
一种Anchor-Free的联合模型车辆多目标跟踪算法
2021-09-03 10:01陈诗煊
辽宁大学学报(自然科学版) 2021年3期
马 利 陈诗煊 牛 斌
(辽宁大学 信息学院,辽宁 沈阳 110036)
0 引言
多目标跟踪旨在预测视频序列中多个跟踪目标的轨迹,被广泛应用在辅助驾驶、智能交通等领域.对车辆目标进行跟踪,不仅能有效辅助驾驶员规避前方危险情况,而且对于智能交通的车流量调控及异常事件处理有着深远的意义.目前主流的多目标跟踪算法,被分为两大类:第一类,采用先检测后关联的两阶范式.这类算法在跟踪准确率上有不俗的表现,但在跟踪效率上不能满足需求.第二类,把多目标跟踪视作目标的检测和重识别任务,在单个联合模型中联合目标检测和学习Re-ID特征,一次性解决目标跟踪.由于使用单个网络,这类算法效率较高,但准确率低于两阶段范式算法.
按照传统的按检测跟踪(tracking-by-detection)[1]的思想,现有的联合模型算法都是对检测器网络添加重识别(Re-ID)特征嵌入分支方式实现的,其骨干网络采用了对检测更适合的基于Anchor的检测方法,并使用了大步长的下采样率提高效率,较少考虑检测器网络学习Re-ID特征的效果.Zhou等[2]提出了一种Anchor-Free的检测器模型,实现了不基于Anchor的关键点目标检测方法.受其启示,本文提出一种Anchor-Free的联合模型车辆多目标跟踪算法,把Anchor-Free的深度特征融合网络[3]引入联合模型,在小步长下采样率的网络结构中提取目标的特征图,减小量化误差.在网络上采样过程中引入最新的可变卷积[4],提高对不同尺寸目标的适应能力.以多个头部的方式并行实现目标检测和学习Re-ID特征.在内部轨迹关联上,以交并比(IOU)匹配的方式,将车辆的Re-ID特征指定给对应车辆轨迹,预测串联轨迹在当前视频帧中的位置以完成跟踪.算法有效改善了模型使用基于Anchor的骨干网络学习Re-ID特征不佳而导致的ID切换、检测失效问题,提高了车辆多目标跟踪算法的鲁棒性.
1 相关工作
1.1 联合模型多目标跟踪算法
视频的多目标跟踪对于利用轨迹度量目标的行为有着至关重要的意义.早期采用深度学习网络的多目标跟踪算法都采用了先检测后关联的两阶段范式.例如Yu等[5]提出了一种两阶段算法,使用Faster R-CNN[6]实现目标检测,再使用匈牙利算法对用GoogleNet[7]提取到的特征关联完成跟踪.Xie等[8]通过基于YOLOV3[9]的检测器捕捉目标,再用Deepsort[10]滤波算法实现轨迹关联.由于两阶段范式算法需要两个密集计算网络,这类算法都难以解决跟踪效率低下的问题.
为了提高多目标跟踪效率,使用联合模型多目标跟踪算法成为近期主流的研究趋势.例如,Wang等[11]率先提出了一种联合模型(JDE),通过在YOLOV3检测模型上进行改进,一次性解决目标检测和提取Re-ID特征,在行人数据集上实现了较高水平的跟踪效率.Lu等[12]在RetinaTrack中使用RetinaNet[13]检测器网络作为骨干网络,在联合模型框架下,实现了对车辆的多目标跟踪.使用联合模型的主流改进思路是把两阶段范式算法在关联模型中学习Re-ID特征的任务融入到检测器网络中,以单个网络完成多目标跟踪中的检测和嵌入Re-ID特征的任务,以内部信息交互的方式,匹配轨迹实现多目标跟踪.该类算法与早期两阶段范式算法相比,模型更轻量,算法效率更高.
然而这类算法在改进的方式上引入了新的问题:联合模型所使用的骨干网络都是检测器网络改进而来的,这类骨干网络并不适合学习Re-ID特征.经过Zheng等在文献[14]中的分析发现,这类骨干网络都使用了基于Anchor的检测方法.在检测上,由于使用Anchor将目标检测任务转化为目标与 Anchor 的匹配任务,确实提高了目标检测效率.但在跟踪中,基于Anchor的骨干网络学习Re-ID特征的能力不是最优的,如图1,不同图像块中的多个Anchor负责估计同一车辆的Re-ID特征,这将导致网络的严重歧义.另外,为了提升效率,联合模型中大都使用较大步长的下采样率获取特征图,这对检测来说可以接受,但对于学习Re-ID特征太过粗糙,这引入了量化误差,导致误检的出现.因此必须采取更有效的骨干网络应对Anchor导致的准确率下降的问题.

