
时空域深度学习火灾烟雾检测
2021-08-30 06:56王慧琴
液晶与显示 2021年8期
吴 凡, 王慧琴, 王 可
(西安建筑科技大学 信息与控制工程学院, 陕西 西安710055)
1 引 言
火灾是自然和社会灾害中发生概率最高的灾害之一,对人类的生活和生命安全构成严重威胁[1]。因此,快速而准确地检测火灾发生至关重要。
当前的火灾探测方式仍以各种火灾传感器为主,虽然其低价简单,但极易受到粉尘、气流以及高度等因素的干扰[2]。通常情况下,明火在与空气充分接触之后才会产生,而在燃烧初期烟雾即已出现,因此准确检测烟雾能够比火焰检测更早发出火灾报警[3]。
目前烟雾检测研究流程大致可分为疑似烟雾目标提取、烟雾特征提取以及烟雾检测几个重要部分。Barmpoutis[4]等基于HSV(Hue, Saturation, Value) 颜色模型,使用结合烟雾颜色特征的背景差法提取帧内疑似烟雾区域。Park[5]等结合帧差法和非参数颜色模型检测疑似烟雾目标,基于此算法设计了一种烟雾检测随机森林分类器。该算法可以加快烟雾检测速度,但检测烟区中易存在空洞,且用于复杂环境时烟雾检测虚警率高。在以上研究基础上,一些学者为增强分类器的性能,加入了机器视觉方法。李红娣[6]等使用金字塔分解算法提取烟雾的金字塔纹理和边缘特征,并通过支持向量机(Support Vector Machine)进行训练和检测烟雾。Zhao[7]等利用烟雾的颜色等特性,基于CS Adaboost算法对烟雾进行检测,该算法可有效地分辨浓雾和烟雾。上述方法的烟雾特征设计与提取多数由手工完成,需基于经验设定阈值作为识别烟雾的判断依据,未必能够反映烟雾的本质特征,其合理性会因烟雾本身和环境变化受到影响。
近年来,基于深度学习的视频检测方法发展迅猛,作为一种性能强、适用性广的方法逐渐在火灾探测中得到应用[8]。Kim[9]等提出用卷积神经网络(Convolutional Neural Networks,CNN)检测视频中的烟雾。该研究利用输入视频图像的颜色信息提取烟雾候选区域,然后利用预训练的CNN进行烟雾检测。该方法较之前的传统检测方法误检率和漏检率得到改善,性能有所提高。陈俊周[10]等融合烟雾的动静态纹理信息,提出基于级联卷积神经网络的烟雾纹理识别框架,提高烟雾检测的准确率,然而其将静态动态纹理信息分别处理导致算法复杂度增加,影响烟雾实时检测。孙颖[11]提出了一种基于3D残差密集网络的烟雾检测算法,将残差网络和密集连接网络进行整合,形成3D Residual Dense Block网络模块,以提取烟雾的时空特征。神经网络算法虽然性能较优,但二维 CNN无法提取时域特征,丢失了时间维度的帧间运动信息,因而检测效果不佳;三维 CNN则因特征维度提升,计算成本大幅增加,影响检测时效和准确率。
