
基于人脸姿态估计的多角度虚拟眼镜试戴技术
2021-09-02 00:23:44付东翔
电子科技 2021年9期
刘 轩,付东翔
(上海理工大学 光电信息与计算机工程学院,上海 200093)
随着互联网时代的发展,方便快捷的线上购物模式逐渐取代了传统实体线下销售模式,成为了新的主要消费方式。眼镜产品不仅具有实用性,其时尚性也受到消费者的重视。网络配镜平台基本缺乏专业化的虚拟试镜功能,使其欠缺真实化和私人化特征。 因此,提高虚拟眼镜试戴的时效性和真实性就成为了本文的主要研究目的。
目前已有一些关于虚拟眼镜试戴的研究与方法,这些方法各有优劣。文献[1]中的方法可精准确定眼镜佩戴位置,但其实验结果仅显示正面试戴,人脸旋转后眼镜不能较好地贴合面部。文献[2]使用三维人脸模型配合Kinect深度相机进行试戴操作,技术上不具备普适性。文献[3]中,非正面人脸内人眼定位精确度不高, 抗干扰能力较差,鲁棒性差。文献[4]所提方法利用手势估计人脸姿态,同时使用OpenGL处理三维眼镜模型,方法复杂且计算量较大。文献[5]针对单幅图像进行试戴,算法高效,适应性强,但试戴效果真实性差,实用性不广。文献[6]所提方法试戴速度快,但仅能处理头部左右旋转情况,且眼镜模型处理失真,佩戴效果一般。通过上述方法的对比分析,可知欲实现较为真实的眼镜虚拟试戴,仅检测平面人脸图像关键点位置信息是不够的,还需获取头部姿态转动信息,解决现实的人脸图像与虚拟的眼镜图像之间合理化融合的难题,才能精准实现三维空间内的多角度虚拟眼镜试戴,增强现实感。
本文虚拟试戴系统设计流程如图1所示,以下将对各部分原理逐一阐述。
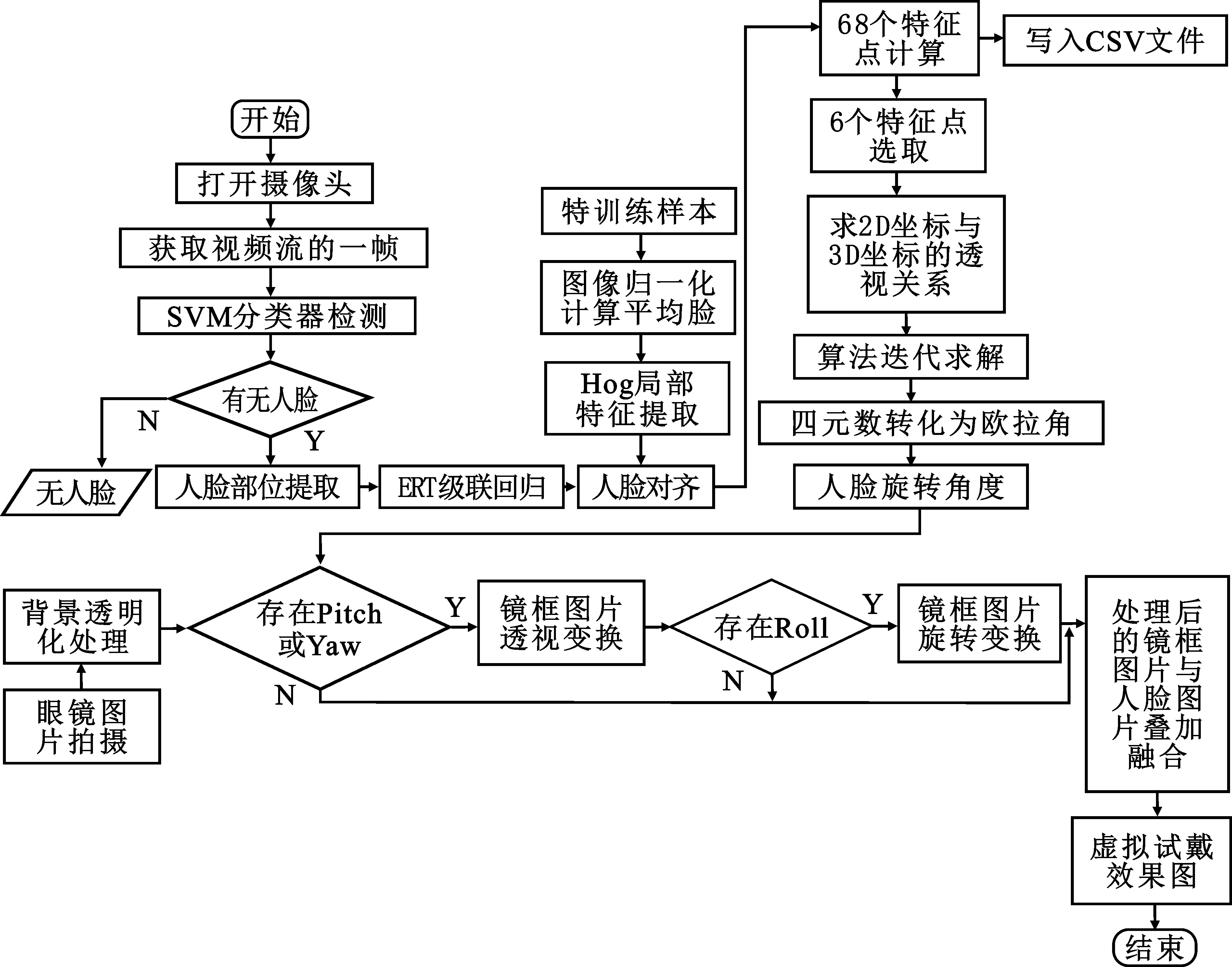
图1 虚拟试戴系统总体设计流程图Figure 1. Overall design flow chart of virtual trial system
1 视频流实时人脸动态姿态估计
根据检验依据的基本信息类型,人脸检测大致可以分为以下4类[7]:基于先验规则的方法、基于灰度信息的方法、基于几何形状的方法、基于机器学习[8]和深度学习[9-10]的统计类方法。
