
基于特征优选的随机森林算法在湿地信息提取中的应用
——以湖北洪湖湿地自然保护区为例
2021-09-02 09:25厉恩华王学雷张莹莹
华中师范大学学报(自然科学版) 2021年4期
夏 盈,厉恩华,王学雷,张莹莹,杨 娇,2,周 瑞
(1.中国科学院精密测量科学与技术创新研究院,环境与灾害监测评估湖北省重点实验室,武汉 430077;2.中国科学院大学,北京 100049;3.郑州师范学院地理与旅游学院,郑州 450044)
湿地处于陆地与水域之间的过渡地带,是具有复杂景观空间结构和变化过程的重要生态系统,在抵御洪水、调节径流,改善气候、控制污染,美化环境和维护区域生态平衡等方面有其它系统所不能替代的作用[1-2].近年来由于气候与地质灾害,错误开发、城市规模加速扩张导致人地矛盾日益突出等因素[3],使得湿地功能受到严重威胁,甚至部分湿地丧失.实时精确获取湿地信息对研究湿地生态功能具有重要意义.因此,优化提取湿地信息的方法显得尤为重要.
遥感领域相关技术不断发展成熟,使得遥感技术在湿地信息提取的研究中得到了广泛应用.国内外相关学者根据不同的分类方法开展了湿地相关研究,Chen[4]等人利用多期Landsat-TM影像数据提取植被指数及缨帽变换后,对比监督与非监督等方法对加利福尼亚州北部地区的湿地与森林植被类型进行整体精度分析;卢柳叶[5]等人利用Landsat-TM影像,结合光谱单元信息和纹理特征建立BP神经网络分类模型;邹青青[6]等人利用Landsat8多光谱影像,采用支持向量机、决策树和面向对象分类法对淮河流域蚌埠段湿地信息提取.上述分类方法主要集中在分辨率较低的影像上提取,基于多特征变量的优化研究较少.
新数据源的出现为湿地信息优化提取提供便利.Sentinel-2作为新的开源数据,具有系统的全球地面覆盖,重访周期5 d,高空间分辨率、以及特有的红边波段等优势,提供诸如土地利用及土地覆被状态与变化、湿地信息提取、森林监测和陆地测绘等服务[7].但在利用Sentinel-2数据的特征集时,由于特征间的相关性容易造成数据冗余使得分类精度降低,如何优化选择特征变量组合起着至关重要的作用.随着数据科学与遥感出现相协调一致化的趋势,机器学习在遥感和地球观测领域中普及[8],利用机器学习方法进行湿地信息提取并综合多种特征变量的优化是今后湿地信息智能化提取的重点和难点之一[9].随机森林算法是使用最广泛的机器学习算法之一[10],随机森林算法不仅可以进行分类与回归分析,而且适用于高维复杂数据集,能自动判别变量的重要性,给出变量间的依赖关系,易于结合专业知识解释[11].
本研究以位于长江中游具有典型性和代表性的重要内陆湿地和淡水生态区域——湖北洪湖湿地自然保护区为研究区,运用随机森林算法模型,提取Sentinel-2A数据的光谱、植被指数、水体指数、红边指数、纹理等特征,并对上述特征进行重要性评估.根据特征的重要性进行优选组合,比较不同的分类方案下的精度差异,验证新数据源、新特征集下基于特征优选的随机森林算法在湿地信息提取的可行性,为湿地变化监测系统提供基础数据,在湿地科学管理与生态保护等方面以期提供科学依据.
1 研究区概况
洪湖(29°38′~29°59′N,113°11′~113°28′E)地处长江中游北岸,位于湖北省东南部,系长江和汉水支流东津河之间的大型浅水洼地壅塞湖,现存湖泊面积348.2 km2[12].洪湖属于典型的亚热带湿润气候,四季分明,光能充足,降水充沛,热量丰富,年平均气温15.9~16.6℃,年平均降水量1 000~1 300 mm,无霜期长,一般在250 d以上.洪湖作为长江中下游地区典型的内陆淡水湖泊湿地,于2008年列入国际重要湿地名录,2014年晋升为国家级自然保护区.洪湖作为天然的湿地物种基因库,生物多样性丰富,植被以水生和湿生植被为主,以人工栽培植被和疏林草植被为辅.随地貌差异和水分梯度的影响,研究区(图1)的植被依次呈现湿生植物、挺水植物、浮叶植物、沉水植物等多种生态类型.
