最优解。
图2为单隐层前馈神经网络(single-hidden layer feedforward neural networks, SLFNs),是ELM的基本构成单元。其优势是隐含层和输出层之间的权值β只需解线性方程组进行反演,计算步骤如图2所示。
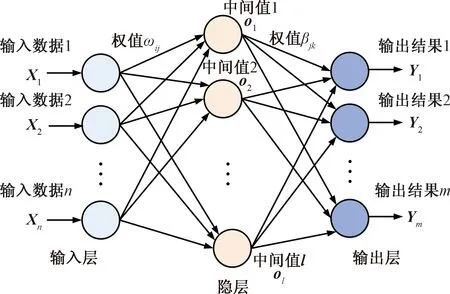
图2 SLFNs网络结构组成
输入数据格式记为(Xi,ti),其中:
(1)
式(1)中:RN为N×1向量空间;RM为M×1向量空间。
包含L个隐层节点的SLFNs模型满足如下关系式:
(2)
式(3)中:βi为输出权重;bi为偏置参数;Wi·Xj为矢量内积;g(x)为激活函数;oj为隐层输出结果;输入权重Wi为
Wi={wi,1,wi,2,…,wi,n}T
(3)
SLFNs的优化目标是使得输出误差最小,即
(4)
式(4)中:tj为观测值。
即存在βi、Wi和bi,使得
(5)
采用下述矩阵形式重新改写式(5),即
Hβ=T
(6)
式(6)中:β为输出权重;H是输出矩阵;T为输出期望值。经分析整理,进一步得出:
H(W1,…,WL,b1,…,bL,X1,…,XL)=
(7)
(8)
(9)
式(9)中:i=1,2,…,L。i=1,2,…,L。其等价于求解:
(10)
式(10)中:E为均方误差。
根据权重Wi和偏置bi的初始值(可随机选取),确定隐层输出矩阵H,单隐层神经网络训练过程等价于为求解线性方程Hβ=T,于是输出权重为
(11)
式(11)中:H†为H的广义逆矩阵。ELM虽然避免了传统基于梯度的机器学习算法面临的许多问题,诸如局部最小值等,但是由于随机选择输入权重和偏置,需要设置较多数目的隐层神经元,容易造成ELM特征空间呈现不可预测的非线性分布,从而导致模型泛化性能严重下降[21]。因此,提出一种改进粒子优化算法,引入至ELM模型参数寻优过程,同时结合云计算技术,可以较大幅度提升网络模型泛化能力和计算效率。
2.2 粒子群算法
粒子群优化(particle swarm optimization, PSO)算法[22]的核心思想为:种群中的粒子通过计算适应度,在迭代过程中进行自身速度和位置的动态调整,利用迭代方式逼近问题的最优解。