本文眼镜试戴算法的核心是精确的面部特征点定位。该要求对算法的鲁棒性要求较高,故本文选用机器学习方法中的级联回归树算法(Ensemble of Regression Trees,ERT)[11]进行人脸对齐,进而通过残差网络和支持向量机(Support Vector Machines,SVM)分类器实现对人脸面部特征点的精确定位。
1.1 ERT级联回归树定位单幅人脸图像特征点
ERT算法通过创建级联残差回归树(Gradient Boosting Decision Tree,GBDT)逐渐将人脸形状从当前形状回归到真实形状。每个GBDT的每个叶子节点都存储着残差回归,如果输入落到一个节点上,则将残差添加到输入中以进行回归, 最后将所有残差叠加在一起,即可实现面部对齐的目的。
当获得图像时,该算法创建初始形状,即首先估计一个粗糙的特征点位置,然后采用梯度增强算法来减小初始形状的二次误差与基本真值之和,使用最小二乘法将误差最小化,并获得每个级联的级联回归因子。该算法的核心计算式如式(1)所示。
(1)
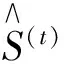
与LBF(Local Binary Features)[12]不同,ERT是在学习Tree的过程中,将shape的更新值ΔS直接保存在叶结点leaf node中。所有学习到的树之后的起始位置S表示形状加上所有过渡,叶节点的ΔS可以获取人脸的最终关键点位置。
通过建立图像金字塔,对每一级图像执行HOG(Histogram of Oriented Gridie)特征提取, 经SVM[13]分类确定图像中是否存在面部,然后结合GBDT级联回归残差网络。对单幅人脸图像特征点定位结果如图2所示。

图2 不同角度下的特征点定位Figure 2. Location of feature points at different angles
同时将定位出的68个特征点信息计入CSV文件,部分特征点位置信息如表1所示。
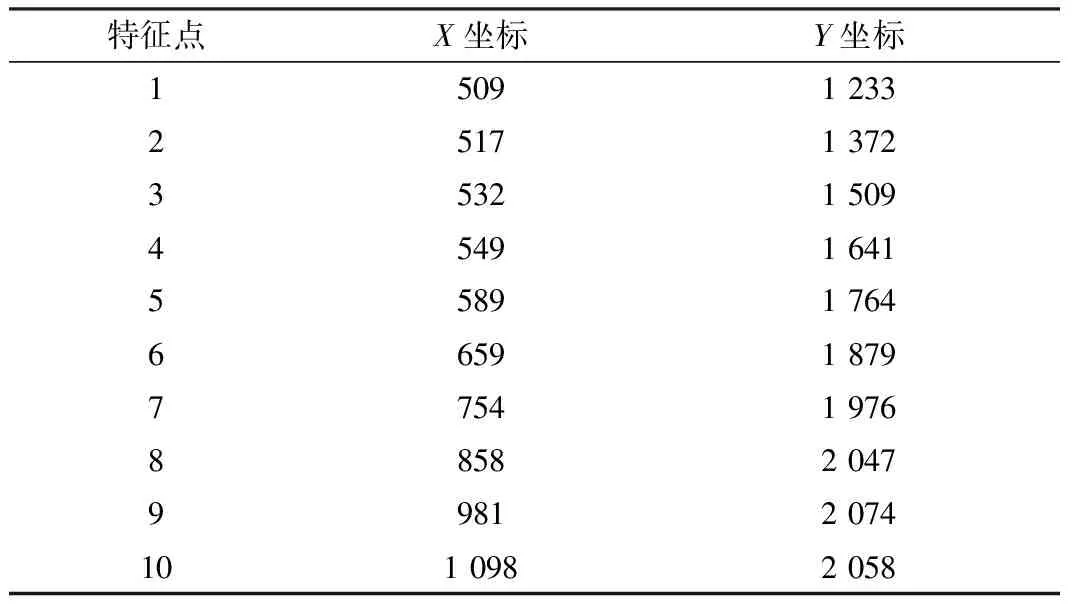
表1 部分特征点位置信息
由图2可以看出,在输入单幅人脸图片时,该算法不仅能精准定位正面图像的人脸特征点,而且在侧面、歪斜、外界光线不佳等背景干扰较多的复杂情况下,仍能较为精准地定位面部特征点。