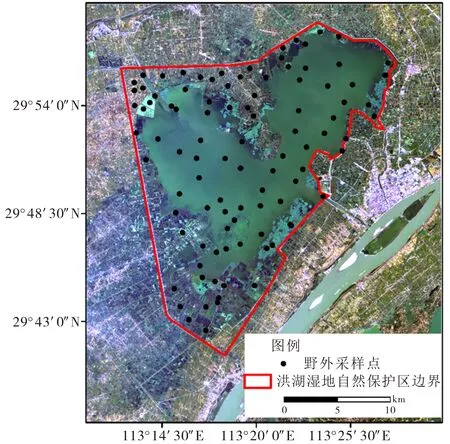
注:背景图为2019-09-30 Sentinel-2A影像432波段组合.图1 研究区位置Fig.1 Location of the study area
2 数据和方法
2.1 数据来源与预处理
Sentinel-2卫星是欧空局(ESA)哥白尼计划中发射的第2组卫星,其搭载的MSI载荷共包含13个光谱波段.这13个光谱波段在空间分辨率范围为10 m、20 m、60 m范围内涵盖了从可见光、近红外、短波红外的电磁波段,各波段具有不同的特点和用途[13].本研究利用的Sentinel-2A影像数据通过美国地质调查局(USGS)网站(http://earthexplorer.usgs.gov)下载获取,影像获取时间为2019年9月30日,研究区内无云且影像质量良好,利用Sen2cor2.8插件进行大气校正,并利用SNAP软件对大气校正后的产品重采样至10 m的空间分辨率,转换至常用遥感软件可处理的格式.在ENVI 5.3软件下,将研究区边界叠加,对其进行裁剪.
2.2 湿地信息提取
利用Sentinel-2A数据的丰富的光谱信息及空间信息,提取光谱特征、指数特征以及纹理特征,并利用随机森林算法对特征的重要性评估,将特征优选后的随机森林分类结果与特征优选前的结果以及传统的监督分类结果比较和精度评估.本研究的技术流程如图2所示.
2.2.1 样本选取 本研究的训练样本主要来源于GPS定位后的野外实地勘查数据和由Google Earth 高分辨率影像目视解译的湿地景观类型图,保证各地物类型测试样本点不少于400个.以上数据构成训练样本用于湿地信息提取的不同分类方案下分类器的建立.本研究的验证样本来源于2019年10月洪湖野外实地采样点,并参考Google Earth高分辨率影像选择验证样本,各类型验证样本点均不少于100个(其中其他用地面积较小,验证点小于100个),总计1 546个验证点,用于分类精度的验证.
2.2.2 湿地分类方案 参照土地利用/土地覆被分类系统[14]、湿地分类和湿地景观分类研究[15],基于洪湖湿地地表特征和已有研究中的分类体系[16],通过综合分析与对比,建立了研究区内的分类体系,划分为以下7类:湖泊(开阔水体)、浮叶及挺水植被(以莲、菰、浮萍、菱群落等湿生植物为主,)、沉水植被(以穗花孤尾藻、金鱼藻为优势种)、耕地(水田、旱地)、坑塘(封闭水体,人为开挖的土埂相间的规则水体)、建设用地(城镇用地、工交建设用地、农村居民点)和其他用地(湖岸滩涂、裸地及坑塘周边分布的低湿生植被覆盖的土埂、田埂).
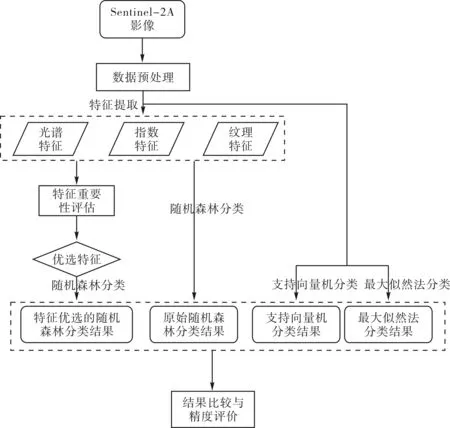
图2 技术路线图Fig.2 Technology road map
2.2.3 特征提取 为达到信息增强的目的,对原始影像进行主成分分析,其中第一主成分包含所有波段中90.56%的方差信息.仅选取第一主成分采用灰度共生矩阵方法提取纹理特征,根据大量试验效果,设置滑动窗口大小为5×5,步长为1,基于二阶概率统计提取5种常用的纹理特征.为提高湿地信息提取的精细度和准确度,提取了10个光谱特征、13个指数特征共28个特征,提取的特征集详细说明和公式见表1.