粒子i在N维空间位置为Xi=(X1,X2,…,XN),运动速度表示为Vi=(v1,v2,…,vN)。每个粒子由3个重要参数来刻画,即暂时的最优位置(pBest)、现在位置Xi、适应值(fitness value)。整个群体中所有粒子发现的最好位置记为gBest。
通过式(12)和式(13)更新粒子的速度及位置:
vi=ωvi+c1rand()(pBesti-xi)+
c2rand()(gBesti-xi)
(12)
xi=xi+vi
(13)
式中:xi为粒子位置;vi为粒子速度;rand()为产生0~1之间的随机数的函数;c1和c2为学习因子,通常设为2;ω为惯性因子,通过调节ω可以调整全局/局部寻优能力。ω可通过式(14)获得:
(14)
式(14)中:Gk为最大迭代次数;ωini为初始值;ωend为迭代至最大进化代数时的权值。根据经验,通常ωini取0.9,ωend取0.4。
与文献[23]类似,引入收敛因子α,位置计算公式如式(15)所示:
vi=α[vi+φ1rand()(pBesti-xi)+
φ2rand()(gBesti-xi)]
(15)
与之对应,收敛因子α的更新步骤为
(16)
式(16)中:φ满足条件φ>4,通常取值4.1,因此收敛因子α为0.729。
根据式(12)~式(16),通过调节粒子数量和粒子速度,进而动态调整粒子搜索空间和局部寻优能力。
3 基于改进极限学习机的预测模型
受文献[18]启发,将改进极限学习机算法与云计算技术进行有机结合,并利用Hadoop平台进行部署,充分发挥神经网络优秀的泛化能力和群智能算法的快速收敛能力、全局寻优能力,并借助云计算平台高效的计算水平,对改进传统电力负荷预测算法性能具有重要现实意义。
3.1 改进粒子群的优化算法
为进一步提升算法性能,对传统粒子群优化算法(PSO)进行优化改进,提出一种添加扰动的PSO算法(BPSO),可以有效避免传统PSO算法容易取得局部最优解的问题。
下面给出全局极值pg与个体极值p0的更新方法:
pBesti=k0pBesti
(17)
gBesti=kggBesti
(18)
其中,
(19)
(20)
式中:t0和tg为单个粒子的历史极值pBesti和全局极值gBesti保持连续的迭代次数;T0和Tg分别为个体和全局历史极值搜索停止阈值。