图1 多Anchor对应目标歧义示例
1.2 Anchor-Free目标检测模型
Huang等[15]为了减少因Anchor数量过多带来的计算压力,在DenseBox中对Anchor-Free的方法做了探索,初步实现了Anchor-Free的目标检测.Zhou等在LAW等[16]提出CornerNet的检测模型基础上提出了CenterNet检测模型,利用中心点获取特征图,给出了高效关键点匹配的检测方法.CenterNet的基本模型结构如图2所示,图像输入后首先通过一个设定步长的卷积单元和的残差单元进行预处理,使图片宽高按r标定的比例进行压缩,输入选定好的特定骨干网络,而后以并行的方式输出三种检测信息预测头部,以边界框回归的方式获得目标的检测结果,其输出的三个预测头部分别如下:
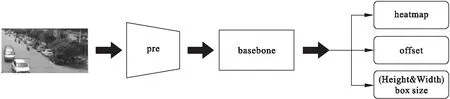
图2 CenterNet目标检测模型
1)热力图,大小为(W/r,H/r,x),输出需要检测类别的物体的中心点位置.
2)中心偏移量,大小为(W/r,H/r,2),对热力图的输出进行精炼,提高定位准确度.
3)目标框大小/宽高信息,大小为(W/r,H/r,2),预测以关键点为中心的目标框的宽高.
热力图和中心偏移量的头部负责完成在高分辨率特征图上对目标进行准确定位,避免了基于Anchor网络出现多个Anchor对应同一个目标的情况,目标框大小(宽高信息)头部输出目标边界框的宽高信息,定位目标位置,提高目标检测的准确率.
在骨干网络的选择上,模型采用了包括残差网络[17]、沙漏网络[18]、深层特征融合网络等进行了实验,其中深层特征融合网络在速度和准确率上取得了良好的平衡,在对人体姿态估计和捕捉目标特征方面优势明显.
2 Anchor-Free车辆联合模型多目标跟踪算法
受到Wang等在文献[11]JDE联合模型及Zhou等在文献[2]检测模型中骨干网络的启发,在利用联合模型提高效率的基础上,本文提出把Anchor-Free检测器网络引入联合模型作为骨干网络以减少Anchor带来的影响.使用添加学习Re-ID特征分支的方式在Anchor-free的深度特征融合网络上进行改进,在此基础上通过IOU匹配完成信息关联,实现对车辆这一特定种类目标的跟踪.
2.1 Anchor-Free联合模型
Anchor-Free联合模型以单网络多任务方式实现车辆多目标跟踪,结构如图3,首先以有序的视频帧作为输入,在数据预处理后,使用可变卷积深度特征融合网络(DDLA),获得以小步长下采样率输出的下采样特征图,减少大步长下采样率带来的特征模糊问题.在上采样过程引入DCNv2可变卷积,提高模型对车辆尺寸及位置变化的适应能力.采用Zhang等[19]对不同目标进行标签分类的思想,在原本的检测器网络上添加更适合车辆目标特征维度(卷积核个数)的卷积层获取车辆目标特征的Re-ID分支,满足联合模型并行输出检测和Re-ID特征的要求,按时间序列进行轨迹链接,完成车辆多目标跟踪.
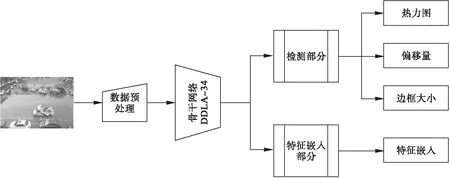
图3 Anchor-Free联合模型结构
2.1.1 可变卷积深度特征融合网络
为了满足联合模型车辆多目标跟踪对于特征图的需求,本文提出一种可变卷积深度特征融合网络(DDLA),并把此网络应用于联合模型骨干网络部分,DDLA网络以小步长的下采样率采样提取不同层次的车辆目标特征信息,用可变卷积代替上采样普通2D卷积方式实现特征图的提取.参考文献[3]中原始DLA-34网络的下采样方式,在下采样过程中,首先以视频帧作Hf×Wf为输入,由base及level0-level5共7个层(layer)实现整个下采样部分.Base-layer、level0-layer利用2D卷积归一化和激励函数对视频帧特征进行初步提取,得到与原始视频帧相同大小的全局特征图FMg:
FMg=Hf×Wf
(1)
其中Hf代表图像特征图高度,Wf代表特征图宽度.