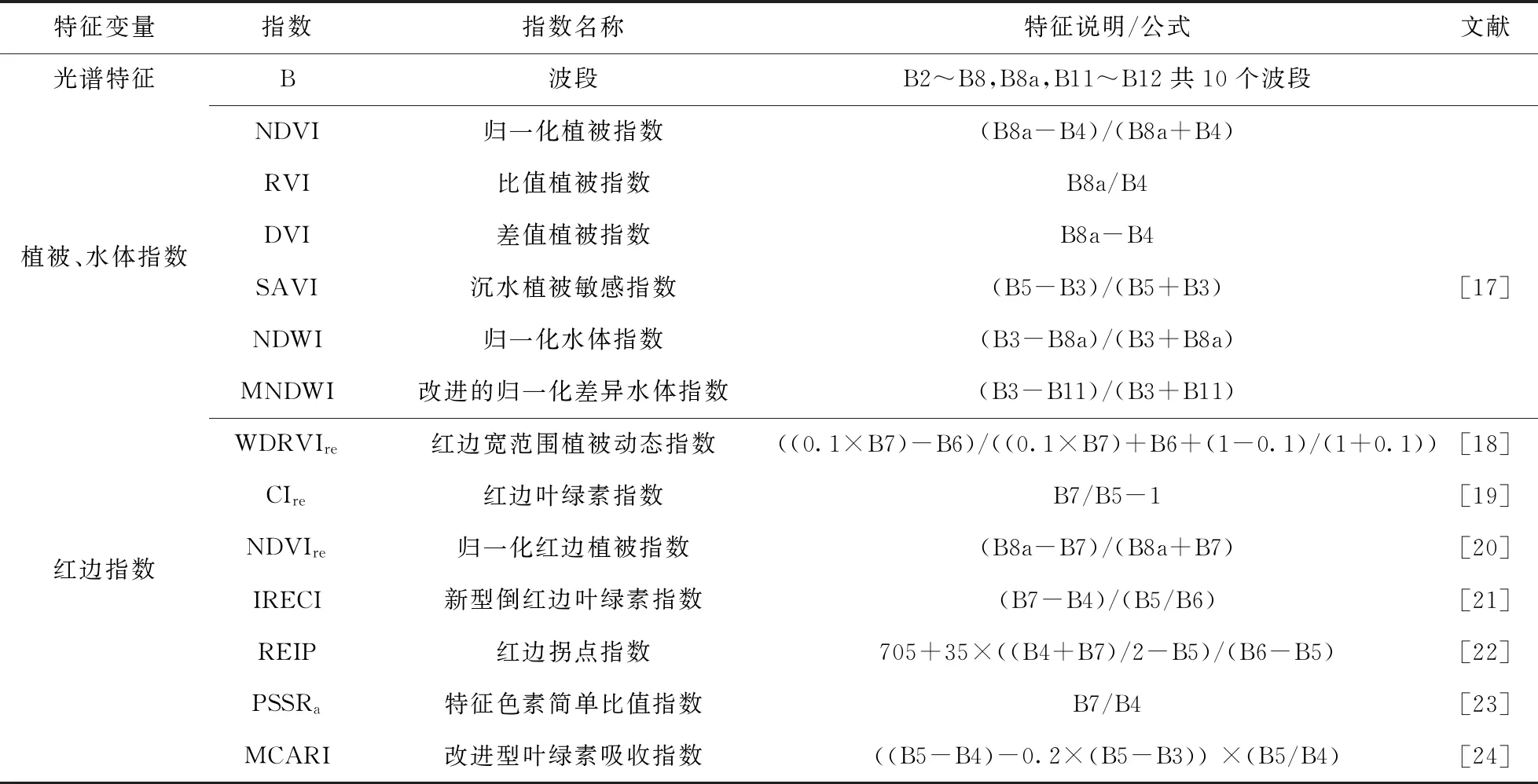
表1 提取特征变量集说明Tab.1 Description of extracted feature variable set

续表1
2.3 随机森林分类算法
随机森林算法是由Breiman等人发明的基于训练样本和特征集的以决策树为基本分类器的一种机器学习算法,它包含两种重要的方法:随机特征子空间和袋外估计[25].
