
基于EL-YOLO的虹膜图像人眼定位及分类算法
2021-09-07 00:48:36陈金鑫沈文忠
计算机工程与应用 2021年17期
陈金鑫,沈文忠
上海电力大学 电子与信息工程学院,上海201306
虹膜相较于指纹、面部等生理特征,具备着先天的与外在隔离的优势,有着极高的稳定性。与常见的指纹、面部相比有着更好的唯一性,防欺骗性与防伪性很好,有着广泛的应用前景[1-2]。但是虹膜认证设备采集的图片一般包含上半个面部,以及一些背景干扰等,如何精确高效地从整幅图片中定位出人眼的位置,是虹膜识别设备处理获取虹膜图像的首要步骤。
传统的人眼定位算法大致可以分为基于人眼的固有特征、基于外观的统计模型以及基于结构信息进行人眼定位等。滕童等[3]提出了基于级联神经网络的多任务虹膜快速定位方法。该算法引入级联神经网络提取虹膜图像特征,将虹膜定位分解成从粗定位到精确定位的步骤,该算法并非是端到端的边框回归,检测速度较慢,而且仅是对于虹膜局部图像的检测且缺少眼睛类别,图像检索范围较小,干扰因素不多。晁静静等[4]提出了基于方向梯度直方图(HOG)和支持向量机(SVM)的人眼定位算法。该方法依赖于人眼的灰度梯度变化,在人脸面部图像较大时,由于鼻孔部位的灰度梯度值同样变化较大,因而出现了误检的情形。同样在应对光照变化较大,图像质量较低以及戴眼镜等情形下,准确定位人眼的性能急剧下降。主动外观(ASM)是一种经典的用于描述空间结构的模型,Ishikawa等[5]提出了基于主动外观模型的人眼定位算法。但该模型是描述整个面部结构,当面部区域信息过少,或者头部转动角度过大,将难以定位出眼睛的位置。
随着卷积神经网络在图像识别与检测领域取得的重大进展,针对传统人眼定位算法的缺陷引入YOLOV3-tiny[6]目标检测算法,结合轻量化网络MobileNetV3[7]提出了EL-YOLO网络。在中科院自动化研究所公开的CASIA-IrisV4、MIR2016以及本实验室获取的虹膜图像数据集上取得了不错的效果。对于光照变化,以及头发遮挡,图像质量较差的情形都有着优秀的定位效果。
本文的工作有如下内容:
(1)标注了已有的开源虹膜数据集和本实验室采集获取的虹膜数据集,对标记的左右眼进行区分,在做目标检测的同时进行左右眼分类,且对眼睛的具体位置做出合理的定义,使得训练loss收敛合理。
(2)修改YOLO算法的损失函数,结合广义交并比[8](GIoU)对传统的均方误差(MSE)边框定位损失函数进行修改,以及对定位置信损失的修改,以此加快训练损失收敛。