本文提出一种基于时空域深度学习的火灾烟雾视频检测算法,利用分块的运动目标检测算法过滤非烟雾区域,再输入经预训练的二加一维时空域网络模型,提取烟雾的时空域特征,抑制无关特征,最后将烟雾区域分块标记,提高了检测准确率和时效。
2 相关算法概述
卷积神经网络是深度学习(Deep learning)的代表算法之一,模仿生物的视觉感知机制构建,可进行监督学习和非监督学习。三维卷积神经网络是一种视频检测网络,在物体识别、动作检测等方面有着巨大优势。
一些研究使用二维神经网络对视频进行检测,研究对象大多数是视频的帧截图,忽略了帧间运动信息的时间序列,因此时间维度上的帧间运动信息会丢失。如果将二维卷积神经网络拓展到三维,便可同时提取时间和空间维度特征,增加时间维度的特征信息,滤波器的内核维度也因此会增加,在学习单个图片邻近像素的同时学习时间上接近的像素,即学习时空特征,其公式如式(1)所示:
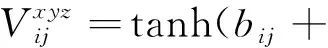
(1)

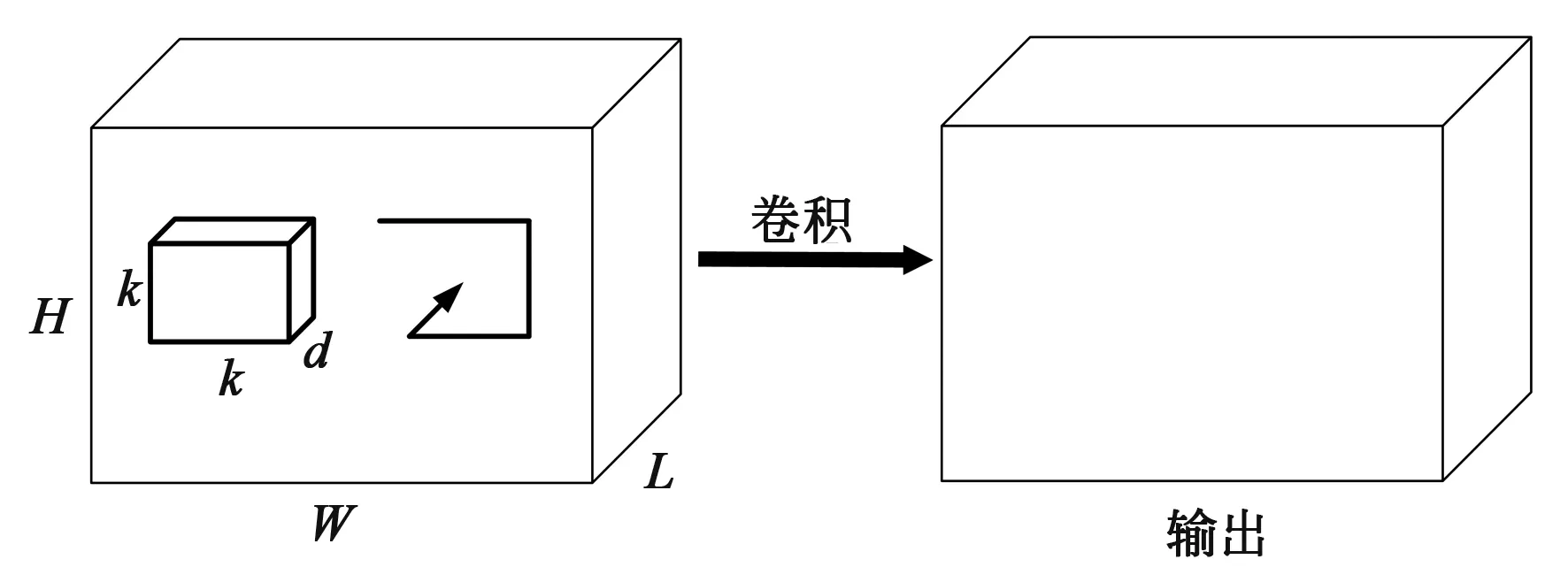
图1 三维卷积原理图Fig.1 Schematic diagram of three-dimensional convolution
3 时空域深度学习烟雾检测
3.1 疑似烟雾目标运动检测
由于烟雾属于运动目标,从视频图像中提取运动目标可滤除大量非烟雾区域,再对分割出的疑似烟雾区域进行预处理,输入网络模型进行烟雾识别,可有效提高准确率和时效。为了使运动目标检测部分达到理想的效果,本研究将采用高斯混合模型和四帧差分法相结合的运动检测算法提取疑似烟雾目标,准备输入网络模型。
3.1.1 高斯混合模型
在高斯混合模型[12](Gaussian mixture model)中,每一个背景图片像素点的描述都由N个高斯分布组成,这几个高斯分布的加权组合形成背景。
首先是构建初始背景模型。读取视频序列前N帧图片,通过预处理将其转化成灰度图片序列fi(i=1,2,3,…,N),将图片中坐标为(x,y)的像素值fi(x,y)分别向这N个高斯分布的均值ui,l(x,y)赋值,随后用一个相对较大的方差将每个高斯分布初始化,至此高斯混合模型建立完成,表达式如下:
(2)
其中,N是高斯模型的数量,ηl(fi,ui,l,σi,l)代表第l个高斯分布,ωi,l表示第l个高斯分布的权重,通常初始值设为1/M。
第二步是前景目标检测。读取下一帧图片,经预处理后记做fi+1,依照ω/σ的值从大到小的顺序将fi+1(x,y)对应的高斯模型排序,选择比值较大的前B个高斯分布生成该图片的背景,B的表达式如下:
(3)
其中,T为使用者设定的阈值,亦称门限参数,随后依照下面的表达式(4)进行匹配,若fi+1(x,y)与其背景模型中序号为k(k≤B)的高斯分布匹配,则该点可以认定为背景,否则为前景目标。λ是前景阈值,一般设为2.5。
|ft+1(x,y)-ut,k|≤λσt,k
.
