
基于深度学习的计算机软件安全性能检测技术
2021-09-04 02:41刘景林
九江学院学报(自然科学版) 2021年2期
刘景林
(泉州经贸职业技术学院信息技术系 福建泉州 362000)
计算机软件开发过程中软件安全性能检测不可或缺,利于及时发现软件安全缺陷、安全故障并修复,更正未来软件应用的安全风险,保障实际应用效能与预期设计一致。计算机软件安全性能检测包含项目众多,漏洞扫描是计算机软件安全性能评估指标之一。该研究以软件的漏洞扫描为对象展开软件的安全性能分析[1]。随着人工智能技术的高速发展与应用,深度学习超越了支持向量机、决策树、贝叶斯分类器等浅层学习架构的识别与分类能力,以其模拟人脑神经网络的极大优势,在解决大数据深层次分类问题、计算机数据深度挖掘问题上功效显著[2]。为此,文章基于深度学习算法检测计算机软件开发期存在的安全漏洞问题,更加精准的探寻软件开发存在的安全风险。
1基于深度学习的计算机软件安全性能检测
该研究中,计算机软件安全性能检测原理如下:①构建软件漏洞代码数据集,作为深度学习算法训练的样本。②设计堆叠自编码器深度学习架构进行漏洞检测样本训练,构建计算机软件漏洞检测模型,以识别软件代码漏洞方面的安全性能。
1.1基于堆叠自编码器的深度学习网络模型构建
卷积神经网络、堆叠自编码器、深度信念网络均为典型的深度学习模型,自编码器训练成本不高、无监督学习,更适合解决计算机恶意软件识别、漏洞检测等问题。多个自编码器组成堆叠自编码器结构,如图1、图2所示。自编码器本质是人工神经网络,以学习编码的方式解决深层次的分类问题[3]。自编码器包括输入层、隐藏层、输出层等基本结构,在输入层样本被进行编码处理传输至隐藏层,再以解码的方式传输到输出层,此为自编码器分类的全过程。此过程中编码数据通常会被压缩,因为隐藏层节点数量相比输入层较少,隐藏层实质是一种特征空间。

图1 自编码器基本结构

图2 堆叠自编码器原理
自编码器运行具体过程如下:
首先,定义自编码器fε的输入样本为X={x1,x2,…,xn},包含n个样本;m0维特征向量用xi描述,公式(1)为自编码器的激活函数形式:
(1)
其次,将输入样本xi转换为隐藏表示向量yi,方法如下:
yi=fε(xi)=s(Wxi+b)
(2)
式(2)中,权重矩阵用W表示,大小为m0×m1,隐藏层神经元为m1个;偏移向量为b。
然后,隐藏层输出的yi成为解码器的输入,公式(3)为解码器的表达式:
(3)
式(3)中,偏移向量与权重矩阵分别描述为b′、W。由于输入层与输出层神经元数量超过隐藏层,所以在堆叠自编码器结构作用下,软件漏洞代码数据样本以压缩的方式进行重构,此时应以重构压缩误差最小作为目标[4],因此重构压缩误差需满足公式(4):
(4)
深层次学习网络(堆叠自编码器)形成需要以数个自编码器连接为前提,共同构建一个可以解决复杂数据分类问题的深度学习模型,上一层次自编码器的输出将作为下一层次自编码器的输入,由此构成的用于软件漏洞扫描的堆叠自编码器结构,如图2所示。其中,堆叠自编码器由n个自编码器组成,将每层编码器的隐藏层输出作为下一层自编码器的输入,如此重复形成一个系统化的深层次网络结构。除此之外,堆叠自编码器尾层增加了分类器结构,其目的是识别软件是否存在漏洞[5]。
1.2基于深度学习模型的软件漏洞训练与检测
堆叠自编码器的预训练与微调是修正模型性能的两个关键步骤,因此在预训练与微调阶段执行以下策略:
(1)堆叠自编码器预训练策略:首先,输入样本集采用无标签形式,还原网络的权值矩阵与偏置向量,同时定义迭代次数、学习率、批量大小、网络层数等参数;其次,以无监督的方式训练堆叠自编码器,求取隐藏层神经元激活量、代价函数两个关键变量;最后参照李晴晴等人方式更新权值与偏置值[6],堆叠自编码器终止迭代的条件时误差符合预设值。
(2)堆叠自编码器的微调策略:首先,输入样本集采用有标签形式,少量样本即可,执行预训练得到的权值矩阵与偏置向量,更新迭代次数、学习率、批量大小、网络层数等参数;其次,为堆叠自编码器末端设置softmax分类器,以有监督的方式进行漏洞分类;最后,在各个迭代环节更新权值与偏置量,方法是BP反向传播法,完成对深度网络参数的微调[7],由此得到一个参数训练完备的堆叠自编码器检测模型。
堆叠自编码器检测阶段,将检测对象的代码构成数据集输入到训练好的堆叠自编码器模型中,得到相应的软件漏洞检测结果,当输出结果为“0”时对应的结果为“不存在漏洞”;当输出结果大于“0”时对应的分类结果为“存在漏洞”。
2测试与分析
基于Python 语言在 Linux 操作系统下对文章深度学习检测算法进行开发,搭建计算机软件安全性能测试环境展开技术实验。由计算机软件开发企业获得大量带有漏洞的软件代码数据,构成5个大小相当的数据集作为测试样本。测试中使用误报率、漏报率评估检测方法的可行性与性能,当不存在漏洞的样本分类成存在漏洞样本时,将其称为误报;当存在漏洞的样本分类成不存在漏洞样本时,将其称为漏报。
2.1检测方法的误报率与漏报率分析
在5个软件代码数据集上对文章方法展开性能测试,文章方法运行完毕记录了相应的误报率与漏报率,结果如表1所示。
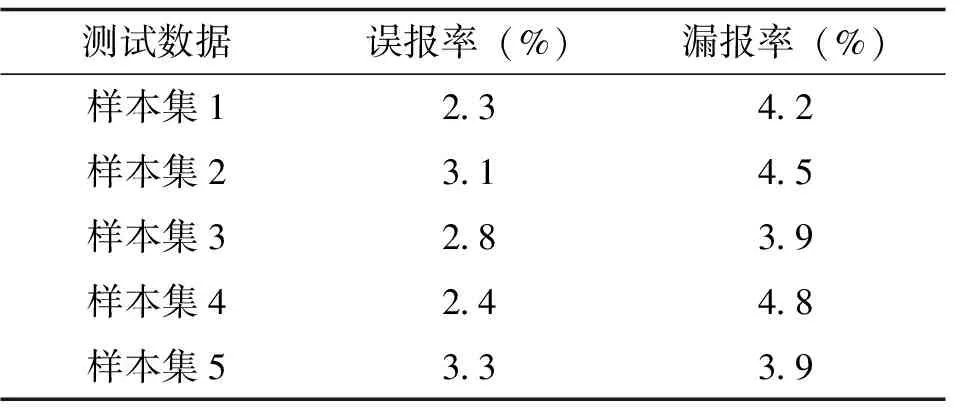
表1 文章方法的软件漏洞检测的误报率与漏报率统计
表1数据显示,文章方法检测软件漏洞的误报率在2.3~3.3%之间,漏报率在3.9~4.8%,漏报的概率整体高于误报的概率。首先说明该方法将漏洞样本分类成无漏洞样本的可能性较大,日后的研究中可从该角度入手改进检测技术的适应性与使用性能;其次,文章方法误报率与漏报率的波动不大,均维持在1%左右,说明该方法检测软件漏洞的稳定性较优,实用性较强。除此之外,两种评估指标均低于5%,在合理范围内,从检测精度方面而言文章方法可作为可靠的检测技术尝试投入应用。
2.2漏洞检测性能对比
为了突出文章方法检测软件漏洞的性能优势,采用基于网络爬虫的漏洞检测方法、基于关联分析的漏洞检测方法进行对比测试。测试样本集1~5中分别存在5个、4个、5个、3个、6个软件漏洞,采用3种方法进行漏洞检测,记录各方法检测漏洞的实际数量与测试用时,如表2所示。

