
融合深度学习与时空预测的目标跟踪方法
2021-09-07 07:45孙炯宁吕太之郭海涛
无线电工程 2021年9期
孙炯宁,吕太之,张 娟,郭海涛
(1.江苏海事职业技术学院 信息工程学院,江苏 南京 211170;2.华南理工大学 土木交通学院,广东 广州 510640)
0 引言
视觉目标跟踪是计算机视觉中的热点问题,在行为分析、智能监控、交通监管、自动监控、汽车导航和高级人机交互等诸多领域都扮演着重要的角色[1]。目标跟踪作为计算机视觉领域的研究热点,近年来有了较大的发展,但由于受到姿势、形状变化,杂波背景,亮度、视角变化、噪声及遮挡等因素的影响,实现健壮的视觉目标跟踪仍极具挑战[2-3]。
随着机器学习技术的发展,视觉目标跟踪技术取得了突飞猛进的发展,尤其是深度学习方法在视频跟踪领域的应用并取得良好效果,推动了视觉跟踪技术发展的新方向[4-6]。2016年研究人员[7]提出利用CNN全卷积网络的SiamFC跟踪方法,大幅度地改善了深度学习在处理视频跟踪过程中的效率低下问题;到2018年,文献[8]提出将SiameseFC和Faster RCNN中的Region Proposal Network(RPN)融合处理,在提升跟踪精度的同时,也进一步改善了跟踪效率,并在VOT2018的全球比赛中夺冠;2019年,SiamMask算法采用半监督分割训练的方法,开启了视觉目标跟踪技术的新思路[9],在给定的数据库上实现了精度最高、速度最快的处理系统,并在开源的实时跟踪系统中表现非凡,但是在实际的应用场景中,由于背景的复杂性及遮挡性、目标特征的差异性和环境影响的随机性等因素,存在着不同的跟踪误差[10-13]。
针对现有方法在动态目标跟踪过程中存在的分割困难、复杂背景下跟踪精度低的问题,研究了一种联合深度学习和时空预测的目标跟踪方法。该方法的主要创新点是在传统基于SiamMask网络的深度学习框架内,通过引入兴趣区域(Region of Interest,ROI)检测实现输入序列中兴趣目标的自动精确提取,克服了干扰导致的误差累积效应;同时,为改善环境干扰、目标遮挡等复杂环境对跟踪精度的影响,在深度跟踪系统中融入了时空上下文目标跟踪算法(STC),根据目标时空关系的在线学习,预测新的目标位置并对SiamMask网络进行算法校正,实现视频序列中的目标快速识别与跟踪。实验结果表明,同传统基于SiamMask网络的深度学习方法和STC方法相比,本文方法在精准度和鲁棒性方面有较大的提高,并且保持着较高的实时性,在跟踪精度和实时性方面实现了很好的折中。
1 基于深度学习的目标快速检测实现
本文通过在PyTorch深度学习框架内引入SiamMask模型进行目标的快速检测和分割。为增加算法的实时性和工程可应用性,采用离线训练的方法对PyTorch深度学习框架进行训练,同时在分割结果中引入损失函数对离线训练网络进行优化,动态调整优化路径和参量。离线训练获取参数以后,SiamMask在既定参量的基础上,对各种输入目标进行未知分割标记(Mask),具体过程如图1所示[15]。

图1 基于SiamMask网络的深度检测框架Fig.1 Depth detection framework based onSiamMask network
标记网络采用2层卷积形式,通道数目为256,通过动态调整实现不同分辨率输入目标的融合。如图1所示,孪生网络通过共享权值,提取目标模板和候选区域特征后,通过卷积实现相似区域的生成。图1中,响应值为Row,目标标记为Mask,预测得分和结果为Score和Box,权重叠加表示为*d,CNN、目标、预测目标、预测以及响应预测的得分处理函数分别表示为fθ,hφ,bσ,sφ,pω[5]。通过离线训练,该网络可以实现对目标的实时处理,采用联想X1电脑可以实现28 帧/秒的处理速度,对于研究而言具有较好的实时性、便捷性和经济性。如果应用于工业场景,考虑环境的适应性,建议采用GPU处理器。
2 融合深度学习和时空预测的跟踪实现
2.1 传统深度学习不足及优化
从上面的分析可以看出,尽管深度学习较好地改善了跟踪精度,但是在背景噪声干扰以及相似特征影响下,跟踪错误明显。基于SiamMask网络的深度检测结果如图2所示。由图2可以明显看出,在正常状态下跟踪结果优秀,精度高且稳定性好。但是当周围出现了背景干扰,例如背景光线变化(如图2(b)所示),以及在相似人体特征干扰目标情况下(如图2(c)所示),系统会出现较大的跟踪误差,甚至跟踪错误。产生这种错误的主要原因是:① 目标初始检测区域的精确性,如果检测区域较大,就会引入较多的干扰因素;② 跟踪失败后无法自适应校正,即使目标再回到稳定环境中,跟踪效果仍然很差。