随机森林算法的基本原理是:
1)通过bagging方式随机并有放回的抽取原始样本种的N个样本构成新的训练样本,当N足够大时,其中约有1/3的样本不在训练样本中,这类数据被称为袋外(out of bag,OOB)数据.
2)并根据Gini系数最小原则下通过随机选择N棵决策树内部分裂后的每个节点变量的子集来构建多个Cart决策树并组成随机森林;其中Gini系数定义如下:
(1)
式中,T为给定数据集,Ci为随机选择一个样本并认定为某一类别,f(Ci,T)/|T|为所选样本为Ci类别的概率.
3)生成的随机森林分类器对数据进行分类,对于精度估计,当每个样本属于OOB样本时,每次都会统计其投票数,多数表决的投票将决定分类类别,OOB样本由于未参与建立决策树,可用来估计预测误差,利用OOB误差评估模型性能及量化变量的重要性[10,26].变量的重要性定义如下:
(2)
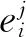
2.4 变量的重要性评估与优选
特征变量重要性的评估优选以及湿地信息提取的分类结果主要由EnMAP-Box工具包实现,EnMAP-Box是一款由德国环境制图与分析计划项目组基于IDL(interactive data language)开发的处理高光谱数据的工具包.为确保分类准确度和运行时间成本,在EnMAP-Box工具包设置的参数中,默认抽取的特征个数(M)为总特征个数的算术平方根,设置决策树数量(N)为1 000.
采用随机森林算法对所有特征进行重要性评估,对得到的特征重要性得分按降序排列,逐一累加按降序排列的特征变量,首先选取重要性得分最高的特征,然后选取重要性得分前2位的特征,依此类推,得到28个特征变量组合,分别进行随机森林分类,比较分类精度,以分类精度最高的组合来确定优选变量特征.
2.5 分类方案及精度评价
将基于特征优选与所有特征变量进行随机森林分类分别为优选特征随机森林(方案a)和原始随机森林(方案b),同时采用支持向量机法(方案c)和最大似然法(方案d)构成4种分类方案.利用混淆矩阵分别计算总体精度、kappa系数、生产者精度、用户精度对以上4种分类结果进行精度评价.
根据Janssen[27]等人指出,有必要在统计上以严格的方式比较不同分类的准确性,需要对由不同分类器计算得到的分类结果评估精度差异是否显著.本研究利用双比例Z值检验比较两种算法中正确分类像素的比例.该测试产生一个两尾概率值,该概率值测试了每个算法对的正确分类像素的比例之间没有差异的零假设,检验产生的Z统计量的平方遵循一个自由度的χ2分布,χ2大于3.84表示在5%的置信区间上具有显著差异[8].
3 结果与分析
3.1 特征重要性评估
分别对28种特征组合的随机森林分类后的结果进行精度评估,生成特征个数与分类精度的关系图(图2),可以得到以下结论,随着特征个数的增加,特征重要性得分靠前且贡献率较高的变量率先作为随机森林模型的输入量,特征变量间相关性较低,总体精度与kappa系数呈现急剧增长的趋势,前期随着可见光波段与红边指数波段输入到随机森林分类模型中,分类精度与kappa系数由48.69%和0.36迅速上升到89.19%和0.85,分类精度上升的趋势迅速.中期呈现波动上升的趋势,在特征个数达到13时,分类精度与kappa系数达到最高,分别为90.69%和0.87,特征个数从13增加到28时,由于特征之间的相互关联导致数据冗余,耗时增加,使得分类器性能降低,从而导致分类过拟合的现象产生,使得分类精度呈现波动减小的趋势.根据分类精度结果,选择最高的前13个特征变量组合作为优选特征集,并将基于特征优选后的随机森林分类结果参与后续的精度评估.