(3)将YOLOV3-tiny与MobileNetV3相整合,提出EL-YOLO网络,降低了YOLOV3-tiny的参数量与计算量,将已有的YOLOV3模型降低到0.5 MB左右,使得模型能够移植到嵌入式边缘设备上运行。
1 算法基础
1.1 特征图信息表示
YOLOV3-tiny是一种单阶段目标检测网络,与RCNN、Fast R-CNN、Faster R-CNN、MTCNN[9-12]等两阶段目标检测网络相比,存在着目标检测速度快的优点。
正因为其是单阶段目标检测网络,其目标定位在神经网络的末端的特征图就可以表示。网络经过一系列卷积层的特征提取,在最终输出时分成两个分支,特征图面积越小,单位面积上的语义信息越丰富。网络输出结构如图1所示。
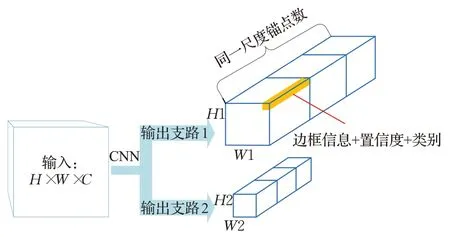
图1 YOLOV3-tiny网络输出结构Fig.1 Output structure of YOLOV3-tiny network
在图1中分支1是预测较小的检测目标,分支2是预测较大的检测目标,因为下采样操作,分支1输出特征图的边长是分支2的2倍。在任意分支中,每一格点由4个边框信息,1个置信度信息以及N类类别信息组成,由于预设k个接近定位目标尺寸的锚点可以加快网络定位速度,因此单个尺度的目标表示信息有k组。
在最终训练后得到的特征图上,每一个格点都会反映此区域是否有检测目标。训练时,对于目标所在区域的格点而言,边框、置信度、类别信息都是可以训练的;对于无关的背景格点,仅训练置信度一个信息即可,因为单个目标中点的唯一性,所以其他位置的边框会框进无关信息,降低了目标的置信度,仅通过置信度就可以排除背景格点。但是实际测试时仅用置信度来筛选目标会导致接近目标中心的格点无法被滤除,因为其靠近目标中心,置信度有可能超过置信阈值,所以在测试时引入了非极大值抑制(NMS)算法,选取最大置信概率的定位目标。
1.2 深度可分离卷积
MobileNet[13]作为高性能的轻量级网络,其参数量极大减少,主要依赖的就是深度可分离卷积。普通的卷积操作是将一个多通道的图像经过一个多通道的卷积核变成单层特征图像,输出的多通道体现在卷积核的不同。深度可分离卷积分为两步:深度卷积(Depthwise Convolution)与点卷积(Pointwise Convolution)。深度卷积即对输入每个通道进行平面卷积,获得与输入图像通道数相同的特征图像。点卷积是进行1×1的立体卷积操作,选取N组1×1的立体卷积就会获得N通道的输出特征图。其卷积步骤如图2所示。