(a) 正常状态
针对以上2个方面,本文提出了2点修正:① 在算法中引入兴趣区域(ROI)的自适应检测算法,提高目标自动检测精度;② 在跟踪过程中融入时空上下文跟踪算法(STC),对跟踪目标进行匹配预测跟踪。因为传统深度算法中初始标记对后续跟踪的影响较大,为避免过多的误差累计效应,通过ROI的引入可以精确地分离目标和背景,消除背景干扰,降低误差累积效应的影响。同时,STC充分考虑了目标和背景的关系,充分利用目标和背景的区分行实现跟踪,其跟踪速度和精度在同类算法中都具有较大的优势。本文算法的总体流程框图如图3所示。其中,Pk为系统输入的第k帧图像,P′k为融入STC算法的预测结果,Φ为本文算法的判断函数。
2.2 输入视频帧中ROI的提取
系统实现ROI精确分割过程主要包括ROI范围的设定和帧图像中运动的检测这2个方面。其中,ROI范围的设定包括起点位置的设定和区域分辨率的设定。假设通过先验信息知道ROI区域的起点像素为A(x,y),且起点位于输入图像左上角,在给定输入画面宽度l′w和高度l′h的情况下,ROI的高度和宽度分别可以表示为lh和lw,具体计算为[16]:
(1)
基于以上分析思路,在给定输入图像的情况下,可以获得ROI自动提取结果。其中,图像的运动情况主要是采用灰度差值的方法获取,假设像素点z(xz,yz)的灰度值为Ik(z),当2帧图像之间的差值大于给定的阈值时,即认为是运动信息,通过试验测试情况,设定判断阈值ΔIT=30。
2.3 时空预测算法的校正实现
针对光照变化、相似特征干扰等影响,该部分在修正后深度学习框架内融入STC算法,通过目标的时空预测获取目标的置信图,并根据置信图的似然概率获取目标的最新位置信息。假设当前目标上下文集合Tc={c(z)=(I(z),z)|z∈Ωc(t*)},在给定SiamMask模型第k帧目标Pk的情况下,基于STC预测的目标表示为P′k,通过设定分析函数Φ,对Pk与P′k的相似度进行判断分析,并根据判断结果进行模板的实时更新,获取跟踪轨迹。其中,t*(xt,yt)是目标中心,I(z)是目标像素z的灰度值,Ωc(t*)是由目标确定的上下文区域的图像灰度与位置的统计建模,c(z)为置信图函数,整个跟踪过程可以描述为:
步骤1:计算k-1帧ROI区域置信图
(2)
式中,o为所跟踪的目标;P为上下文先验模型:
(3)
式中,ωσ(z)=a×e-z2/σ2是一个权重函数,a为归一化参数,取值为[0,1],σ是一个尺度参数,σ2为高斯函数方差;hsc(t-z)为时空上下文模型,是傅里叶变换后的频率域计算变形。
步骤2:计算k-1帧Ωc(t*)上下文区域的空间上下文模型
(4)
式中,b为归一化参数;α为尺度参数;β为目标形变参数。
步骤3:更新空间上下文hsc(x)模型
(5)
(6)
式中,ρ为模型更新的学习速率。
步骤4:在第k帧计算上下文先验模型及置信图
(7)
(8)
步骤5:将第k帧得到的置信图极值点作为目标在k帧的位置输出
(9)

3 实验与结果分析
3.1 训练及实验环境说明
网络训练采用Object Tracking Benchmark(OTB 2015)数据库[17],该数据库包含了光照变化、运动模糊、形变、遮挡以及目标尺度变化等丰富的复杂干扰背景,且所有目标的真实位置都有精确的人工标注,非常便于网络的训练,近年来被广泛应用于深度学习网络的训练。为加快训练速度,参考SiamMask网络,将Warmup预训练获取的权重作为后续网络的初始参数,提升迭代速度的同时,也保证了网络参数的稳定性。为避免常规梯度训练中参数的局部极值问题,采用冲量算法对参数进行迭代更新。
实验在i7处理器,CPU主频率3.5 GHz,内存16 GB的RAM环境中运行Matlab 2015进行分析,基于OTB 2015的相关视频进行实验分析,主要背景干扰包括遮挡、光照变化以及变形等。为对比分析算法性能,将传统基于SiamMask网络的深度学习方法(SSM)[15]和基于STC[18]的方法进行对比。
3.2 定性分析
本文方法的检测跟踪结果如图4所示。选取了3个同时包含多种挑战因素的视频序列来对算法进行定性评估。

