
一种基于深度学习的臂丛神经超声图像分割网络
2021-09-07 07:45孔令军王茜雯包云超刘伟光
无线电工程 2021年9期
孔令军,王茜雯,包云超,刘伟光
(1.金陵科技学院 网络与通信工程学院,江苏 南京 211169;2.南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引言
医疗图像处理已经成为数字医疗的重要组成部分,借助图像分割可以找到图像中对医生有用的部分。超声扫描是应用广泛的医疗成像形式,其通过诊断和分析人体内部的肌肉、神经等结构来检测各种疾病和损伤。因此,如何对超声图像进行自动分割以获取感兴趣区域具有十分重要的意义。
与高对比度的CT和MRI相比,超声图像自动分割是更具挑战的任务。臂丛神经(Brachial Plexus,BP)超声图像形成过程中由于电子器件的随机扰动,导致图像变得模糊、失真从而出现颗粒状纹理,降低了图像的信噪比。此外,由于超声图像属于低回声成像,神经元区域在图像中不是一个突出的结构,导致其目标轮廓不明显甚至很难被肉眼分辨。这些困难导致医生很难找到神经的确切位置从而注射药物进行手术。除了准确地定位神经元,BP图像分割还必须减少假阳性样本的预测,这使其成为一个复杂的问题。
传统图像分割方法依靠人工手段来对图像中的边缘、颜色和纹理等信息进行抽取和选择。针对超声图像中的神经分割问题,文献[1]提出了一种基于高斯过程的分类方法,其中感兴趣的区域由专家定义。文献[2]提出了一种基于贝叶斯形状模型的技术,并通过计算训练集中神经结构的平均形状来初始化形状模型。上述方法属于非自动图像分割,需要专家的干预,不仅需要消耗大量的人员和精力,同时需要一定的专业知识,不能保证提取特征的有用性。
基于深度学习的卷积神经网络是目前流行的图像分割技术,其通过卷积操作来自主学习图像中的特征信息,不仅节省了精力,而且提取的特征更为准确。文献[3]首先使用Gabor滤波器对超声神经图像进行边缘检测,然后使用线性二值模式提取特征,最后利用U-Net[4]进行自动图像分割。