根据优选特征重要性分布图(图4)可知,Sentinel-2A的光谱波段特征占所有优选特征组合个数的62%,红边指数占31%,纹理特征占7%,说明影像光谱特征及红边指数特征在湿地信息提取中发挥着重要的作用.在优选特征重要性分布中,蓝光波段对洪湖湿地信息提取起重要的作用,蓝光波段重要性得分最高,分值达到2.85.可能的原因在于:1)蓝光波段对水体穿透性强,同时对植物绿反射反应敏感,具有较强的检测水体、识别植物的能力.洪湖作为长江中下游的大型湖泊,其主要地物类型为开阔水体,所以蓝光波段重要性得分最高.2)根据Immitzer与何云[28-29]等人研究结果表明,蓝光波段受其他波段特征关联的影响,蓝光波段选定后其他与其关联性强的波段特征重要性得分会相应降低,也使得蓝光波段重要性得分偏高;3)可见光波段中蓝光波段与其他波段相关性较低,重要性得分偏高.近红外波段排名相对靠前,位列第三,对于提高随机森林分类精度起到一定的作用.优选特征组合中红边指数排名靠前,红边指数特征重要性得分差异不大,其中IRECI指数重要性得分最高,达到1.71.在提取的5个纹理特征中只有均值(Mean)重要性得分较高,位列12,由于洪湖湿地土地覆盖类型中水体占绝大多数比例,水体内部异质性小,整体分类图斑比较规整,故纹理特征占优选特征的比例较小,仅有均值(Mean)纳入优选特征组合中.原始光谱波段与红边指数对于提取湿地土地覆盖的贡献大于一般的植被指数,由于植被水体指数的重要性贡献率偏低,发挥相对较弱的作用,没有在优选特征组合中体现.由此推断,与传统的光谱植被指数相比,红边植被指数是更有效的湿地植被的检测特征变量,将有助于改进目前基于遥感的湿地信息提取及土地覆盖监测,这也与Raczko[30]等人研究结果相一致.
3.2 特征变量对于区分地物的意义
遥感影像中不同波段对于分类不同地物具有重要意义,通过计算每种典型地类的特征均值,得到地物波谱曲线(图5).对于红边指数,由于红边指数量纲不同,对各类地物的红边指数均值进行标准化处理.由图5可知,红边指数特征IRECI与MCARI上水体波谱、浮叶及挺水植被与其他地物波谱间具有明显差异,可见红边指数对于洪湖复杂湿地信息提取具有重要意义.相较于其他纹理特征,均值(Mean)地物波谱曲线差异较大,在区分地物上更具优势.原始光谱特征中近红外波段在区分地物类别中相对具有较大差异,因而IRECI指数和MCARI指数的重要性得分较高,在评估特征变量的重要性得分时,B8a波段的重要性排名靠前,纹理特征中仅有均值(Mean)纳入优选特征集中.
3.3 分类结果及精度评价
基于四种不同分类方案下的湿地信息分类结果(图6)可知,通过目视解译效果来看,方案c和方案d的分类效果较差,出现了“椒盐现象”及类别错分,坑塘与湖泊两类水体斑块交界处区分较差,存在混分现象,其中方案d中沉水植被与水体之间、其他用地与浮叶及挺水植被类别之间存在错分现象.由于复杂的景观总是包含一些相似的地物类别,例如本研究中的坑塘与湖泊,其他用地与浮叶及挺水植被等类别,虽具有相似的光谱特征,但为不同的土地覆盖类别,支持向量机与最大似然分类算法在此类类别上集成训练样本的能力将被削弱,导致以上地物类别之间重叠、混分、错分的现象出现.
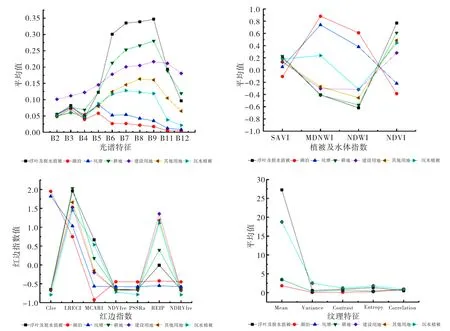
图5 地物波谱曲线Fig.5 Spectral curve of surface features
通过计算不同分类方案下的混淆矩阵,获得各类地物的生产者精度、用户精度以及分类结果的总体精度与kappa系数结果(见表2).各分类方案的分类精度差异较大,基于特征优选的随机森林方案分类精度最高,总体精度达到90.69%,kappa系数达到0.87,原始随机森林分类精度次之,最大似然法分类精度最低,其总体精度和kappa系数分别仅为83.12%和0.77.基于特征优选的随机森林方案分类结果中,汇总其混淆矩阵(表3),可以看出,湖泊、浮叶及挺水植被、耕地及建设用地以上4种类别的生产者精度和用户精度均高于85%,分类效果较好.由于其他用地与坑塘交相分布,内部结构复杂,在分类过程中分类精度不高,其他用地与坑塘混淆,用户精度与生产者精度均低于80%.