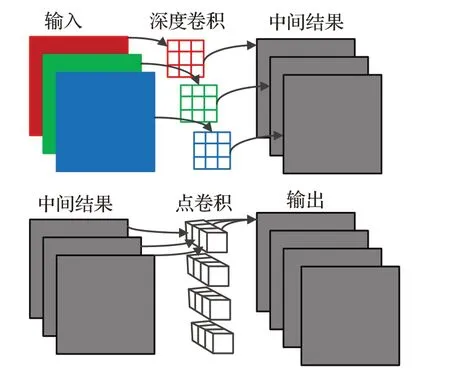
图2 深度可分离卷积Fig.2 Depthwise convolution
假设在神经网络中,输入通道为M,输出通道数为N,使用的卷积核尺寸为S。那么普通卷积的训练参数量为(M×S×S+1)×N,深度可分离卷积的训练参数量为M×S×S+(M+1)×N,相较于普通卷积减少参数量为M×S×S×(N-1)-M×N。
1.3 锚点框
YOLO网络的每一层锚点框的数目是人为设定的,其中每个锚点的大小是按照具体训练的数据集进行K-means[14]聚类获得,其算法流程如图3所示。
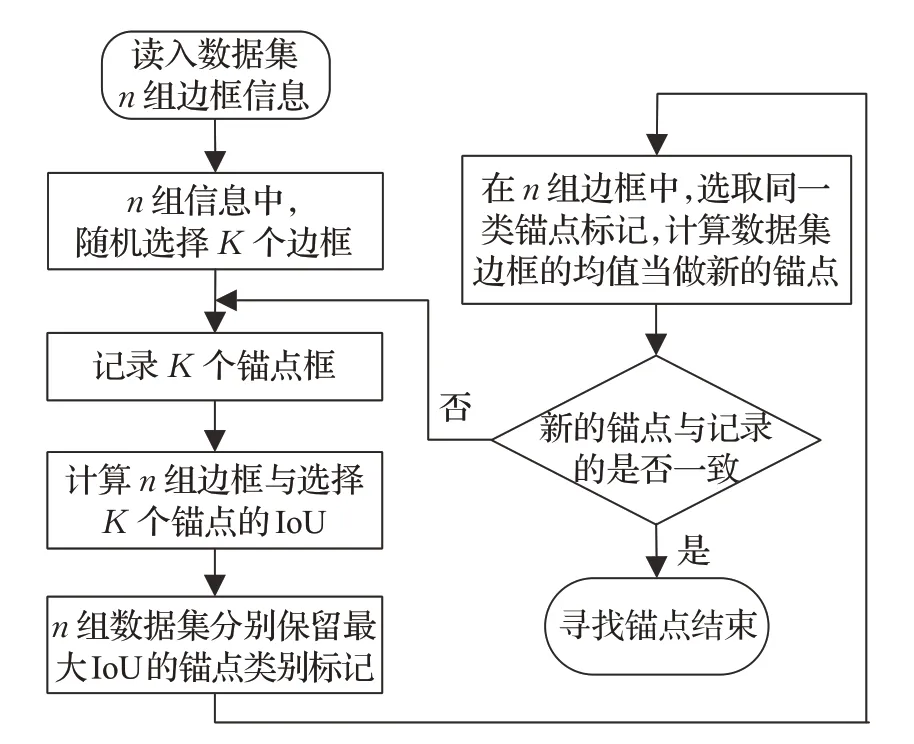
图3 锚点框聚类流程图Fig.3 Anchor box clustering flowchart
锚点框当作超参数用于网络训练,可以加快网络对于定位目标的查找。定位目标的边框实际信息需要对特征网络预测的信息进行解码,边界框如图4所示,其中虚线框是预设锚点框,以( )cx,cy为矩形框中心坐标,Pw和Ph分别为预设锚点框的宽与高,实线框是实际目标的边框,( )tx,ty是实际边框相对于锚点框的偏移,在YOLO网络实际输出中偏移量范围为( -∞,+∞),而最终的输出层每一格范围为[0,1),所以要经过sigmoid函数归一化,优点是可以加快网络训练的收敛,同理以e为底数的边框边长也是如此。
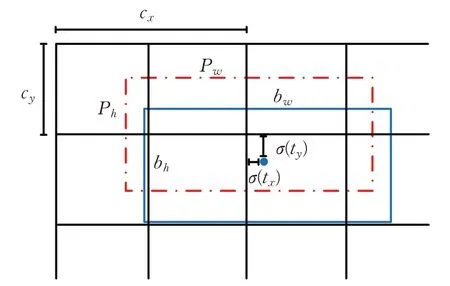
图4 边界框示意图Fig.4 Diagram of boundary box
定位目标的实际边框信息表达为:

式中,σ是sigmoid函数,(tw,th)是实际目标边框相对于预设锚点的宽高缩放比例。
2 EL-YOLO模型
由于YOLOV3-tiny网络模型的主干网络使用大量的卷积层,所以YOLOV3-tiny的模型大小达到33.8 MB。原YOLOV3-tiny网络用于80类别物体的识别定位;而且原模型输入图像为彩色图像,背景复杂多变需要较大的网络模型去提取特征,针对虹膜图像单一类别的目标而言,且输入图像为灰度图像,具有一定的可行性,可以设计轻量快速的模型完成定位及分类任务。
2.1 人眼定位及分类模型设计
在主干网络中使用MobileNetV3 block构成特征提取网络。单个MobileNetV3网络块由点卷积通道膨胀、深度卷积、点卷积通道压缩、SENet块、逆残差结构这些主要部分构成。单个MobileNetV3块如图5所示。