(a) Shaking(8,70,120帧)
其中,Shaking视频中存在光照突变、形变等干扰,由于传统SSM方法严重依赖训练特征和初始输入参量,第8帧时因光照变化导致输入参量权重降低、特征漂移,SSM方法产生了跟踪漂移,第70帧时明显跟踪失败。传统STC方法因为背景干扰导致置信图漂移,也产生了一定的跟踪误差,本文算法一直保持着对光照突变和形变的较好鲁棒性。Girl2视频中由于遮挡的干扰,传统SSM方法和STC方法在目标遮挡后跟踪失败,而本文方法因为引入了兴趣目标的自动检测,能够很好地恢复跟踪性能,从第1 451帧的完全遮挡到第1 465帧的遮挡后恢复,可以看出本文方法对遮挡恢复后的目标仍然能够保持较好的跟踪效果。Freeman4视频存在分辨率低以及遮挡干扰。从第211帧开始,SSM方法和STC方法都出现了漂移,第280帧时2种方法基本上都是跟踪失败状态,但是本文方法仍然保持了较高的跟踪精度。
3.3 定量分析
参考业界目前普遍采用的度量指标,该部分针对跟踪目标的中心位置误差(CLE)和重叠率(OR)进行量化的性能分析[19]。通常情况下,CLE越小、OR越大,跟踪精度越高。3种不同算法针对测试序列的相关量化指标如表1和表2所示。从表1和表2可以看出,针对测试视频,本文方法始终保持着较高的跟踪精度。为了进一步分析本文方法的运行效率和实时性,针对全部的OTB 2015测试序列进行了平均运行分析。SSM的平均跟踪速率为18 帧/秒,STC的平均跟踪速率为49 帧/秒,本文方法的平均跟踪速率为37 帧/秒。由此可以看出,因为引入了兴趣目标自动检测和迭代权重的自适应更新,导致跟踪速率有所降低,但其帧处理速度仍然大于37 帧/秒,满足实时性需求,在跟踪精度和运行实时性方面实现了很好的折中。

表1 CLE计算列表Tab.1 CLE calculation list 单位:pixel
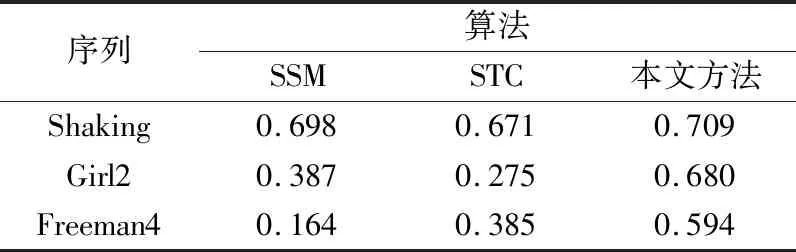
表2 OR计算列表Tab.2 OR calculation list
4 结束语
针对复杂背景下视频目标稳健跟踪问题,提出了一种融合深度学习和时空预测的鲁棒单目标跟踪方法,其创新点主要表现在2个方面:
① 在传统基于SiamMask网络的深度学习框架内,通过引入兴趣区域(ROI)检测实现输入序列中兴趣目标的自动精确提取,在提升系统自动检测跟踪精度的同时,有效地克服了背景干扰导致个跟踪误差累积效应;
② 在深度跟踪系统中融入了时空上下文目标跟踪算法(STC),根据目标时空关系的在线学习,预测新的目标位置并对SiamMask网络进行算法校正,实现视频序列中的目标快速识别与跟踪,有效地改善环境干扰、目标遮挡等复杂背景导致的跟踪漂移问题。
本文方法较好地改善了目标在复杂应用背景中的检测与跟踪问题,但是对于多目标检测问题尚在探索有效的检测跟踪手段,是后续走向应用需要进一步突破的瓶颈所在。
猜你喜欢
四川党的建设(2022年8期)2022-04-28
一重技术(2021年5期)2022-01-18
汽车工程师(2021年12期)2022-01-17
当代陕西(2020年14期)2021-01-08
小学生学习指导(低年级)(2020年11期)2020-12-14
奥秘(创新大赛)(2020年7期)2020-07-27
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
作文大王·低年级(2018年10期)2018-12-06
电子制作(2018年11期)2018-08-04
