
面向资源发现的联合目录体系构建研究
2021-09-07 10:00:06丁遒劲
农业图书情报学刊 2021年8期
丁遒劲
(中国科学技术信息研究所,北京 100038)
1 引言
联合目录能够一站式揭示、报道多个文献收藏机构所藏文献情况,通常由若干文献收藏机构共同遵循统一著录原则和标准合作编制而成[1]。在以印本文献为主体的资源建设时期,联合目录在指明文献馆藏处所,支持文献传递、馆际互借等文献资源共享活动中发挥了重要作用[2]。但是,随着越来越多文献资源以数字化方式呈现,联合目录单纯以印本文献为主要揭示对象的建设局限性日益显现,建设动力存在明显不足。与联合目录发展相对缓慢形成鲜明对比,自2009 年Serials Solution 公司发布全球第一个大型资源发现系统Summon 起,引进资源发现系统成为各大图书馆整合与揭示馆藏资源的重要手段,主要用于在论文层级向用户提供资源获取线索[3]。通过将资源发现系统中的统一元数据仓储与本地馆藏相结合,国内主要高校图书馆形成了各自专有资源发现系统,例如清华大学“水木搜索”[4]、北京大学“未名学术搜索”[5]等。
无论是联合目录还是资源发现系统,其功能实质都在于协助用户发现和获取其所需资源。现有资源发现系统虽然已经拥有数据量庞大的统一元数据仓储,但是各图书馆在实际应用中仍多是以本馆馆藏以及开放获取资源作为主要全文来源,馆际资源界限仍然存在,用户对本馆以外的馆藏检索与获取能力仍相对较弱。联合目录作为多家馆藏信息的集合,恰好能够弥补资源发现系统的这一不足。也正因如此,联合目录的建设不能局限于印本文献馆藏的书目数据,需要结合数字信息环境中用户的资源发现需求,通过有效的调度计算在更大范围内实现文献资源服务的精准配置[6]。
2 中国联合目录构建模式转型的必要性
中国真正现代意义上的联合目录是1929 年出版的《北平各图书馆所藏中文期刊联合目录》[7]。20 世纪50年代以后,伴随着1956 年图书馆为科学服务方针的制定,中国的联合目录的编制与研究出现了一个高潮[8]。此后,在计算机网络技术和Z39.50 技术的支撑下,联合目录的编制伴随编目技术的进步也得到快速发展,各系统、行业相继形成各类联合目录。但是在当前数字出版环境和用户需求的双重变革下,现有联合目录的建设亟待转型。
2.1 完整揭示馆藏格局,为资源保障策略调整提供依据
受机构性质以及版权等因素限制,中国当前的文献资源建设一方面采购经费日益缩减,另一方面存在资源重复建设与使用不充分的情况,各级、各类图书馆都需要依托联合目录全面了解国内文献资源建设情况。但是,国内目前具有代表性的联合目录,例如CALIS 管理中心的“CALIS 联合目录公共检索系统”、中国科学院文献情报中心的“全国期刊联合目录”以及华东地区六省一市科技情报(信息)所的“华东地区外国和港台科技期刊预订联合目录”等,一般多是侧重于不同系统或地区对图书馆馆藏(订购)信息进行了整合与揭示,造成各联合目录收录文献资源在馆藏单位、馆藏资源品种等不同维度存在交叉重复,而又未能有单一联合目录能够覆盖国内所有馆藏文献。此外,现有联合目录以整合印本资源馆藏信息为主,对包括开放获取资源、数据库在内的电子资源馆藏信息揭示较少,亟待通过优化联合目录建设完整揭示国内文献资源馆藏格局。