(4)
第三步是背景模型更新。新的一帧图片完成检测后,若fi+1(x,y)被判定来自于前景,即说明前B个高斯分布模型没有一个能与该点对应的模型相匹配,需要一个新的高斯分布函数代替ω/σ值最小的那个分布函数,其均值为fi+1(x,y),给定的权值较小,方差较大。
与fi+1(x,y)匹配的高斯分布表达式按下面的表达式更新:

ωt+1,l(x,y)=(1-α)ωt,l(x,y)+α
(5)
ut+1,l(x,y)=(1-ρ)ui,l(x,y)+ρft+1(x,y)
(6)
(7)
不与fi+1(x,y)匹配的高斯分布表达式则按照表达式(8)更新:
ωt+1,l(x,y)=(1-α)wi,l(x,y)
(8)
最终将权值归一化,式中α、ρ是通常由经验设定的学习速率。
3.1.2 四帧差分法
帧间差分法(Frame difference method)是通过获得相邻连续帧的差别以进行运动目标检测,具有算法简单、时间复杂度低的优点,对动静态背景适应性好,不需要提取和更新背景。然而常用的二帧差分法无法解决双影与空洞问题,本研究采用性能较好的四帧差分法[13]以消除目标检测过程中存在的空洞和双影现象。具体步骤如下:
(1)读取视频序列连续4帧图片,处理为灰度图片后进行中值滤波去噪,获得连续4帧预处理过的图片,并将其设为Ik(x,y),Ik+1(x,y),Ik+2(x,y),Ik+3(x,y)。
(2)将4帧图片进行间隔差分,即第1帧与第3帧、第2帧与第4帧差分,使用阈值进行分割,获得二值化图片,表达式如下:
(9)
(10)
式中,d1k、d2k是差分处理过的图片,Z是预设的二值化固定阈值。
(3)将第2步得到的二值化图片中运动目标的轮廓进行填充,由于背景为纯黑色,故选用易于分辨的纯白色对运动目标区域进行填充。
(4)为了减少双影现象,对第3步结果进行逻辑“与”操作,见下式:
Dk=d1k∩d2k
(11)
.
(12)
3.1.3 视频分块检测
烟雾部分明显特征是形状不确定,运动方向和速度不规律,为了更便捷地标记运动区域,以及将疑似烟雾目标区域输入后续神经网络中进行学习,本文将原始视频数据的每一帧分成相同大小互不重合的小方块,进行如图2的分块运动检测,分块公式如下所示:

图2 烟雾图像分块处理示例Fig.2 Example of block processing of smoke image

(13)
其中,hX、hY分别代表原始图像的宽和高,hx、hy分别代表图像每个分块的宽和高,nc、nr分别代表视频帧被分割的行数与列数。
3.1.4 高斯混合模型与四帧差分法混合运动目标检测
本文采取四帧差分法与高斯混合模型混合算法进行运动目标检测。首先将读取的视频序列进行预处理,随后分别送入四帧差分改进算法和高斯混合模型当中进行前景目标提取,再将两个算法分割的前景目标进行“与”逻辑操作,通过连通性分析,形态学处理,得到疑似烟雾目标区域,最后使用分块将其标记并储存。具体算法流程如图3所示。

