
分布式文件存储系统在电子通信大数据存储中的应用*
2021-09-04 02:41刘苏英
九江学院学报(自然科学版) 2021年2期
刘苏英
(安徽机电职业技术学院电气工程学院 安徽芜湖 241002)
信息时代,社会各行业正常运转已经离不开电子通信数据文件的支持,如何高效率存储大规模电子通信数据是当前多领域健康有序发展迫切需要解决的问题[1]。HDFS(hadoop distributed file system)是一种分布式的文件存储系统,具备强大的数据追加、数据读取优化能力[2]。面对不断增长的电子通信数据存储规模,HDFS集群可以按需求拓展容量,同时在可靠性、容错率方面取得了用户的广泛认可[3]。为此,文章对传统的HDFS分布式文件存储系统进行优化与改进,实现电子通信数据在HDFS集群上的高效率、低能耗存储目标。
1基于HDFS分布式文件存储系统的电子通信大数据存储方法
1.1 HDFS分布式文件存储系统基本结构
HDFS分布式文件存储系统具有极强的数据存储节点拓展功能,个体HDFS集群具有拓展千万节点的能力,可以适应较大吞吐量数据的读取写入工作,所以适用于大规模的服务集群的海量数据存储工作,可靠性得到广大用户的认可。图1描述了HDFS集群架构布局情况,待存储的大型文件一般划分成大型数据块,标记为data block,在集群节点上有序且分布存储。图1中,HDFS集群的命名空间、数据块存储位置信息全部属于元数据范畴,由NameNode节点集中管理,系统专门为其设计了备份节点,以免NameNode管理误差导致的HDFS分布式集群故障[4]。HDFS分布式集群元数据规模不是一层不变的,跟随集群规模扩张、文件存储规模增加而扩大,针对这一情况,HDFS集群设计了人性化的多个NameNode节点并存机制,将分布式存储任务按照其负荷能力分配到具体的NameNode节点上,值得注意的是多个NameNode节点之间不存在关联关系。
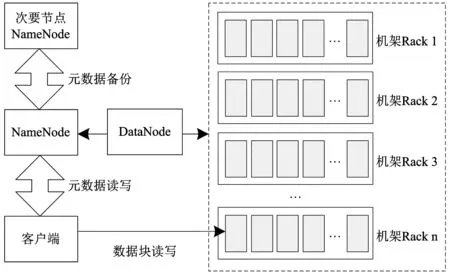
图1 HDFS集群架构布局
DataNode是HDFS集群节点数据管理主体,将本地不同数据块分派给若干个DataNode,NameNode可定时接收来自DataNode发送的表征节点状内容的心跳信息。由于最初电子通信大数据开始分布式存储行为之初进行了数据块划分处理,HDFS在统一集群环境中保存了3个左右的文件副本以保障数据存储的可靠性与安全性,增强HDFS集群分布式存储的容错性能,这些数据块和副本一同存储在DataNode。机架内部为数据块位置所在,即图中的虚线块部分,数据块详细的位置信息取决于NameNode[5]。另外,机架(Rack)是HDFS分布式文件存储系统的关键构成要素,每个机架设置了若干个DataNode,以数据中心的网络为介质实施高效率、高速率的数据交互行为。
1.2 基于空闲容量的HDFS系统优化存储策略
HDFS分布式文件系统需要依靠集群存储状态划分系统各节点的文件存储任务,避免个别节点负载量过大,均衡系统的大数据存储效率[6]。该研究为了高效率完成电子通信大数据在HDFS分布式文件系统上的安全存储,首先需要了解集群各层次硬盘空闲占比情况,基于这些相关变量合理的向系统节点分配文件存储任务,为此基于公式(1)求取HDFS集群虚拟内存盘空闲容量百分比:
(1)
其中,集群包含n个节点;G1j、Gah分别表示各节点虚拟内存磁盘空闲存储大小及其总存储量大小,j、h的取值均为j=1,…,n。
根据公式(1)明确HDFS集群不同层次空闲存储情况后,需定义科学的阈值对可用的存储层次进行评估和确定[7]。例如阈值设置为25%,若G超过阈值视其为健康的存储层次,可以作为正常的存储节点使用;反之,若G低于阈值则视其为非健康存储层次,需深度评估其存储状态,进行更加深度的维护处理。
1.3 基于细粒度均衡的文件放置优化算法