2.2 全面共享馆藏信息,为馆际资源共享提供动力
无论是联合目录,还是资源发现系统,基于资源、用户、使用情境等特征进行资源调度计算都是其核心功能所在,因此两者的建设并不能完全独立开来。国内现有联合目录涵盖数据分为两类,一类是馆藏信息,一类是订购信息。单纯的订购品种信息难以支撑后端文献获取,而按年度更新馆藏数据对终端用户的检索效用较小。在资源发现服务构建方面,国内图书馆多是在商业系统中添加本地馆藏,馆际之间的馆藏壁垒依旧存在。但是,有效的资源发现服务既需要海量论文元数据细化资源揭示粒度,也需要融合多馆藏信息,在资源发现服务中增加多馆藏信息指引,只有这样才能实现全国文献资源与服务的精准配置,协调全国文献机构有层次地开展文献服务、数据服务乃至定制化情报分析服务,吸引全国文献机构参与文献资源发现服务体系建设,从根本上提升中国文献资源的保障能力和服务水平。
2.3 系统分析使用数据,为用户需求跟踪提供支撑
在目前以在IP 范围内开通数据库为主的商业模式中,图书馆能够获取的用户数据十分有限。在电子资源使用统计数据采集方法上,目前主要包括本地网络日志分析和服务器端数据商获取,存在日志文件数据过于简单,无法真实还原读者信息行为,统计数据完整性等问题[9]。商业出版社提供的标准化使用统计,主要按月度或年份提供用户检索和下载次数,但是一般不提供包括高频检索词、单一用户信息等在内的更为具体的使用数据。因此,中国自主构建的联合目录需要强化丰富用户数据维度,既包括用户学历、所属机构、学科专业等静态数据,又包括地理位置、检索浏览日志等动态数据,通过收集和分析系统用户的个人基本统计信息、实时动态行为、采集用户的兴趣偏好等数据,基于自然语言处理、数据挖掘等能够提炼并描绘出特定的用户画像类型,从而形成基于用户画像的精准知识服务模式和策略[10],进一步深化馆藏资源利用。
3 国外典型联合目录面向发现服务的发展特征
为了突破联合目录的建设瓶颈,以OCLC 为代表的国外部分联合目录的建设模式已发生较大变化,早已不再局限于印本文献的书目数据,它们正在通过更为广泛的数据获取以及多来源元数据融合优化其资源发现服务,以适应大数据环境下用户对文献资源的精准定位和获取需求。
3.1 革新元数据集成功能定位,打破馆藏信息服务界限
面对电子资源的大量增加以及用户需求的个性化特征日益凸显,以纸质资料为中心的传统OPAC 难以适应数字信息环境中的各项服务要求。为此,日本国立国会图书馆于2004 年发布《数字图书馆中期计划(2004 年版)》,将国立国会图书馆数字存储门户网(PORTA)建设列为图书馆三大支柱功能之一[11],并在2012 年1 月开始使用新的检索服务系统NDL(National Diet Library)Search。