Level1-layer负责对全局特征图进行初次下采样,得到与输出特征图相同大小的1层特征图:
(2)
其中Sd代表下采样率,为了能保证网络对车辆目标特征的提取能力,同时平衡网络的计算量,采用了不同的下采样率进行实验,最终选择Sd=4.
Level2-layer到level5-layer三个下采样过程(如图4所示)充分利用分层特征融合(HDA)结构提取车辆目标的特征信息,下采样得到第i层特征图FMi:
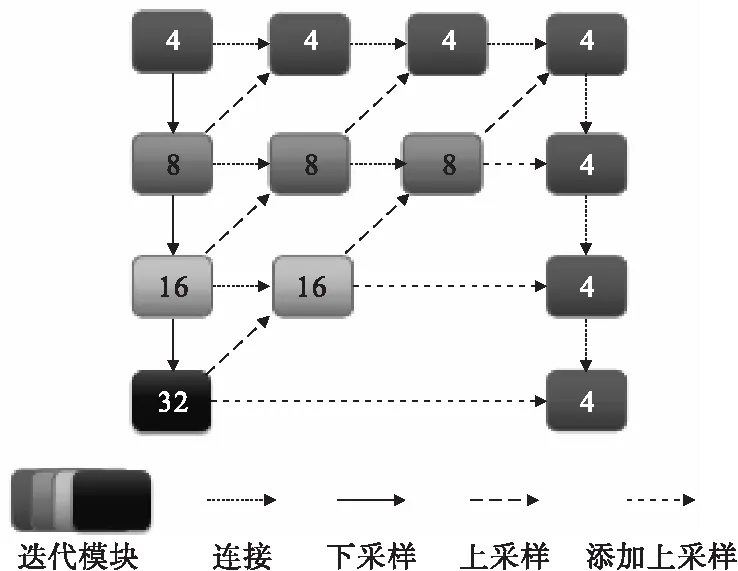
图4 DDLA-34特征融合过程

(3)
在三个下采样过程中,参考了Huang等[20]在DenseNet中的思想,交错连接每个Tree模块与root模块,以提高不同特征图之间的信息交互,通过类似于空间特征金字塔的相互连接方式组合形成整体树形结构,以实现不同尺度的语义空间融合,提高网络在不同层次之间的车辆特征交互能力.
在网络的上采样过程中,本网络应用多个迭代特征融合(IDA)结构实现网络的上采样过程,迭代特征融合结构由project、node,up三个模块组成,为了提高网络在感受野上动态适应因车辆运动而出现的尺寸及形状变化的能力,应用文献[4]提出的最新(Deformable Convolutional Networks v2)DCNv2可变卷积代替了每个迭代特征融合(IDA)模块中的普通2D卷积,在DCNv2可变卷积中,对于给定k个采样点的卷积核,令wk和pk分别表示第k个采样点的权值和预先指定的偏移量.设x(p)和y(p)分别表示输入的特征图x和输出的特征图y中位置p处的车辆特征.调制后的可变卷积可表示为:
(4)
其中Δpk和Δmk分别为第k个位置的可学习偏移量和调制标量.这种对于对偏移量和调制标量的引入能够有效减少普通2D卷积在位置变化上给整体网络计算量带来的压力.
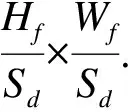
2.1.2 车辆目标检测分支
在骨干网络输出高分辨率特征图后,采用文献[2]中的检测方式利用添加头部的方式实现目标检测,添加的头部分别用来预测每个车辆目标的热力图,车辆中心的偏移量,以及每个不同尺寸车辆的边界框大小.
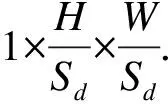
中心偏移头部负责在热力图的基础上更精确地定位目标的位置.由于直接使用原图像提取特征的计算量过大,在模型的骨干网络部分不可避免的要使用下采样的方式来获取信息集中的特征图,这种下采样会造成一定的中心偏移,从而引起中心模糊化的问题,为了解决此问题,通过一个单独的头部对特征图偏移量进行校准,提高模型对于中心点位置的定位准确度,进一步来说,在车辆跟踪算法上,该头部能有效减少学习Re-ID特征时由于检测目标中心模糊化所带来的ID切换问题.