3.2 融合优化粒子群的极限学习机
在BPSO开始阶段,随机产生[-1,1]初始解,其目的是引入ELM模型的输入权重和隐层节点偏置,编码如下:
θ=(ω11,ω12,…,ω1L,ω21,ω22,…,ω2L,…,ωn1,ωn2,…,ωnL,b1,b2,…,bL)
(21)
式(21)中:L为隐层节点个数;N为输入层节点个数。另外,采用基于均方根误差(root mean square error, RMSE)的KRMSE指标[23]来提取适应度,定义如下:
(22)
式(22)中:xobs,i为估计值;xreal,i为真实值。
3.3 基于Hadoop框架的算法流程实现
随着海量负荷采集数据的涌现,传统基于极限学习机预测方法存在耗时长、效率低,计算精度下降等诸多问题,无法满足智能电网快速增长的各项业务需求。本研究提出的结合云计算与改进粒子群的极限学习机,不仅能够提升海量样本数据训练及处理效率,提高算法实时处理能力,还具有更优的电力负荷预测精度。所提算法的处理流程如图3所示,对应的计算步骤如下。
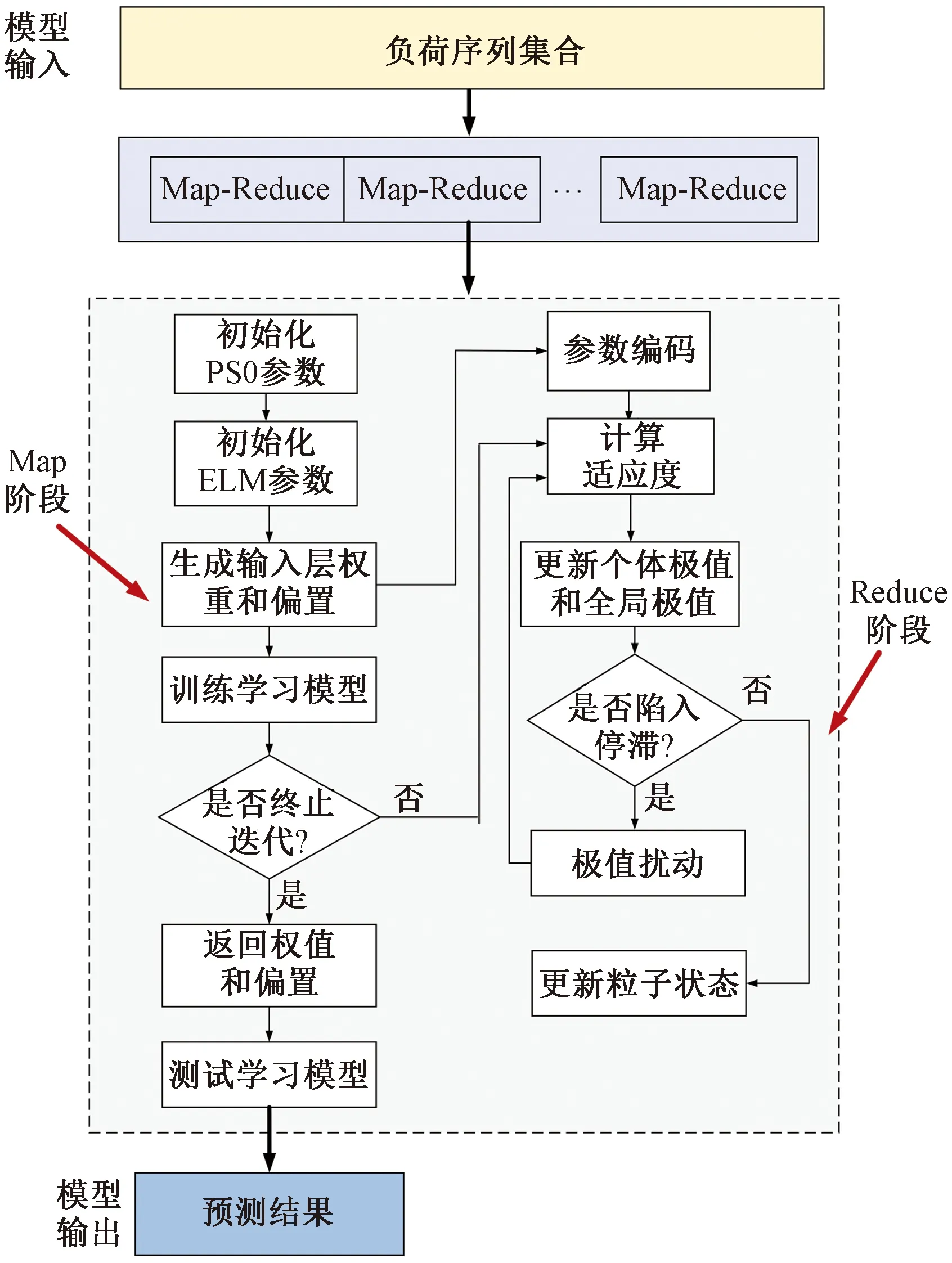
图3 本文模型处理流程
步骤1 将海量电力数据训练集输入至Hadoop平台系统,利用Map-Reduce框架进行分割得出训练子集,并构建相应的并行Map函数。
步骤2 按照Map函数的计算步骤(图2)训练各子集数据。
步骤3 所有Map阶段处理结果传递到Reduce进程后,通过取平均值的方法获得输入权重和隐层偏置。
结合云计算中的Map-Reduce框架,对改进粒子群优化的极限学习机实施并行处理,因而能够取得较优的电网负荷预测结果。
4 实验与分析
下面利用实测数据验证海量采集下本文模型的有效性。依托分布式电力采集平台(如智能电表、集中器等)实时采集终端用户用电数据,推送至中间物联网平台,然后经过流计算进行数据清洗,推送至大数据云平台。云计算处理基于Hadoop平台,总节点数为4个(可根据需要进行扩展),每个节点配置8核2.5 GHz主频CPU、16 GB内存主机,Hadoop版本为2.0,网络带宽为1 000 Mbit/s。在Hadoop平台上,将待处理数据进行整合并分块存储至各数据节点,客户端通过主节点连接其他数据节点进行并行运算,最后输出整合后的运算结果,如图4所示,其中JobTracker为作业跟踪器,负责任务的整个执行过程,TaskTracker为从节点上的任务追踪器。