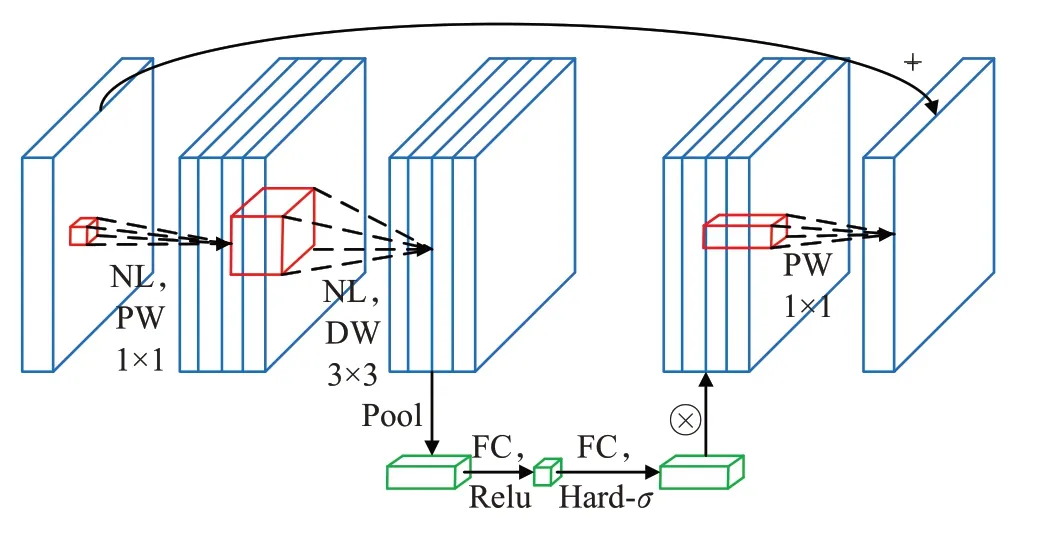
图5 MobileNetV3块Fig.5 MobileNetV3 block
其中,PW与DW分别代表深度卷积与点卷积,NL代表非线性激活函数,本文中主要用到三种激活函数h-swish、h-sigmoid以及ReLU。h-swish激活函数相对于swish[15]函数计算更快,其表达式为:
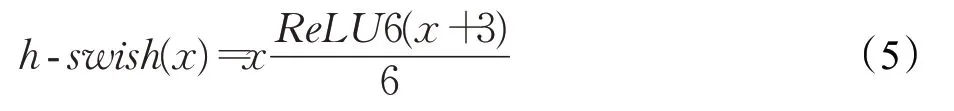
EL-YOLO网络的整体结构如图6所示,其中实线框内为主干特征提取网络,具体内容见表1。网络末端两个分支输出的通道数都为7,其中前1~4通道表征人眼边框信息,第5通道表征定位人眼的置信度和第6、7通道表征定位的左右眼分类。网络末端采用普通卷积操作,其中在中尺度目标定位24×18分支处,上采样操作之后并非如YOLO一样采用通道连接的策略,而是选择直接相加,可以减少网络参数并且提高运算速率。
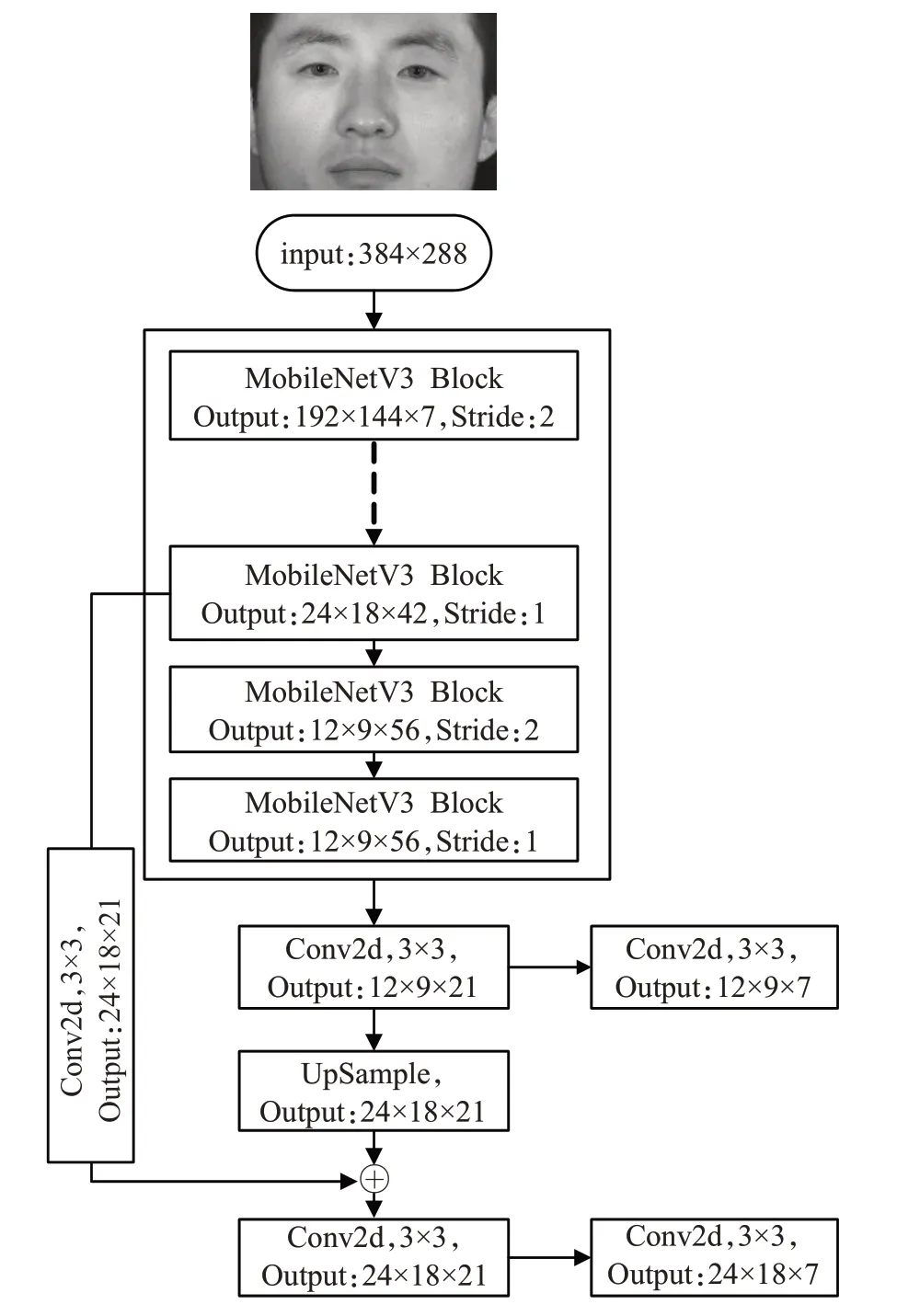
图6 EL-YOLO网络整体结构图Fig.6 Overall structure diagram of EL-YOLO network
人眼定位的特征提取网络结构如表1所示。
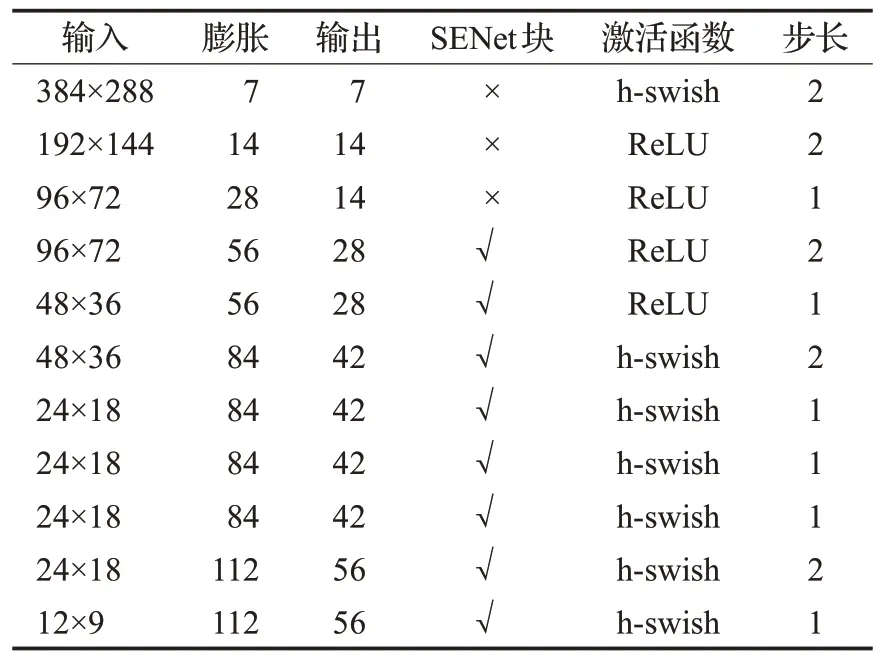
表1 特征提取网络结构Table 1 Network structure of feature extraction
表1中每一层都引入MobileNetV3 block的结构,且卷积核尺寸都是3×3大小。表1中的膨胀与输出指的是网络卷积层通道数,网络的下采样不采用池化操作,通过卷积运算的步长调整来实现。
2.2 损失函数设计
整体的网络训练损失由边框交并比(IoU)损失、置信度损失以及类别损失构成。在此IoU损失引入广义交并比(GIoU),这个相较于传统的IoU可以反映出预测框和标签框在没有交集时的远近,即在IoU为0时,GIoU不为0,训练梯度不为0,依然可以进行反向传播,训练网络。GIoU的表达式为:
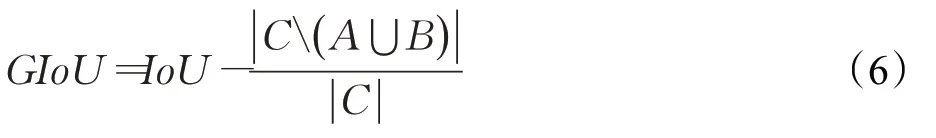
此处C是包含A与B的最小框,C( )A⋃B表示C排除掉A与B的交集。LossGIoU的计算公式为:
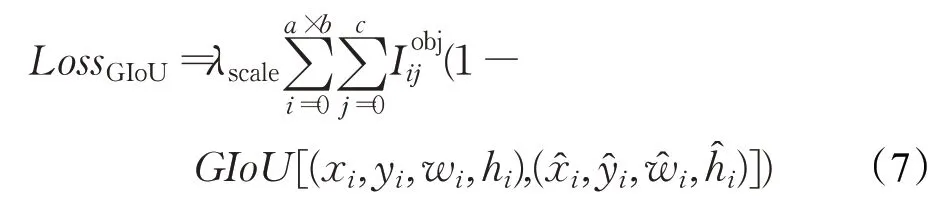