在《关于国立国会图书馆的搜索合作拓展的实施计划(2019 年修订版)》(《国立国会図書館サ+チ連携拡張に係る実施銒画(2019 年修订版)》)中,日本国立国会图书馆将NDL Search 定位为元数据的聚集者和提供者,需要在用户中扮演“知识接入点”的角色。NDL Search 除了能够检索本馆馆藏资源外,还囊括了日本国内其他学术信息机构、公共图书馆、大学图书馆、专业图书馆的馆藏信息,具体合作对象包括馆藏目录、数字档案、机构库资源、开放获取期刊等。由此可见,图日本国立国会图书馆对元数据的开发利用不再局限于自主编目的书目数据,而是通过对内外部元数据的广泛关联集成,充分发挥元数据的规模效应。
3.2 拓展与内容提供商合作,扩充元数据仓储规模
面对电子资源规模不断扩大带来的各项挑战,特别是图书馆的工作重点从“拥有”转变为“获取”,WorldCat 的发展不再局限于印本文献的书目数据,而是利用其作为全球众多图书馆的代表身份,通过与内容提供商合作直接获取电子资源的论文元数据,不断充实WorldCat 知识库(WorldCat Knowledge Base)。截至2021 年2 月,知识库中涵盖5 233 万条记录和1.79 万份内容馆藏,这些资料来自包括Wiley、Elsevier等在内的731 内容提供商[12]。以WorldCat 和WorldCat知识库为统一元数据仓储,OCLC 构建了发现服务,可为用户提供对超过9.77 亿篇电子版论文的集成访问。与OCLC 类似,俄亥俄图书馆与信息网络(The Ohio Library and Information Network,简称OhioLink)的中央书目库同时涵盖了印本和电子资源馆藏数据,因此除了文献传递服务外,在相应的电子资源开通范围内,用户还可通过系统提供的电子期刊访问链接获取所需文献[13]。因此,面对当前文快速变化的献资源生产和传播模式,任何文献收藏机构都难以对文献资源进行完整保障。特别是在数字出版与数字图书馆融合趋势下,联合目录需要包括图书馆以及出版社、数据库商等在内的各类型文献信息服务机构的共同参与建设。
3.3 深化发现服务内涵,促进数据开放共享
传统联合目录虽然也面向终端用户提供馆藏查询服务,但是其更侧重于对图书馆业务的支撑,如编目、馆际互借以及文献传递。在当前“以用户为中心”的服务理念,联合目录需要以多个触角接近终端用户,数据的开放共享则是实现的前提。为此,OCLC 通过Google 等学术搜索引擎尽可能丰富终端用户的资源发现服务入口,进一步提升元数据的能见度[14]。NDL Search 通过API 广泛分发内容来提高内容的可见性并促进其使用[15],实现国立国会图书馆和外部机构的数据糅合,为用户提供新的具有附加价值的信息服务[16]。由此可见,资源发现服务的内涵不止于用户检索词与内部数据仓储的检索匹配,它需要通过与搜索引擎合作、开放API 接口等方式促进数据的进一步传播利用,只有促进数据利用的多样性。
综观OCLC、日本国立国会图书馆等机构近年来在书目以及馆藏数据集成与服务方面的实践与规划,上述机构都清晰地认识到数字信息环境正在深刻影响着图书馆的资源遴选、采集、描述、检索发现等各个环节产生影响,并且正在积极适应各项变化,为中国创新构建联合目录体系提供了参考。