HDFS分布式文件存储系统中存在访问热度不同的海量电子信息文件,随着时间的推移能够显著区别文件的访问热度,工作中较为关注的信息内容往往更容易被查看点击,因此文件创建时间更加邻近当前时刻;同样,热度较低的电子通信大数据文件较少被查看点击,其创建时间相应的更加久远[8]。为此,该研究基于电子通信大数据热度与时间的相关性特征,对HDFS集群的大数据文件进行合理放置。主要原理如下:此过程中,热度接近的文件称它们在时间维度上的细粒度相似,将细粒度相似的文件平均分配给各个节点,这样可以分担各节点的存储负担,实现HDFS集群均衡存储与负载,此为细粒度均衡算法的基本要义。
细粒度均衡算法实施之前,需预先设定文件创建时间区间、创建时间区间数量等信息[9]。细粒度较低的文件对存储系统的负载贡献较小,因为它们距离当前时刻较为久远、访问的热度较低,由此可以得出以下规律:接近当前时刻的文件创建时间,对应的区间更加细密;远离当前时刻的文件创建时间,其区间更加稀疏。
2实验分析
搭建包含3个节点的HDFS分布式文件存储集群实验环境,其中包含1 NameNode节点,2个DataNode节点,DataNode节点的详细参数如表1所示。使用2.6.0版本的Hadoop,计算机硬件条件如下:CPU 2.7 GHz Intel Core i7、内存大小为8GB、硬盘大小为500GB。实验数据集采集自某企业的正规电子通信业务,根据测试需求划分成1000个大小一致的实验数据包。引用传统HDFS大数据存储方法、基于Hadoop的大数据存储方法作为对比测试方法,突出文章方法在存储电子通信大数据方面的优越性。

表1 DataNode节点详细参数
采用文章方法、传统HDFS大数据存储方法、基于Hadoop的大数据存储方法向分布式文件存储系统发送数据包,记录不同时间节点上数据传输延时情况,如表2所示。

表2 不同时间节点上三种方法的大数据传输延时(s)
随着数据发送行为的进行,分布式文件存储系统存储文件的工作有序开展,3~15s期间文章方法存储数据的延时保持在0.05~0.11s之内,延时增幅较小,属于正常数据存储状态。传统HDFS大数据存储方法起步存储延时与文章方法一致,但是随着时间的推移,该方法延时增幅越来越大,运行到15s时的传输延时达到0.17s。此外,基于Hadoop的大数据存储方法最初的存储延时较大,每个时间节点上的延时大幅度提升,测试进行到12s、15s时其存储大数据的延时也达到0.19s、0.22s。相比之下,对比方法均展现了较差的存储效率,文章方法存储海量电子通信数据的效率得到了认可,同时记录了3种方法测试中文件存储的节能效率走势,如图2所示。
由图2可知,测试开展最初,3种方法的节能效率均保持在60%左右,存储电子通信大数据的节能效果优异;当数据包增加至400个时,3种方法节能效率仍然持平并出现同步的小幅度下降趋势;当数据包传输量增加到600个时,传统HDFS大数据存储方法、基于Hadoop的大数据存储方法节能效率下降趋势显著,文章方法节能效率仍然高达约48%;随后,数据包传输达到1000个时,文章方法的节能效率约为33.3%,另外两种方法降低至16.5%左右。
3结论
文章利用分布式文件存储系统生成一套行之有效的电子通信大数据存储方案,在实验中取得了较短的延时效果以及良好的节能效率,为存储海量电子通信数据提供了有效途径。文章方法始终保持良好的节能效率,是因为使用了基于空闲容量的HDFS系统优化存储策略,也是文章方法的创新之处。该方法避免了个别节点负载量过大、均衡了系统的大数据存储效率和实现大数据存储的节能目标。另外,基于细粒度均衡的文件放置优化算法实现了对HDFS集群大数据的合理放置,减轻了海量电子通信数据对HDFS集群的存储负担。
猜你喜欢
红外技术(2022年11期)2022-11-25
自动化仪表(2020年10期)2020-11-13
哈尔滨轴承(2020年2期)2020-11-06
安阳工学院学报(2020年2期)2020-06-05
电子制作(2019年14期)2019-08-20
发明与创新·大科技(2019年12期)2019-03-17
电脑知识与技术(2017年26期)2017-11-20
信息安全研究(2016年3期)2016-12-01
船舶力学(2015年6期)2015-12-12
中国教育信息化(2015年12期)2015-08-24