1.2 人脸特征点动态定位及实时多角度姿态估计
用3个欧拉角(Pitch、Yaw、Roll)[14]表示本文的头部姿态信息。
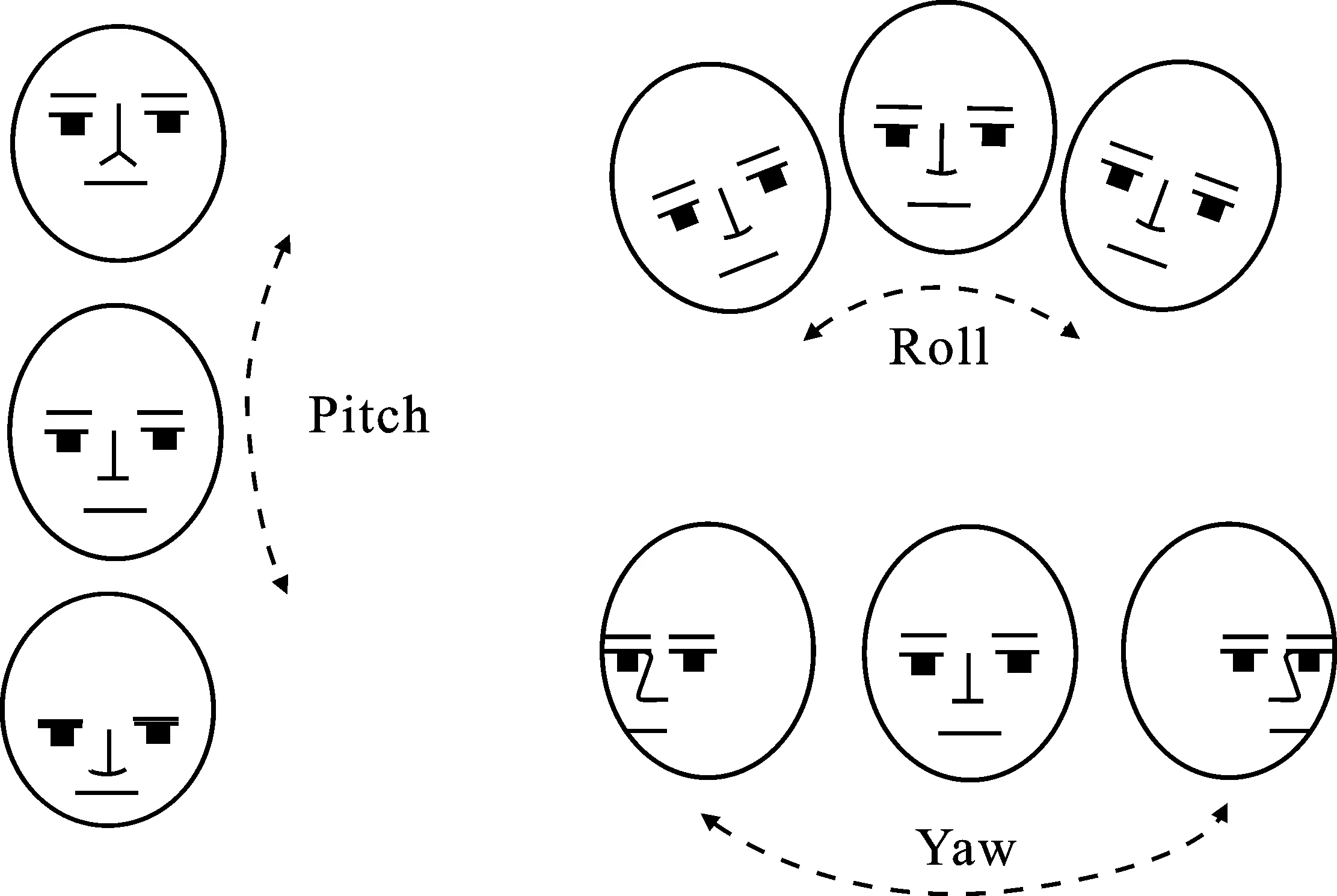
图3 三维姿态欧拉角Figure 3.Three dimensional attitude Euler angle
章节1.1中已实现二维平面的特征点定位。如果要确定三维人脸的姿态估计,一般都需要人脸3D模型。文献[4]运用了3D模型来实现虚拟试戴,试戴效果较好,但该方法模型处理棘手且运算复杂,时效性和适用性较差。
本文首先定义一个3D脸部模型,取该模型6个关键点(鼻尖、下颌、左眼角、右眼角、左嘴角、右嘴角),然后采用章节1.1ERT算法检测出二维图片中对应的6个脸部关键点。2D平面与3D模型的映射关系如图4所示。

图4 2D平面与3D模型的对应关系Figure 4. Correspondence between 2D plane and 3D model
本文规定俯仰角Pitch为X轴,偏转角Yaw为Y轴,滚动角Roll为Z轴。脸部完全平行于摄像头时,Pitch、Yaw、Roll均为0°。随着脸部的转动,其余角度下的Pitch、Yaw、Roll值如表2所示。
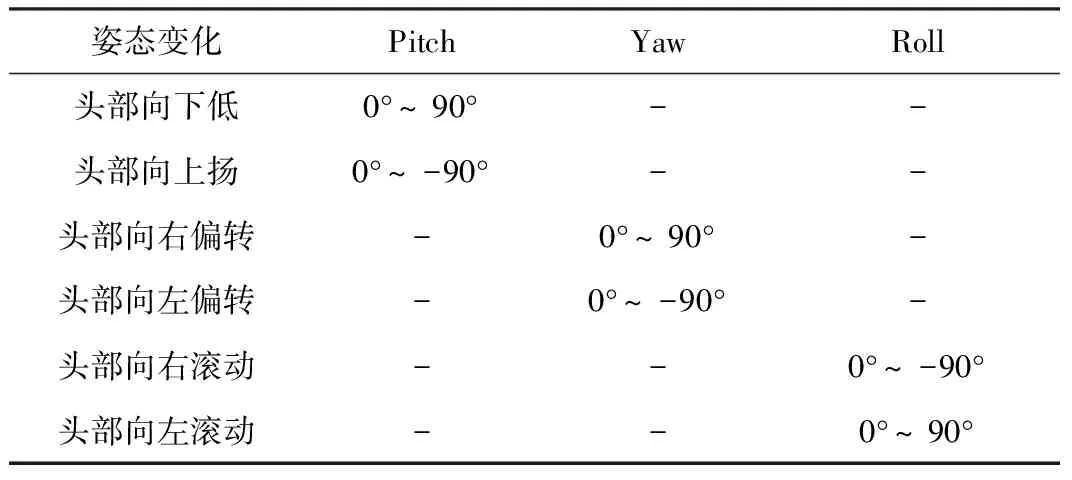
表2 姿态变化后的Pitch、Yaw、Roll范围变化
人脸模型的6个关键点的3D坐标标定值如表3所示。
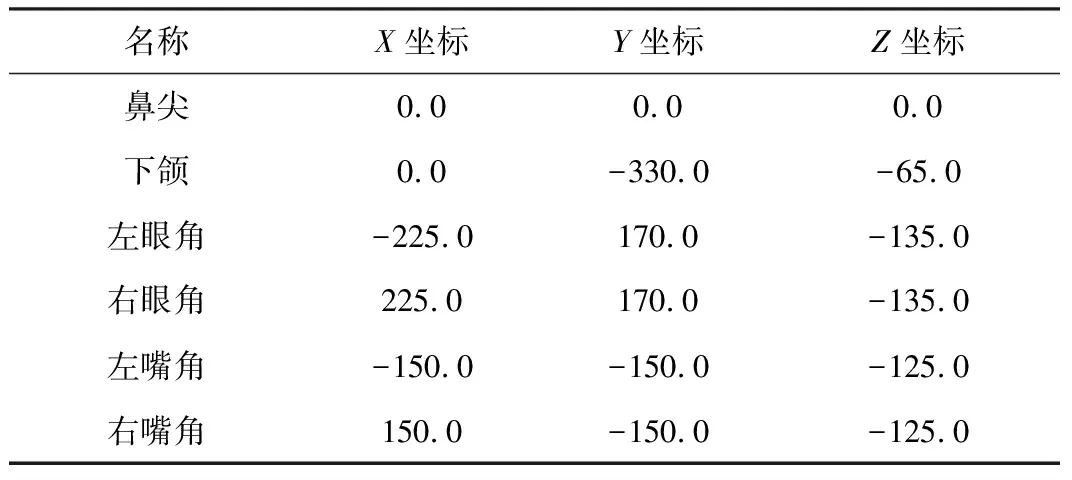
表3 3D坐标标定值
在计算机视觉中,物体的姿态是指相对于相机的相对取向和位置,可以通过相对于相机移动对象或移动相机来更改物体的三维姿态。实际上,欲估算3D物体的3个欧拉角,需要3个坐标系, 即世界坐标系、相机坐标系和二维图像坐标系。世界坐标系存储3D人脸模型的6个关键点坐标,用文献[15]中所提方法标定完的标准相机,将相机坐标系中的3D关键点投影到二维图像平面上,投影原理如图5所示。
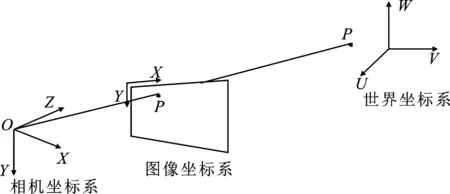