图3 运动目标检测算法流程图Fig.3 Moving target detection algorithm flow chart
3.2 时空域深度学习火灾烟雾检测
烟雾本身外观特征复杂,也会环境变化增大特征差异。传统人工设计处理的特征难以描述烟雾的全部本质,极易受到相似目标的干扰,因此检测准确率不高。三维神经网络在视频检测,动作分类等领域优势巨大,而残差网络则在特征提取方面拥有出色表现,本文结合二者优势,提出一种改进的二加一维时空域网络。将一般的三维卷积神经网络结构分解为二维加一维卷积网络层,先后提取视频图像的空域和时域特征,并加入注意力机制,利用该机制的小型子网络运算重新标定特征通道权重,过滤无关特征,最后通过全连接层得到最终检测结果。
3.2.1 二加一维时空域网络结构
三维卷积神经网络因其能同时提取时空域特征在视频检测领域得到应用,但是其存在参数量多、计算量高的问题。以最常见的三维网络模型C3D(Convolutional 3D Network)为例,在使用数据集Sports-1M训练时,模型大小超过300 MB。视频烟雾检测系统多用于嵌入式设备,这就要求烟雾时空域特征提取所用到的神经网络计算成本低,模型参数少。
二加一维神经网络模块是指将三维网络结构拆分为独立的二维空域卷积结构和一维时域网络结构,使得非线性数量增加一倍,同时分解交织的时间与空间信息,使得网络利于优化,从而在保证三维网络性能的前提下降低了计算成本。设输入特征图尺寸为l×w×h×f,其中l为视频帧数,w为视频宽度,h为视频高度,f为输入特征维度。原三维卷积核尺寸为t×k×k,将其拆分为1×k×k的空域卷积核与t×1×1的时域卷积核后,计算过程由t×k×k变为t+k×k,计算量得到明显减少,然而参数量的锐减对模型的复杂性和表达能力有明显影响。由此需要在充分利用二加一维网络的优点的同时保留足够的参数量。
本文参考文献[14]的方法,通过一个超参数M更改中间特征通道数量,将二加一维参数量恢复到原三维网络的水平,图4为采用超参数M的二加一维结构。M的计算公式以及计算参数对比如下:
(14)
3D:Ni-1×Ni×t×k×k;(2+1)D:Ni-1×M×1×k×k+M×Ni×t×1×1
.
(15)
在时域与空域卷积之后是批标准化层(Batch Normalization,BN)[15],其作用对象是每个隐层神经元,其输入分布在逐渐向非线性函数映射后,取值区间会向极限饱和区靠拢,BN层可以将其强制拉回到均值为0、方差为1的标准正态分布,使非线性变换函数的输入值落入对输入比较敏感的区域,有效解决不同层数据分布不一致和梯度消失问题。之后引入整流线性单元(Rectified Linear Unit,ReLU)激活函数层[16],其作用是增加模型的非线性表达能力,防止过拟合现象,提升训练精度。