图4 电力云平台计算架构
算例数据集选自福建省某地区电力系统采集的2017—2019 年负荷数据和对应的气温、湿度、降雨量、空气质量指数等关联数据,为分析不同算法的优缺点提供参考基础。实验数据集描述如表1所示。

表1 实验数据集说明
4.1 评价指标
为评估不同算法性能,选用均方根误差(RMSE)和归一化均方误差(normalized mean square error, NMSE)指标[12]来衡量不同算法的电力负荷预测效果,定义如下:
(23)
(24)
4.2 数据预处理
利用本文模型正式训练之前,需要对原始数据进行清洗操作。其中,对于异常数据,采用文献[12]提出的数据平滑技术进行消除。另外,对不同类型的数据(如每日气温)实施归一化处理。
4.3 实验验证
示例一:区域负荷预测效果对比。将前26 000个负荷数据作为模型输入,利用后30个负荷数据作为测试集进行算法性能测试。表2展示了不同算法的实验结果对比。容易看出,传统极限学习机算法(ELM)的预测效果最差,这是因为该模型出现了过拟合现象。相比文献[18]方法,本文方法在其研究基础上,由于采用了改进粒子群优化算法动态调整ELM网络模型参数,因而获得了最低的预测误差。
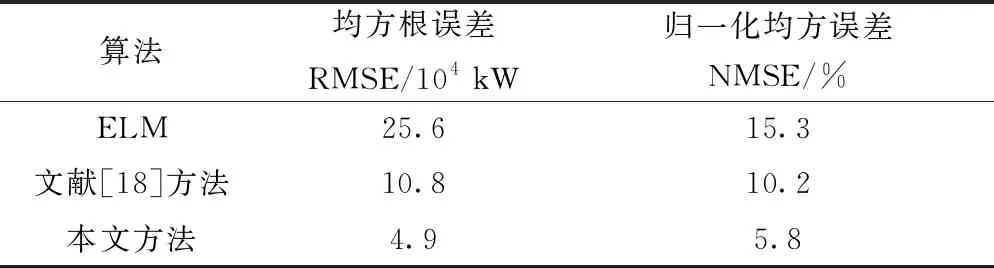
表2 不同算法的实验结果比对
图5为采用不同计算方法获得的电力负荷预测结果对比,可以看出本文方法相比文献[18]方法更加接近真实值,误差波动小、鲁棒性强,特别是当数据存在波动、拐点较多时,具有更好的自适应性。

图5 不同方法区域负荷预测效果对比
示例二:台区超载、过载预测效果对比。精准的台区电力负荷预测,一方面可以保证用电安全,为运检部门对超载、过载小区及时实施用电调整,另一方面大大节省了人力排查成本,提高了电力部门用电管理效率。图6展示了国庆节期间,采用不同模型对台区过载、超载现象的预测结果对比。容易看出,本文方法的预测精度最高,准确预测台区比例超过80%。
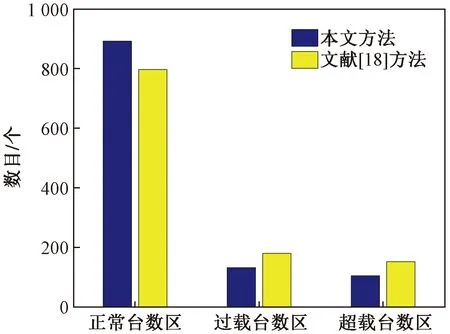