图5 成像投影关系Figure 5. Image projection relation
3D物体在空间中相对于相机只有两种刚体运动:平移和旋转。如图5所示,O是相机中心,世界坐标系内存在一个3D点P(U,V,W),相机坐标系存在一个3D点Q(X,Y,Z),P点与Q点的投影关系通过一个3×3的旋转矩阵R和一个3×1的平移向量t得到,如式(2)所示。
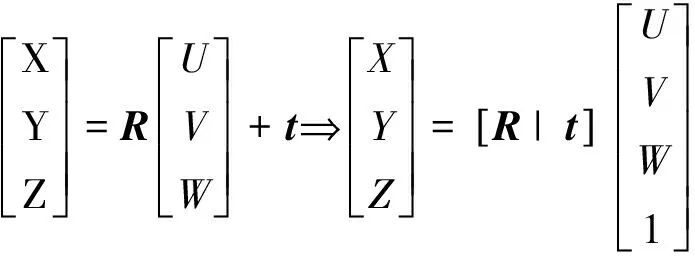
(2)
带入R和t,即
(3)
在不考虑相机参数畸变的情况下,二维图像坐标系中的p点坐标(x,y)由式(4)得出
(4)
带入式(3),即得式(5)。
(5)
相机的4个内参fx、fy、cx和cy可由文献[15]的方法算出。对实时视频提取某一帧图像,对该帧的图像进行特征点定位,获取这一帧的6个关键点二维平面坐标,带入式(5)。同时已知三维头部模型的6个关键点坐标,即可求得该帧对应时刻的头部旋转矢量R和平移向量t。
求得的旋转矢量R并非欧拉角Pitch、Yaw、Roll,故还需先将R转化为四元数,再转化为Pitch、Yaw、Roll的欧拉角。转化过程如下。
定义ψ、θ、φ分别代表绕Z轴、Y轴、X轴的旋转角度,分别为Yaw、Pitch、Roll,空间关系如图6所示。
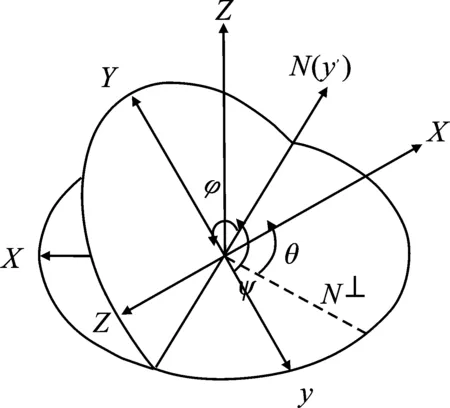
图6 自由度空间表示Figure 6. Space representation of degrees of freedom
该组四元数由旋转轴和绕该轴的旋转角度得出
(6)
式中,α是绕旋转轴旋转的角度;cos(βx)、cos(βy)、cos(βz)分别为旋转轴在x、y、z方向上的分量。
将该组四元数转化为此帧下对应的欧拉角可求得当前帧下的Yaw、Pitch、Roll弧度值。再将弧度值转化为度,即可得到3个旋转方向的角度值。
(7)
2 三维镜框模型处理及图片合成
2.1 基于二维图片的三维眼镜模型处理