文献[5]采用中值滤波来抑制超声神经图像中的斑点噪声,并且使用密集的空洞卷积模块和残差多尺度池化模块在U-Net的基础上构建成新的ResU-Net,减少了空间信息的缺失并提高了对不同尺度图像分割的鲁棒性。文献[6]使用Prewitt算子对超声神经图像进行边缘检测,然后通过改进的M-Net[7]进行图像分割。文献[8]对U-Net模型进行改进,构建了一个适用于臂丛神经分割的卷积神经网络模型QU-Net。文献[9]使用SegNet[10]进行超声图像分割,表明了基于多次边界增强的自适应对比度增强算法进行图像预处理能够提高模型的准确率。
多数方法对超声图像进行预处理以去除噪声,给模型训练过程添加了不必要的步骤,因为深度网络能够自适应地学习主要特征。基于U-Net的模型虽然考虑到在解码端通过跳跃连接来补充缺失的细节信息,但这些细节信息可能含有较多噪声并且缺少明显的位置信息。为此本文不使用任何算子进行图像预处理;使用EfficientNetB3[11]作为U-Net的骨干网;重新设计U-Net的跳跃连接,使用空洞卷积、残差连接和最大池化操作在大的感受野上提取更加显著的特征;使用周期欠采样方法,即每个周期训练所有有目标图像而随机训练一半无目标的图像,以提高模型的性能和泛化能力。
1 网络设计
1.1 网络编码端
本文使用EfficientNetB3作为骨干网来构建U-Net框架的编码端,整个网络结构如图1所示。
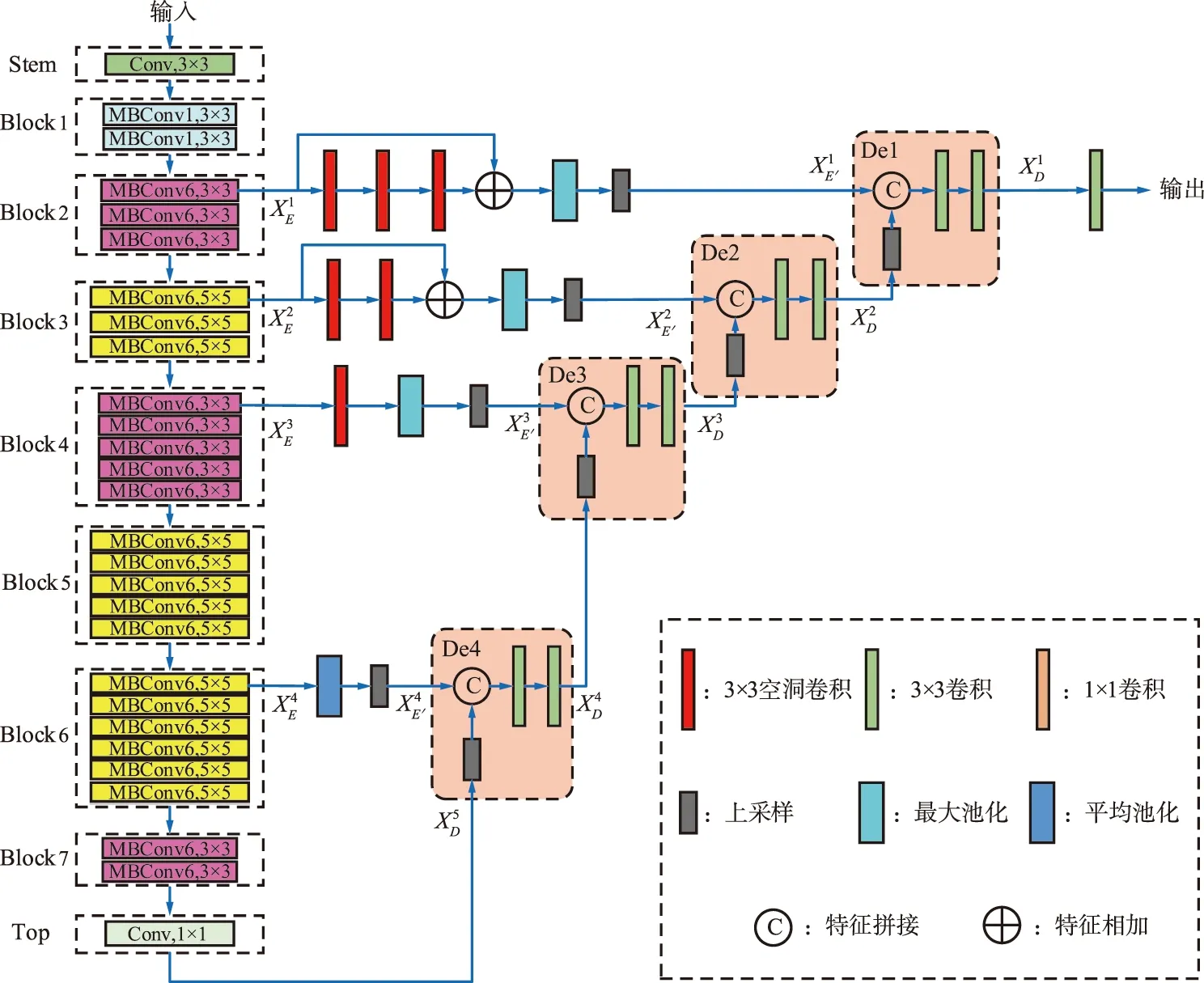
图1 本文设计的网络整体结构Fig.1 Overall structure of the proposed network
EfficientNetB3的Stem模块使用一个3×3的卷积层初步提取特征。Block1~7使用轻量翻转残差模块(Mobile Inverted Residual Block,MB)作为基础结构,MB内部构造如图2所示。
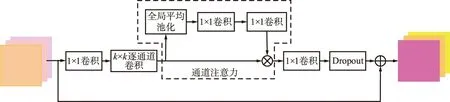
图2 MB的内部结构Fig.2 Internal structure of MB