二加一维网络结构因为有M超参数的存在,使得时空域两个子卷积层之间增加了一个非线性操作,与原来同样参数量的三维卷积结构相比非线性操作数量翻倍,网络复杂度由此增加。第二个好处是时空域分解让优化的过程也分解开,三维时空卷积把空间信息和动态信息交织在一起,优化过程较为复杂。而二加一维卷积分别提取时空域特征,优化过程相对简单,可以使模型误差降低。
3.2.2 注意力机制层
为了提高检测效率,本文在二加一维网络结构中引入注意力机制。Hu[17]等提出了一种压缩和激励网络(Squeeze-and-Excitation Network,SENet),在网络训练过程中可以自动重新标定特征,抑制对分类无用的特征,提高网络的分类识别能力。
该网络层包括以下3个处理步骤:
(1)压缩(Squeeze)操作:将大小为l×w×h×f的输入,使用一个全局池化层压缩输入张量中除特征通道维度f之外的所有维度,使其转化为一特征通道数大小的实数向量,大小为1×f。
(2)激励(Excitation)操作:通过一个全连接层压缩转换的特征向量,使其维度降低到f/r,大小为1×f/r,再经过ReLU函数激活后通过一个全连接层,得到一个输出维度与输入特征通道数相匹配的特征权重向量,大小为1×f。
(3)权值重标定(Reweight)操作:使用Sigmoid函数将权重归一化,最后将Excitation操作得到的权重对特征通道进行加权,从而实现对特征的重新标定。
将SENet和二加一维网络按图5的形式结合在一起,就形成了时空域注意力网络模块。

图5 时空域注意力网络模块Fig.5 Spatio-temporal attention network module
3.2.3 网络总体框架
本文提出的二加一维时空域网络采用时间卷积层和空间卷积层串联结构替代三维卷积结构提取时空特征,并引入注意力机制,过滤无关特征,提高了网络的检测性能。本文提出的网络结构整体框架如图6所示。
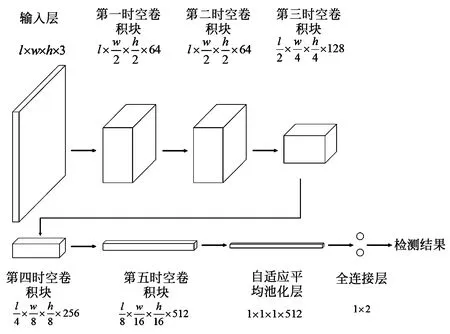
图6 时空域深度卷积神经网络架构图Fig.6 Graph of convolutional neural network in spatio-temporal
(1)输入层:输入为l帧连续RGB烟雾图像,尺寸为l×w×h×f,其中l为视频帧数,w为视频宽度,h为视频高度,f为输入特征维度。本文输入为连续的RGB图像,故f取值为3。
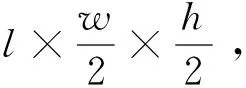
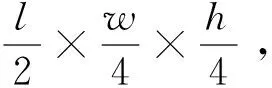
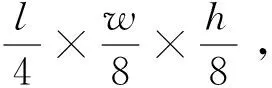