常见的镜框处理方法为使用三维建模软件构建眼镜的三维模型,根据人脸旋转角度对三维镜框进行角度变换,再投影至二维平面与人脸图像叠加融合。文献[16~17]使用3Ds MAX软件绘制眼镜的三维模型,保存为obj文件,运用OpenGL读取眼镜obj文件纹理信息,再投影至二维平面进行图像融合。 但该方法耗费时间长、计算量大且效率较低。对于不同的眼镜模型需要对应不同的obj文件,但实际上对于工业生产而言,并不能做到每一幅眼镜都提供标准的obj文件。若实验者自己绘制眼镜模型,则工作量巨大,与虚拟试戴要求的高时效性理念不符。因此,本文提出了一种基于二维图片的眼镜三维模型替代方法,使用普通照相机拍摄镜框作为眼镜图像,从前视、左视、右视3个维度垂直拍摄眼镜图片。
组成眼镜的3张图片为:正面框架、左侧支架、右侧支架。为了保证眼镜图片的真实性,提高三维眼镜模型的现实感,这3张图片应能够刚好实现完整拼接,图像长宽比应一致。为了提高算法效率,方便对图片进行透视投影变换,还需人工手动将3张图片中非眼镜模型部分进行背景透明化处理,处理结果如图7所示。

图7 透明化处理后的眼镜图片Figure 7. The picture of the transparent glasses
2.2 基于姿态估计的眼镜透视变换
章节1.2已经通过姿态估计得到了头部转动的Yaw、Pitch、Roll角度值,当头部存在转动时,眼镜也会进行相应角度的转动,产生一定程度上的形变才符合视觉系统。而眼镜的“远小近大”需要通过透视变换来实现,需要已知非共面的4对对应点来确定透视变换矩阵。
本文选定正面人脸图像的鼻梁中线(即图2中特征点28、29、30、31的拟合直线)作为眼镜纵向轴,将两个外眼角的连线作为眼镜横向轴,两个直线交汇处Q为正面镜框图片的中心点,特征点1和17的Y轴距离作为眼镜的宽度,对眼镜进行适当缩放。眼镜图像上的A、B、C、D点与人脸图像上的A、B、C、D点一一对应,组成4对对应点,如图8所示。
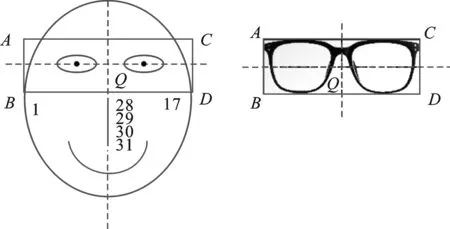
图8 面部和眼镜图像正四边形对应关系Figure 8. Face and glasses image quadrilateral corresponding relationship
以左右旋转为例,当正面面向相机时,人脸的各点和相机的距离均相等,故AB=CD。当人脸发生旋转时, 离相机近的一侧会变长,远的一侧会变短,所以当头部向左侧旋转时,AB