在MB内部,设置通道扩张率为1或6。若通道扩张率设为6,输入特征先经过1×1的卷积进行6倍的通道扩张,否则输入特征跳过这一层1×1卷积。MB的输入特征或者1×1卷积层的输出特征经过卷积核大小为k的逐通道卷积层提取特征,k的取值为3或5,同时可以设置卷积其步长为1或2。当步长为2时,逐通道卷积在提取特征的同时起到下采样的作用。逐通道卷积输出的特征经过通道注意力部分对不同通道特征加权,其后依次经过1×1卷积层和Dropout层,分别起到调整通道数和随机失活激活值的作用。最终将整个模块的输入作为残差连接与Dropout层的输出相加。每个Block的首个MB以及通道扩张率为1的MB不包括Dropout层和残差连接。
1.2 带空洞卷积的跳跃连接

(1)
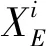
(2)
(3)
(4)
F4(X)=Up2⊙Paverage⊙X,
(5)
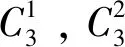
1.3 网络解码端
如图1所示,网络的解码模块为De1,De2,De3和De4,其内部运算可表示为:
(6)
1.4 损失函数
为了解决数据集正负样本严重失衡的问题,本文使用与区域相关的Dice Loss加专注于平衡正负样本以及挖掘困难样本的Focal Loss[12]作为总的损失函数L,具体表示如下:
L=λ1LD+λ2LF,
(7)
(8)
LF=-X×α×(1-Y)γ×lbY-(1-X)×
(1-α)×Yγ×lb(1-Y)。
(9)
针对图像分割,X为掩模,Y为网络输出的预测图,损失函数定义为LD与LF的加权和,如式(7)所示,权重λ1和λ2均赋值为0.5。如式(8)所示,LD为Dice Loss,|X∩Y|为X和Y之间的交集,|X|和|Y|分别表示X和Y的所有元素数值和。LD数值越小X和Y之间的相似度越大,反之越小。如式(9)所示,LF为Focal Loss,使用参数α和γ来调节正负样本的权重以及困难样本挖掘的程度,本文定义α为0.25,γ为2。