提取的特征集的个数与特征变量将影响分类类别的生产者精度、用户精度以及总体精度.所有特征参与分类时,因信息冗余造成原始随机森林分类结果的总体精度降低并影响分类类别的分类精度,所有特征的随机森林分类方案中考虑到沉水植被指数,沉水植被类别中生产者精度与用户精度有所提高,但数据冗余导致的分类性能降低也造成了其他地物类别生产者精度和用户精度的降低从而造成总体精度降低.相较于随机森林分类结果而言,支持向量机与最大似然法未考虑纹理特征及红边、植被水体指数特征等变量,所以支持向量机分类和最大似然法分类结果中沉水植被、坑塘及其他用地等类别的分类精度值较低,导致整体分类精度结果较差,其中总体分类精度分别降低了6.02%、7.57%.
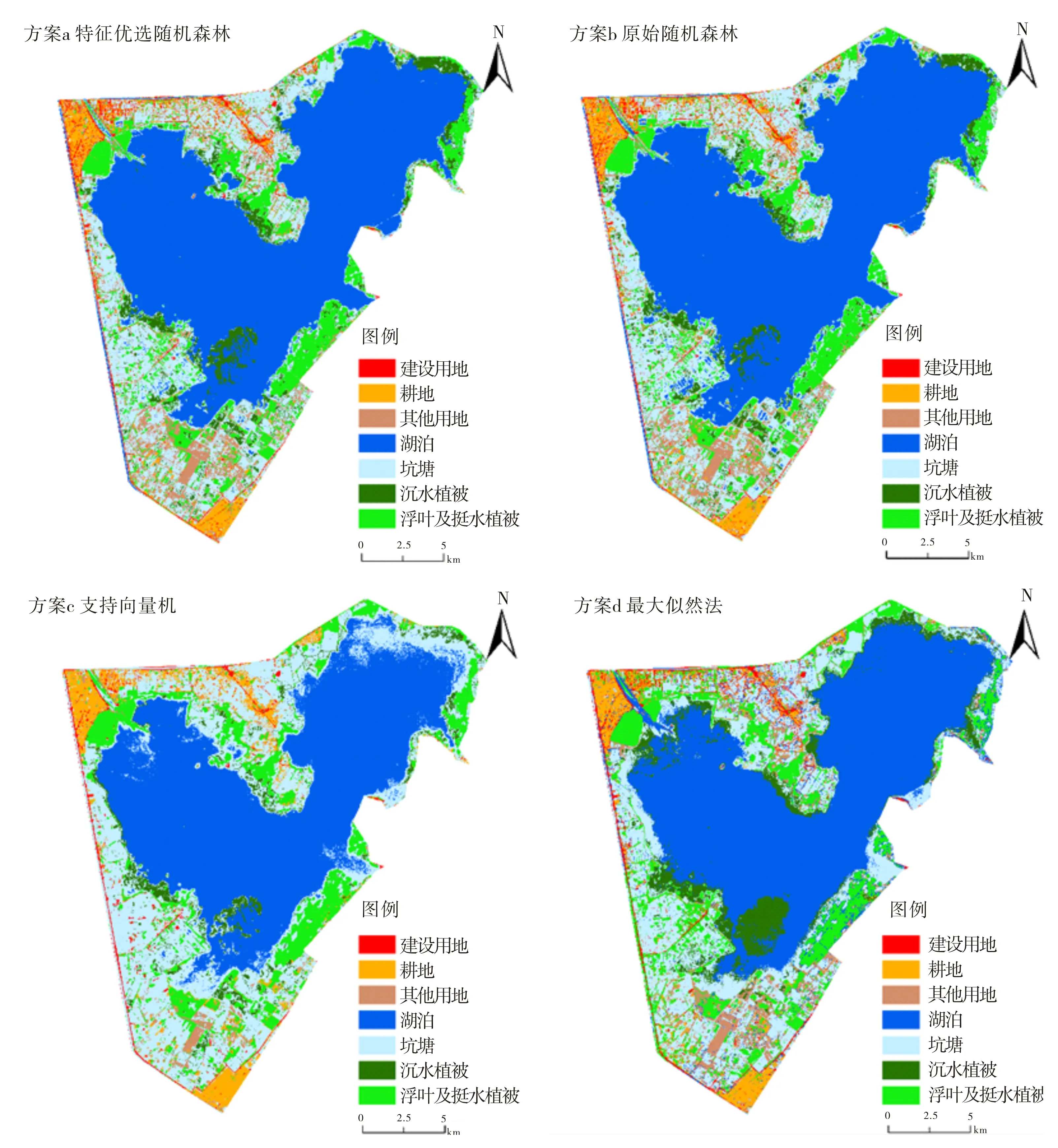
图6 基于四种不同分类方案的分类结果Fig.6 Classification results based on four different classification schemes
由于各分类方案的训练样本与验证样本数量相同,可以对精度做无偏估计,利用双比例Z值检验来判断算法对之间的精度分布差异(表4),结果可知:其中基于特征优选的随机森林分类结果分别与传统的支持向量机分类和最大似然法分类的精度分布在统计学上具有显著差异(p<0.01,χ2=25.891;p<0.01,χ2=38.895).