表2 三种方法的软件漏洞检测结果
表2数据显示,文章方法基本可以准确检测出样本集中的漏洞信息,只有第5个样本集的检测结果存在偏差,实际软件漏洞为6个,文章方法检测出5个,整体的漏洞检测率约为95.7%,耗时645s;基于网络爬虫的漏洞检测方法成功检测出15个软件漏洞,检测率约为65.2%,检测漏洞的时间开销高达1012s,无论在检测准确率还是效率方面都没有达到可行标准。同理,基于关联分析的漏洞检测方法检测率为73.9%,检测漏洞的时间开销为894s,同样没有达到可推广应用的标准。
相比之下,文章方法的检测效率与检测准确度均较为理想,这是因为文章方法利用堆叠自编码器构建深度学习架构,以编码与解码的方式对输入样本进行深层次处理,采用多个自编码器连接形成堆叠自编码器架构,在模型训练阶段基于堆叠自编码器预训练策略与微调策略修正模型的性能。这种方法超越了浅层神经网络分类方法对数据特征学习的有效性,深入挖掘软件漏洞代码数据中的特征规律,因此在检测精度和时间开销上达到了理想状态。
3结论
针对计算机软件开发中漏洞检测的复杂性与多特征性质,将深度学习算法引入到软件安全漏洞检测方案中。首先,该研究构建具有漏洞信息的代码数据集,作为深度学习模型的训练与检测样本;然后,采用多个自编码器连接形成堆叠自编码器模型,经过预训练与微调后,得到一个较为完备的堆叠自编码器软件漏洞检测模型。
为了提高检测方案与软件漏洞特征、安全信息的紧密度,增强检测方案的有效性,未来关于软件安全性能检测的工作应做到如下方面:其一,立足于软件漏洞类型特征分析角度,在掌握软件运行的安全特性基础上设计安全检测算法。其二,了解软件漏洞的具体分类,构建多分类识别模型,将软件当前存在的漏洞类型信息呈现在检测结果之中。
猜你喜欢
今日农业(2022年13期)2022-09-15
网络安全与数据管理(2022年1期)2022-08-29
电子制作(2018年16期)2018-09-26
成都信息工程大学学报(2018年3期)2018-08-29
电子制作(2018年1期)2018-04-04
电子制作(2017年24期)2017-02-02
西安工程大学学报(2016年6期)2017-01-15
中国卫生(2016年5期)2016-11-12
儿童时代(2016年6期)2016-09-14
中国卫生(2015年12期)2015-11-10