2 数据集
本文使用Kaggle竞赛[13]在2016年发布的BP超声图像作为数据集,样例如图3所示,第一行为臂丛神经元超声图像;第二行为臂丛神经元超声图像对应掩模。
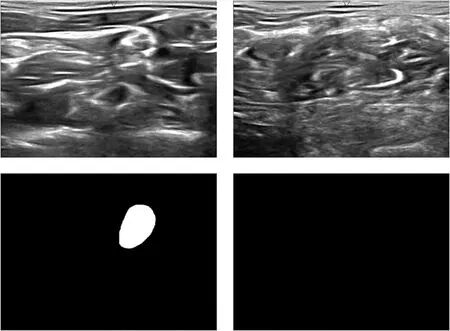
图3 BP数据集样例Fig.3 Sample of BP dataset
带标注的训练集共5 635张,其中含有2 323张有神经元的图像和3 312张没有神经元的图像。将训练集按照9∶1划分为本文实验的训练集和测试集,为了保证训练集与测试集数据分布相同,使训练集中有目标(无目标)与测试集中有目标(无目标)的图像数目比同样为9∶1。官方给出了5 508张标签未知的测试集,只能通过本地提交预测数据来获得其Dice系数,故本文使用官方测试集验证模型的泛化能力。具体数据集划分如表1所示。
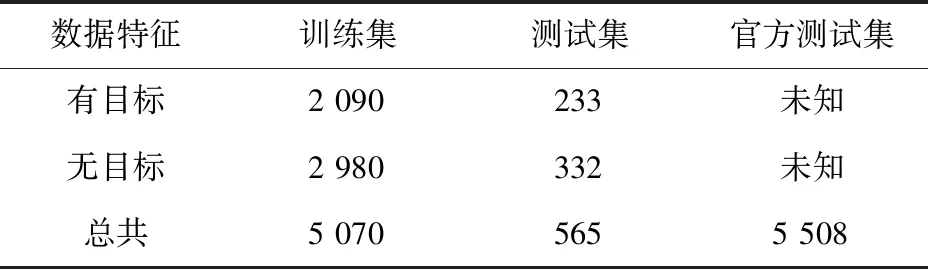
表1 数据集划分Tab.1 Dataset division 单位:张
3 实验与分析
本文在NVIDIA GeForce GTX 1 080 12 GB服务器上进行实验,所有实验的配置相同,具体参数设置为:周期为200,批次大小为4,优化器采用Adam[14],学习率为0.000 1,输入尺寸为320 pixel×320 pixel×3 pixel。同时本文使用数据增强技术来防止过拟合问题,包括水平翻转和随机平移缩放。
本文首先在BP超声数据集上对U-Net、U-Net++[15]、M-Net、用EfficientNetB3作为U-Net骨干网的模型1和用EfficientNetB3作为U-Net骨干网并含有空洞跳跃连接的模型2进行评估,结果如表2所示。
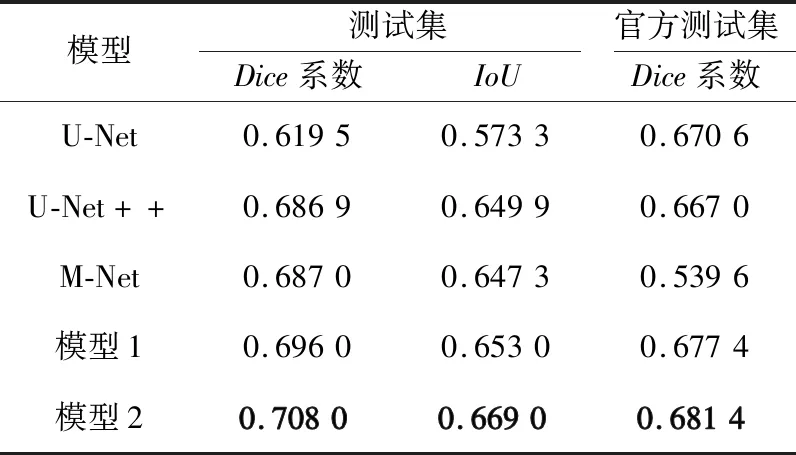
表2 模型性能对比实验结果Tab.2 Comparative experimental results of model performance