图6 国庆节期间台区超载过载预测效果对比
示例三:不同算法并行性能验证分析。下面对不同方法的并行计算性能进行对比分析。与文献[12]类似,首先将原始数据集进行扩充处理,分别增至500倍和1 000倍,然后计算“加速比”(即单机算法运行时间与云集群算法运行时间之比)指标,如图7所示。可以看出,两种方法的效果基本一致,随着数据集的不断增大,加速比趋于线性增加模式。
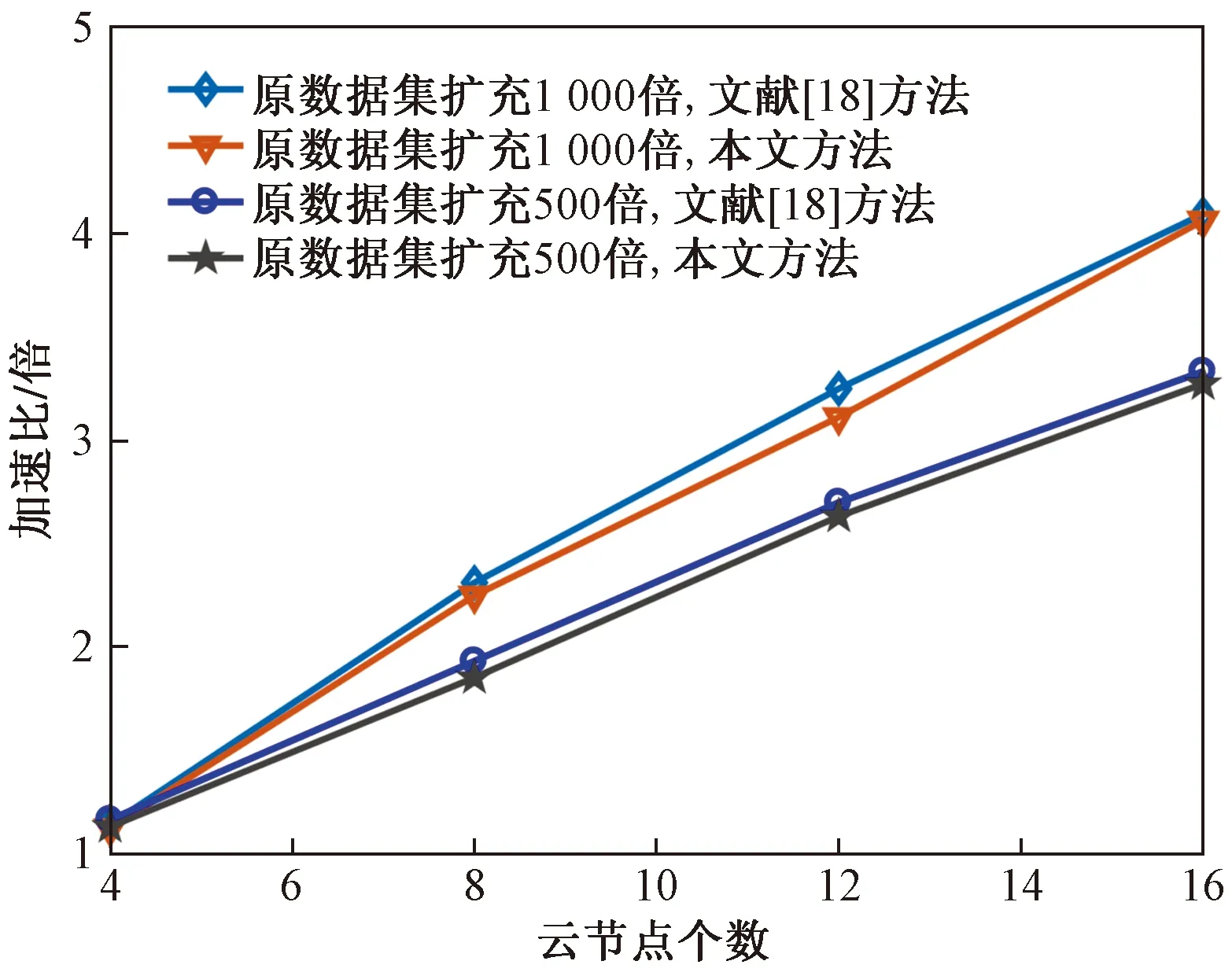
图7 不同算法并行计算性能对比分析
综上分析,本文方法由于整合了云计算模型,相比传统ELM算法,处理海量电力负荷数据的优越性是显然的,特别是样本量持续增加时,计算效能更优。另外,与文献[18]方法相比,本文方法由于对ELM模型使用改进粒子群算法在模型参数更新方式上进行了优化改进,因而在加速比指标接近的前提下,能够取得更为精准的预测结果。
5 结论
提出了一种基于Hadoop平台改进极限学习机的电力负荷预测模型,可用于海量采集数据背景下的电力负荷预测问题,并基于实测数据进行了性能分析验证。主要得出如下结论。
(1)传统基于机器学习的电力负荷预测方法,无法有效满足海量数据采集下的电力云平台计算需求,因此需要对相关算法进行优化改进。
(2)所提方法在预测精度、运算效率等指标上,相比已有方法具有更高的性能优势,且具有良好的加速和扩展能力,可为今后智能电网的广泛应用提供一种可行的技术途径。
(3)后续将重点在多种预测方法有效结合、算法并行化优化以及海量数据分布式计算等方面开展研究工作,以进一步提高处理海量电力负荷数据的能力。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
昆明医科大学学报(2022年1期)2022-02-28
文萃报·周五版(2021年30期)2021-09-05
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
当代陕西(2019年14期)2019-08-26
消费导刊(2018年10期)2018-08-20
北京航空航天大学学报(2017年6期)2017-11-23
中学数学杂志(初中版)(2016年5期)2016-11-01