4 面向发现服务的联合目录体系构建框架
在国家大型文献保障机构既有元数据资源基础上,结合国内已有的联合目录工作基础和数据优势,对国内主要文献收藏机构的书目和馆藏信息进行集成揭示,形成“面向发现服务的联合目录”,一方面有利于在拓展馆藏发现范围的基础上丰富用户全文获取路径,优化国家文献保障服务体系,另一方面也能够通过全国性的联合目录建设工作加强国内主要文献收藏机构在资源建设方面的交流与互动,促进文献资源共享,尽可能减少文献资源的重复和低效建设情况。总体构建框架如图1 所示。
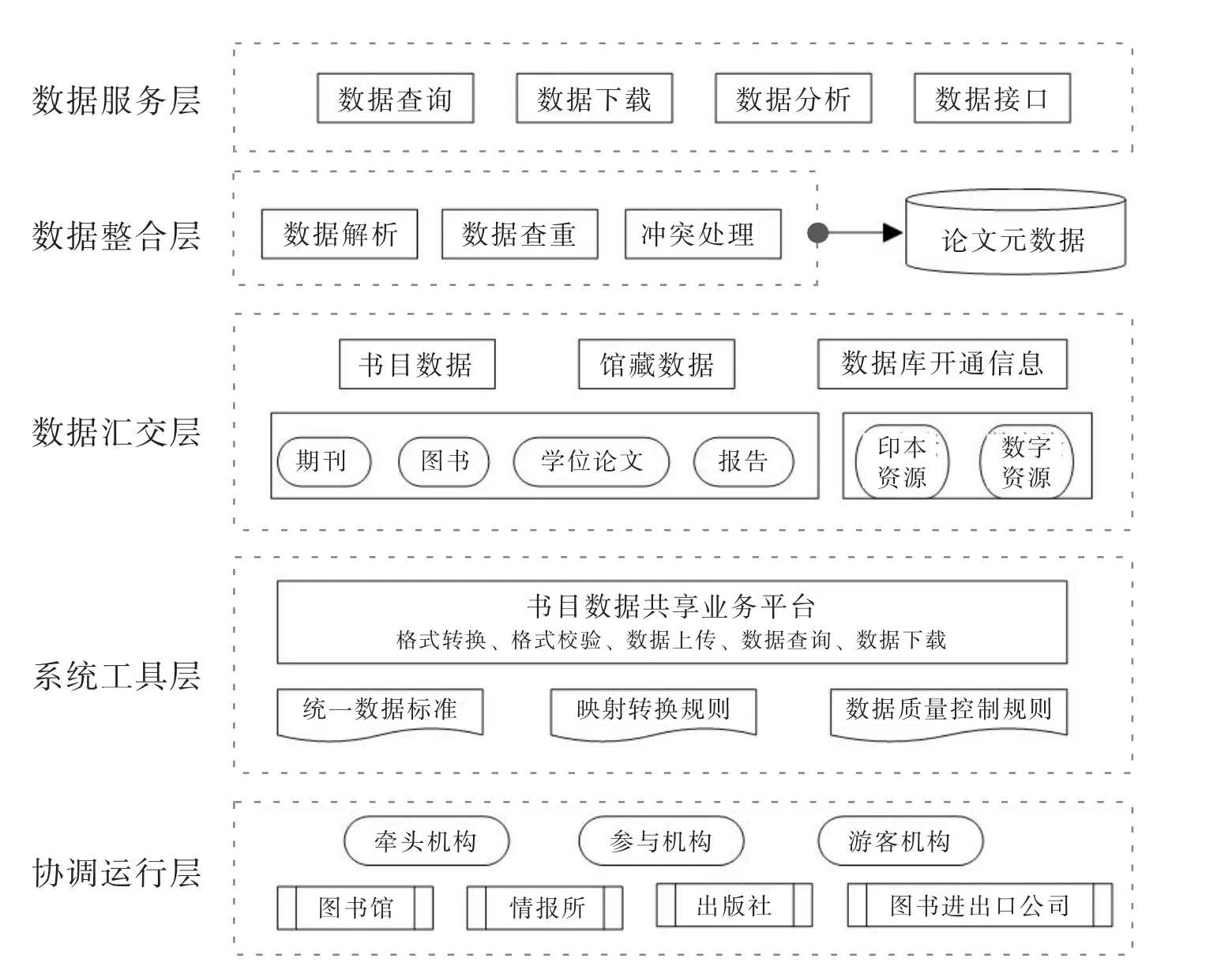
图1 面向资源发现的联合目录体系构建框架Fig.1 The framework of the union catalog system for resource discovery
4.1 总体构建思路
结合中国联合目录建设现状,以及国外典型联合目录发展特征,“面向资源发现服务的联合目录”主要从构建主体、数据采集与处理以及开放利用方面,与传统联合目录相比发生较大变化。
4.1.1 多类型机构共同参与构建
传统联合目录建设方式下,一方面是单一图书馆可能同时参与多个联合目录建设造成重复劳动,另一方面仍以图书馆为建设主体,缺乏出版社、图书进出口代理公司等其他环节主体的参与,在当前数字出版与信息服务融合发展的大背景下,出版社与图书馆已不再是单纯的甲乙方关系,竞争与合作关系并存[17]。因此,图书馆必须以开放的态度吸引各类型信息服务机构参与联合目录建设。即使在图书馆界内部,也存在着一定的系统或地区的条块分割,新型联合目录体系则是需要着眼于全国各类型图书馆的馆藏信息集成。
4.1.2 印本资源与电子资源融合建设
国内图书馆对外文印本资源订购普遍呈下降趋势。根据《2019 年高校图书馆发展报告》[18]统计数据显示,高校图书馆馆均纸质文献资源购置费自2016 年起呈逐年下降趋势,反之,馆均电子资源购置费上涨趋势明显。因此,单纯印本馆藏信息整合使联合目录建设动力不足,逐渐走向“无水之源,无木之本”。因此需要重视印本资源与电子资源的融合揭示,一方面在经费允许的情况下保持印本资源的订购,另一方面着力加大电子资源引进力度。所谓电子资源引进,不再是单纯以IP 方式开通使用,而要同时强化论文元数据乃至全文在本地的保存与使用权益,从而实现印本资源和电子资源的真正融合。
4.1.3 强化数据、系统和服务开放性
数据之间的有效关联是拓展和深化馆藏利用的重要途径之一。仅仅在书目层级的文献资源集成揭示往往满足的是图书馆的业务需求而非终端使用需求。“面向资源发现服务的联合目录”将在书目数据和论文元数据之间形成有效关联,这既是书目数据向文章乃至知识单元层级的有效延伸,也是在书目层级对海量元数据进行结构化管理,基于资源调度系统协助用户在资源发现过程中反向获取印本资源馆藏信息和电子资源开通信息。此外,对系统本身而言,数据接口也是“面向资源发现服务的联合目录”与外部其他系统形成有效关联和深化利用的有效途径,能够支持机构在学科、主题等方面构建专有服务系统。