从表2可以看到,传统U-Net、U-Net++和M-Net中,M-Net有最高的Dice系数,U-Net++有更好的IoU值,U-Net的泛化性能出色。模型1在测试集上的Dice系数和IoU值以及在官方测试集上的Dice系数均高于以上传统模型,分别达到了0.696 0,0.653 0和0.677 4,表明使用EfficientNetB3代替U-Net的骨干网可以提高模型的性能。而模型2的性能又好于模型1,其在测试集上的Dice系数和IoU值分别达到了0.708 0和0.669 0,比模型1分别高出了1.2%和1.6%;在官方测试集上的Dice系数达到了0.681 4,比模型1高出了0.4%,表明带有空洞卷积的跳跃连接能够提高模型性能和泛化能力。
图4为5种对比模型的部分测试预测图,第一列为BP超声原图,第二列为掩模,第三列为模型2预测图,第四列为模型1预测图,第五列为M-Net预测图,第六列为U-Net预测图,第七列为U-Net++预测图。从图中可以看出,模型1和模型2与掩模的形状更加相似,边缘更加平滑。

图4 不同模型的预测结果Fig.4 Prediction results of different models
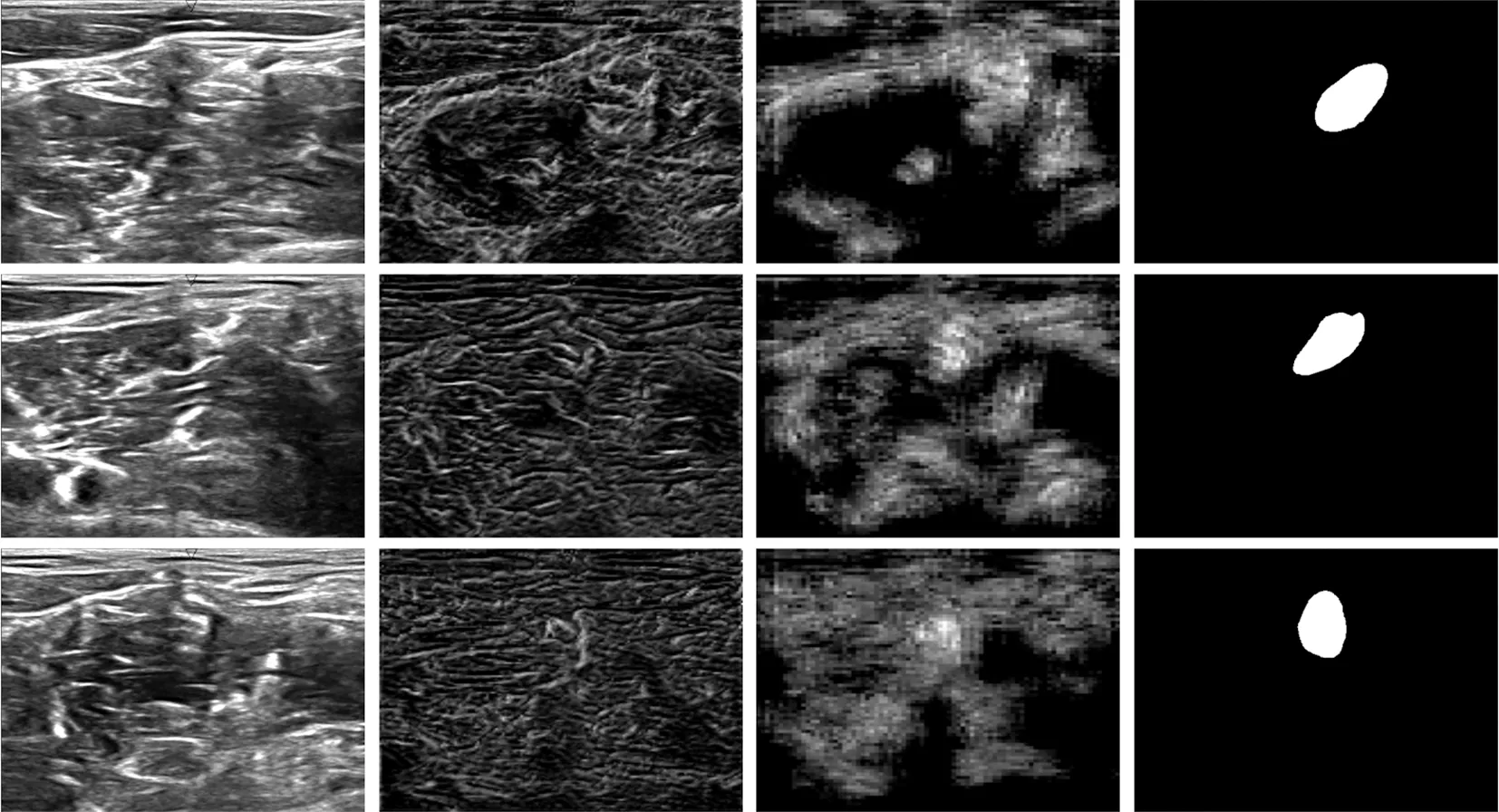
图5 特征和特征可视化结果Fig.5 Visualization results of feature
为了防止模型过分依赖负样本特征,对模型1和模型2使用周期欠采样技术,并与不使用欠采样的模型对比,结果如表3所示。从表3可以看出,使用周期欠采样训练得到的模型1和2均有更好的性能。与模型1相比,模型2的性能提高更多,其在测试集上Dice系数和IoU值均提高了2.67%,在官方测试集上的Dice系数提高了0.39%,表明周期欠采样方法能提高模型的性能同时增强其泛化能力。
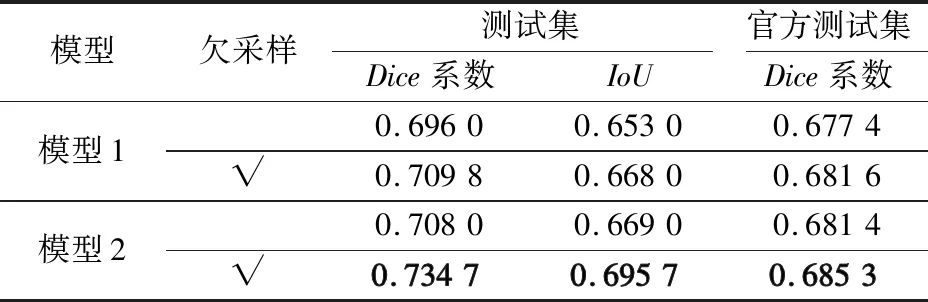
表3 欠采样对模型性能影响的实验结果Tab.3 Experimental results of the effect of undersampling on model performance