框体大小头部负责估计每个车辆目标边界框的高度和宽度.在此部分由于车辆尺寸比例变化并不固定,本文为了更好地适应车辆目标,在边界框获取时限定了长宽比例不超过1∶10来满足所有车辆的特点.
在实现的三个头部时,本文采用对特征图进行卷积的方式获取特征图的特征映射,首先经过一个3×3卷积分别提取不同头部需要的特征映射,并使用线性激励函数提高其特征的表现,再经过1×1卷积得到最终的对车辆目标检测结果.
2.1.3 车辆Re-ID特征嵌入分支
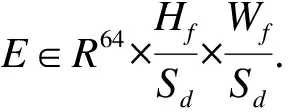
2.1.4 损失函数计算
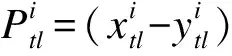
(5)
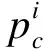
(6)
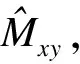
(7)
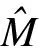
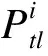
(8)
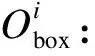
(9)
本文利用文献[2]中L1损失函数计算每个车辆目标的尺寸及偏移量损失,得到目标框的尺寸偏移量损失为:
(10)
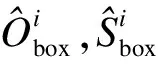
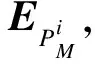
(11)
2.2 跟踪实现
在跟踪实现上,依照视频帧顺序的输入方式,采用Online的跟踪方法.由于只需要内部关联信息,本文采用了标准的关联方法,对于给定的视频,本文的Anchor-Free的联合模型处理每个视频帧,并输出目标边界框和与之对应的重识别(Re-ID)特征.首先根据第一帧中的初始目标边界框初始化多个车辆的轨迹,在接续的视频帧中,根据与之对应的重识别(Re-ID)特征和IOU匹配所测得的距离将目标边界框和现有的轨迹链接起来,对于IOU的匹配,本文采用如下定义:
(12)
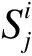
3 实验及结果分析
3.1 实验环境
使用到的Anchor-Free联合模型使用Python3.7进行编译和测试,CUDA版本为10.1,PyTorch版本为1.1,torchversion0.4.0.操作系统为Ubuntu,CPU为intel至强E3,显卡为NVIDIA GTX1080,内存16G,硬盘容量1T SSD.
3.2 实验方法
3.2.1 数据处理
使用以KITTI-tracking[22]和UA-DETRAC[23]进行融合、标准化处理后的联合数据集作为实验数据集,由于联合数据集较大(共22.5 G),选取其中90%作为训练集用于训练模型,10%作为测试集.在标准化过程中,对原视频帧进行剪裁和缩放,统一图像大小至960*540.根据骨干网络的要求,需要输入class(目标类别)、id(目标id)、x_center/img_width(归一化中心列坐标)、y_center/img_height(归一化中心行坐标)、w/img_width(归一化宽)、h/img_height(归一化高).据此要求使用txt格式对文档标准化.每个标定的文档都与图片相对应,保证图像与标定统一.
3.2.2 训练过程
使用可变卷积深度特征融合网络作为骨干网络,采用COCO检测预训练模型中的参数初始化联合模型.在此基础上对算法进行30个训练纪元(epoch)的训练,初始学习率定1e-5,在第29epoach学习率衰减到1e-6,设置批处理大小为12,输入的联合数据集中的视频帧大小为归一化为960×540 特征图大小为240×145,训练时长约为100 h.
3.2.3 评价指标
车辆多目标跟踪的指标需要评估跟踪模型预测目标位置信息的精确程度,跟踪算法随时间产生的轨迹的一致性,以及模型本身的效率.本文参考多目标主流评价体系MOT[24],并根据车辆目标的特点采用如下评价标准:多目标追踪准确率(MOTA)、正确检测比(IDF1)、统计ID切换总数(IDS)、模型检测准确度(TPR)、模型检测帧率(FPS).其中MOTA衡量了跟踪目标的总体准确率,将误检率和错配率结合成一个单独的指标,对整体的跟踪性能给出评估.IDF衡量了ID准确率和ID召回率,体现了模型跟踪的修正能力.IDS衡量了跟踪轨迹更改其匹配的真实身份的次数,体现了其模型跟踪的稳定性.TPR反映了模型对于目标出现的触发灵敏度,衡量了跟踪模型的检测水平,FPS衡量了模型处理视频帧的帧时比例,体现了模型的推理效率.