相较于特征优选的随机森林分类和支持向量机分类的算法对的精度分布差异,基于特征优选的随机森林分类和最大似然法分类的两种算法的精度分布差异更大;支持向量机分类与最大似然法分类的总体精度分布并没有显著差异(p>0.05,χ2=1.379).
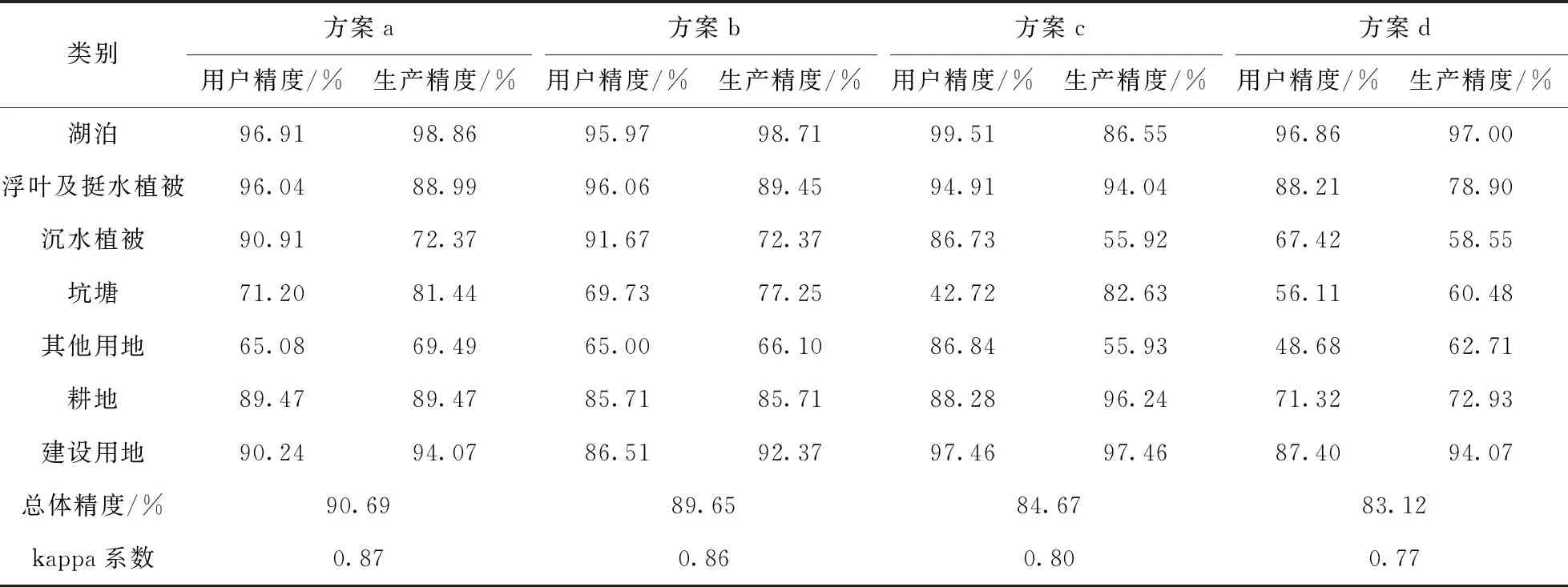
表2 分类精度统计Tab.2 The statistics of classification accuracy
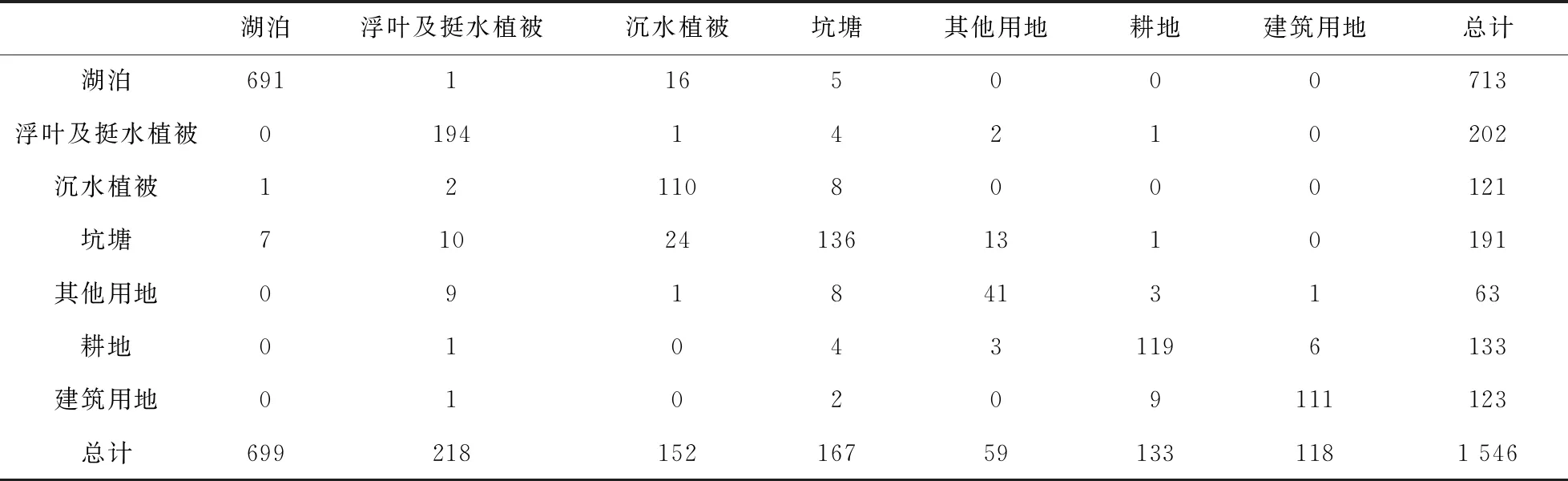
表3 基于特征优选的随机森林方法的分类结果混淆矩阵Tab.3 Confusion matrix of classificationresult based on feature-optimized random forest

表4 不同分类器下算法对的双比例Z值统计检验Tab.4 A two proportion Z-test for algorithm pairsunder different classifiers
4 结论
1)从特征个数与分类精度的关系来看,当特征个数增加到13以后,随机森林分类精度会随着特征个数过多造成的数据冗余以及分类过拟合现象而下降.