本文在表现最好的模型2上进行消融实验来说明所选损失函数的有效性,消融实验结果如表4所示。
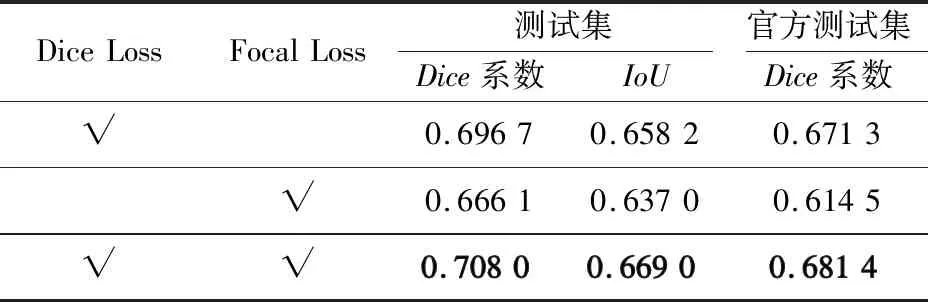
表4 损失函数对模型性能影响的实验结果Tab.4 Experimental results of the effect of loss function on model performance
从表4可以看出,单独使用Dice Loss比单独使用Focal Loss有更好的效果。相比于单独使用Dice Loss和Focal Loss,同时使用Dice Loss和Focal Loss有更好的性能,在测试集上的Dice系数分别提升了1.13%和4.19%。
4 结束语
本文使用EfficientNetB3代替传统U-Net的骨干网构造了一个新的语义分割模型,并在跳跃连接上设计使用空洞卷积来提取特征。在BP超声图像的实验结果表明,带空洞卷积的跳跃连接能够抑制噪声并获取位置信息,同时本文设计的网络在测试集上有更好的性能和泛化能力。周期欠采样方法能够解决正负样本失衡的问题,而且可以提高性能和泛化能力的效果。由于模型的Dice系数与IoU值都较低,在实际应用中只能将其作为医生的辅助诊断工具,还无法实现完全没有人工干预的分割。
获取更多人工标注的臂丛超声图像,并进行有监督的模型训练以获取更好的性能是未来进一步的工作。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学年刊A辑(中文版)(2020年2期)2020-07-25
电子制作(2019年13期)2020-01-14
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中国卫生标准管理(2015年18期)2016-01-20
中外医疗(2015年18期)2016-01-04
中国医疗美容(2015年2期)2015-07-19