本文采取己求得的Yaw值,确定Yaw值与AB、CD长度的比例变换关系,求出左右旋转任意角度后,A′B′与C′D′的长度大小,从而得出4个点的对应坐标。
以图9中CD边为例,当头部向左旋转30°时,CD发生形变,变为C′D′,式(8)可计算平均每旋转1°时CD缩小的比例
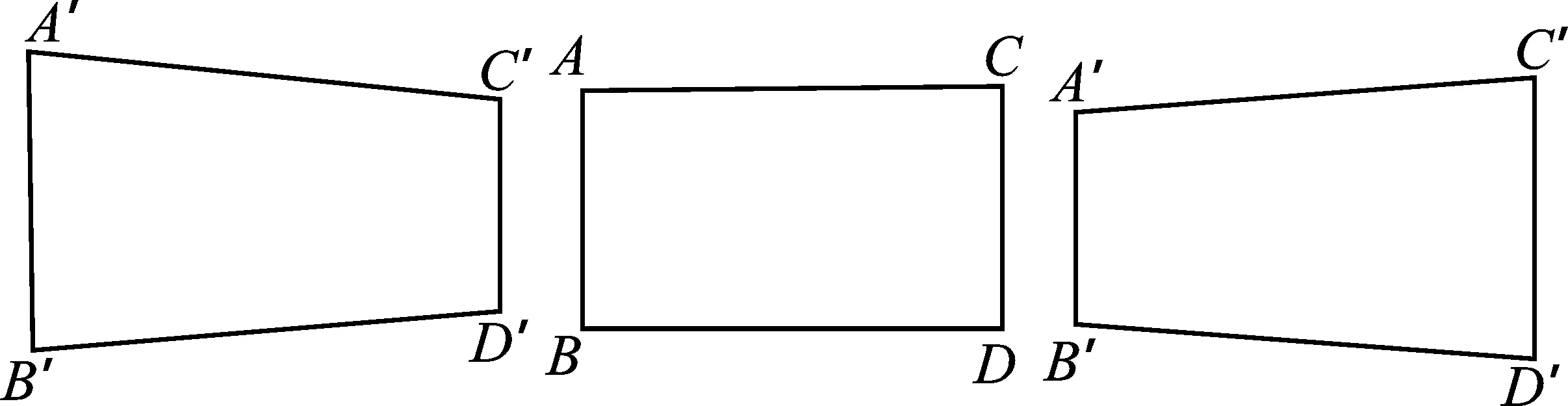
图9 旋转后的透视变化Figure 9. Perspective changes after the rotation
(8)
式中,s为平均每旋转1°时CD所缩小的比例值。
同理,当头部上下晃动时,AC与BD随着晃动角度也存在“远大近小”的现象,以AC边为例,变化后的A′C′与AC存在如下关系
(9)
当人脸存在滚动变化时,仅需对正面眼镜图像进行旋转变换即可,旋转角度等同于Roll值。
处理完眼镜图像后需要对要贴合的人脸图像进行ROI掩膜处理[18],确定人脸图像的ROI区域,将该区域选做蒙版。提取眼镜图像的4通道值,以第4通道Alpha值为判断,剔除Alpha值为0的眼镜图像部分,将Alpha值为1的眼镜图像区域的RGB值写入蒙版区域,即可完成眼镜模型与对应角度的人脸图片的叠加融合。图片合成效果即为虚拟试戴效果图。
3 试戴实验结果对比分析
3.1 算法精度测试与对比
本文选用带有关键点位置和姿态信息数据的AFLW[19](Annotated Facial Landmarks in the Wild)人脸公开数据库测试姿态估计算法精度。AFLW人脸数据库包含18 398张现实世界的被采集者图像,其图片的分辨率、背景、光线各不相同,被采集者的年龄、种族、表情、姿态均存在变化,其中水平、摆动和竖直方向角度变化范围均为-90°~90°。
本文测试集为800张随机抽取的图像,当面部各关键点存在遮挡情况下,算法无法检测。为保证实验结果的有效性,剔除了所有存在关键点被遮挡的图像,最后测试集为660张人脸图像。
本文算法实时动态姿态估计效果如图10所示。

图10 姿态估计效果图Figure 10. Attitude estimation renderings