4.2 构建框架结构
“面向资源发现服务的联合目录”自下而上包括协调运行层、系统工具层、数据汇交层、数据管理层和数据服务层。
4.2.1 协调运行层
目前,国内已有大型文献保障机构开始注重元数据资源建设工作,例如,国家科技图书文献中心(简称“NSTL”)已与科睿唯安、Elsevier、Springer、ProQuest 等20 余家出版社/集成商达成元数据合作[19]。依托类似NSTL 这类机构既有书目数据、馆藏数据以及论文元数据资源,利用其统筹优势和工作体系,协调专业图书馆系统、高校图书馆系统和公共图书馆系统主要机构参与书目和馆藏数据共享,从而对国内主要文献收藏机构的书目数据和馆藏信息进行集成揭示。数据共享是多机构持续参与建设的根本保障。面向发现服务的联合目录建设强调基础数据的双向流动与互利共享,最大化提升数据使用效率,保障系统建设的稳定性和持续性。参建机构能够持续地共享数据,用于丰富自身数据体系,并根据本地特定的用户需求将数据用于系统开发、定制化分析服务等。在版权管理方面,参考OCLC 针对WorldCat 数据的做法[20],无论是通过牵头机构还是成员机构直接上传的书目数据和馆藏数据,都需要保证数据不存在版权纠纷;牵头组织和管理机构将代表所有数据上传机构对集成数据的汇编权,牵头机构对集成数据均具有永久使用权,但是单条数据的版权始终归各上传机构所有。
4.2.2 系统工具层
目前,各个现有联合目录在数据遵循标准、数据质量方面存在较大差异,多个联合目录数据的集成需要依据统一的标准规范进行集成。联合目录系统数据标准及其映射规范、书目与馆藏数据质量控制规范是影响联合目录数据集成效果的主要标准规范。因此,在分析各个联合目录数据格式和数据质量的基础上,参建机构将联合制订统一的数据标准,并建立各个联合目录数据规范与统一数据标准之间的映射转换规则。在统一元数据标准制定方面,NSTL 在2017 年便基于多家国际知名出版商和信息服务机构采用的文献元数据标准,形成《NSTL 统一文献元数据标准》[21],可作为中心元数据标准对各来源数据进行映射转化。同时,为了保证数据字段完整性、准确性等,需要制订书目与馆藏数据质量控制规范,对各来源数据进行二次补充和完善,提升数据质量。
4.2.3 数据汇交层
“面向发现服务的联合目录”数据汇交采取多级汇交管理方式。例如,CALIS 管理中心负责高校图书馆系统,NSTL 负责其九家成员单位、地方情报所和专业图书馆,以及国家图书馆负责各省市公共图书馆的数据集中收集,它们分别将各自系统参建机构提交的数据进行汇总,并统一上传至系统。在各自图书馆系统内部,也可根据既有管理体系对数据管理组织进行进一步细分,例如在CALIS 内部,按照学科中心或地区中心进行管理。各参建机构提交数据分为回溯数据和更新数据,回溯数据为一次性提交,更新书目数据和馆藏数据需要至少按周或月进行更新,对于长时间未更新数据单位,将由上一级数据提交单位负责跟踪催缺,以保障联合目录数据的及时性、完整性和连续性。
4.2.4 数据管理层