式中,λscale是表示预测目标大小的权重,越小的检测目标系数权重越大。a×b表示预测特征图的尺寸,c表示每个尺寸的锚点数,代表特征图此处有检测目标。GIoU的详细计算方法如公式(6)所示,本处是计算预测值边框信息(xi,yi,wi,hi)与实际边框信息之间的广义交并比,相较于YOLO算法采用的均方误差(MSE)更能反映预测检测框的检测效果的好坏。
左右眼类别损失与边框损失相似,仅仅考虑在有目标时候的损失情况,LossCls的计算公式为:
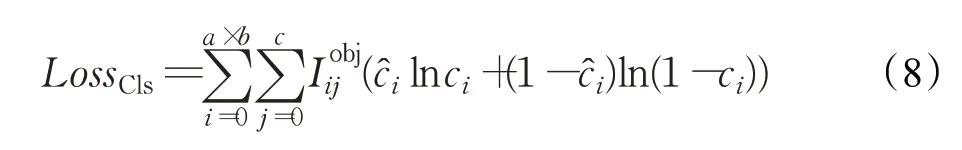
式中,ci代表目标类别预测值,ci代表目标类别标签值。
置信损失不仅需要考虑有目标时的置信损失,也需要考虑无检测目标的置信损失,因为这是确定目标位置的首要信息。LossConf的计算公式为:
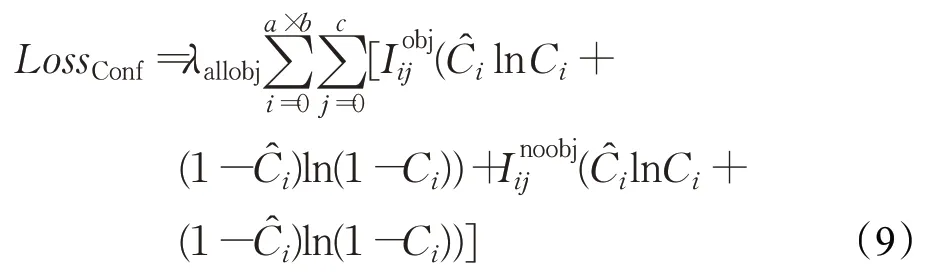
式中,λallobj是预测的所有格点的系数,即该格点处是否有目标都要乘以该系数。λallobj系数后的因子为交叉熵损失。λallobj的计算公式如下:

λallobj是衡量预测整体结构与标签之间的距离情况,本文中 ∂=1,γ=2,即用L2距离。上述公式(7)、(8)、(9)中:代表特征图此处有检测目标,反之代表没有,Ci代表置信度预测值,代表置信度标签值。
3 实验评估
本实验的数据集由中科院自动化研究所公开的CASIA-IrisV4、MIR2016和本实验室采集的虹膜数据集构成,选取CASIA-IrisV4-Distance与MIR2016库中分别为2 567与4 499张含有双眼的虹膜图像,抽取CASIAIrisV4库中和本实验室采集的单眼图像SEPAD_V1共计2110张,训练与测试集数目具体划分见表2。

表2 数据集构成Table 2 Dataset composition
3.1 数据集
无论是公开数据集还是实验室自采集数据集SEPAD_V1、SEPAD_V2都没有眼睛区域的精确标注和分类标注,本文眼睛标注的边框有如下要求,边框的左右边界要包含内外眼角,边框的上下边界至少要包含眼睑边界,使用Imglab标注工具对数据集进行标注,如图7所示。
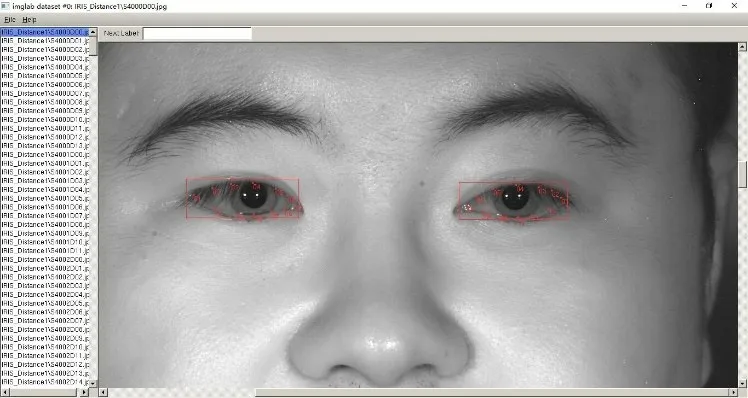
图7 标注软件:ImglabFig.7 Labeling software:Imglab
图8选自CASIA-IrisV4数据库,图片编号为S4000D00,展示该图像局部细节,可以发现数据集标注的信息包含眼睛位置与关键点位置。在实际网络训练中,由于人为标注边框的大小不统一,所以使用标注的眼睛局部关键点所占据的范围当作实际边框。