测试数据如表4和表5所示。表4中统计了头部不同姿态变化范围内的平均误差,角度范围为±15°~±60°;表5中统计了各误差范围内覆盖的3种头部姿态变化图片数量占比。
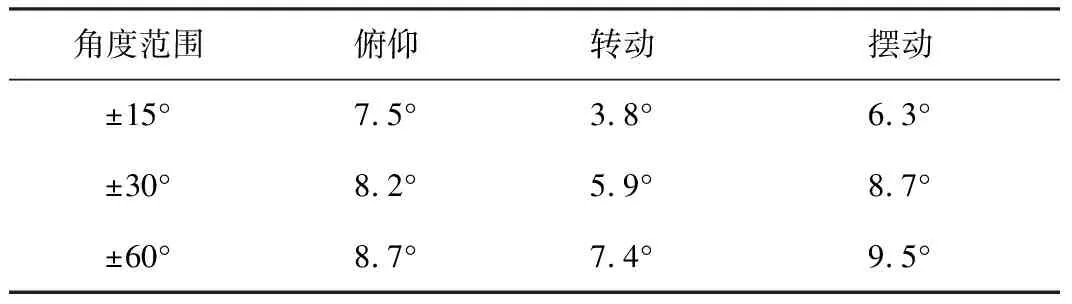
表4 姿态估计平均误差
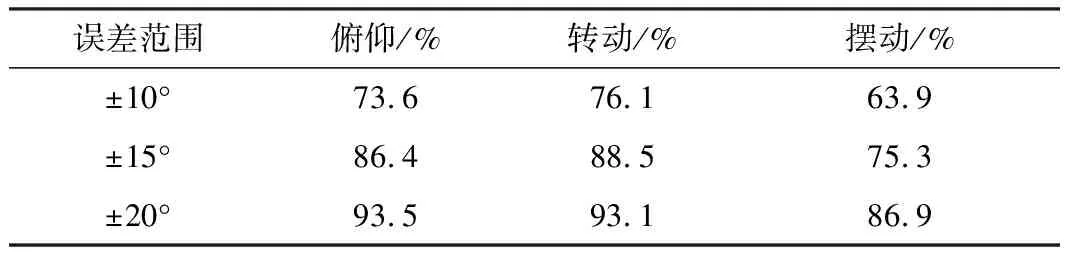
表5 姿态估计误差统计结果
由表4可知,本文提出的基于ERT算法的姿态估计算法在转动角度范围-60°~60°内平均误差约为8.8°。由表5可知,93%以上的转动和俯仰图像角度估计及86%以上的摆动图像角度估计误差范围为±20°,基本满足虚拟试戴技术的检测精度要求。
3.2 虚拟试戴效果对比与分析
本文实验算法环境如下:CPU为Intel(R) Core(TM) i5-6300HQ 2.30 GHz,内存16 GB,Windows10操作系统,编程语言Python3.7,PyCharm集成开发环境,OpenCV 4.1.1库。
在此环境下选取了部分包括3种姿态变化较为典型的视频帧图像对虚拟试戴的效果进行测试。实验结果如图 11 所示,横向3张图片为一组,最左侧为视频原图,中间为文献[20]方法效果图,最右侧为本文算法试戴效果图。
由图11可知,本文提出的虚拟试戴技术在试戴者头部相对于采集相机在正面(如第1行)、转动(如第2行)、俯仰(如第3行)、摆动(如第4行)以及背景复杂有干扰物、光线强度不均匀、存在少量头发遮挡的情况下均能较为准确地实现三维试戴,对于遮挡关系及虚实融合的处理自然逼真。文献[20]中的方法仅能实现水平转动情况下的虚拟试戴,并非三维空间的多角度试戴。而本文提出的算法能实现三维试戴,针对俯仰和摆动情况下仍能较好地实现对应角度的虚拟试戴,三维虚拟试戴精度更高,立体效果较好,虚实基本无缝融合,试戴真实感更强。

(a) (b) (c)图11 试戴效果对比图(a)视频原始图 (b)文献[20]方法 (c)本文方法Figure 11. Comparison of trial effect(a) Original video images (b) The method of literature[20](c) The proposed method