2)优选特征组合下,受蓝光波段自身穿透性强的特性和其他相关联的特征影响,蓝光波段的重要性得分最高,对湿地信息提取发挥重要作用.红边指数及红边波段的重要性排名靠前,而传统的植被指数没有在优选特征集中体现,表明在提取湖泊湿地信息时,相较于传统的植被指数,红边波段及红边指数发挥的作用更明显,红边波段及红边指数的应用将可能替代传统的植被指数,并提升分类精度.
3)比较不同分类方案下的分类精度,基于特征优选的随机森林分类精度高于原始随机森林分类结果,基于特征优选的随机森林分类精度明显高于支持向量机分类和最大似然法分类,在5%的置信区间上具有显著差异.
综上所述,基于特征优选的随机森林方法对于优化提取复杂湿地信息发挥重要的作用,将为今后管理湿地提供科学依据与决策支持.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
九江学院学报(自然科学版)(2022年2期)2022-07-02
航天返回与遥感(2022年2期)2022-05-12
波谱学杂志(2022年1期)2022-03-15
华北理工大学学报(自然科学版)(2021年3期)2021-07-03
小学生学习指导(高年级)(2021年4期)2021-04-29
华人时刊(2016年16期)2016-04-05
新高考·高二数学(2014年7期)2014-09-18
福建中学数学(2011年9期)2011-11-03