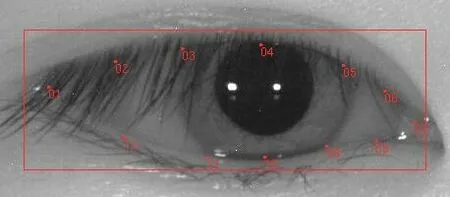
图8 眼睛标注细节信息Fig.8 Eye label details
3.2 训练部署与评价指标
实验使用的工作站及运行环境配置如表3所示。

表3 工作站及运行环境配置Table 3 Workstation and operating environment configuration
EL-YOLO网络的训练策略设置如表4所示。
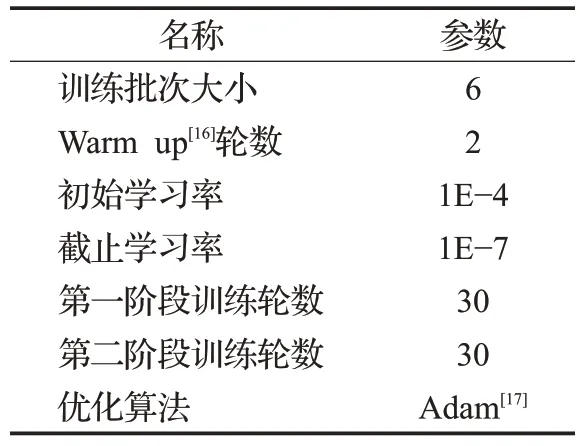
表4 训练策略设置Table 4 Training strategy settings
利用K-means聚类算法对虹膜图像数据集中眼睛的边框大小进行聚类,分别归一化到12×9和24×18的图像大小,聚类结果分别为(6.906 25×2.781 25)与(3.437 5×1.312 5)。将聚类结果写入配置文件以便ELYOLO网络带入训练。
眼睛定位的精确率(Precision)与召回率(Recall)公式如下:

式中,TP(True Positive)表示预测与标签一致,通常预测与标签的IoU达到0.5即可认为是TP[9]。FP(False Positive)表示把负例预测为正例,FN(False Negative)表示正例预测为负例。
3.3 结果分析
3.3.1 数据集测试及网络收敛表现
经过在CASIA-IrisV4、MIR2016和本实验室采集的虹膜数据集上训练后,不同数据集测试集部分的定位表现以及分类准确性[18]如表5所示。
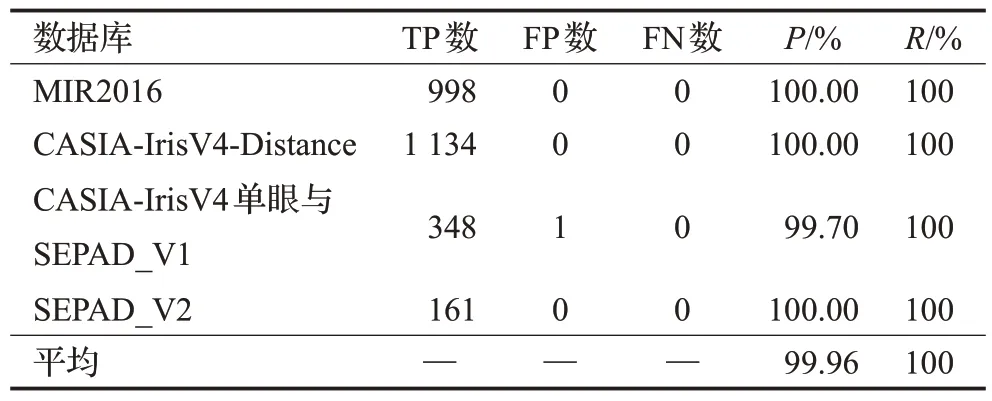
表5 不同数据集测试表现Table 5 Test performance on different datasets
在默认的IoU阈值为0.5时[9],平均定位准确率达到99.96%,在标签与预测边框同等尺寸下,交集已经占据了标签框面积的66.67%,重叠已经较多。更进一步衡量在不同IoU阈值下EL-YOLO网络模型的表现,其定位准确率如表6所示。

表6 不同IoU下平均定位准确率Table 6 Average positioning accuracy under different IoU
测试集中一些图片的眼睛定位及分类置信率结果如图9所示。