3.3 实验结果和分析
3.3.1 消融实验分析
在利用UA-DETRAC车辆数据集、KITTI-tracking组成的联合数据集,用不同场景的车辆对本文骨干网络进行训练,递减车辆Re-ID特征嵌入分支使用的卷积层中的卷积核数量,在相同实验环境下训练10个epoch,如表1,本文分别利用256,128,64,32四个不同数量的卷积核数以不同维度提取Re-ID特征,其中使用128个卷积核时,跟踪准确率达到了最高水平,在使用64个卷积核时,仍保持类似的高水平跟踪准确率,而且实现了最好的正确检测比54.6和最少的ID切换数97.当进一步降低卷积核数量时,由于特征维度过少导致提取Re-ID不充分.进一步导致了灵敏度下降,因此本文采用64个卷积核数量,以学习低维度特征的方式来提取车辆特征信息,实验也证明了,以低维度特征提取车辆Re-ID信息的有效性.

表1 不同特征维度实验结果对比
小步长下采样倍率也在实验中被证明更有优势,本文分别在下采样倍率2,4,8,16四个不同步长的下采样率下实现骨干网络,在相同的实验环境下训练10个epoch,如表2,当下采样率的步长为4时,正确检测比达到最好的54.6,同时有着最高的检测灵敏度66.7以及最少的ID切换次数.在跟踪帧率上,借助于联合模型单网络的优势,本文的骨干网络能在较小的4步长的下采样率的条件下,达到以8为步长的下采样率相近的推理速度.当以16为步长实验时,由于层级跳跃过大而导致了下采样特征图信息不完整,影响了整体的跟踪效果.由于步长为2下采样率的推理速度不能满足联合模型的帧率计算,在这里本文没有列出该实验结果.据此实验,本文选择了以4为步长的下采样率实现模型,该实验也有效证明了小步长下采样率对于车辆特征提取的优势,体现了Anchor-Free的网络的轻量化的特点.

表2 不同下采样率实验结果对比
3.3.2 算法对比分析
本文在相同的实验环境下,以联合数据集,分别训练基于Anchor的联合检测嵌入模型(JDE),以及本文所使用的Anchor-Free的联合模型,在保持相同的30个epoach训练循环下,对模型进行测试,其效果分别如图5(a)、5(b)所示,在相同视频帧中,本文所提出的Anchor-Free的联合模型,在跟踪中产生更少的漏检情况.

图5 JDE及本文跟踪效果对比示例
本文进一步在UA-DETRAC数据集上对两阶段模型,JDE以及本文提出的Anchor-Free的联合模型上训练30个epoach,并与在联合数据集上的训练结果汇总,如表3,通过数据分析可知:在UA-DETRAC数据集下训练,本文模型的准确率达到了67.5.同时相比于JDE模型,正确检测比达到了74.3,远高于JDE的66.7,同时ID切换个数也由73个下降到41个,跟踪效率也从两阶段模型和JDE模型的7.6FPS、11.6FPS提高到16FPS.在车辆方向和环境更为复杂的联合数据集下训练,本文的准确率达到了67.2,远高于基于Anchor的JDE的63.8,同时仍保持了高水平的正确检测比73.1,以及较低的ID切换个数114.并且在跟踪效率上仍保持着最高的13.9FPS的水平.实验结果表明,本文的Anchor-Free联合检测模型通过较高的跟踪效率保证了正确检测数,从而得到了较高的跟踪准确率,并且有效减少误检率和ID切换个数.

表3 不同数据集训练结果对比
4 结束语
对于车辆多目标跟踪问题,在追求速度和准确率的同时,目前的单步法算法并没有很好地解决在Re-ID部分由于下采样倍率所造成的目标Anchor和目标不一致所导致的歧义情况,导致在车流量较大,车辆通行较为复杂的情况下,车辆相互遮挡,相似同型号车辆相互交错时,产生ID切换的问题,本文利用Anchor-Free的联合模型对车辆重识别特征的学习实现了跟踪,既明确了车辆本身的位置和轨迹,提高了跟踪准确率,同时也保证了更好的检测效率.实验表明,本文算法有效地改善了Anchor所带来的ID切换、误检,在车辆多目标跟踪中表现出了良好的效果和性能.由于本文在内部关联只使用了简单的匹配的关联算法,因此在接下来的工作中将对不同的匹配算法进行尝试,以进一步完善模型,同时在有噪声的视频下进行实验,以期在不同的环境下提高算法的鲁棒性.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
实用手外科杂志(2022年2期)2022-08-31
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
当代陕西(2020年16期)2020-09-11