本文最后统计各模块运行时间,处理一帧图像各模块的平均运行时间如表6所示。

表6 各模块运行时间统计
从表6中可以看出,该虚拟眼镜试戴系统处理一帧图像的时间约为20 ms,则试戴时视频的帧率可以到50 frame·s-1,基本满足系统对实时性的要求。
4 结束语
本文通过对人脸检测、面部特征点定位及头部姿态估计的研究,提出了面部特征点精确定位和头部三维姿态精确估计方法。根据二维图片替代三维眼镜模型,提出基于三维旋转角度的眼镜透视变换方法。综合以上两种方法,提出一种基于三维空间的多角度虚拟眼镜试戴技术。实验结果表明,头部姿态估计精确,虚拟试戴效果逼真,三维立体效果较好,能根据空间旋转角度实现三维多角度试戴。由于不用读取特定的三维镜框模型文件,试戴系统运行速度较快,能较好地满足当前眼镜虚拟试戴需求的时效性和真实性,因此具有良好的应用价值。
当前虚拟试穿试戴领域研究主要集中在衣物穿搭方面, 虚拟眼镜试戴领域研究较少。下一步工作将集中解决两方面的问题:(1)人脸特征提取精度有待提高,需进一步降低人脸关键点定位检测误差,提高算法鲁棒性和适用性;(2)合成图像缺少现实中的光照阴影效果,需进一步提高合成图像的真实感。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16 07:36:56
今日农业(2021年8期)2021-11-28 05:07:50
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
基层中医药(2021年1期)2021-07-22 06:56:44
军事文摘(2020年22期)2021-01-04 02:16:38
动漫星空(2018年9期)2018-10-26 01:17:14
天津医科大学学报(2015年2期)2015-12-22 09:24:34
发明与创新(2015年33期)2015-02-27 10:40:09
中国卫生(2014年2期)2014-11-12 13:00:16
奇闻怪事(2014年5期)2014-05-13 21:43:01