图9(a)与(b)是同一对象的双眼虹膜图像,图9(a)是对象的左眼处于半睁开状态,图9(b)是其带眼镜进行干扰拍摄的图像,可以发现EL-YOLO网络可以克服眨眼和眼镜带来的干扰。图9(c)与(d)是同一对象在不同光照条件下拍摄的双眼虹膜图像,在其具体定位效果以及置信率来看,EL-YOLO网络可以有效克服光照带来的影响。图9(e)与图9(f)是同一用户的左右眼单眼图像,可以发现分类置信率依然很高,可知EL-YOLO网络具有很强的定位和分类能力,而不是依赖双眼图像的眼睛相对空间位置关系给出的简易判定,这也是在训练网络时引入单眼数据集的原因。图9(g)是上述测试中唯一的一例错把右眼当成左眼的情况,从图中可以发现有较大反射光斑以及眼镜镜框干扰,但是其分类置信率较低,说明网络对这幅图像的判别不是过于肯定。

图9 EL-YOLO网络测试效果(左右眼类别:置信度)Fig.9 EL-YOLO network test results(left and right eye classification:confidence)
EL-YOLO网络在目标回归训练时引入了广义交并比(GIoU),通过一个训练批次后的测试损失,比较了网络引入GIoU和常规交并比(IoU)在前10个批次的网络收敛情况。二者的网络收敛情况如图10所示,可以发现本网络收敛都很快,但是在第2到5批次训练时,引入GIoU损失函数的网络收敛更为迅速,且最终的网络整体损失略低。
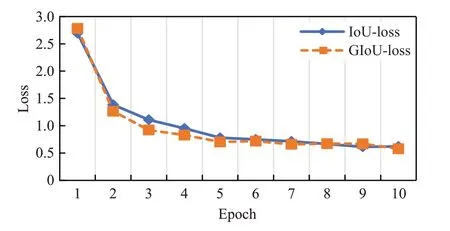
图10 不同交并比的网络收敛情况Fig.10 Convergence of networks with different intersection-over-union
3.3.2 负样本抗干扰测试
在实际使用中,虹膜认证设备在没有用户使用或者画面中未出现虹膜图像时并不需要进行采集无关图像进行后续的匹配认证。实验采集了704幅不含眼睛的负样本,这些负样本实际使用中可能出现的干扰物体,有些图像接近眼睛的大致形状来予以干扰,以此来检测网络的健壮性。部分负样本如图11所示。

图11 负样本示例Fig.11 Negative sample
将负样本图像放入EL-YOLO网络进行测试,测试的结果与正样本出现频次进行统计,结果如图12所示。图12中的横轴代表置信率分布区间,纵轴代表在该区间出现的频次。从图12可以发现,当EL-YOLO的置信度设置在0.9以上可以排除绝大部分干扰,体现了EL-YOLO网络的实用性与稳健性。
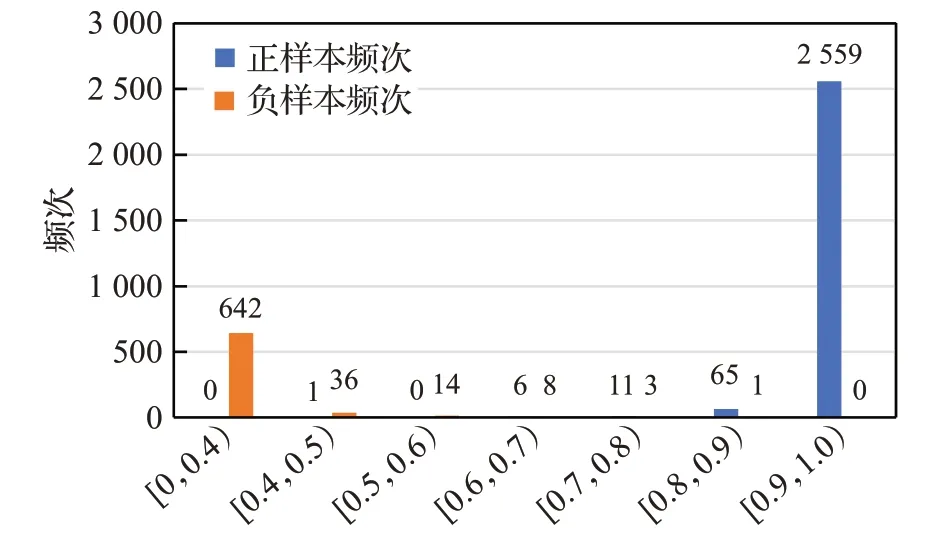
图12 正负样本出现频次统计Fig.12 Statistics of frequency of positive and negative samples