(7)输出层:将输入数据送入通道数为512的全局平均池化层,最后通过全连接层得到是否为烟雾的评估结果。
4 实验及结果分析
本研究实验环境为 Win10 64位操作系统,内存为16 GB,CPU为Intel Core i7-8700,图形处理器为 NVIDIA GeForce RTX2070 8G,深度学习框架为Pytorch,在Python和 Microsoft Visual Studio Code 编程环境下实现。
4.1 实验设置
为验证本算法的有效性,数据集从课题组自行拍摄的烟雾视频以及网络烟雾视频集中截取,选取不同场景下的烟雾正样本及负样本进行火灾识别实验。场景分为室内与室外开阔空间两种环境,干扰物有与烟雾颜色相近的云朵、加湿器水雾、白色背景墙,树林等。总样本为208 184张,每8张连续图片为一个视频块,其中 188 792 张用于train数据集,9 792 张用于val数据集,9 600张作为test数据集,每帧样本大小为32×32。
4.2 网络模型训练
本次研究使用4.1节的数据集进行训练,在参数设定环节中,我们选择随机梯度下降(Stochastic Gradient Descent,SGD)作为网络损耗的优化器,训练Epoch数量设置为50,一次训练所选取的样本数(Batch_size)为64,设置动量系数为0.9和权重衰减值为0.000 5,初始学习率设置为0.001,学习率每经过10个训练周期(Epoch)便衰减为原来的1/10。
4.3 评价指标
为了测试本研究算法的性能,采用文献[18]的评价标准。计算得到准确率(ACC),正确率(TPR),虚警率(FPR),公式如下:
(16)
(17)
(18)
式中,N为总烟雾样本数,TP为被检测为有烟雾的有烟雾样本数,TN为被检测为无烟雾的无烟雾样本数,FP为被检测为有烟雾的无烟雾样本数,FN为被检测为无烟雾的有烟雾样本数。
4.4 实验结果与性能对比
本次研究共选择10段视频作为测试,具体描述说明如表1所示。
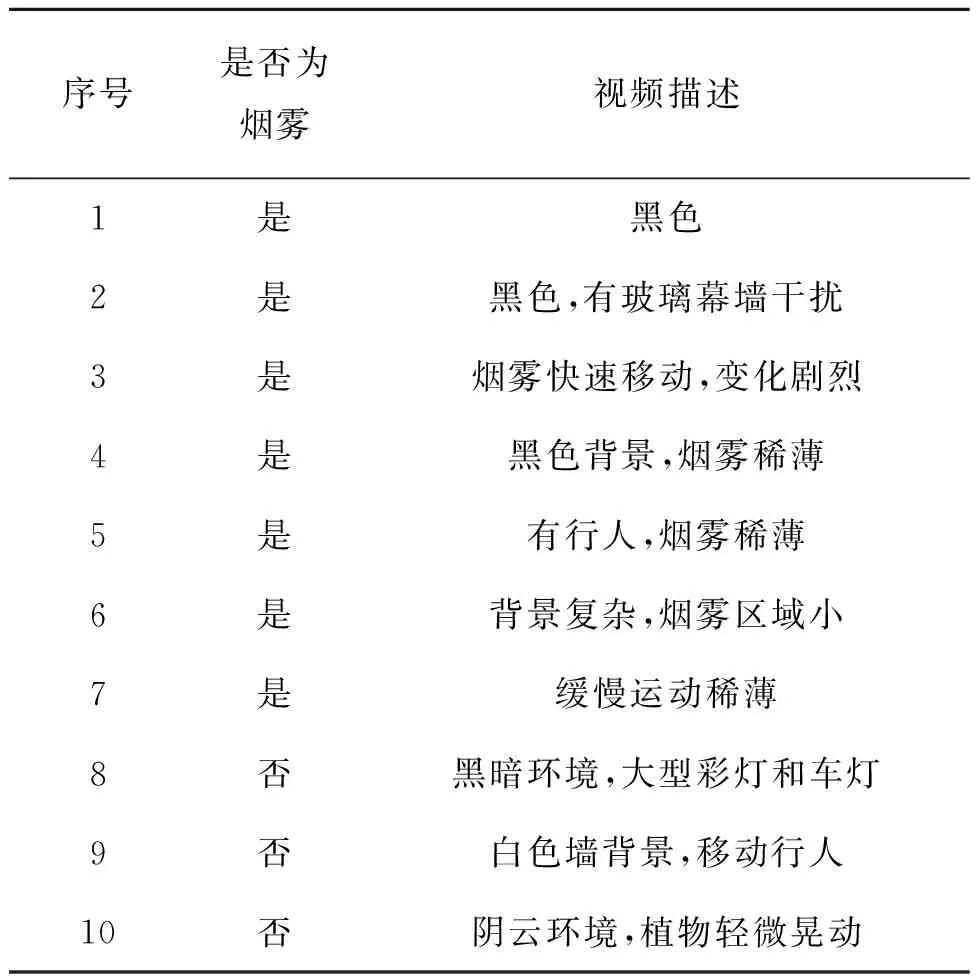
表1 测试视频说明Tab.1 Test video description
图7所示为部分视频烟雾检测效果,图中检测出的烟雾区域为白色方块标记的位置。实验结果表明,本文采用的烟雾检测算法在10段测试视频中都取得了良好的效果。对于不同颜色、不同浓度、不同速度的烟雾都能够取得理想的检测效果。在加湿器水雾、云等类烟运动物体、多云和白色背景墙的复杂背景干扰下也具有良好的鲁棒性。

图7 部分检测结果。(a)、(b)、(c)为有烟雾视频,(d)为无烟雾视频。Fig.7 Part of the test results. (a),(b),(c) Smoke videos; (d) Non-smoke video.