相比于通过编目产生的书目数据,数字环境中的数据种类、层级、来源、渠道、形态和格式则更为多样,存在数据孤岛、数据蜘蛛网等问题,需要通过集成整合在数据源逻辑层上建立统一的访问结构,屏蔽底层数据源的差异,实现统一的查询界面灵活地访问网络上的异构数据源[22]。因此,对各参建机构提交的数据,最终将由牵头组织和管理机构基于统一业务平台进行规范集成。通过本地数据收割以及FTP 等远程数据收割方式,系统将对从不同来源获取的数据进行初步格式校验,并基于统一的元数据标准将数据转换为统一格式。不同来源数据可能涉及相同馆藏机构或同一资源实体,需要依靠品种名称、资源唯一标识符等进行查重和归并,最终形成统一的书目数据和馆藏数据仓储[23],并以联合目录形式对外提供服务。
4.2.5 数据服务层
基于“面向发现服务的联合目录”的功能定位,系统服务主要在于支持参建机构实现数据的稳定传输、查询和下载,并能够按照馆藏单位、文献资源品种等不同维度对系统数据进行统计分析,以支持本馆资源建设决策。与此同时,系统同时对外提供数据服务方面,外部机构的目录系统和数据存储系统可以通过Restful 接口及OAI 接口等与系统互联,形成稳定的在线接口数据传输,能够利用系统数据支持本地系统建设和服务。通过灵活使用统计数据查询、书目数据获取等接口,“面向发现服务的联合目录”和外部机构能实现数据糅合,从而为使用者提供具有更高附加价值的信息服务。
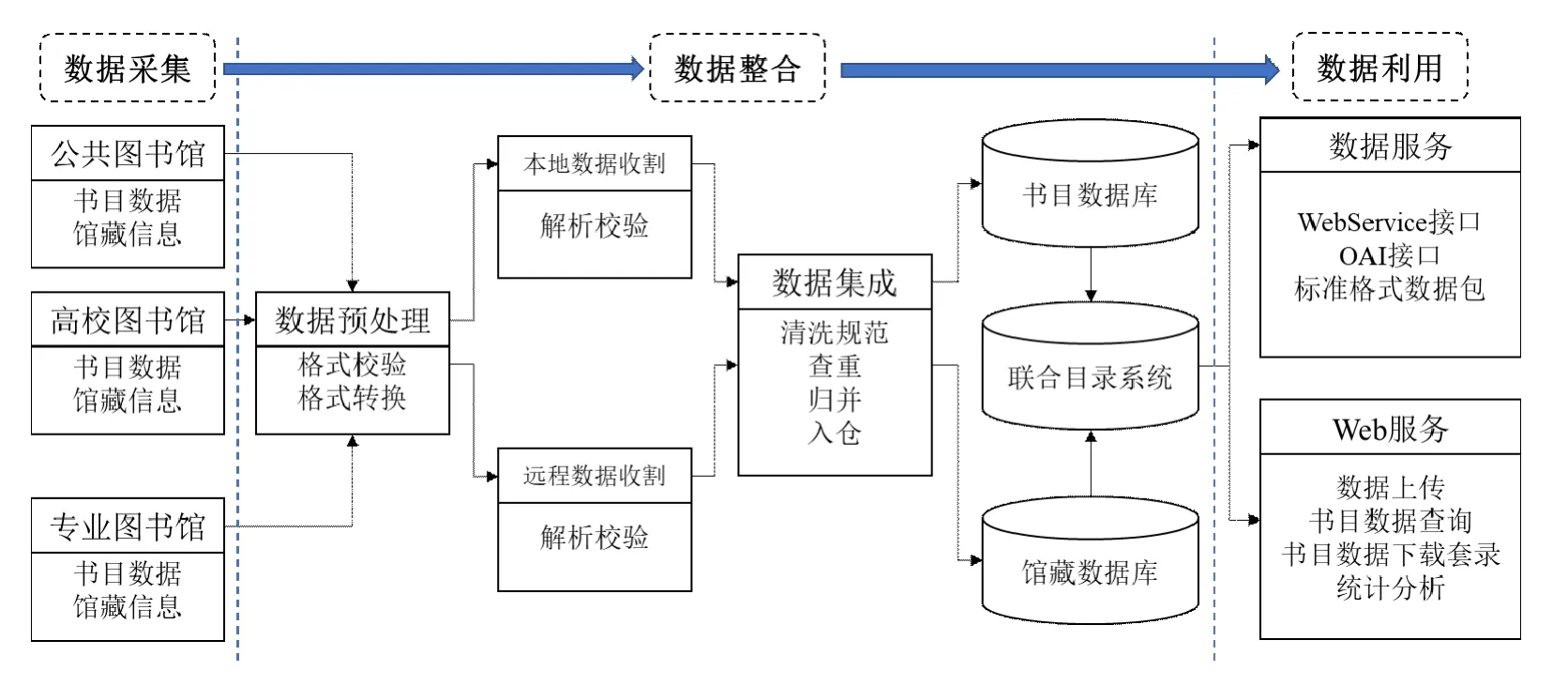
图2 数据汇交管理流程Fig.2 The process of metadata collection
5 结论
在印本资源为主体的资源建设时期,联合目录在文献资源共享中发挥了不可替代的作用。但是,随着数字出版潮流以及用户需求的不断变化,传统联合目录建设的弊端逐渐显现,需要面向发现服务构建新型联合目录体系。与以往相比,新型联合目录特征突出表现在3 个方面,参建主体多样化、建设对象同时涵盖印本资源和电子资源,数据、系统和服务的开放性得到强化,能够进一步提升联合目录的服务效益。“面向发现服务的联合目录”有效适应了数字出版时代的发展要求,能够在一定程度上打破资源发现服务中的馆藏壁垒,进一步推动文献资源的共享利用。
猜你喜欢
现代装饰(2022年6期)2022-12-17 01:07:32
都市人(2022年3期)2022-04-27 00:44:57
速读·下旬(2021年11期)2021-10-12 01:10:43
艺术品鉴(2019年11期)2019-12-27 09:06:18
大东方(2019年12期)2019-10-20 13:12:49
大观(书画家)(2018年6期)2018-07-08 00:43:26
科学与财富(2017年22期)2017-09-10 13:20:02
商情(2017年1期)2017-03-22 16:56:36
文物春秋(2014年2期)2014-12-24 21:23:05
中国民间疗法(2012年1期)2012-07-27 09:31:30