3.3.3 算法对比
EL-YOLO网络模型的浮点运算次数(FLOPs)为1.17亿,参数量119 945个,即模型469 000大小。在前述的工作站配置下处理2 560×960分辨率的图片,检测速率可达34帧/s,可以满足实时应用的需求。相较于YOLOV3-tiny[6]的55.6亿的浮点运算次数,EL-YOLO是低算力消耗的模型,拥有在嵌入式边缘设备运行的能力。
EL-YOLO网络以及其他眼睛定位算法的准确率如表7所示,可以发现本文算法在能够区分左右眼的同时定位准确率依然很高。其中级联神经网络[3]的算法与基于HOG和SVM[4]的算法都没有对左右眼进行分类。虽然基于HOG和SVM的算法准确率较高,但它并不是端到端的方法,准确率是通过多种策略组合处理获得的结果,计算量大,复杂度高。如果在不考虑分类正确的情况下本文算法的定位准确率将会更高。YOLOV3-tiny[6]由于网络参数较多,应对复杂场景的处理能力更强,但是在边缘设备上使用代价过大。
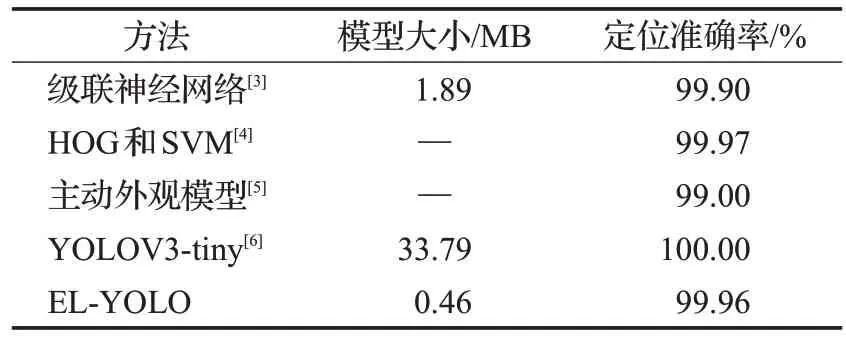
表7 不同方法的定位准确率Table 7 Positioning accuracy of different methods
4 结束语
针对在虹膜图像中的人眼位置确定以及左右眼区分问题,本文提出了EL-YOLO模型来解决上述问题。将轻量级网络引入模型,将模型减小到0.5 MB,使得模型拥有在边缘设备上运行的能力,同时修改网络的损失函数,使模型快速收敛。实验结果表明,对于正负样本,网络都可以拥有很好的区分能力以及定位效果,最终的定位准确率可达99.96%。本模型为后续的虹膜定位以及识别等奠定了基础,具有一定的实用价值。
猜你喜欢
智能制造(2022年4期)2022-08-18 16:21:14
中国典型病例大全(2022年11期)2022-05-13 17:54:50
核科学与工程(2021年4期)2022-01-12 06:30:22
文萃报·周二版(2018年51期)2018-08-04 06:05:18
计算机应用(2018年5期)2018-07-25 07:41:26
摄影之友(影像视觉)(2018年1期)2018-03-22 01:12:04
摄影之友(影像视觉)(2017年11期)2017-11-27 02:39:53
中国照明(2016年6期)2016-06-15 20:30:14
轴承(2015年2期)2015-07-25 03:51:04
警察技术(2015年3期)2015-02-27 15:37:15