为充分验证本算法的有效性,将去掉第三与第四时空残差卷积块,减少特征通道维度变换次数的模型称为算法1,所有时空残差卷积块去掉SENet网络层的模型称为算法2,共同与本文提出的算法进行对比,对比的数值为10个视频评价标准的平均数值,分别为平均准确率(AACC),平均正确率(ATPR)和平均虚警率(AFPR),结果如表2所示。


表2 不同结构性能对比
由表2可知,算法1由于减少时空残差卷积块导致网络的层数减少,模型深度不足,对烟雾特征提取不充分,故而本文算法比算法1平均准确率增加3.09%,虚警率降低2.18%,说明较深层数的网络模型能够有效提取烟雾特征。而对于算法2,本文算法增加了SENet层以重新标定特征权重,减少了冗余的无用特征,因此平均准确率提升0.97%,平均虚警率也有所改善,降低了0.7%,说明增加Senet层能够使网络模型对烟雾特征的注意力提高。
为进一步验证烟雾检测算法的有效性,本文还将采用LBP和LBPV检测烟雾的文献[19]方法,采用PCA主成分分析和Inception Resnet v2网络算法的文献[20]方法,采用VGG16和Resnet50网络融合算法的文献[21]方法以及采用3D密集残差网络的文献[11]方法加入本文算法性能对比,结果如表3所示。
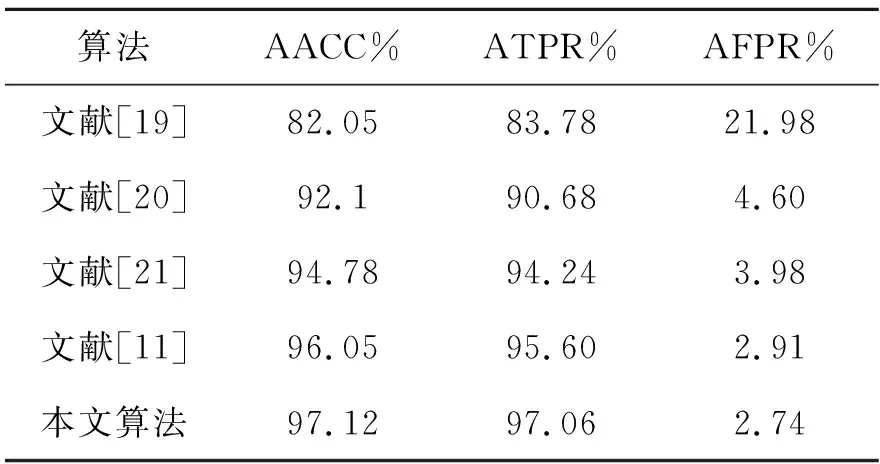
表3 与其他算法性能对比Tab.3 Performance comparison with other algorithms
由表3结果可知,与传统的手工设计提取烟雾特征以及机器视觉算法的检测方法相比,卷积神经网络能够实现端对端、自动选取烟雾的检测特征,且特征种类和规模更加丰富,因此文献[20],文献[21]、文献[11]的算法及本文算法平均准确率均可以达到90%以上,文献[21]的方法平均虚警率比文献[19]降低了18%。而对于各种基于二维卷积神经网络的算法,本文算法使用的网络模型能够对图像和运动信息建模,同时提取空域与时域特征,最终平均准确率提升2.34%,虚警率改善明显,降低了1.24%,说明提取时空域特征可以显著提升烟雾检测效果。对于文献[11]方法,由于本文算法增加了非线性因素且时空域分开运算,因而检测准确率提升1.07%,虚警率提升0.17%。
为了验证烟雾检测算法的时效,本文以每秒传输帧数(Frames Per Second,FPS)作为对比指标,将采用三维密集残差网络的文献[11]方法,以及去掉本文算法时空网络块中SENet层的算法3加入性能对比,结果如表4所示。

表4 检测效率对比Tab.4 Comparison of detection efficiency
由表4结果可知,本文的二加一维网络算法比标准的三维网络检测速率有明显提升,且未因SENet层的加入出现大幅降低的现象,对比算法3,检测准确率有所提升,综合效果更好。
5 结 论
本文为了准确地从视频中检测烟雾,充分提取视频的时空域特征,同时改善三维网络模型的检测时效问题,提出了一种加入注意力机制的二加一维时空域深度学习检测算法。利用分块的运动目标检测算法,过滤非烟雾目标,经预处理后输入到二加一维神经网络模型进行时空域特征提取。为抑制无关特征,使用注意力机制重新标定特征通道,经全连接层输出检测结果后将烟雾区域分块标定。在实验数据集测试得到的结果中,平均准确率为97.12%,平均正确率为97.06%,平均虚警率为2.74%,平均FPS为10.49帧/s。实验数据表明,该算法可以有效减少复杂场景、类烟目标对烟雾特征的干扰,相比现有三维CNN算法提升了检测速率,取得了良好的检测效果。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
小学阅读指南·低年级版(2021年3期)2021-03-19
军民两用技术与产品(2021年10期)2021-03-16
华人时刊(2019年13期)2019-11-26
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
当代陕西(2017年12期)2018-01-19
西南交通大学学报(2016年4期)2016-06-15
海峡科技与产业(2016年3期)2016-05-17
中国农业文摘-农业工程(2016年5期)2016-04-12
